Java 操作RestHighLevelClient查询详解
top_hits应用场景:当获取分桶后,桶内最匹配的顶部文档列表。@Test//1.创建 SearchRequest搜索请求,并指定要查询的索引//2.创建 SearchSourceBuilder条件构造。// top_hits示例:指定size,不同工种中,年纪最大的3个员工的具体信息.size(3)//嵌套聚合//3.将 SearchSourceBuilder 添加到 SearchReques
根据我之前文章对 ES命令的查询使用,测试索引的文档数据前面文章有提到的。下面我们就通过 RestHighLevelClient来进行查询。
参考官方AP文档: Search APIs | Java REST Client [7.17] | Elastic
一、高级查询Query DSL
Elasticsearch高级查询Query DSL: Elasticsearch高级查询Query DSL_Charge8的博客-CSDN博客
1、查询接口的步骤
一个查询接口的基本步骤如下:
1、创建 SearchRequest搜索请求
创建 SearchRequest 搜索请求,如果不带参数,表示查询所有索引
2、创建 SearchSourceBuilder条件构造
创建 SearchSourceBuilder条件构造,构建搜索的条件。
添加大部分查询参数到 SearchSourceBuilder,还可以接收 QueryBuilders构建的查询参数。
3、将 SearchSourceBuilder 添加到 SearchRequest中
4、执行查询
5、解析查询结果其中,第二步和第五步最为关键。
下面直接上代码,语法使用就不解释了。
2、查询所有match_all
使用 match_all,默认只会返回 10条数据。
2.1 全量查询
@Test
public void testMatchAll() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("db_idx4");//指定要查询的索引
//2.创建 SearchSourceBuilder条件构造。builder模式这里就先不简写了
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
searchSourceBuilder.query(matchAllQueryBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println(searchResponse);
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println(hits.getTotalHits());
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
}
2.2 分页查询
- size 关键字:指定查询结果中返回指定条数。 默认返回值10条。
- from 关键字:用来指定起始返回位置,和size关键字连用可实现分页效果
@Test
public void testMatchAllPage() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("db_idx4");//指定要查询的索引
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery());
//设置分页
searchSourceBuilder.from(1);
searchSourceBuilder.size(5);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
}
3、数据排序
@Test
public void testSortByAge() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("db_idx4");//指定要查询的索引
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery());
//年龄倒序
searchSourceBuilder.sort("age", SortOrder.DESC);
searchSourceBuilder.sort("id", SortOrder.DESC);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
}
4、数据过滤
数据过滤就是 返回我们指定的字段。
@Test
public void testSource() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("db_idx4");//指定要查询的索引
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery());
//指定需要返回或者排除的字段
String[] includes = {
"id", "name"};
String[] excludes = {
};
searchSourceBuilder.fetchSource(includes, excludes);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
}
5、match 查找
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找。
@Test
public void testMatch() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("db_idx4");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//match 查找
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("address", "王者打野");
matchQueryBuilder.operator(Operator.OR);
searchSourceBuilder.query(matchQueryBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
}
6、多字段查询multi_match
multi_match 关键字:可以根据字段类型,决定是否使用分词查询,得分最高的在前面。
@Test
public void testMultiMatch() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("db_idx4");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//MultiMatch 查找
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("王者辅助","address", "desc");
multiMatchQuery.operator(Operator.OR);
searchSourceBuilder.query(multiMatchQuery);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
}
7、精确查询Term
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//Term 查找
//TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("age", 23);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("address.keyword", "三国演义小乔");
searchSourceBuilder.query(termQueryBuilder);8、范围查询range
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//Range 查找
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age");
rangeQueryBuilder.gte(18);
rangeQueryBuilder.lt(23);
searchSourceBuilder.query(rangeQueryBuilder);9、日期查询range
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("product");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//日期Range 查找
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("date"); //date字段
rangeQueryBuilder.lt("now‐2y");
searchSourceBuilder.query(rangeQueryBuilder);10、多个id查询
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//多个id 查找
IdsQueryBuilder idsQueryBuilder = QueryBuilders.idsQuery();
idsQueryBuilder.addIds("2", "5", "1111");
searchSourceBuilder.query(idsQueryBuilder);11、高亮查询
@Test
public void testHighlight() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("db_idx4");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//Term 查找
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("address", "王者");
searchSourceBuilder.query(termQueryBuilder);
//自定义高亮 查找
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
highlightBuilder.field("address");
highlightBuilder.requireFieldMatch(false); //多字段时,需要设置为false
highlightBuilder.field("desc");
searchSourceBuilder.highlighter(highlightBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> {
System.out.println("文档原生信息:" + p.getSourceAsString());
