redis---分布式锁存在的问题及解决方案(Redisson)
系列文章目录提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加例如:第一章 Python 机器学习入门之pandas的使用提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录系列文章目录前言一、pandas是什么?二、使用步骤1.setNx2.setNX NP3.锁超时问题3.1过期时间如何设置3.2锁的续签4.增加锁的可重入性2.读入数据总结前言提示:这里可以添
文章目录
1.setNx
初识分布式锁大多数人都是从setNx命令开始的,我们很轻易的就可以借助setNx命令及redis的特性创建一个简陋的分布式锁。释放锁时只需要直接删除即可。
存在问题:
- 客户端所在节点崩溃,无法正确释放锁
- 业务逻辑异常,无法执行 DEL指令
- 如何保证锁不被别的应用程序释放
上述只是列出的一小部分问题,实际还存在很多漏洞没有展示出来。我们循序渐进一点一点啃先解决以上几个问题。
2.set NX NP
对于出现异常锁无法释放问题,我们很容易可以想到能够通过设置一个过期时间来进行处理。比如像订单30分钟未支付默认放弃此订单这样。这里采用常规的SETNX + EXPIRE 为两个单独的命令会缺乏原子性,想象一下如果加锁成功但是客户端节点在执行EXPIRE 命令时突然宕机了。这种情况锁将会无法主动释放。
结局方案:
好在redis自2.6.X 之后,官方拓展了 SET 命令的参数,满足了当 key 不存在则设置 value,同时设置超时时间的语义,并且满足原子性。
SET resource_name random_value NX PX 10000
- NX:表示只有 resource_name 不存在的时候才能 SET 成功,从而保证只有一个客户端可以获得锁;
- PX 10000:表示这个锁有一个 10 秒自动过期时间。
