Mysql和ES数据同步方案汇总
本文主要对Mysql和ES进行数据同步的常见方案进行了汇总说明。1. 同步双写2. 异步双写3. 基于Mysql表定时扫描同步4. 基于Binlog实时同步
文章目录
前言
在实际项目开发中,我们经常将Mysql作为业务数据库,ES作为查询数据库,用来实现读写分离,缓解Mysql数据库的查询压力,应对海量数据的复杂查询。这其中有一个很重要的问题,就是如何实现Mysql数据库和ES的数据同步,今天和大家聊聊Mysql和ES数据同步的各种方案。
一、Mysql和ES各自的特点
为什么选用Mysql
MySQL 在关系型数据库历史上并没有特别优势的位置,Oracle/DB2/PostgreSQL(Ingres) 三老比 MySQL 开发早了 20 来年, 但是乘着 2000 年的互联网东风, LAMP 架构得到迅速的使用,特别在中国,大部分新兴企业的 IT 系统主数据沉淀于 MySQL 中。
核心特点:开源免费、高并发、稳定、支持事务、支持SQL查询
-
高并发能力:MySQL 内核特征特别适合高并发简单 SQL 操作 ,链接轻量化(线程模式),优化器、执行器、事务引擎相对简单粗暴,存储引擎做得比较细致
-
稳定性好:主数据库最大的要求就是稳定、不丢数据,MySQL 内核特征反倒让其特点鲜明,从而达到很好的稳定性,主备系统也很早就 ready ,应对崩溃情况下的快速切换,innodb 存储引擎也保障了 MySQL 下盘稳定
-
操作便捷:良好、便捷的用户体验(相比 PostgreSQL) , 让应用开发者非常容易上手 ,学习成本较低
-
开源生态:MySQL 是一款开源产品,让上下游厂商围绕其构建工具相对简单,HA proxy、分库分表中间件让其实用性大大加强,同时开源的特质让其有大量的用户
为什么选用 ES
ES 几个显著的特点,能够有效补足 MySQL 在企业级数据操作场景的缺陷,而这也是我们将其选择作为下游数据源重要原因
核心特点:支持分词检索,多维筛选性能好,支持海量数据查询
-
文本搜索能力:ES 是基于倒排索引实现的搜索系统,配合多样的分词器,在文本模糊匹配搜索上表现得比较好,业务场景广泛
-
多维筛选性能好:亿级规模数据使用宽表预构建(消除 join),配合全字段索引,使 ES 在多维筛选能力上具备压倒性优势,而这个能力是诸如 CRM, BOSS, MIS 等企业运营系统核心诉求,加上文本搜索能力,独此一家
