Redis数据结构之Zset
一、zset数据结构相比于set,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。zset有两种不同的实现,分别是zipList和skipList。zipList:满足以下两个条件:[score,value]键值对数量少于128个;每个元素的长度小于64字节;skipList:不满足以上两个条件
一、zset数据结构
相比于set,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。
zset有两种不同的实现,分别是zipList和skipList。
zipList:
满足以下两个条件:
- [score,value]键值对数量少于128个;
- 每个元素的长度小于64字节;
skipList:
不满足以上两个条件时使用跳表(组合了hash和skipList)
- hash用来存储value到score的映射,这样就可以在O(1)时间内找到value对应的分数;
- skipList按照从小到大的顺序存储分数;
- skipList每个元素的值都是[score,value]对
Redis 中 zset 不是单一结构完成,是跳表和哈希表共同完成。
实现方式:Redis sorted set的内部使用HashMap和跳跃表(skipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
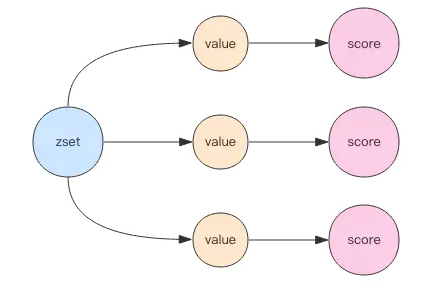
使用zipList的示意图如下所示:
使用跳表时的示意图:
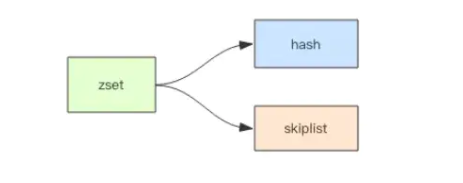

zset 结构中,既支持按单个元素查询,又支持范围查询。
二、跳表skipList
什么是跳表?
对链表进行改造,在链表上建索引,即每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引。这种链表加多级索引的结构,就是跳表。

跳表的特点:
- 由许多层结构组成。
- 每一层都是一个有序的链表。
- 最底层 (Level 1) 的链表包含所有元素。
- 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
跳表的优点:
跳表可以保证增、删、查等操作时的时间复杂度为O(logN),且维持结构平衡的成本比较低,完全依靠随机。而二叉查找树在多次插入删除后,需要Rebalance来重新调整结构平衡。
跳表的缺点:
跳表占用的空间比较大(多级索引),其实就是一种空间换时间的思想。
1.跳表的查找
跳表的查找会从顶层链表的头部元素开始,然后遍历该链表,直到找到元素大于或等于目标元素的节点,如果当前元素正好等于目标,那么就直接返回它。如果当前元素小于目标元素,那么就垂直下降到下一层继续搜索,如果当前元素大于目标或到达链表尾部,则移动到前一个节点的位置,然后垂直下降到下一层。
2.跳表的插入
为跳表插入数据,首先需要找到插入的位置,然后执行插入操作。
可以通过图看一下插入的过程:
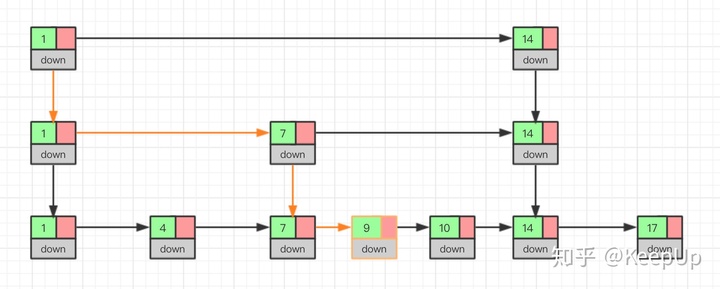
如果我们不停的向跳表中插入元素,就可能会造成两个索引点之间的结点过多的情况。结点过多的话,我们建立索引的优势也就没有了。所以我们需要维护索引与原始链表的大小平衡,也就是结点增多了,索引也相应增加,避免出现两个索引之间结点过多的情况,查找效率降低。
跳表是通过一个随机函数来维护这个平衡的,当我们向跳表中插入数据的的时候,我们可以选择同时把这个数据插入到索引里,那我们插入到哪一级的索引呢,这就需要随机函数,来决定我们插入到哪一级的索引中。
这样可以很有效的防止跳表退化,而造成效率变低。
3.跳表的删除
- 自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
- 删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
总体上,跳跃表删除操作的时间复杂度是O(logN)。
整个删除过程,可以简化理解为:先找到,断关联,删内存
4.跳表的更新
当我们调用zadd方法时,如果对应的value不存在,那就是插入过程。如果这个value 已经存在了,只是调整一下 score 的值,那就需要走一个更新的流程。假设这个新的score 值不会带来排序位置上的改变,那么就不需要调整位置,直接修改元素的 score 值就可以了。但是如果排序位置改变了,那就要调整位置。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)