springboot项目使用ES
springboot + ES
**
一、环境安装
整个过程基本就是无脑安装 开箱即用 偶尔需要修改一下配置信息
ES兼容版本:
版本兼容链接
**
1.安装jdk
略
2.安装ES
下载地址
Elasticsearch目录结构:
启动: 在bin目录下双击elasticsearch.bat
验证服务启动成功:http://localhost:9200
本机多节点启动 :
- 将es项目删除data文件后 copy多个node,分别启动
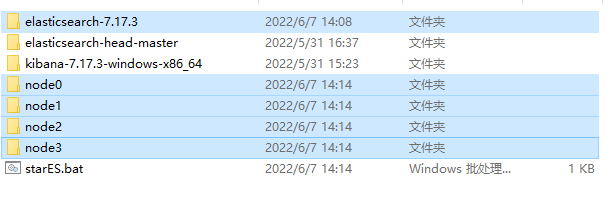
- 修改每一个node下的elasticsearch.yml
cluster.name 是集群名称所有node必须一样,node.name是节点名,http.port是端口号,每个几点不一样,对应修改
cluster.name: my-application
node.name: node-0
http.port: 9200
- 创建脚本文件starES.bat 批量启动
start node0\bin\elasticsearch.bat
start node1\bin\elasticsearch.bat
start node2\bin\elasticsearch.bat
start node3\bin\elasticsearch.bat
3.安装kanba
下载链接
启动:在bin目录下双击kibana.bat
验证服务启动成功:http://localhost:5601
配置elasticsearch服务的地址:config/Kibana.yml
命令行关闭kibana:
关闭窗口ps -ef | grep 5601 或者 ps -ef | grep kibana 或者 lsof -i :5601kill -9 pid

4.安装nodejs
下载地址
1.无脑下一步 检查是否安装成功 `node -V`
2.安装grunt:
- CMD中执行“npm install -g grunt-cli”命令等待安装完成
- grunt -version命令检查是否安装成功
5.安装head插件
下载地址或者谷歌商店
- 下载完成后,解压,打开elasticsearch-head-master文件夹,
修改Gruntfile.js文件,添加hostname:'*', 如图: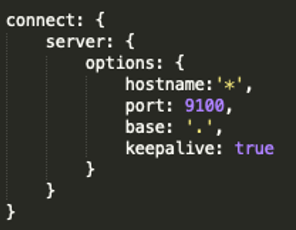
- elasticsearch-head-master 路径下 执行
npm install - 安装完成
npm run start启动服务 - 配置跨域 在ES配置文件
/config/elasticsearch.yml中最后添加
http.cors.enabled: true
http.cors.allow-origin: "*"
- 验证:
http://localhost:9100/安装成功
二、倒排索引
1.什么是倒排索引