-
开源和商业并行:ES 开源生态非常活跃,具备大量的用户群体,同时其背后也有独立的商业公司支撑,而这让用户根据自身特点有了更加多样、渐进的选择
二、数据同步方案
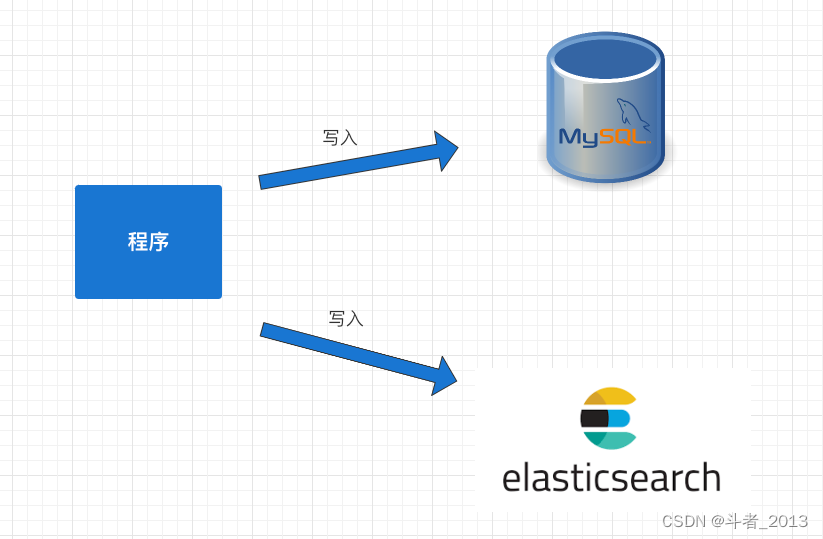
1.同步双写
这是一种最为简单的方式,在将数据写到mysql时,同时将数据写到ES。
伪代码:
/**
* 新增商品
*/
@Transactional(rollbackFor = Exception.class)
public void addGoods(GoodsDto goodsDto) {
//1、保存Mysql
Goods goods = new Goods();
BeanUtils.copyProperties(goodsDto,goods);
GoodsMapper.insert();
//2、保存ES
IndexRequest indexRequest = new IndexRequest("goods_index","_doc");
indexRequest.source(JSON.toJSONString(goods), XContentType.JSON);
indexRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);
highLevelClient.index(indexRequest);
}
-
优点:
1、业务逻辑简单
2、实时性高 -
缺点:
1、 硬编码,有需要写入mysql的地方都需要添加写入ES的代码;
2、 业务强耦合;
3、 存在双写失败丢数据风险;
4、 性能较差:本来mysql的性能不是很高,再加一个ES,系统的性能必然会下降。
附:
上面说的双写失败风险,包括以下几种:
1) ES系统不可用;
2) 程序和ES之间的网络故障;
3) 程序重启,导致系统来不及写入ES等。
针对这种情况,有数据强一致性要求的,就必须双写放到事务中来处理,而一旦用上事物,则性能下降更加明显。
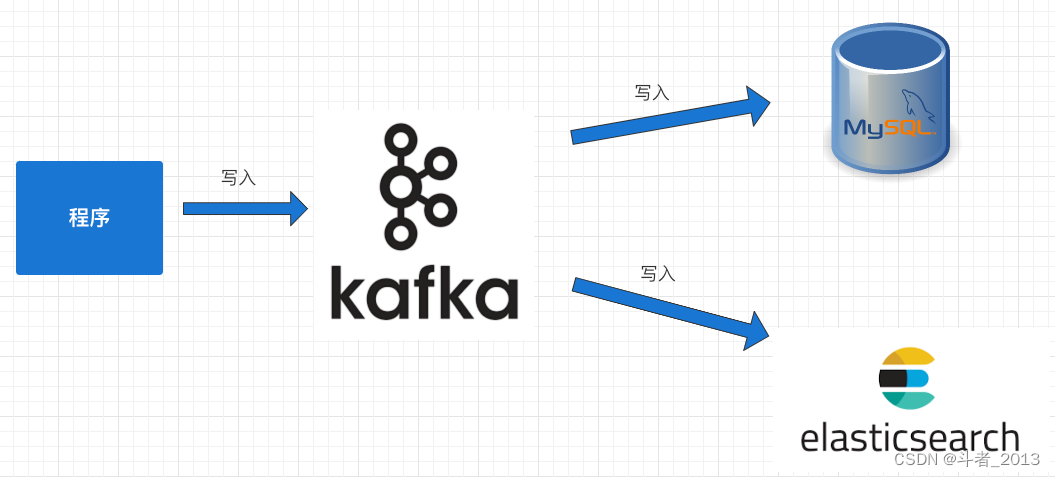
2.异步双写(MQ方式)
