Kafka系列之—从Kafka读取数据(五)
一 KafkaConsumer1.1 消费者和消费者群组假设主题T1有四个分区,我们创建了消费者C1,他是群组G1里唯一的消费者,我们用它订阅主题T1,消费者C1将收到主题T1全部4个分区的消息,如图:如果在群组G1里新增一个消费者C2,那么每个消费者将分别从两个分区接收消息。我们假设消费者C1接受分区0和分区2的消息,消费者C2接收分区1和分区3的消息,如图:如果群组G1有4个消费者,那么每个消
一 KafkaConsumer
1.1 消费者和消费者群组
假设主题T1有四个分区,我们创建了消费者C1,他是群组G1里唯一的消费者,我们用它订阅主题T1,消费者C1将收到主题T1全部4个分区的消息,如图:

如果在群组G1里新增一个消费者C2,那么每个消费者将分别从两个分区接收消息。我们假设消费者C1接受分区0和分区2的消息,消费者C2接收分区1和分区3的消息,如图:
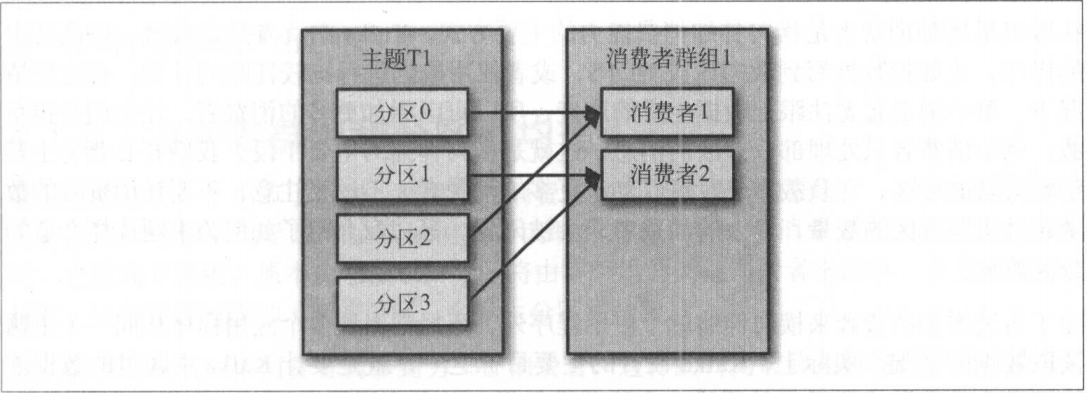
如果群组G1有4个消费者,那么每个消费者可以分配到一个分区,如图:

如果我们往群组中添加更多的消费者,超过主题的分区数量,那么有一部分消费者就会被闲置,不会收到任何消息,如图:
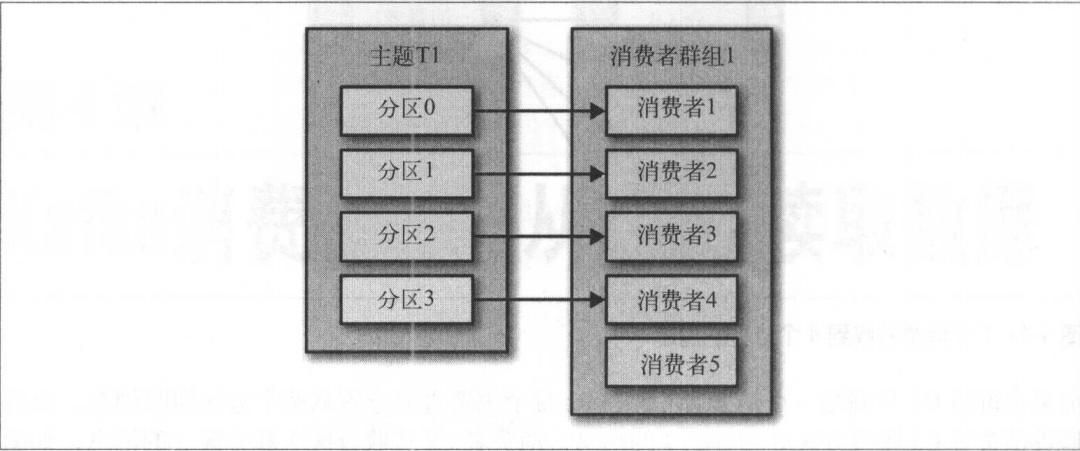
注意不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置
1.2 三个必要属性
1.2.1 bootstrap.servers
指定了kafka集群的连接字符串
1.2.2 key.deserializer 和 value.deserializer
使用指定的类把字节数组转换成java对象
1.2.3 group.id
非必须,指定了kafkaConsumer属于哪一个消费者群组,创建不属于任何一个群组的消费者也是可以的。
Properties props = new Properties();
props.put("bootstrap.servers","broker1:9092,broker2:9092");
props.put("group.id","CountryCounter");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String,String>(props);二 订阅主题
consumer.subscribe(Collections.singletonList("customerCountries"))要订阅所有与test相关的主题可以这样做:
consumer.subscribe("test.*");三 轮询
通过一个简单的轮询向服务器请求数据。案例如下:
try{
while(true){
ConsumerRecords<String, String> records = consumer.pol1(100);
for(ConsumerrRecord<String, String> record: records){
record.topic();
record.partition();
record.offset();
record.key();
record.value();
}
}
}轮询不只是获取数据,在第一次调用新消费者的poll()方法时,它会负责查找GroupCoordinator,然后加入群组,接受分配的分区,如果发生了再均衡,整个过程也是在轮询期间进行的。心跳也是从轮询里发送出去的。
四 消费者的配置
4.1 fetch.min.bytes
指定了消费者从服务器获取记录的最小字节数。
4.2 fetch.max.wait.ms
指定broker等待时间,默认是500ms. 如果fetch.min.bytes被设置为1M, fetch.max.wait.ms被设置为100ms , 那么Kafka在收到消费者的请求后,要么返回1MB数据,要么在100ms后返回所有的可用数据,就看哪个条件先满足。