首先要明白为什么ES适合做搜索引擎, 而MySQL不适合
Mysql的索引结构可以增加查询效率
| id | name |
|---|---|
| 1 | like apple |
| 2 | like banana |
| 3 | like banana,apple |
| 4 | like orange |
如上表结构 如果用mysql做搜索引擎 建立索引结构
| id | name |
|---|---|
| 1 | apple |
| 2 | banana |
| 3 | banana,apple |
| 4 | orange |
如果想查询apple数据 还是要遍历所有索引 查到id之后再回表, 很浪费性能, 而ES则设计了倒排索引, 用分词作为主题建立索引结构只要查询到前面的分词就可以直接获取相应的数据:
| name | index |
|---|---|
| apple | 1,3 |
| banana | 2,3 |
| orange | 4 |
2.为什么倒排索引需要压缩算法
索引中分词包含的数据存放在数组中 如果数组为 [1,2,3,4,78,90,1000,1001,1002,1003,9998,9999]
所以实际存储的就是一个有序数组,如果直接存储的话就需要占用4byte * 12 = 48byte(1int占用4byte)
而有序数值数组是比较容易进行压缩处理的,而且一般来说压缩效益也不错,如果能对其进行压缩是能够大大节约空间资源的
FOR压缩算法
因为数组是有序数组, 所以可以在数组中存储每隔数字之前的差值
比如数组是73,300,302,332,342,372,原本需要6 * 4 byte = 24byte = 192bit
压缩后:73,227,2,30,11,29 其中227最大 所以需要8bit来装 6 * 8bit = 48bit
我们可以把8bit的容器理解为一个箱子,总共需要6个箱子,所有箱子占48bit,但是这并不是我们的总大小,因为相比较于原数组,我们引入了一个箱子的概念,那么除了箱子数,我们还需要记录每个箱子的大小,所以需要有一个数来记录箱子大小,这里注意我们规定盛装大小不超过256bit,因此箱子大小值最大不超过2^8,即箱子大小值占用不超过8bit,因此总共的大小是48bit+8bit = 56bit
可以看到压缩后大小由192bit降到了56bit,已经有很大改善了,但是这还不是FOR算法的终点,观察这组数中最大值227,后一位最小值是2,两者相差很大,2实际上只需要1bit来盛装,那么能不能进一步压缩呢?答案是可以,只是不再需要做差值,直接将数组分组,将其拆分为:
73,227
2,30,11,29
那么占用空间就变成了73,227箱子大小8bit,2,30,11,29中最大30,箱子大小为5bit
因此数组总大小为28bit + 45bit = 36bit,另外不要忘记这里因为分成两组,还需要单独记录两组箱子的大小值,所以总大小是36bit+2*8bit= 52bit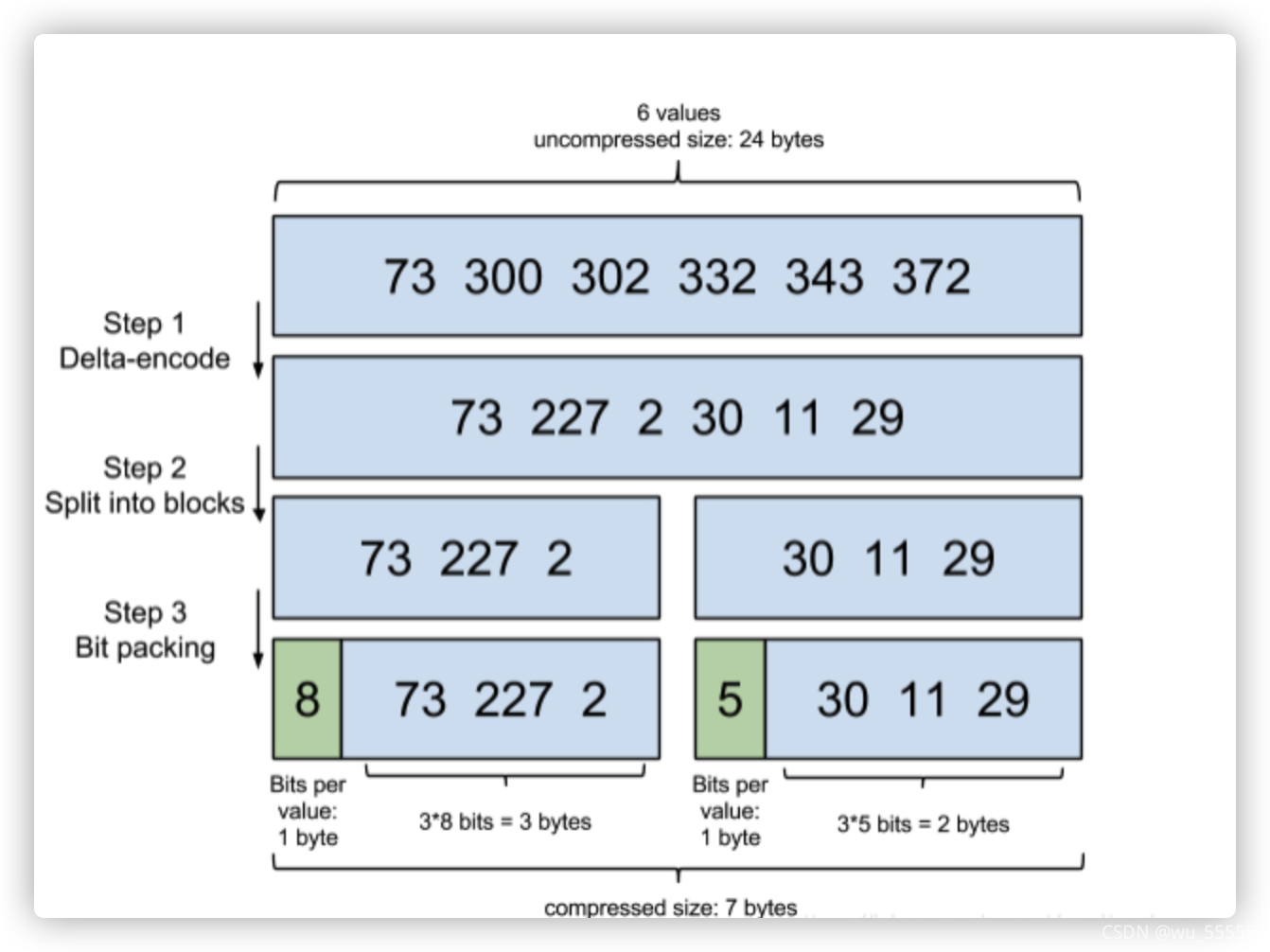
