大数据技术---流计算(Storm)
一、流计算概述流数据:实时产生的数据,并且实时不断地像流水一样到达。流数据特征:1、数据快速持续到达,潜在大小也许是无穷无尽的。2、数据来源众多,格式复杂。3、数据量大,但是不是十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储。4、注重数据的整体价值,不过分关注个别数据。5、数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。数据类型:静态数据和流数据(动态计算)。流计算
一、流计算概述
流数据:实时产生的数据,并且实时不断地像流水一样到达。
流数据特征:
1、数据快速持续到达,潜在大小也许是无穷无尽的。
2、数据来源众多,格式复杂。
3、数据量大,但是不是十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储。
4、注重数据的整体价值,不过分关注个别数据。
5、数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。
数据类型:静态数据和流数据(动态计算)。
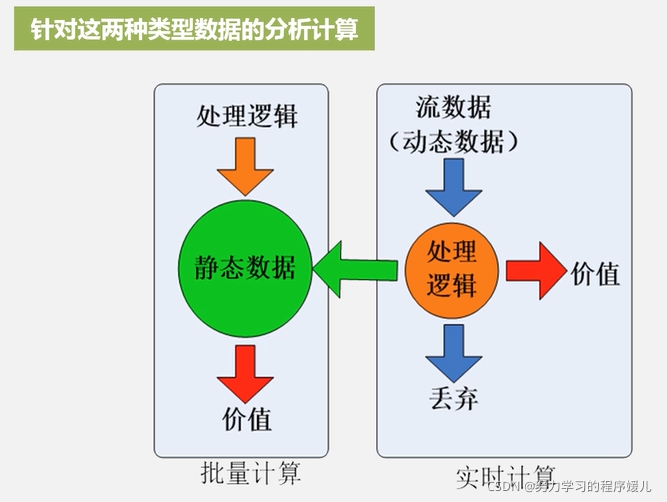
流计算:实时获取来自不同数据源的海量数据经过实时分析处理,获取有价值的信息。
流计算基本理念:
1、数据的价值随着时间的流逝而降低。如用户点击流。
2、当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。
流计算系统要求:
1、高性能
2、海量式
3、实时性
4、分布式
5、易用性
6、可靠性
二、流计算处理流程
流计算的处理流程:
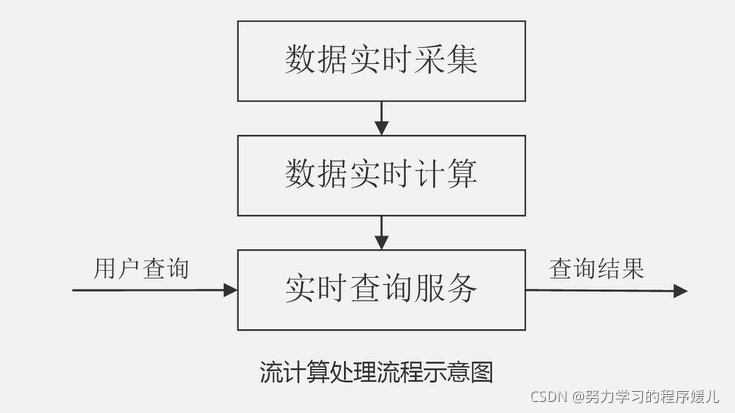
1、数据实时采集阶段
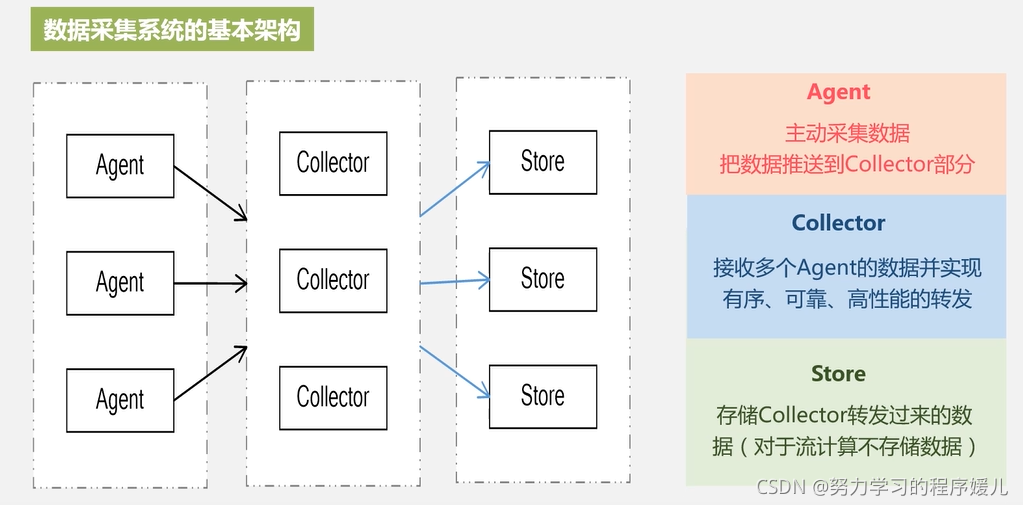
通常采集多个数据源的海量数据,需要保证实时性、低延迟与稳定可靠。
开源分布式日志采集系统:scibe、kafka、flume。
2、数据实时计算
数据实时计算阶段对采集的数据进行实时的分析和计算并反馈实时结果。数据经流处理系统处理后的数据,可以流出给下一个环节继续处理,可以把相关结果处理完以后就丢弃掉,或者存储到相关的存储系统中去。
3、实时查询服务
经过流计算框架得出的结果让用户能够进行实时的查询展示和存储。用户需要主动去查询,而流处理计算结果,会不断的去更新,不断的实时推动给用户。
流处理系统和传统的数据处理系统的区别?
1、流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据。
2、用户通过流处理系统获取的一般是实时结果,而传统的数据处理方式获取的都是过去某一个历史时刻的快照。