4.3 max.partition.fetch.bytes
指定了服务器从每个分区里返回给消费者的最大字节数。默认值为1MB。
4.4 session.timeout.ms
指定了消费者在被认为死亡之前可以与服务器断开连接的时间,默认是3s。
4.5 auto.offset.reset
指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下改如何处理。
4.6 enable.out.commit
指定了消费者是否自动提交偏移量,默认为true。为了尽量避免出现重复数据和数据丢失,可以把它设置为false,由自己控制何时提交偏移量。
4.7 partition.assignment.strategy
根据给定的消费者和主题,决定哪些分区应该被分配给哪个消费者。Kafka有两种分配策略:
Range
该策略会把主题的若干个连续的分区分配给消费者。默认使用的这个。
RoundRobin
该策略把主题的所有分区逐个分配给消费者。
4.8 client.id
broker用它来标识从客户端发送过来的消息,通常被用在日志,度量指标和配额里。
4.9 max.poll.records
该属性用于控制单次调用call()方法能够返回的记录数量。
4.10 receive.buffer.bytes和send.buffer.bytes
socket在读写数据时用到的TCP缓冲区也可以设置大小。
五 提交和偏移量
把更新分区当前位置的操作叫做提交,消费者往一个叫做_consumer_offset的特殊主题发送消息,消息包含每个分区的偏移量。如果消费者一直处于运行状态,那么偏移量就没有什么用处,如果消费者发生崩溃或者有新的消费者加入群组,就回触发再均衡,完成均衡之后,每个消费者可能分配到新的分区,而不是之前处理的那个。为了能继续之前的工作,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的地方继续处理。
如果提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
5.1 自动提交
如果enable.auto.commit设为true,那么每过5s,消费者会自动把从poll()方法接收到的最大偏移量提交上去。提交时间间隔由auto.commit.interval.ms控制,默认5s.消费者每次在进行轮询的时候会检查是否该提交偏移量了,如果是,那么就会提交从上一次轮询返回的偏移量。
自动提交虽然方便,但并没有避免重复处理消息。
5.2 提交当前偏移量
把auto.commit.offset设置为false.让应用程序决定何时提交偏移量,并在发生再均衡时减少重复消息的数量。使用commitSync()提交偏移量最简单也最可靠。commitSync()将会提交由poll()返回的最新偏移量。要确保在当前轮询中,再处理完所有记录后要确保调用了commitSync();
5.3 异步提交
手动提交对提交请求做出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量,但如果发生了再均衡,会增加重复消息的数量。
这时候可以使用异步提交API,使用commitAsync()
5.4 同步和异步组合提交
try{
while(true){
ConsumerRecords<String, String> records = cosumer.poll(100);
for(ConsumerRecord<String, String> record: records){
// todo
}
consumer.commitAsync();
}
}catch(Exception e){
log.error("e",e);
}finally {
try{
consumer.commitSync();
}finally {
consumer.close();
}
}
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)