针对多数据源写入的场景,可以借助MQ实现异步的多源写入,这种情况下各个源的写入逻辑互不干扰,不会由于单个数据源写入异常或缓慢影响其他数据源的写入,虽然整体写入的吞吐量增大了,但是由于MQ消费是异步消费,所以不适合实时业务场景。
-
优点:
1、性能高
2、不易出现数据丢失问题,主要基于MQ消息的消费保障机制,比如ES宕机或者写入失败,还能重新消费MQ消息。
3、多源写入之间相互隔离,便于扩展更多的数据源写入 -
缺点:
1、硬编码问题,接入新的数据源需要实现新的消费者代码
3、系统复杂度增加:引入了消息中间件
4、可能出现延时问题:MQ是异步消费模型,用户写入的数据不一定可以马上看到,造成延时。
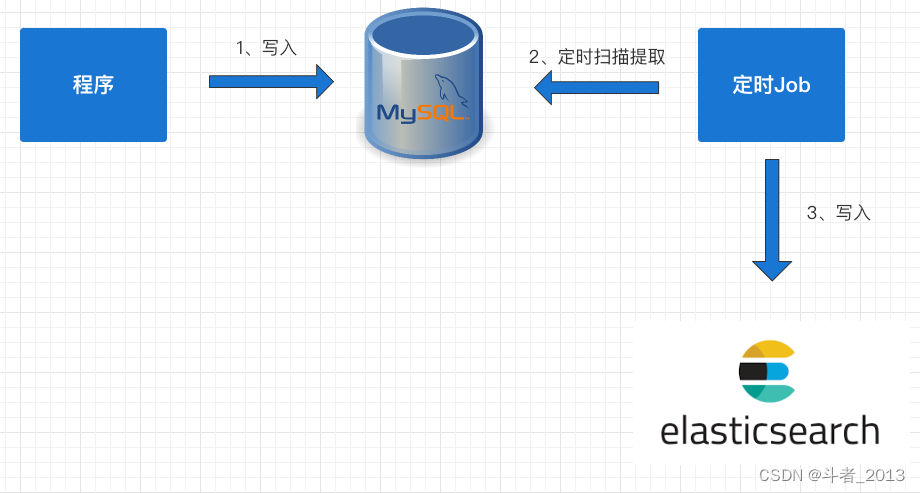
3.基于Mysql表定时扫描同步
上面两种方案中都存在硬编码问题,也就是有任何对mysq进行增删改查的地方要么植入ES代码,要么替换为MQ代码,代码的侵入性太强。
如果对实时性要求不高的情况下,可以考虑用定时器来处理,具体步骤如下:
1、数据库的相关表中增加一个字段为timestamp的字段,任何crud操作都会导致该字段的时间发生变化;
2、原来程序中的CURD操作不做任何变化;
3、增加一个定时器程序,让该程序按一定的时间周期扫描指定的表,把该时间段内发生变化的数据提取出来;
4、逐条写入到ES中。
如下图所示:
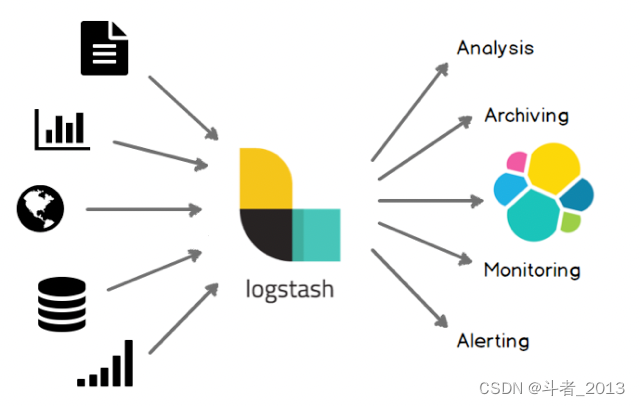
该方案的典型实现是借助logstash实现数据同步,其底层实现原理就是根据配置定期使用sql查询新增的数据写入ES中,实现数据的增量同步。
具体实现可以参考:通过Logstash实现mysql数据定时增量同步到ES
- 优点:
1、不改变原来代码,没有侵入性、没有硬编码;
2、没有业务强耦合,不改变原来程序的性能;
3、Worker代码编写简单不需要考虑增删改查; - 缺点:
1、时效性较差,由于是采用定时器根据固定频率查询表来同步数据,尽管将同步周期设置到秒级,也还是会存在一定时间的延迟。
2、对数据库有一定的轮询压力,一种改进方法是将轮询放到压力不大的从库上。
4.基于Binlog实时同步
上面三种方案要么有代码侵入,要么有硬编码,要么有延迟,那么有没有一种方案既能保证数据同步的实时性又没有代入侵入呢?