3、流处理系统不需要用户主动发出查询,它会实时地把生成的查询结果不断的推动给用户。
三、Storm
1、storm特点
(1)整合性
(2)简易的API
(3)可扩展性
(4)可靠的消息处理
(5)支持各自编程语言
(6)快速部署
(7)免费开源
2、storm设计思想
storm主要术语:
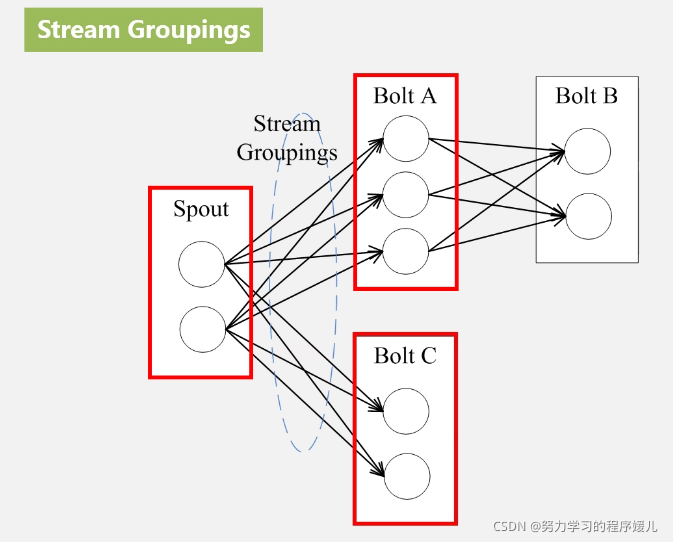
(1)stream:每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型。tuple是一个value list(值列表)。

(2)spout:stream的源头。spout会从外部数据源读取数据,然后封装成tuple形式,发送到stream中。spout是一个主动的角色,在接口内部有个nextTuple函数,storm框架会不停的调用该函数。
(3)bolt:stream的状态转换过程抽象为bolt。bolt可以处理tuple,也可以将处理后的tuple作为新的stream发送给其他bolt。bolt可以执行过滤、函数操作、join、操作数据库等任何操作。bolt是被动的角色,接口中有一个execute(Tuple tuple)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