此时虽然初步解决了锁无法释放的问题,但是又打开新的缺口。比如我们将时间设为了500ms,但是此时突然网络抖动程序执行时间被大大延长我们执行了2s才结束。但是,锁已经被提前释放了。这样就又会产生新的冲突。
3.如何保障自己的锁只能自己来释放?
假如有以下情景:
客户 1 获取锁成功并设置设置 30 秒超时;
客户 1 因为一些原因导致执行很慢(网络问题、发生 FullGC……),过了 30 秒依然没执行完,但是锁过期「自动释放了」;
客户 2 申请加锁成功;
客户 1 执行完成,执行 DEL 释放锁指令,这个时候就把客户 2 的锁给释放了。
最直观能想到的方案就是:在执行 DEL 指令的时候,我们要想办法检查下这个锁是不是自己加的锁再执行删除指令。
我们必须保证A上的锁只有A能解锁,如果任何人都可以随意解锁那么锁的存在就没有任何意义。我们在设置锁时可以为每个锁打上一个独属于自己的标签。就像车牌号一样,可以帮我们快速的分辨是不是自己的车。否则你拿钥匙怼一百遍也是徒劳的。

假设伪代码如下:
// 比对 value 与 唯一标识
if (redis.get("lock:9999999").equals(random_value)){
redis.del("lock:99999999"); //比对成功则删除
}
我们可以直观的看到通过常规命令的方式,每一条指令都是独立的又会存在原子性问题。这个问题我们先不考虑,看看redisson是如何实现的:
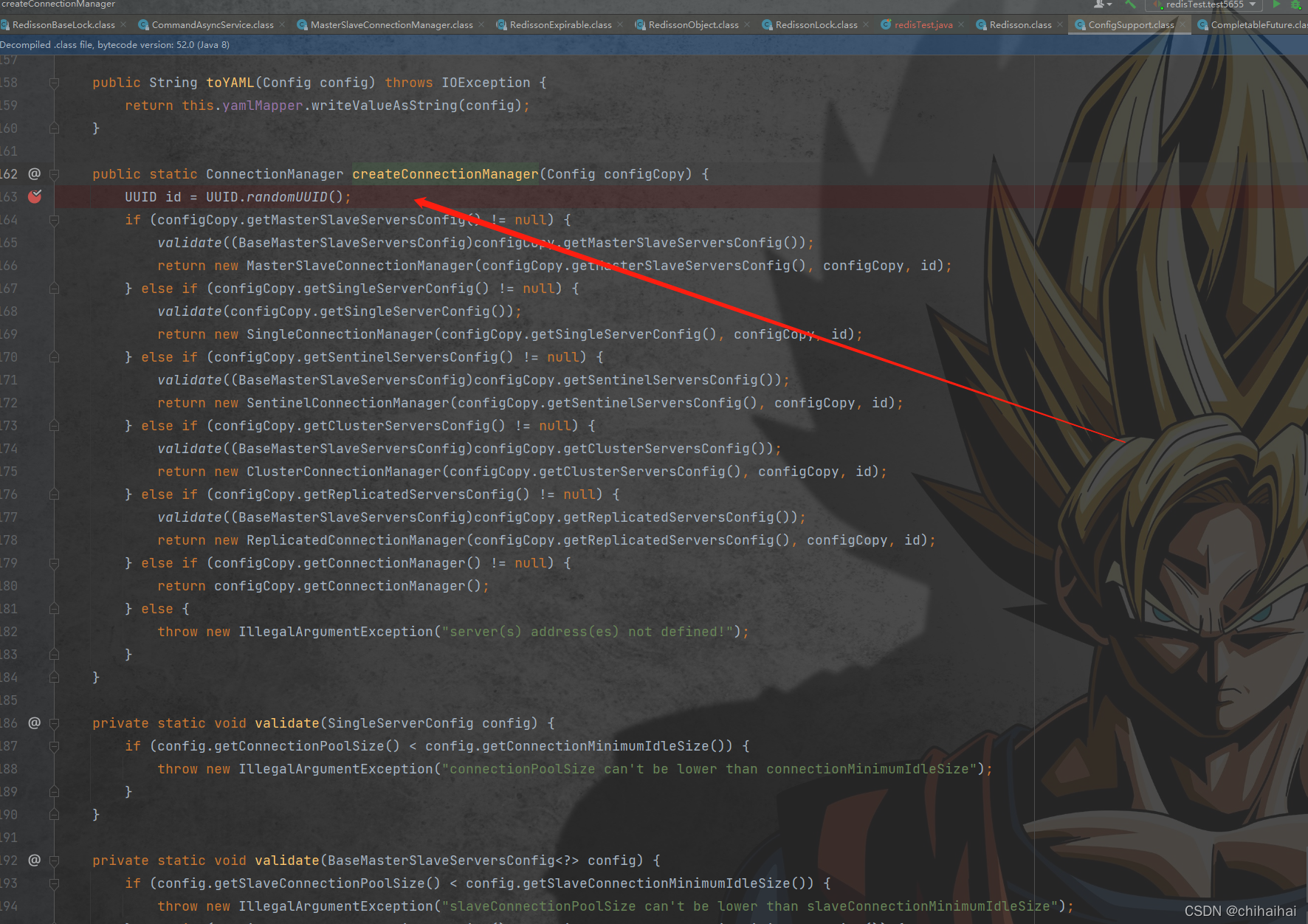
redisson默认会生成一个长度为36位的随机字符串作为唯一标识,并且加入了"_“与”-"字符最大程度保证了不会产生重复的可能性。
UUID:ThreadId
后面的:1为,当前线程id。在解锁前会对key进行判断,如果一致证明是自己上的锁才能删除保证了锁不被其它线程解锁的可能性。官方文档也是这么说的:https://redis.io/topics/distlock这个方案已经相对完美,我们用的最多的可能就是这个方案。了。
4.如何命令的原子性?