可以看到大小又变小了,但是思考一个问题:是不是还可以进行压缩?是越小越好吗?
是可以再压缩,但是我们还要考虑解码的问题,数据压缩后是要使用的,因此需要解码,压缩得越深,解码越耗时,因此不是越小越好,那么在哪里取一个平衡,这就是通过计算机动态计算的,计算方法这里不做深一步讨论了,大家理解这个概念即可
以上就是FOR算法的概念,总结一下:
(1)数组元素值为与前一位的差值V(n)=V(n)-V(n-1),n=2,3,4…
(2)计算数组中最大值所需占用的大小
(3)计算数组是否需要拆分,计算拆分后每组的最大值所需占用的大小并记录
RBM算法(RoaringBitMap)
有了FOR算法为什么需要别的算法呢?说明FOR算法本身是有缺陷的,那么思考一下FOR算法的缺陷在哪里?
FOR算法的核心是用减法来缩减数值大小,但是减法一定能缩减大小吗?但数值大小很大时,减法能够达到的效果是不明显的,比如100W,200W,300W,相减后是100W,100W,100W,依然很大,这时的压缩效果很不理想,所以引入了RBM算法
那么大家再思考一下,既然减法不能满足,那么还有什么方法能够更快地减小数值大小呢?
没错,就是除法!
RBM的核心就是通过除法来缩减数值大小,但是并不是直接的相除。
比如数组为1000,62101,131385,191173,196658
其中196658的二进制表示为0000 0000 0000 0011 0000 0000 0011 0010
然后将其高16位和低16位分别转换为10进制:
0000 0000 0000 0011 -> 3
0000 0000 0011 0010 -> 50
那么196658就转换成了(3,50)的表示形式,其效果就相当于除以2^16,商3余50
这里的计算用位运算会更快更好理解,除以2^n相当于将这个数的二进制向右位移n位(不含符号位),并且用0补足空位。容易得出196658二进制右移16位后为
0000 0000 0000 0000 0000 0000 0000 0011
也就是其高16位,前面用0补足,而被位移顶替掉的就是其余数0000 0000 0011 0010
因为商和余数都不超过16位,那么我们最大用16bit来存储足够了。也就是short类型
因此商和余数都可以用一个short来盛装,那么所有的商就是一个short[],所有的余数就是一个short[][]
将原数组除以2^16得:
(0,1000),(0,62101),(2,313),(2,980),(2,60101),(3,50)
转化为二维数组盛装
0: 1000,62101
2: 313,980,60101
3: 50
我们把每一个商所对应的余数short[]称之为一个容器Container,使用上述所说的short盛装也称为ArrayContainer
我们也容易观察发现到,每一个Container实际上都是有序数值数组,是不是能够联想到什么?