当然有,可以利用mysql的binlog来进行同步。其实现原理如下:
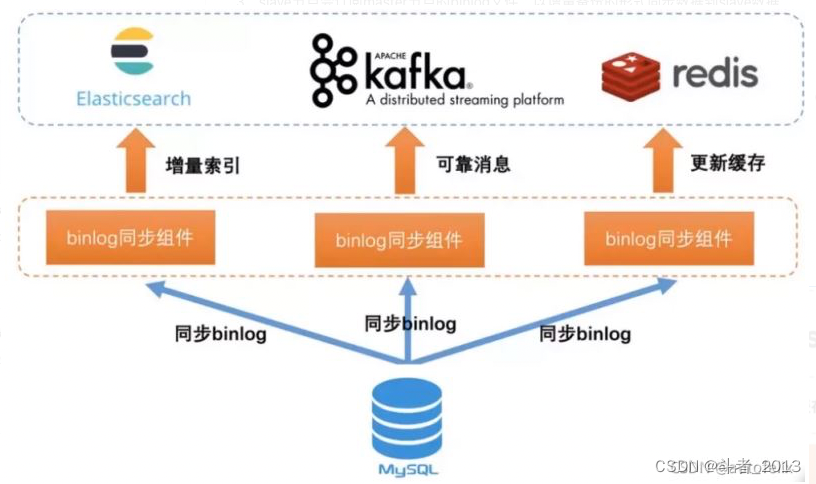
具体步骤如下:
1) 读取mysql的binlog日志,获取指定表的日志信息;
2) 将读取的信息转为MQ;
3) 编写一个MQ消费程序;
4) 不断消费MQ,每消费完一条消息,将消息写入到ES中。
- 优点:
1、没有代码侵入、没有硬编码;
2、原有系统不需要任何变化,没有感知;
3、性能高;
4、业务解耦,不需要关注原来系统的业务逻辑。 - 缺点:
1、构建Binlog系统复杂;
2、如果采用MQ消费解析的binlog信息,也会像方案二一样存在MQ延时的风险。
业界目前较为流行的方案:使用canal监听binlog同步数据到es
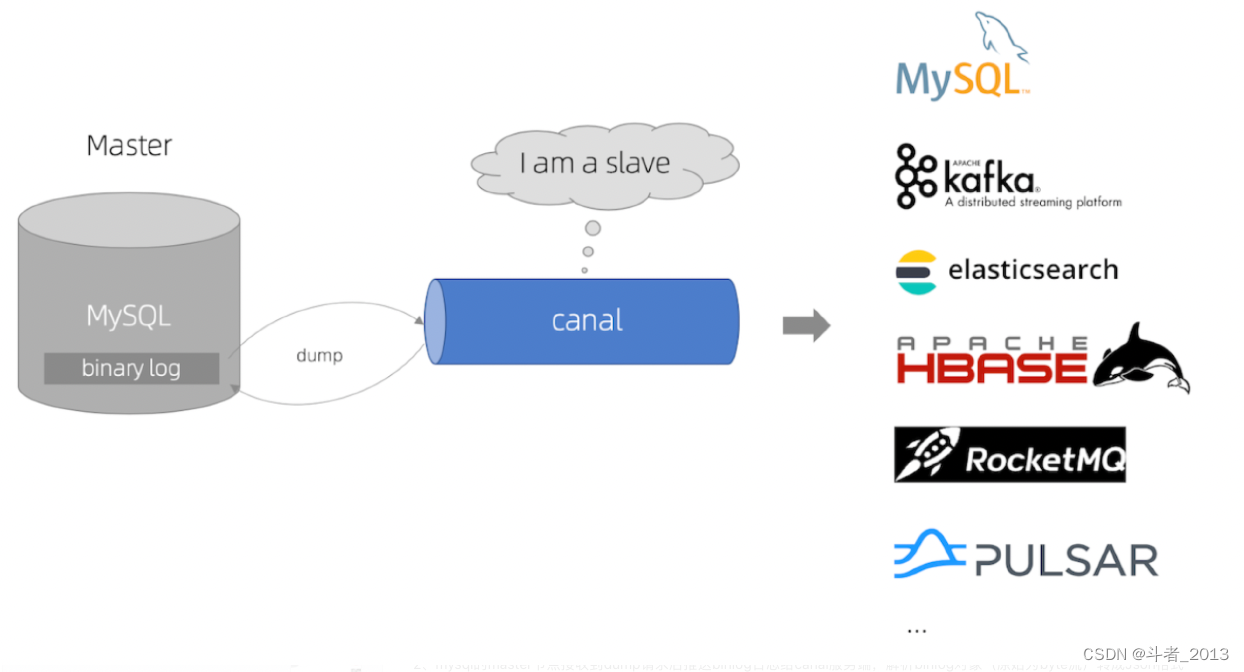
canal ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
说白了就是,根据Mysql的binlog日志进行增量同步数据。要理解canal的原理,就要先了解mysql的主从复制原理:
1、所有的create update delete操作都会进入MySQLmaster节点
2、master节点会生成binlog文件,每次操作mysql数据库就会记录到binlog文件中
3、slave节点会订阅master节点的binlog文件,以增量备份的形式同步数据到slave数据
canal原理就是伪装成mysql的从节点,从而订阅master节点的binlog日志,主要流程为:
1、canal服务端向mysql的master节点传输dump协议
2、mysql的master节点接收到dump请求后推送binlog日志给canal服务端,解析binlog对象(原始为byte流)转成Json格式
3、canal客户端通过TCP协议或MQ形式监听canal服务端,同步数据到ES
三、数据迁移同步工具选型
数据迁移同步工具的选择比较多样,下表仅从 MySQL 同步 ES 这个场景下,对一些笔者深度使用研究过的数据同步工具进行对比,用户可以根据自己的实际需要选取适合自己的产品。
| 特性\产品 | Canal | DTS | CloudCanal |
|---|---|---|---|
| 是否支持自建ES | 是 | 否 | 是 |
| ES对端版本支持丰富度 | 中 支持ES6和ES7 | 高 支持ES5,ES6和ES7 | 中 支持ES6和ES7 |