在进行redis锁操作时我们必须通过 Lua 脚本来实现,这样判断和删除的过程就是原子操作了。
// 获取锁的 value 与 ARGV[1] 是否匹配,匹配则执行 del
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
5.锁超时问题
5.1过期时间如何设置
延续上面的问题,我们是否可以用最简单的方式来进行解决呢?老子直接设置1个小时超时时间,我就不信还不够用。理论上不是不可行,但是如果节点宕机了重新拉起面对重多的key我们难道要一个个人肉删除么。显然这种暴露手段是不太可取的。那么锁的超时时间怎么计算合适呢?
这个时间不能瞎写,一般要根据在测试环境多次测试,然后压测多轮之后,比如计算出平均执行时间 200 ms。
那么锁的超时时间就放大为平均执行时间的 3~5 倍。
为啥要放放大呢?
因为如果锁的操作逻辑中有网络 IO 操作、JVM FullGC 等,线上的网络不会总一帆风顺,我们要给网络抖动留有缓冲时间。
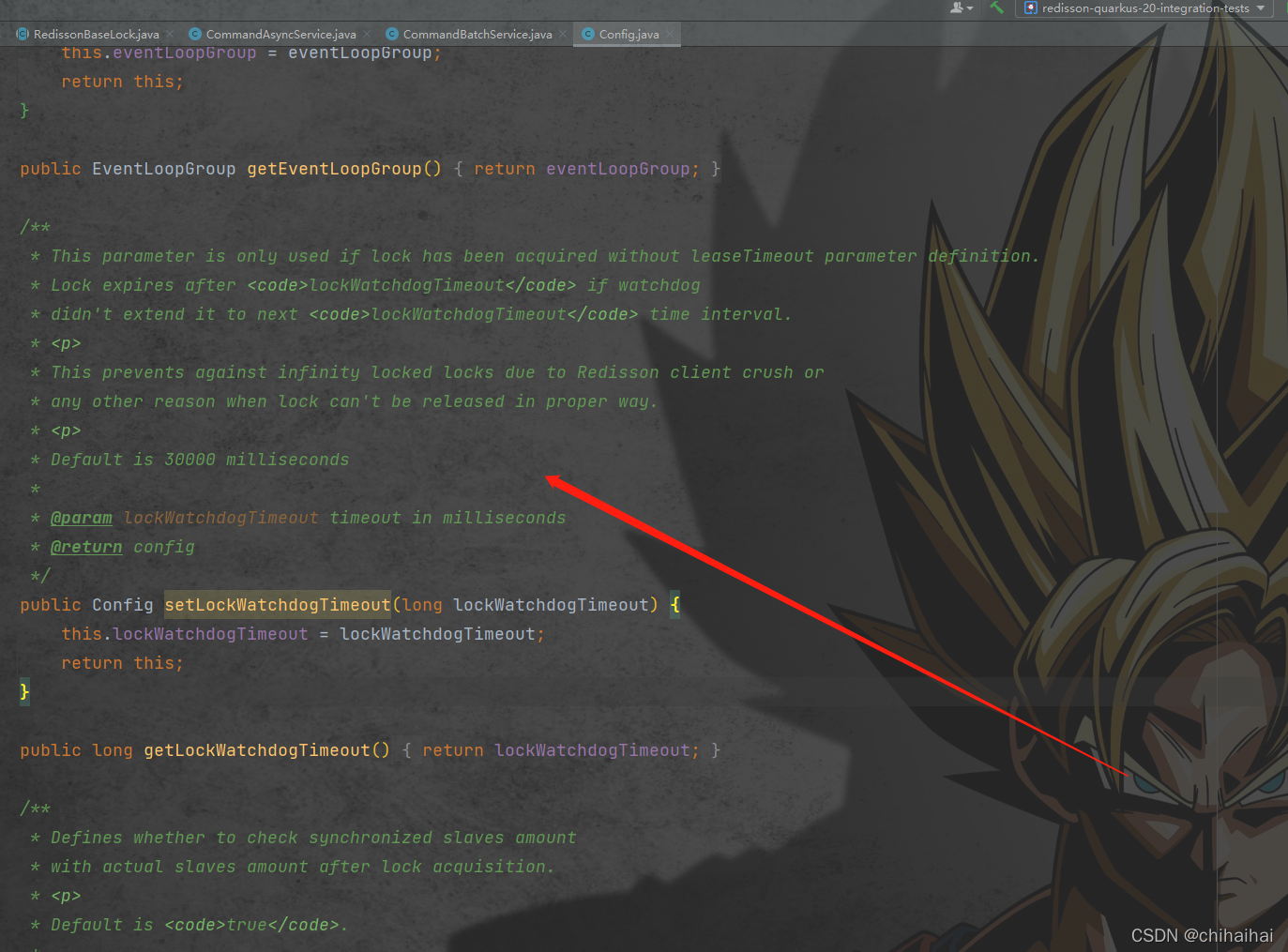
此时我们上面所出现的问题还没有真正解决,即使我们预留了一定的波动空间。但是并不能保证程序一定能在我们规定阈值内执行完毕。还是无法保证锁不被提前释放。在redisson中默认的过期时间是30000ms。
5.2锁的续签(守护线程)
这里我们可以采取一种常见的解决方案,其实在我们使用JWT的过程中就有类似场景。如果一个用户在令牌即将过期的半小时内依然进行了相关操作,我们就可以认为此用户可能不会立即结束操作。为了避免用户的重复认真影响体验,我们会自动延长token的时间这样动态的调整过期时间达到更好的用户体验。
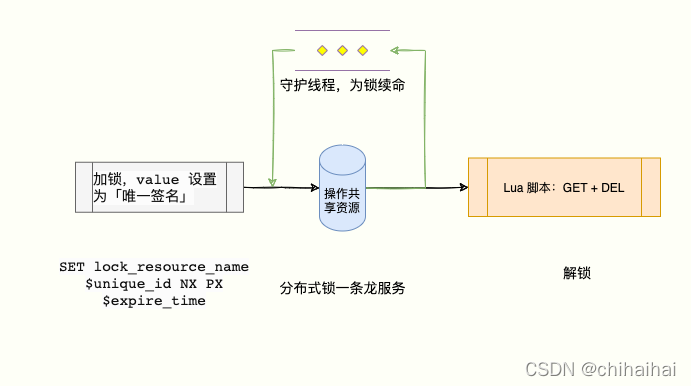