数组还能进行压缩吗?
数组能用FOR算法再压缩吗?
有别的方式再进行压缩吗?
首先回答前两个问题:数组肯定可以压缩,而且正是我们需要去做的;用FOR算法在这里进行压缩是可以的,不算错,但是我们说不合适,正如在FOR算法中介绍的那样,压缩的同时我们还有考虑解码时的效率,其实这里已经经过除法做了一次处理了,那么再用减法做一次处理,再解码时效率会降低不少,所以我们追求的是一种解码更加容器,但又能具备压缩能力的方法
那么怎么找这种方法呢?在阐明这个方法前,我先抛出一个问题,熟悉java容器的同学应该比较了解:现在有10亿条11位的电话号码,请问如何用2G的空间将他们存储下来?
首先11位的电话号码用int是无法存储的,所以就要考虑用String和Long。显然用String不划算,如果用Long,那么8byte * 10亿 = 80亿byte = 7.45G
所以用Long来存储显然不行,那么有没有一种更加高效的容器?我们知道电话号码虽然不是连续的,但是当数量足够多时,我们可以大概认为他们是连续的,所以11位的电话号码。实际上就是10000000000 ~ 200000000000,那么我们用bit来存储一个数是否存在,现在定义有100亿位数,那么就可以存储100亿个数,用1表示对应位上的数存在。因为电话号码是11位,最小是10000000001,我们把右数第1位定义为10000000001,也就是说13866668888的表示是将第3866668888上设置为1: 0000…0001000.0000
因此电话号码phone的存储方式就是将第N-10000000000位上的数设置为1.判断电话号码是否存在的时候我们只需要判断对应位上的数是否为1即可。这样的话一共使用100亿bit=1192M就可以存下,不到2G满足要求。
当然以上是理想状态,那么我们实际中该怎么存储呢,那就是使用数组,我们知道long占64位,也就是说一个long可以表示64个数,那么100亿个数就需要156250000个long,我们就需要定义一个long[156250000]数组arr
存储电话号码phone: arr[(phone-10000000000)/64] | (1 << ((phone-10000000000)%64))
判断电话号码是否存在:arr[(phone-10000000000)/64] & (1 << ((phone-10000000000)%64)) > 0