| 嵌套类型支持 | join/nested/object | object | nested/object |
| join支持方式 | 基于join父子文档&反查 | 无 | 基于宽表预构建&反查 |
| 是否支持结构迁移 | 否 | 是 | 是 |
| 是否支持全量迁移 | 是 | 是 | 是 |
| 是否支持增量迁移 | 是 | 是 | 是 |
| 数据过滤能力 | 中 -仅全量可添加where条件 | 高 -全增量阶段where条件 | 高 -全增量阶段where条件 |
| 是否支持时区转换 | 否 | 是 | 是 |
| 同步限流能力 | 无 | 有 | 有 |
| 任务编辑能力 | 无 | 有 | 无 |
| 数据源支持丰富度 | 中 | 高 | 中 |
| 架构模式 | 订阅消费模式 需先写入消息队列 | 直连模式 | 直连模式 |
| 监控指标丰富度 | 中 性能指标监控 | 中 性能指标监控 | 高 性能指标、资源指标监控 |
| 报警能力 | 无 | 针对延迟、异常的电话报警 | 针对延迟、异常的钉钉、短信、邮件报警 |
| 任务可视化创建&配置&管理能力 | 无 | 有 | 有 |
| 是否开源 | 是 | 否 | 否 |
| 是否免费 | 是 | 否 是社区版、 | SAAS版免费 |
| 是否支持独立输出 | 是 | 否依赖云平台整体输出 | 是 |
| 是否支持SAAS化使用 | 否 | 是 | 是 |
总结
本文主要对Mysql和ES进行数据同步的常见方案进行了汇总说明。
同步双写是最简单的同步方式,能最大程度保证数据同步写入的实时性,最大的问题是代码侵入性太强。异步双写引入了消息中间件,由于MQ都是异步消费模型,所以可能出现数据同步延迟的问题。好处是在大规模消息同步时吞吐量更、高性能更好,便于接入更多的数据源,且各个数据源数据消费写入相互隔离互不影响。基于Mysql表定时扫描同步,原理是通过定时器定时扫描表中的增量数据进行数据同步,不会产生代码侵入,但由于是定时扫描同步,所以也会存在数据同步延迟问题,典型实现是采用Logstash实现增量同步。基于Binlog实时同步,原理是通过监听Mysql的binlog日志进行增量同步数据。不会产生代码侵入,数据同步的实时也能得到保障,弊端是Binlog系统都较为复杂。典型实现是采用canal实现数据同步。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 22
22 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)