显然我们可以学习上述解决方案,我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁「续航」。加锁的时候设置一个过期时间,同时客户端开启一个「守护线程」,定时去检测这个锁的失效时间。如果快要过期,但是业务逻辑还没执行完成,自动对这个锁进行续期,重新设置过期时间。上述几点Redisson都已经帮我们提供了现成的实现不需要重复造轮子了。在使用分布式锁时,它就采用了「自动续期」的方案来避免锁过期,这个守护线程我们一般也把它叫做「看门狗」线程。redisson默认过期时间是30s,看门狗会在10s后检测当前锁是否已经执行完毕,如果当前锁还没有释放就会对其进行续签。将ttl重置为30s。
补充:当时没有考虑到这个问题,如果线程一直运行redission是否会无限续签导致锁无限期被占用?
答案:是的。
RReadWriteLock lock = redissonClient.getReadWriteLock("lock:test:999");
try {
boolean isHold = lock.writeLock().tryLock(60, 120, TimeUnit.SECONDS);
if (isHold){
mongoOperations.updateFirst(Query.query(where(ID).is(aggregate.getCommentId().getId())), update, CommentPo.class);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
lock.writeLock().forceUnlock();
}
我们考虑的这个点比较极端,其实这个问题的根源与锁无关。本身在业务没执行完毕的形况下锁就不应该被释放,如果出现极端超长时间占用锁的情况我们应该通过例如aop监控等来找出接口响应时间过久的原因从根本上解决问题。如果一定想要看门狗不无限进行续签可以如上述进行配置,给予一个自定义的最大持有时间(watchDog 只有在未显示指定加锁时间时才会生效)。当然这是强烈不推荐的做法。
到这里看起来已经相对完善了,但是我们永远要问自己是否已经做到最好?
