
MongoDB应用场景及选型(海量数据存储选型)
MongoDB应用场景及选型设计实践中,要基于需求、业务驱动架构,无论选用 DB/NoSQL, 一定是以需求为导向,最终数据存储方案必然是各种权衡的综合性设计。
文章目录
一、海量数据存储选型
什么情况下需要考虑库表拆分呢?单表数据量达多少时才建议分库分表?
实际上,是没有一个非常量化的指标来判定库表瓶颈的,因为每个系统的业务场景,查询复杂度都有不同。 但力有穷尽时,我们虽然可以尽量地从加从库读写分离、优化 sql、优化索引、复用连接等等方面进行优化,但总会有到达极限的时候的时候。
阿里巴巴开发手册建议是:
【推荐】单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
表主要看容量,很多经验表明 上千万后性能会有显著下降,因此,我们可以把表容量定在一半多一点,600w。
针对海量数据和高并发的主要解决方案
-
使用缓存;
很多数据的特点大多数呈现为“二八定律”:80%的业务访问集中在20%的数据上。
使用缓存的方式可以通过程序代码将数据直接保存到内存中,例如通过使用Map或者ConcurrentHashMap;另一种,就是使用缓存框架:Redis、Ehcache、Memcache等。 -
页面静态化技术;
可以将这些静态的HTML、CSS、JS、图片资源等放置在缓存服务器上或者CDN服务器上,一般使用最多的应该是CDN服务器或者Nginx服务器提供的静态资源功能。 -
数据库优化;
数据库优化的方式很多,常见的可以分为:数据库表结构优化、SQL语句优化、分区、分表、索引优化、使用存储过程代替直接操作等 。 -
延迟修改;
延迟修改是对于一些高并发的并且修改频繁修改的数据,在每次修改的时候首先将数据保存到缓存中,然后定时将缓存中的数据保存到数据库中,程序可以在读取数据时可以同时读取数据库中和缓存中的数据。 -
读写分离;
-
使用NoSQL和Hadoop等技术;
NoSQL是一种非结构化的非关系型数据库,由于其灵活性,突破了关系型数据库的条条框框,可以灵活的进行操作,另外,因为NoSQL通过多个块存储数据的特点,其操作大数据的速度也是相当快的 -
分布式部署数据库;
-
应用服务和数据服务分离;
应用服务器和数据库服务器进行分离的目的是为了根据应用服务器的特点和数据库服务器的特点进行底层的优化,这样的话能够更好的发挥每一台服务器的特性,数据库服务器当然是有一定的磁盘空间,而应用服务器相对不需要太大的磁盘空间,这样的话进行分离是有好处的,也能防止一台服务器出现问题连带的其他服务也不可以使用。 -
使用搜索引擎搜索数据库中的数据;
使用搜索引擎这种非数据库查询技术对网站应用的可伸缩分布式特性具有更好的支持。 -
进行业务的拆分;
例如一个大型的购物网站就会将首页、商铺、订单、买家、卖家等拆分为不通的子业务,一方面将业务模块分归为不同的团队进行开发,另外一方面不同的业务使用的数据库表部署到不通的服务器上,体现到拆分的思想,当一个业务模块使用的数据库服务器发生故障也不会影响其他业务模块的数据库正常使用。
存储选型的考虑要素
存储选型的目的还是为了我们的使用场景和用户服务,因此在选型前需要回答一些业务指标 & 技术指标方面的问题,以便于我们清楚存储选型的应用环境。
- 用户量:用户量预估多少?几百几万还是几亿?
- 数据量:数据量预估多少?日均增量能有多少?
- 读写偏好:数据是读多一些还是写多一些?
- 数据场景:强事务型还是分析型需求?
- 运行性能要求:并发量是多少?高峰、平均、低谷分别预估是多少?
