zookeeper介绍
Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
1、简介
Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储, Zookeeper 作用主要是用来维护和监控存储的数据的状态变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理
简单的说,zookeeper = 文件系统 + 通知机制。
2、应用场景
-
命名服务:
在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现。
这个主要是作为分布式命名服务,通过调用zk的create node api,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。 -
配置管理
现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。 -
集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。
新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了,对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。 -
负载均衡
把ZooKeeper作为一个服务的注册中心,在其中登记每个服务,每台服务器知道自己是属于哪个服务,在服务器启动时,自己向所属服务进行登记,这样,一个树形的服务结构就呈现出来了,根据这样一个树形服务结构,RPC服务的消费者可以很轻松的找到它所需求的服务信息。同时在一个service节点下可以注册多个业务逻辑相同的服务,以实现负载均衡。zookeeper实现负载均衡其实原理很简单,zookeeper 的数据存储类似于liunx的目录结构。首先建立servers节点,并建立监听器监视servers子节点的状态(用于在服务器增添时及时同步当前集群中服务器列表)。
在每个服务器启动时,在servers节点下建立子节点worker server(可以用服务器地址命名),并在对应的字节点下存入服务器的相关信息。这样,我们在zookeeper服务器上可以获取当前集群中的服务器列表及相关信息,可以自定义一个负载均衡算法,在每个请求过来时从zookeeper服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求。
-
分布式锁
分布式锁是控制分布式系统或不同系统之间共同访问共享资源的一种锁实现,如果不同的系统或同一个系统的不同主机之间共享了某个资源时,往往需要互斥来防止彼此干扰来保证一致性。
3、zookeeper的基本概念
3.1、角色介绍
ZooKeeper中包含Leader、Follower和Observer三个角色;
通过一次选举过程,被选举的机器节点被称为Leader,Leader机器为客户端提供读和写服务;
Follower和Observer是集群中的其他机器节点,唯一的区别就是:Observer不参与Leader的选举过程。
Leader主要有三个功能:
- 恢复数据;
- 维持与follower的心跳,接收follower请求并判断follower的请求消息类型;
- follower的消息类型主要有PING消息、REQUEST消息、ACK等消息,根据不同的消息类型,进行不同的处理。
系统模型
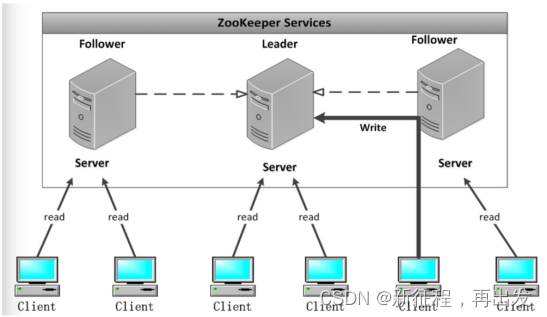
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的 Server都恢复到一个正确的状态。
Zk的选举算法有两种:
- 一种是基于basic paxos实现的,
- 另外一种是基于fast paxos算法实现的。
系统默认的选举算法为fast paxos。
3.2、 Zookeeper的数据节点
Zookeeper维护一个类似文件系统的数据结构:
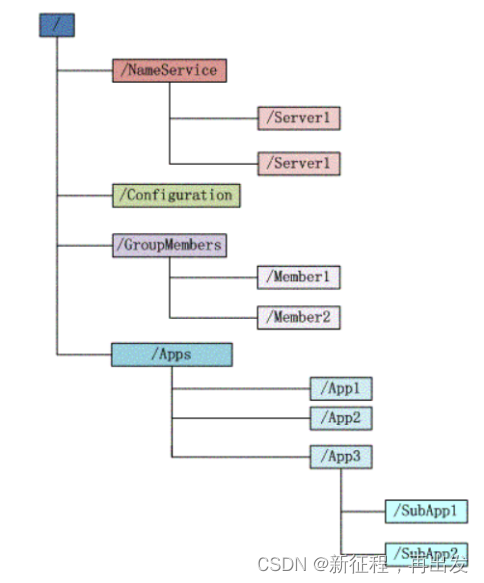
每个子目录项如 NameService 都被称作为 znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
-
PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在 -
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号。 -
EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除 -
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
3.2.1、Zookeeper的数据同步的特点
-
最终一致性:
client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。 -
可靠性:
具有简单、健壮、良好的性能,如果消息被到一台服务器接受,那么它将被所有的服务器接受。 -
实时性:
Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。 -
原子性:
更新只能成功或者失败,没有中间状态。
3.2.2、Zookeeper的数据广播
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。
Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。
状态同步保证了leader和Server具有相同的系统状态。
结束!!!
行动是自己的,控制好它,你就能任游东西。怕只怕,思想不是自己的,千行万动,还只是在原地踏步。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)