public synchronized void a() {
b();
}
public synchronized void b() {
// pass
}
假设在某个请求中,需要获取一颗满足条件的菜单树或者分类树。我们以菜单为例,这就需要在接口中从根节点开始,递归遍历出所有满足条件的子节点,然后组装成一颗菜单树。需要注意的是菜单不是一成不变的,在后台系统中运营同学可以动态添加、修改和删除菜单。为了保证在并发的情况下,每次都可能获取最新的数据,这里可以加redis分布式锁。加redis分布式锁的思路是对的。但接下来问题来了,在递归方法中递归遍历多次,每次都是加的同一把锁。递归第一层当然是可以加锁成功的,但递归第二层、第三层…第N层,不就会加锁失败了?
public void fun(int level,String lockKey,String requestId){
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(level<=10){
this.fun(++level,lockKey,requestId);
} else {
return;
}
}
return;
} finally {
unlock(lockKey,requestId);
}
}
如果你直接这么用,看起来好像没有问题。但最终执行程序之后发现,等待你的结果只有一个:出现异常。因为从根节点开始,第一层递归加锁成功,还没释放锁,就直接进入第二层递归。因为锁名为lockKey,并且值为requestId的锁已经存在,所以第二层递归大概率会加锁失败,然后返回到第一层。第一层接下来正常释放锁,然后整个递归方法直接返回了。那么这个问题该如何解决呢?
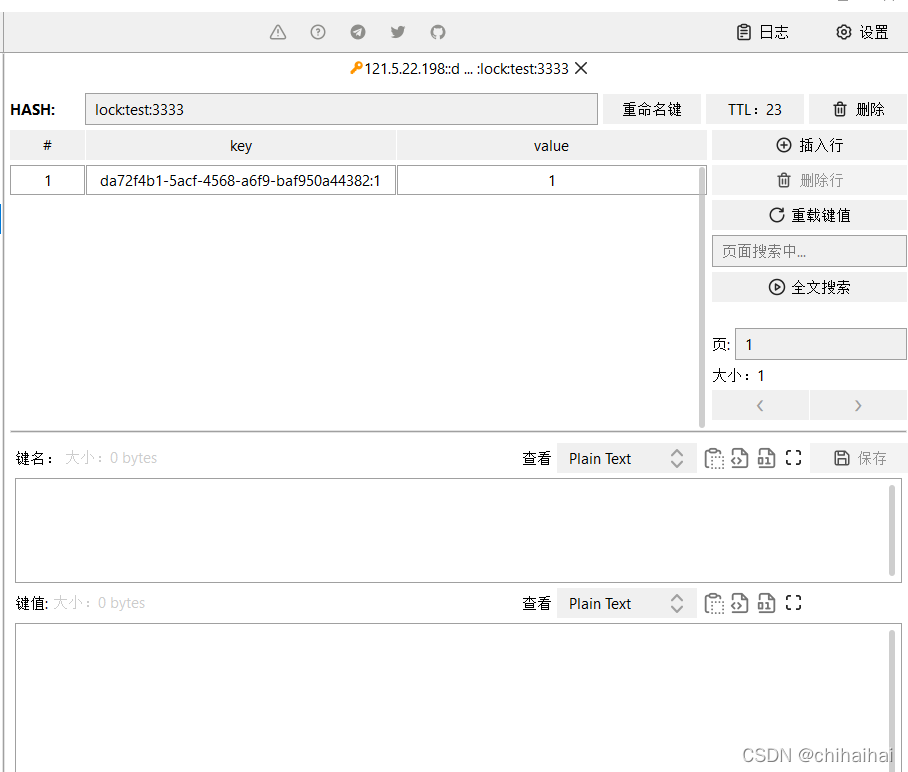
6.增加锁的可重入性(hincrby)
我们常规使用的Redisson 分布式锁实现方案,就是通过 Redis Hash 来实现可重入锁。当线程拥有锁之后,往后再遇到加锁方法,直接将加锁次数加 1,然后再执行方法逻辑。退出加锁方法之后,加锁次数再减 1,当加锁次数为 0 时,锁才被真正的释放。可以看到可重入锁最大特性就是计数,计算加锁的次数。所以当可重入锁需要在分布式环境实现时,我们也就需要统计加锁次数。我们可以使用 Redis hash 结构实现,key 表示被锁的共享资源, hash 结构的 fieldKey 的 value 则保存加锁的次数。