设计实践中,要基于需求、业务驱动架构,无论选用 DB/NoSQL, 一定是以需求为导向,最终数据存储方案必然是各种权衡的综合性设计。
二、MongoDB应用场景及选型
什么是NoSQL
NoSQL:Not Only SQL ,本质也是一种数据库的技术。
NoSQL数据库在整个数据库领域的江湖地位已经不言而喻。在大数据时代,虽然RDBMS很优秀,但是面对快速增长的数据规模和日渐复杂的数据模型,RDBMS渐渐力不从心,无法应对很多数据库处理任务,这时NoSQL凭借易扩展、大数据量和高性能以及灵活的数据模型成功的在数据库领域站稳了脚跟。
主流nosql:MongoDB、Hbase、Redis
关于MongoDB
MongoDB 是一个高性能,开源,无模式的文档型数据库,开发语言是C++。它在许多场景下可用于替代统的关系型数据库或键/值存储方式。
MongoDB优点:
1)更高的写负载,MongoDB拥有更高的插入速度。
2)处理很大的规模的单表,当数据表太大的时候可以很容易的分割表。
3)高可用性,设置M-S不仅方便而且很快,MongoDB还可以快速、安全及自动化的实现节点 (数据中心)故障转移。
4)快速的查询,MongoDB支持二维空间索引,比如管道,因此可以快速及精确的从指定位置 获取数据。MongoDB在启动后会将数据库中的数据以文件映射的方式加载到内存中。如果内 存资源相当丰富的话,这将极大地提高数据库的查询速度。
5)非结构化数据的爆发增长,增加列在有些情况下可能锁定整个数据库,或者增加负载从而 导致性能下降,由于MongoDB的弱数据结构模式,添加1个新字段不会对旧表格有任何影响, 整个过程会非常快速。
mongdb性能测试
MongoDB分配的内存与吞吐率的测试
参考URL: https://blog.csdn.net/qq_32523587/article/details/82534391
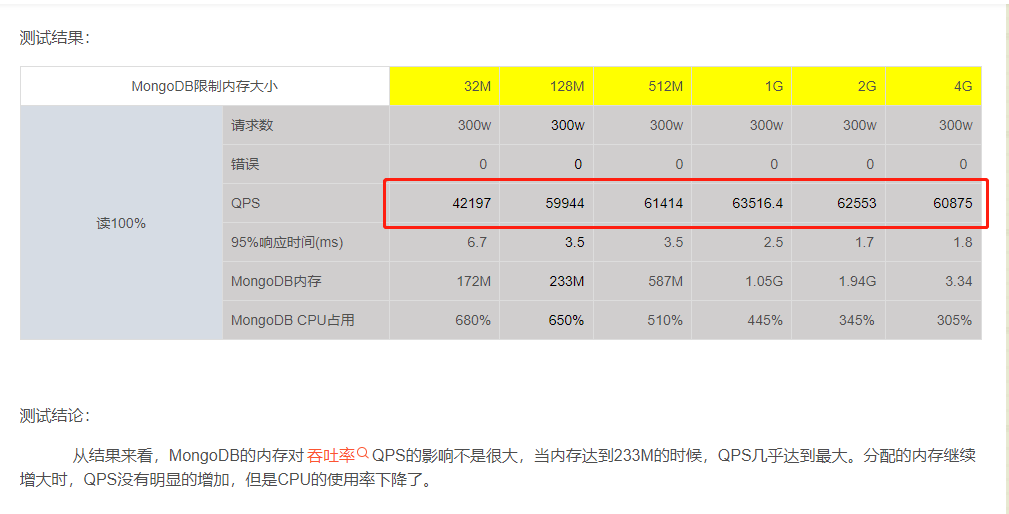 MongoDB的内存对吞吐率QPS的影响不是很大,当内存达到233M的时候,QPS几乎达到最大。分配的内存继续增大时,QPS没有明显的增加,但是CPU的使用率下降了。
MongoDB的内存对吞吐率QPS的影响不是很大,当内存达到233M的时候,QPS几乎达到最大。分配的内存继续增大时,QPS没有明显的增加,但是CPU的使用率下降了。
Mysql.8.0 与 MongoDB.4.2大数据量查询性能对比
Mysql.8.0 与 MongoDB.4.2大数据量查询性能对比
参考URL: https://blog.csdn.net/weixin_41715077/article/details/102879357
未亲自验证,直接贴原作者结论:
数据量增加到千万的时候,响应时间上升很多和吞吐量下降很多。需要分表或者分片。
(1)从平均响应时间来看,mongodb占据绝对优势。
(2)从吞吐量上来看,mongodb占据绝对优势。
关于mongodb占用内存过大的问题
关于mongodb占用内存过大的问题
参考URL: https://blog.csdn.net/ruoyunliufeng/article/details/83655026
mongo为了优化他的读写效率,将内存当做缓存,所以你读写次数越多,缓存就越大。
mongo从3.4开始,WiredTiger内部缓存默认使用下面较大的一个:
- 50%(RAM - 1 GB),或
- 256 MB。
例如,我是8G内存,那么最大缓存0.5*(8-1)=3.5G,mongo默认3.5G都是他的缓存。
解决方案: 修改(增加)cacheSizeGB配置。
什么场景用MongoDB?
原则上Oracle和MySQL能做的事情,MongoDB都能做(包括ACID事务)
- 亿级以上数据量
- 灵活表结构
- 高并发读
- 高并发写
- 跨区域集群
- 地里职位查询
- 聚合计算
NoSQL适合存储非结构化数据,如文章、评论:
1)这些数据通常用于模糊处理,如全文搜索、机器学习
2)这些数据是海量的,而且增长的速度是难以预期的,
3)根据数据的特点,NoSQL数据库通常具有无限(至少接近)伸缩性
4)按key获取数据效率很高,但是对join或其他结构化查询的支持就比较差
NoSQL 数据库都是通过牺牲了 ACID 特性来获取更高性能的,假设表数据有很强的事务特性需求,那么这类数据是不适合放在非关系型数据库。此外,选用 NoSQL 数据库时也要根据公司技术栈框架、业务特性、运维成本等多方面考虑。
MongDB 的使用场景很大程度上可以对标关系型数据库,但是比较适合处理那些没有 join、没有强一致性要求且表 Schema 会常变化的数据。
参考
参考URL: https://time.geekbang.org/course/detail/100040001-193615
MongoDB、Hbase、Redis 的优劣势及应用场景介绍
参考URL: https://zhuanlan.zhihu.com/p/271098279
MongoDB 优缺点
参考URL: https://blog.csdn.net/qq_32364939/article/details/79654377
大数据时代的海量数据存储、和高并发解决方案总结
参考URL: https://blog.csdn.net/qq_22473611/article/details/91039843
[推荐阅读]数据库存储选型经验总结
参考URL:https://www.modb.pro/db/246025

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)