System.out.println("高亮信息:" + p.getHighlightFields());
});
}
12、布尔查询Bool
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//Bool查找
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// and
//boolQueryBuilder.must(QueryBuilders.rangeQuery("age").gte(20));
//boolQueryBuilder.must(QueryBuilders.matchQuery("sex", "0"));
// or
boolQueryBuilder.should(QueryBuilders.rangeQuery("age").gte(20));
boolQueryBuilder.should(QueryBuilders.matchQuery("sex", "0"));
searchSourceBuilder.query(boolQueryBuilder);13、模糊查询
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//Fuzzy 查找
FuzzyQueryBuilder fuzzyQueryBuilder = QueryBuilders.fuzzyQuery("name", "张").fuzziness(Fuzziness.ONE);
searchSourceBuilder.query(fuzzyQueryBuilder);二、聚合操作
ElasticSearch聚合操作: ElasticSearch聚合操作_Charge8的博客-CSDN博客_elasticsearch聚合size
1、Metric Aggregation
Metric Aggregation 一些数学运算,可以对文档字段进行统计分析。
1.1 查询员工的最低最高和平均工资
@Test
public void testAgg1() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查询员工的最低最高和平均工资
MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("maxSalary").field("salary");
MinAggregationBuilder minAggregationBuilder = AggregationBuilders.min("minSalary").field("salary");
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("avgSalary").field("salary");
searchSourceBuilder.aggregation(maxAggregationBuilder);
searchSourceBuilder.aggregation(minAggregationBuilder);
searchSourceBuilder.aggregation(avgAggregationBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println(searchResponse);
System.out.println("花费的时长:" + searchResponse.getTook());
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedMax maxSalary = aggregations.get("maxSalary");
ParsedMin minSalary = aggregations.get("minSalary");
ParsedAvg avgSalary = aggregations.get("avgSalary");
System.out.println("maxSalary:" + maxSalary);
System.out.println("最低工资" + maxSalary.getValue());
System.out.println("最高工资" + minSalary.getValue());
System.out.println("平均工资" + avgSalary.getValue());
}
1.2 对salary进行统计
@Test
public void testAgg2() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//对salary进行统计
StatsAggregationBuilder statsAggregationBuilder = AggregationBuilders.stats("statSalary").field("salary");
searchSourceBuilder.aggregation(statsAggregationBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedStats statSalary = aggregations.get("statSalary");
System.out.println("统计个数" + statSalary.getCount());
System.out.println("平均工资" + statSalary.getAvg());
System.out.println("最高工资" + statSalary.getMaxAsString()); //可以转String
System.out.println("最低工资" + statSalary.getMin());
System.out.println("工资之和" + statSalary.getSum());
}
1.3 cardinate对搜索结果去重统计
@Test
public void testAgg3() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//cardinate对搜索结果去重统计
CardinalityAggregationBuilder cardinalityAggregationBuilder = AggregationBuilders.cardinality("jobCardinate").field("job.keyword");
searchSourceBuilder.aggregation(cardinalityAggregationBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedCardinality cardinality = aggregations.get("jobCardinate");
System.out.println("字段:" + cardinality.getName());
System.out.println("不重复的个数" + cardinality.getValue());
}
2、Bucket Aggregation
Bucket Aggregation:按照一定的规则,将文档分配到不同的桶中,每一个桶关联一个 key,从而达到分类的目的。类比Mysql中的group by操作。
2.1 获取 job的分类信息
@Test
public void testAgg4() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//获取 job的分类信息
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("jobGroup").field("job.keyword");
searchSourceBuilder.aggregation(termsAggregationBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedTerms jobGroup = aggregations.get("jobGroup");
System.out.println("字段:" + jobGroup.getName());
List<? extends Terms.Bucket> buckets = jobGroup.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println("getKey:" + bucket.getKey());
System.out.println("getKeyAsString:" + bucket.getKeyAsString());
System.out.println("getDocCount:" + bucket.getDocCount());
}
}
2.2 限定聚合范围
@Test
public void testAgg5() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("salary").gte(10000);
searchSourceBuilder.query(rangeQueryBuilder);
//获取 job的分类信息
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("jobGroup")
.field("job.keyword")
.size(10)
.order(BucketOrder.aggregation("_count", true));
searchSourceBuilder.aggregation(termsAggregationBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
//聚合信息
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedTerms jobGroup = aggregations.get("jobGroup");
System.out.println("字段:" + jobGroup.getName());
List<? extends Terms.Bucket> buckets = jobGroup.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println("getKey:" + bucket.getKey());
System.out.println("getKeyAsString:" + bucket.getKeyAsString());
System.out.println("getDocCount:" + bucket.getDocCount());
}
}
2.3 Range 示例:按照工资的 Range 分桶
@Test
public void testAgg6() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// Salary Range分桶,可以自己定义 key