if (redis.call('exists', KEYS[1]) == 0)
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
=======================================================================================================
if (redis.call('exists', lock:test:333) == 0)
// 重入将key值+1
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
7.大量失败请求自旋锁的必要性
上面的加锁方法看起来好像没有问题,但如果你仔细想想,如果有1万的请求同时去竞争那把锁,可能只有一个请求是成功的,其余的9999个请求都会失败。
在秒杀场景下,会有什么问题?
答:每1万个请求,有1个成功。再1万个请求,有1个成功。如此下去,直到库存不足。这就变成均匀分布的秒杀了,跟我们想象中的不一样。
如何解决这个问题呢?
此外,还有一种场景:
比如,有两个线程同时上传文件到sftp,上传文件前先要创建目录。假设两个线程需要创建的目录名都是当天的日期,比如:20210920,如果不做任何控制,
直接并发的创建目录,第二个线程必然会失败。
这时候有些朋友可能会说:这还不容易,加一个redis分布式锁就能解决问题了,此外再判断一下,如果目录已经存在就不创建,只有目录不存在才需要创建。
伪代码如下:
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
一切看似美好,但经不起仔细推敲。来自灵魂的一问:第二个请求如果加锁失败了,接下来,是返回失败,还是返回成功呢?
主要流程图如下:
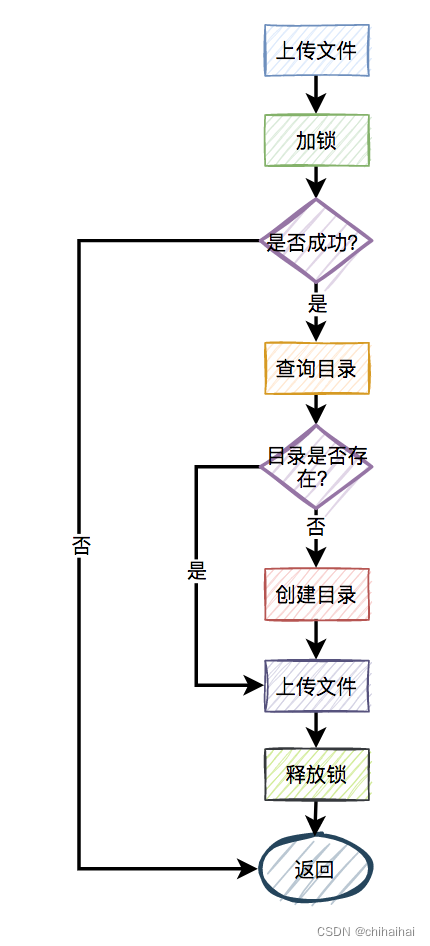
显然第二个请求,肯定是不能返回失败的,如果返回失败了,这个问题还是没有被解决。如果文件还没有上传成功,直接返回成功会有更大的问题。头疼,到底该如何解决呢?