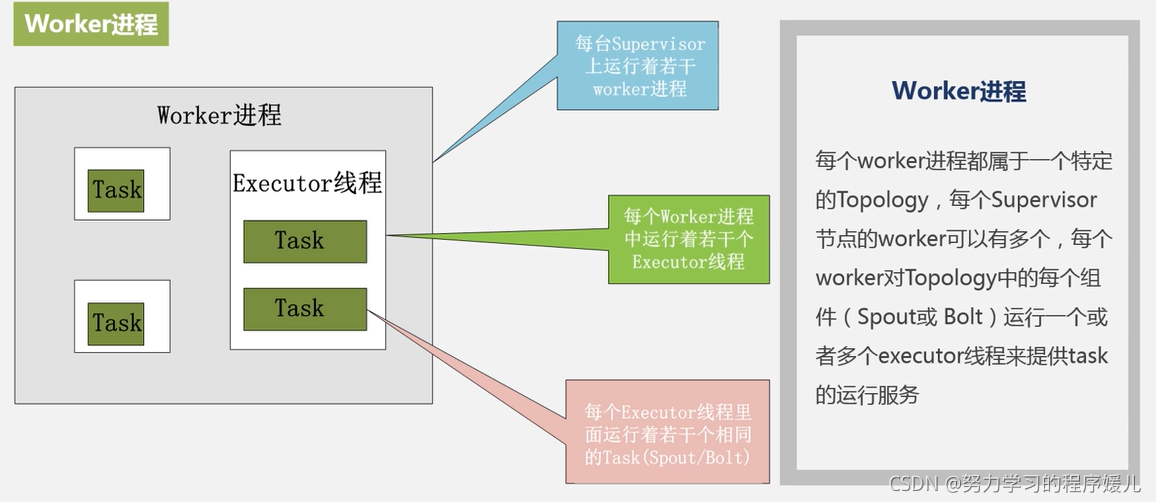
(4)topology:每一个组件都是并行运行的。bolt中包含多个task,可以在不同机器节点并行地处理,topology中可以指定每个组件的并行度。
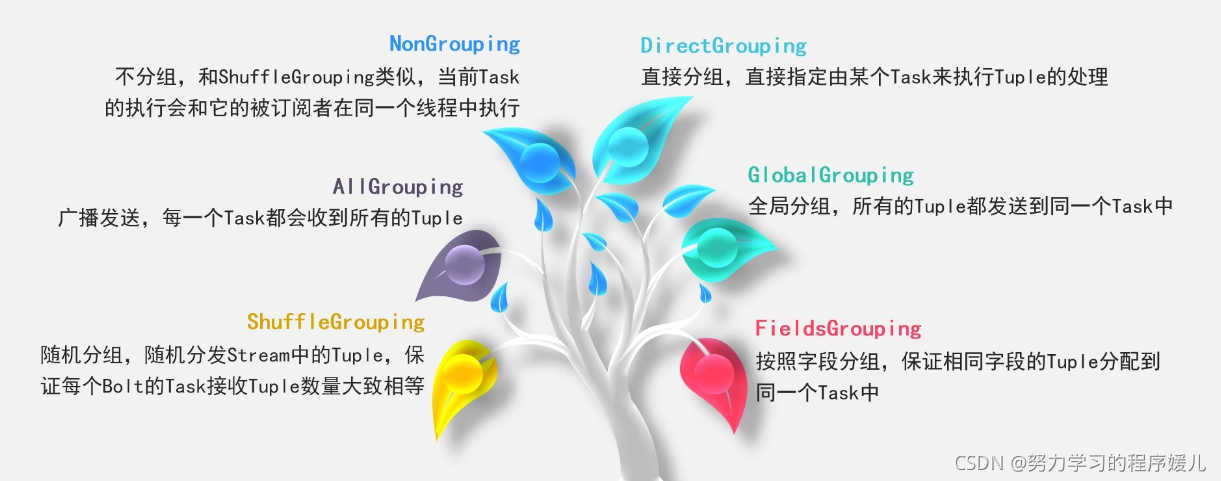
(5)stream groupings:
3、storm框架设计

4、storm工作流程
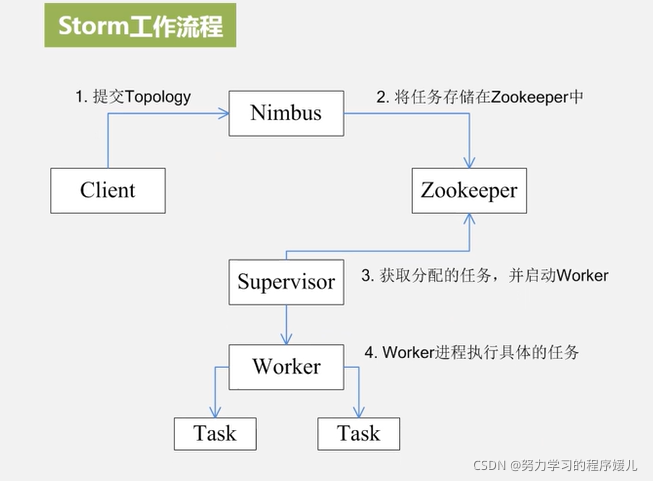
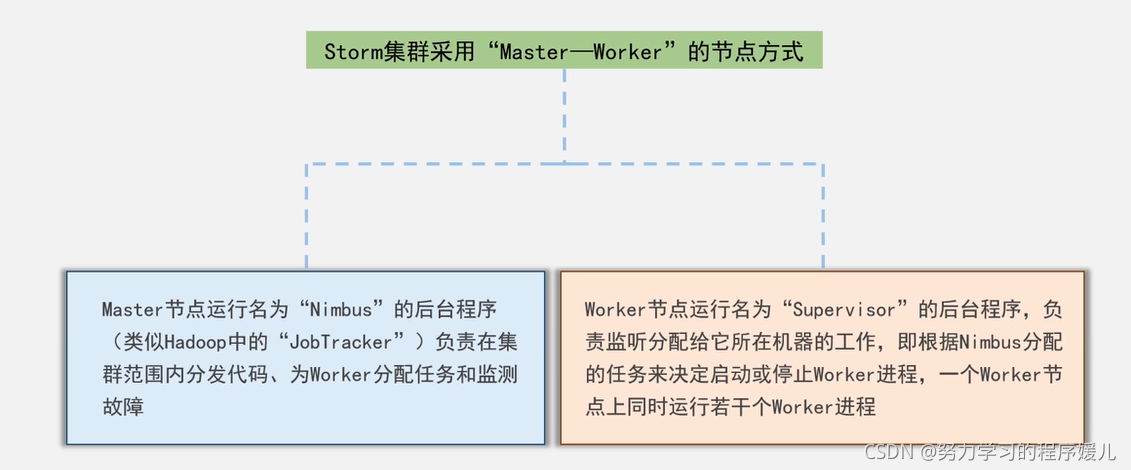
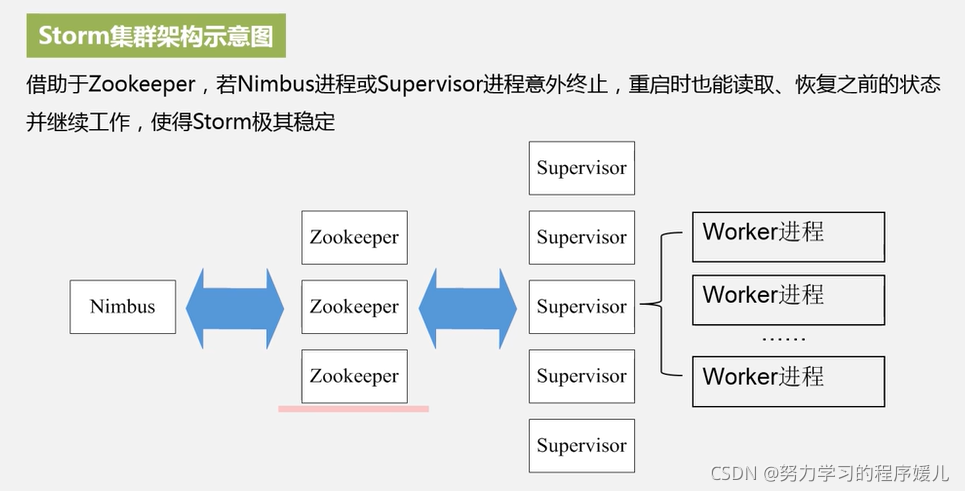
(1)所有的topology任务的提交必须在storm客户端节点上进行,提交后,由nimbus节点分配给其他supervisor节点进行处理。
(2)nimbus节点首先将提交的topology进行分片,分成一个个task,分配给相应的supervisor,并将task和supervisor相关的信息提交到zookeeper集群上。
(3)supervisor会去zookeeper集群上认领自己的task,通知自己的worker进程进行task的处理。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)