SparkStreaming读取Kafka数据源并写入Mysql数据库
SparkStreaming读取Kafka数据源并写入Mysql数据库一、实验环境本实验所用到的工具有kafka_2.11-0.11.0.2;zookeeper-3.4.5;spark-2.4.8;Idea;MySQL5.7什么是zookeeper?zookeeper 主要是服务于分布式服务,可以用zookeeper来做:统一配置管理,统一命名服务,分布式锁,集群管理。使用分布式系统就无法避免对节
SparkStreaming读取Kafka数据源并写入Mysql数据库
一、实验环境
本实验所用到的工具有
kafka_2.11-0.11.0.2;
zookeeper-3.4.5;
spark-2.4.8;
Idea;
MySQL5.7
什么是zookeeper?
zookeeper 主要是服务于分布式服务,可以用zookeeper来做:统一配置管理,统一命名服务,分布式锁,集群管理。使用分布式系统就无法避免对节点管理的问题(需要是实时感知节点的状态,对接点进行统一管理等等),而由于这些问题处理起来相对麻烦,提高了系统的复杂性,zookeeper作为一个可以通用解决这些问题的中间件就应运而生了。
Kafka是什么?
简单的说,Kafka是由Linkedin开发的一个分布式的消息队列系统(Message Queue),不只是消息队列系统,还是实时流处理应用和保存流数据。kafka开发的主要初衷目标是构建一个用来处理海量日志,用户行为和网站运营统计等的数据处理框架。在结合了数据挖掘,行为分析,运营监控等需求的情况下,需要能够满足各种实时在线和批量离线处理应用场合对低延迟和批量吞吐性能的要求。从需求的根本上来说,高吞吐率是第一要求,其次是实时性和持久性。
kafka与zookeeper:
一个典型的Kafka集群中包含若干Produce,若干broker(一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。kafka依赖于zookeeper。
二、准备工作
虚拟机上:配置好相应的环境后,启动zookeeper,再启动Kafka。
Windows上:在idea的maven项目的pom.xml文件添加kafka依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>2.4.8</version>
</dependency>
三、思路分析
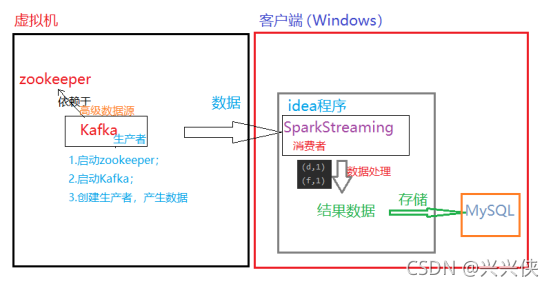
1.服务器端:在启动了zookeeper的情况下启动Kafka,并且启动Kafka的生产者作为产生数据的数据源。
2.客户端:通过在idea上编写SparkStreaming程序作为消费者来实时消费Kafka产生的数据,并对数据进行处理,即词频统计。
3.将客户端的结果数据存入MySQL数据库。
四、代码实现
1.测试
1.1 在idea上编写消费程序:
package scala.sparkstreaming
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
object KafkaDemo {
def main(args:Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("KafkaDemo").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "zyx:9092",//主机名称为zyx
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("test", "t100")//主题名称为test
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
val resultRDD: DStream[(String, Int)] = mapDStream.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _)
//打印
resultRDD.print()
//启动
streamingContext.start()
//等待计算结束
streamingContext.awaitTermination()
}
}
1.2 创建Kafka生产者:/training/kafka_2.11-0.11.0.2/bin/kafka-console-producer.sh --broker-list zyx:9092 --topic test(kafka-console-producer.sh在Kafka安装的bin目录下,我这里是绝对路径,我的主机名称为zyx,主题为test)

附加:
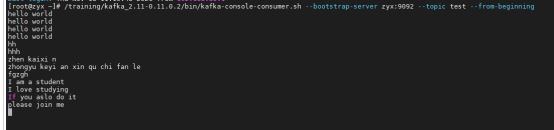
这里也可以在另外的一个终端创建Kafka的消费者:/training/kafka_2.11-0.11.0.2/bin/kafka-console-consumer.sh --bootstrap-server zyx:9092 --topic test --from-beginning
1.3 运行程序;
1.4 输入数据:

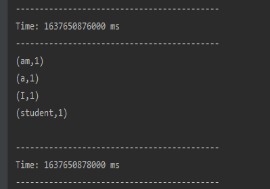
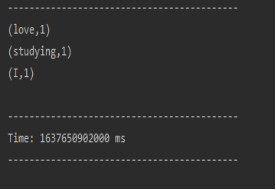
1.5 查看运行结果:
2.将结果数据写入MySQL数据库:
2.1 在之前的程序基础上加上数据写入数据库的代码,如下:
package scala.sparkstreaming
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
object KafkaDemo {
def main(args:Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("KafkaDemo").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "zyx:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("test", "t100")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value))
val resultRDD: DStream[(String, Int)] = mapDStream.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _)
//打印
resultRDD.print()
//把DStream保存到MySQL数据库中
resultRDD.foreachRDD(rdd => {
def func(records: Iterator[(String,Int)]) {
var conn: Connection = null
var stmt: PreparedStatement = null
try {
//定义MySQL是链接方式及其用户名和密码
val url = "jdbc:mysql://localhost:3306/llianxi?useUnicode=true&characterEncoding=UTF-8"//数据库为llianxi
val user = "root"
val password = "123456"
conn = DriverManager.getConnection(url, user, password)
records.foreach(p => {
val sql = "insert into zklog(information,count) values (?,?)"//在llianxi数据库中的zklog表,有information,count两列
stmt = conn.prepareStatement(sql);
stmt.setString(1, p._1.trim)
stmt.setInt(2,p._2.toInt)
stmt.executeUpdate()
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (stmt != null) {
stmt.close()
}
if (conn != null) {
conn.close()
}
}
}
val repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(func)
})
//启动
streamingContext.start()
//等待计算结束
streamingContext.awaitTermination()
}
}
2.2 运行idea程序,在服务端输入数据(如果生产者不在了,要重新创建,如果出现创建失败的原因,可能是Kafka挂掉了,重新启动就好):

2.3 查看MySQL表中数据:
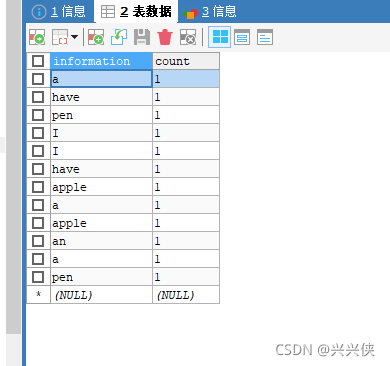
在真实的业务中,得到了这些数据,就可以通过数据库的查询语句来分析数据等。
参考博客:
https://blog.csdn.net/sujiangming/article/details/121391972?spm=1001.2014.3001.5501
zookeeper的单机安装
Kafka的安装与基本操作

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)