
Kafka重复消费场景及解决方案
在消费过程中消费者单次会拉取11条消息,每条消息耗时30s,11条消息耗时5分钟30秒,由于max.poll.interval.ms默认值5分钟,所以理论上消费者无法在5分钟内消费完,consumer会离开组,导致rebalance。
Kafka消费者以消费者组(Consumer Group)的形式消费一个topic,发布到topic中的每个记录将传递到每个订阅消费者者组中的一个消费者实例。Consumer Group 之间彼此独立,互不影响,它们能够订阅相同的一组主题而互不干涉。生产环境中消费者在消费消息的时候若不考虑消费者的相关特性可能会出现重复消费的问题。
在讨论重复消费之前,首先来看一下kafka中跟消费者有关的几个重要配置参数。
- enable.auto.commit 默认值true,表示消费者会周期性自动提交消费的offset
- auto.commit.interval.ms 在enable.auto.commit 为true的情况下,
自动提交的间隔,默认值5000ms max.poll.records 单次消费者拉取的最大数据条数,默认值 500 - max.poll.interval.ms
- 默认值5分钟,表示若5分钟之内消费者没有消费完上一次poll的消息,那么consumer会主动发起离开group的请求
在常见的使用场景下,我们的消费者配置比较简单,特别是集成Spring组件进行消息的消费,通常情况下我们仅需通过一个注解就可以实现消息的消费。例如如下代码:
这段代码中我们配置了一个kafka消费注解,制定消费名为"test1"的topic,这个消费者属于"group1"消费组。开发者只需要对得到的消息进行处理即可。那么这段 代码中的消费者在这个过程中是如何拉取消息的呢,消费者消费消息之后又是如何提交对应消息的位移(offset)的呢?
实际上在autocommit=true时,当上一次poll方法拉取的消息消费完时会进行下一次poll,在经过auto.commit.interval.ms间隔后,下一次调用poll时会提交所有已消费消息的offset。
为了验证consumer自动提交的时机,配置消费者参数如下:

为了便于获取消费者消费进度,以下代码通过kafka提供的相关接口定时每隔5s获取一次消费者的消费进度信息,并将获取到的信息打印到控制台。

对于topic test1,为了便于观察消费情况,我们仅设置了一个partition。对于消费者组group1的配置参数,消费者会单次拉取消息数20条,消费每条消息耗费1s,部分记录日志打印结果如下:
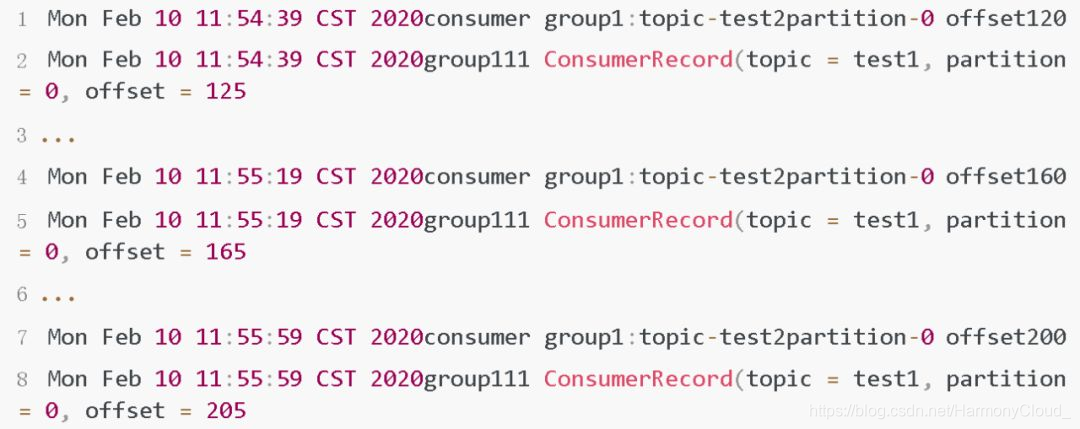
从日志中可以看出,消费组的offset每40s更新一次,因为每次poll会拉取20条消息,每个消息消费1s,在第一次poll之后,下一次poll因为没有达到auto.commit.interval.ms=30s,所以不会提交offset。第二次poll时,已经经过40s,因此这次poll会提交之前两次消费的消息,offset增加40。也就是说只有在经过auto.commit.interval.ms间隔后,并且在下一次调用poll时才会提交所有 已消费消息的offset。
考虑到以上消费者消费消息的特点,在配置自动提交enable.auto.commit 默认值true情况下,出现重复消费的场景有以下几种:
- Consumer 在消费过程中,应用进程被强制kill掉或发生异常退出。
例如在一次poll500条消息后,消费到200条时,进程被强制kill消费导致offset 未提交,或出现异常退出导致消费到offset未提交。下次重启时,依然会重新拉取这500消息,这样就造成之前消费到200条消息重复消费了两次。因此在有消费者线程的应用中,应尽量避免使用kill -9这样强制杀进程的命令。
- 消费者消费时间过长
max.poll.interval.ms参数定义了两次poll的最大间隔,它的默认值是 5 分钟,表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起“离开组”的请求,Coordinator 也会开启新一轮 Rebalance。若消费者消费的消息比较耗时,那么这种情况可能就会出现。
为了复现这种场景,我们对消费者重新进行了配置,消费者参数如下:

在消费过程中消费者单次会拉取11条消息,每条消息耗时30s,11条消息耗时 5分钟30秒,由于max.poll.interval.ms 默认值5分钟,所以理论上消费者无法在5分钟内消费完,consumer会离开组,导致rebalance。
实际运行日志如下:
可以看到在消费完第11条消息后,因为消费时间超出max.poll.interval.ms 默认值5分钟,这时consumer已经离开消费组了,开始rebalance,因此提交offset失败。之后重新rebalance,消费者再次分配partition后,再次poll拉取消息依然从之前消费过的消息处开始消费,这样就造成重复消费。而且若不解决消费单次消费时间过长的问题,这部分消息可能会一直重复消费。
对于上述重复消费的场景,若不进行相应的处理,那么有可能造成一些线上问题。为了避免因重复消费导致的问题,以下提供了两种解决重复消费的思路。
第一种思路是提高消费能力,提高单条消息的处理速度,例如对消息处理中比 较耗时的步骤可通过异步的方式进行处理、利用多线程处理等。在缩短单条消息消费时常的同时,根据实际场景可将max.poll.interval.ms值设置大一点,避免不 必要的rebalance,此外可适当减小max.poll.records的值,默认值是500,可根 据实际消息速率适当调小。这种思路可解决因消费时间过长导致的重复消费问题, 对代码改动较小,但无法绝对避免重复消费问题。
第二种思路是引入单独去重机制,例如生成消息时,在消息中加入唯一标识符如消息id等。在消费端,我们可以保存最近的1000条消息id到redis或mysql表中,配置max.poll.records的值小于1000。在消费消息时先通过前置表去重后再进行消息的处理。
此外,在一些消费场景中,我们可以将消费的接口幂等处理,例如数据库的查 询操作天然具有幂等性,这时候可不用考虑重复消费的问题。对于例如新增数据的操作,可通过设置唯一键等方式以达到单次与多次操作对系统的影响相同,从而使接口具有幂等性。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)