python的kafka安装教程和使用教程 windows
python的卡夫卡安装教程和使用教程
python安装命令:
pip install kafka-python -i https://pypi.tuna.tsinghua.edu.cn/simple
卡夫卡是实现服务器数据共享使用的
1.首先下载java
java网址: https://www.oracle.com/java/technologies/downloads/#jdk18-windows

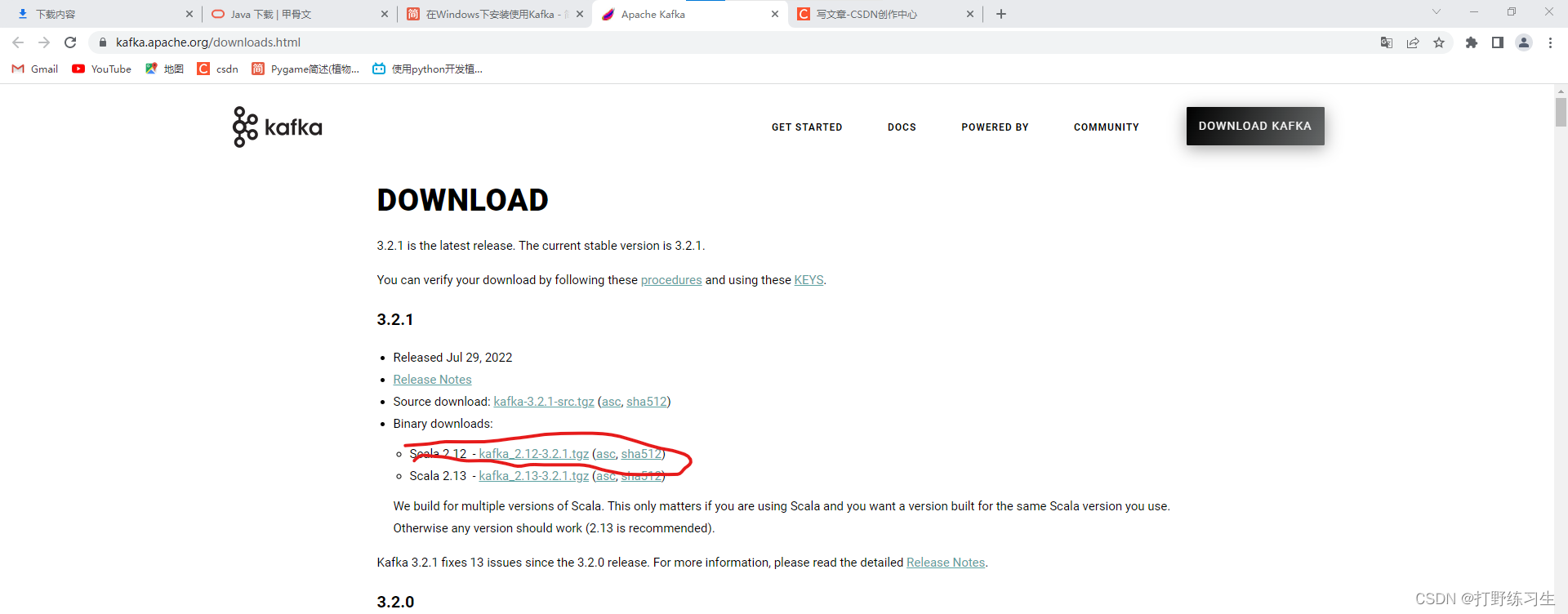
2.kafka下载网址
https://kafka.apache.org/downloads.html
3.解压文件
4.进入存放卡夫卡的目录,在
D:\Tool\kafka\kafka_2.12-3.2.1\bin\windows下输入cmd
每一条命令开启一个cmd窗口:
(1)zookeeper-server-start.bat ..\..\config\zookeeper.properties
(2)kafka-server-start.bat ..\..\config\server.properties
(3)kafka-console-producer.bat --broker-list LAPTOP-9DFELM73:9092 --topic test #启动生产者
(4)kafka-console-consumer.bat --bootstrap-server LAPTOP-9DFELM73:9092 --topic test --from-beginning #启动消费者
第二条命令出现错误时:

请重新执行几次第二条命令,即可
代码实现:
知识点:
1.kafka的数据存储,不是永久的,它有默认的过期时间
2.消费者才有分组
kafka使用的目录结构

kafka数据管理流程图
生产者.py文件
# 生产者
from kafka import KafkaProducer
#
consumer = KafkaProducer(bootstrap_servers=["localhost:9092"])
#partition分区
#s.get(10)发送数据,10的参数是,存入kafka的限制,不限制一直存,会把服务器存崩溃
for i in range(100):
s = consumer.send(topic="test", value=b'123564765fdsgvfg', partition=0)
s.get(10)
print(s)
消费者.py
from kafka import KafkaConsumer
#创建一个消费者
consumer = KafkaConsumer('test',bootstrap_servers=['localhost:9092'])
for i in consumer:
print(i)
直接右击运行两个py文件
kafka模式:
观察者模式:
定义对象中的一种一对多的模式,是的每一个当前对象改变状态,则所有依赖于它的对象都会得到通知,并自动更新,一个对象(目标对象)的状态发生改变,所有的依赖对象都将得到通知 业务场景:京东到货通知
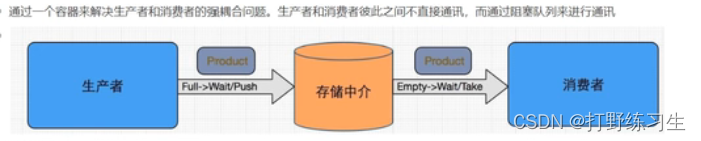
生产者消费者模式:即N个线程进行生成,同时N个线程进行消费
生产者:生产数据存入缓冲区(存储中介)
消费者:从存储中介拿数据

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)