RangeAggregationBuilder rangeAggregationBuilder = AggregationBuilders.range("salary_range")
.field("salary")
.addUnboundedTo(10000)
.addRange(10000, 20000)
.addUnboundedFrom(">20000", 20000);
searchSourceBuilder.aggregation(rangeAggregationBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
//聚合信息
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedRange salaryRange = aggregations.get("salary_range"); //注意类型
System.out.println("字段:" + salaryRange.getName());
List<? extends Range.Bucket> buckets = salaryRange.getBuckets();
for (Range.Bucket bucket : buckets) {
System.out.println("getKey:" + bucket.getKey());
System.out.println("getKeyAsString:" + bucket.getKeyAsString());
System.out.println("getDocCount:" + bucket.getDocCount());
System.out.println("getFromAsString:" + bucket.getFromAsString());
System.out.println("getToAsString:" + bucket.getToAsString());
}
}
2.4 Histogram示例:按照工资的间隔分桶
// Histogram示例:按照工资的间隔分桶
HistogramAggregationBuilder histogramAggregationBuilder = AggregationBuilders.histogram("salary_histrogram")
.field("salary")
.interval(5000)
.extendedBounds(0, 100000);
searchSourceBuilder.aggregation(histogramAggregationBuilder);.5 date_histogram 根据年月日做统计和上面类似,可自定义时间格式
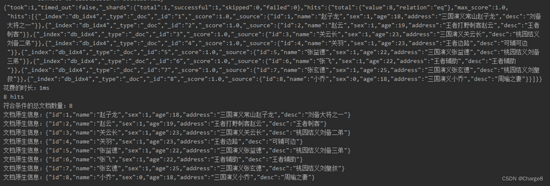
2.6 top_hits示例:
top_hits应用场景:当获取分桶后,桶内最匹配的顶部文档列表。
@Test
public void testAgg8() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// top_hits示例:指定size,不同工种中,年纪最大的3个员工的具体信息
TopHitsAggregationBuilder topHitsAggregationBuilder = AggregationBuilders.topHits("old_employee")
.size(3)
.sort("age", SortOrder.DESC);
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("jobs")
.field("job.keyword")
.subAggregation(topHitsAggregationBuilder); //嵌套聚合
searchSourceBuilder.aggregation(termsAggregationBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
//聚合信息
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedTerms jobs = aggregations.get("jobs"); //注意类型
System.out.println("字段:" + jobs.getName());
List<? extends Terms.Bucket> buckets = jobs.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println("getKey:" + bucket.getKey());
System.out.println("getKeyAsString:" + bucket.getKeyAsString());
System.out.println("getDocCount:" + bucket.getDocCount());
//嵌套的信息
ParsedTopHits oldEmployee = bucket.getAggregations().get("old_employee");
SearchHits employeeHits = oldEmployee.getHits();
System.out.println(" hits.getTotalHits().value:" + hits.getTotalHits().value);
for (SearchHit employeeHit : employeeHits) {
System.out.println(" employeeHit.getSourceAsString():" + employeeHit.getSourceAsString());
}
}
}
3、Pipeline Aggregation
Pipeline Aggregation:支持对聚合分析的结果,再次进行聚合分析。
3.1 min_bucket示例:最小值
在员工数最多的工种里,找出平均工资最低的工种
public void testAgg9() throws IOException {
RestHighLevelClient restHighLevelClient = ESUtil.getRestHighLevelClient();
//1.创建 SearchRequest搜索请求,并指定要查询的索引
SearchRequest searchRequest = new SearchRequest("employees");
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// min_bucket示例:平均工资最低的工种
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("avg_salary").field("salary");
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("jobs")
.field("job.keyword")
.size(10)
.subAggregation(avgAggregationBuilder); //嵌套聚合
searchSourceBuilder.aggregation(termsAggregationBuilder);
// 添加 bucket pipeline(min_bucket)
searchSourceBuilder.aggregation(new MinBucketPipelineAggregationBuilder("min_salary_by_job", "jobs>avg_salary"));
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
//聚合信息
Aggregations aggregations = searchResponse.getAggregations();
System.out.println("aggregations:" + aggregations);
ParsedTerms jobs = aggregations.get("jobs"); //注意类型
System.out.println("字段:" + jobs.getName());
List<? extends Terms.Bucket> buckets = jobs.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println("getKey:" + bucket.getKey());
System.out.println("getKeyAsString:" + bucket.getKeyAsString());
System.out.println("getDocCount:" + bucket.getDocCount());
//嵌套的信息
ParsedAvg avgSalary = bucket.getAggregations().get("avg_salary");
System.out.println(" hits.getTotalHits().value:" + avgSalary.getValue());
}
}
3.2 Stats示例:统计分析
//2.创建 SearchSourceBuilder条件构造。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// Stats示例:统计分析:平均工资的统计分析
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("avg_salary").field("salary");
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("jobs")
.field("job.keyword")
.size(10)
.subAggregation(avgAggregationBuilder); //嵌套聚合
searchSourceBuilder.aggregation(termsAggregationBuilder);
// 添加 bucket pipeline(stats_bucket)
searchSourceBuilder.aggregation(new StatsBucketPipelineAggregationBuilder("stats_salary_by_job", "jobs>avg_salary"));到此,Java 操作 RestHighLevelClient查询基本就 ok了。
总结如下:
- 写好 ES语句很关键,然后通过 客户端编写出来就简单了。
- 创建 SearchSourceBuilder条件构造,构建搜索的条件很重要,根据业务构造r条件变化多端。
- 不管是 Query DSL还是 聚合操作,通过 ES语句的结果来编写 SearchResponse的解析查询结果就很容易了,注意里边的类型。
– 求知若饥,虚心若愚。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)