try {
Long start = System.currentTimeMillis();
while(true) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
long time = System.currentTimeMillis() - start;
if (time>=timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally{
unlock(lockKey,requestId);
}
return false;
在规定的时间,比如500毫秒内,自旋不断尝试加锁(说白了,就是在死循环中,不断尝试加锁),如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。这里redisson也早早帮我们想到了,我们只需要在创建锁的时候指定自旋锁即可。
RLock lock = redissonClient.getSpinLock("lock:test:999");
8.读写锁进一步提升锁效率
众所周知,加锁的目的是为了保证,在并发环境中读写数据的安全性,即不会出现数据错误或者不一致的情况。但在绝大多数实际业务场景中,一般是读数据的频率远远大于写数据。而线程间的并发读操作是并不涉及并发安全问题,我们没有必要给读操作加互斥锁,只要保证读写、写写并发操作上锁是互斥的就行,这样可以提升系统的性能。我们以redisson框架为例,它内部已经实现了读写锁的功能。
读锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
//业务操作
} catch (Exception e) {
log.error(e);
} finally {
rLock.unlock();
}
写锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
//业务操作
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}
将读锁和写锁分开,最大的好处是提升读操作的性能,因为读和读之间是共享的,不存在互斥性。而我们的实际业务场景中,绝大多数数据操作都是读操作。所以,如果提升了读操作的性能,也就会提升整个锁的性能。
9.主从架构带来的问题及如何选择redis部署方式
我们通常使用「Cluster 集群」或者「哨兵集群」的模式部署保证高可用。这两个模式都是基于「主从架构数据同步复制」实现的数据同步,而 Redis 的主从复制默认是异步的。
我们试想下如下场景会发生什么问题:
1.客户端 A 在 master 节点获取锁成功。
2.还没有把获取锁的信息同步到 slave 的时候,master 宕机。
3.slave 被选举为新 master,这时候没有客户端 A 获取锁的数据。
4.客户端 B 就能成功的获得客户端 A 持有的锁,违背了分布式锁定义的互斥。
虽然这个概率极低,但是我们必须得承认这个风险的存在。其实不管是基于redis中比较著名的redlock实现方案或者单机还是主从,再或者zookeeper 实现都有各自的局限性。
分布式系统设计是实现复杂性和收益的平衡,既要尽可能地安全可靠,也要避免过度设计。Redlock 确实能够提供更安全的分布式锁,但也是有代价的,需要更多的 Redis 节点。同时其也并不是百分百安全的依然存在时钟一致性等问题在实际业务中,一般使用基于单点的 Redis 实现分布式锁就可以满足绝大部分的需求,偶尔出现数据不一致的情况,可通过人工介入回补数据进行解决,正所谓“技术不够,人工来凑”!。
没有任何一种方案可以保证CAP三个方向都满足。redis是AP的,zookeeper是CP的。如果你的实际业务场景,更需要的是保证数据一致性那么可以使用zookeeper,它是基于磁盘的,性能可能没那么好,但数据一般不会丢。如果你的实际业务场景,更需要的是保证数据高可用性。那么请使用AP类型的分布式锁,比如:redis,它是基于内存的,性能比较好,但有丢失数据的风险。其实,在我们绝大多数分布式业务场景中,使用redis分布式锁就够了,真的别太较真。因为数据不一致问题,可以通过最终一致性方案解决。但如果系统不可用了,对用户来说是暴击一万点伤害。
总结:
我个人更推崇基于redisson实现的redis哨兵模式方案,对于要求数据绝对正确的业务,在资源层一定要做好「兜底」,设计思路可以借鉴 fencing token 的方案来做。
这个模型流程如下:
客户端在获取锁时,锁服务可以提供一个「递增」的 token
客户端拿着这个 token 去操作共享资源
共享资源可以根据 token 拒绝「后来者」的请求
这样一来,无论 NPC 哪种异常情况发生,都可以保证分布式锁的安全性,因为它是建立在「异步模型」上的。而 Redlock 无法提供类似 fencing token 的方案,所以它无法保证安全性。
- N:Network Delay,网络延迟
- P:Process Pause,进程暂停(GC)
- C:Clock Drift,时钟漂移

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)