通过上述的bit存储的方式来存储数据,就是使用bitmap的形式来存储数据,了解这个知识后我们再来看之前的问题,以下的二维数组,每一个Container中的数据当量足够多时我们认为他是有序连续的:
0: 1000,62101
2: 313,980,60101
3: 50
因此我们就可以使用bitmap来存储数据,按照规定一个Container的最大值是65534(这里为什么最大值是65534,思考一下,如果不明白往上看看原数组是怎么处理的),也就需要65535bit=8k的容器来存储,当然bitmap有个很明显的缺点,那就是无论Container中有多少个数,都要占用8k的大小,所以当数量不超过65535bit /16bit = 4096个时,使用short (16bit)来存储更划算,当每个Container的数量超过4096个时使用bitmap更加划算,那么使用bitmap的Container称为BitmapContainer
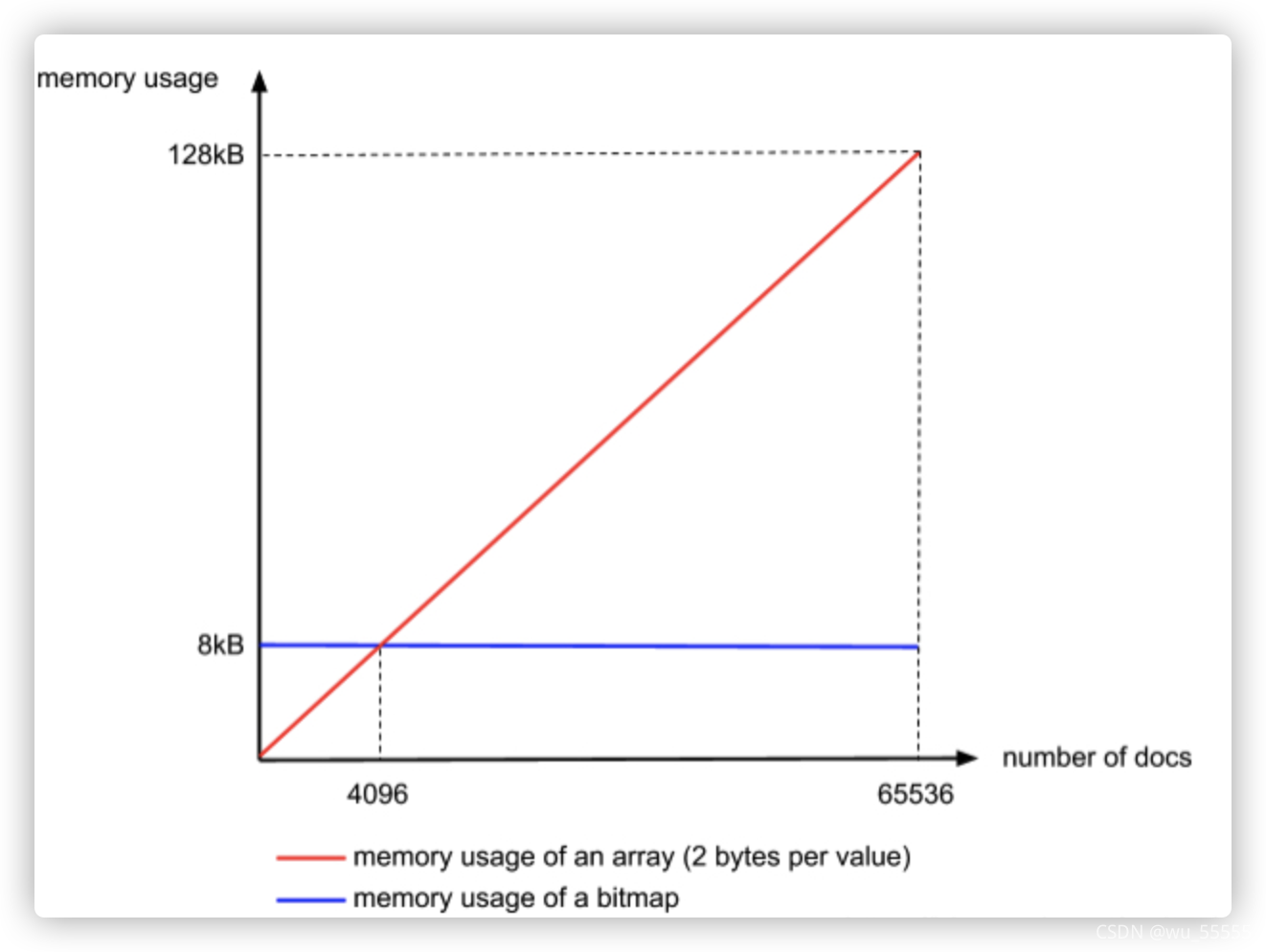
还有一个Container叫RunContainer,专门用来解决连续数组存储的,比如[1,2,3,…,100W],那么可以表示为[1,100W],只存储一个最小值和最大值,如果数组是如下形式
[1,2,3,4,5,100,101,102,999,1000,1001]
就会被拆分为三段:[1,5],[100,102],[999,1001]
综上Container有三种:ArrayContainer,BitmapContainer,RunContainer
RBM算法的核心步骤如下:
(1)数组中每个数除以2^16,以商,余数的形式表示出来
(2)将相同商的归在一个Container,如果Contaniner中数值容量超过4096使用bitmap的形式来存储一个Container中的数,如果没有超过那就使用short[]来存储,如果是连续数组那就使用RunContainer来存储
三、java使用
增加配置
elasticsearch:
host: 127.0.0.1
port: 9201
connTimeout: 3000
socketTimeout: 5000
connectionRequestTimeout: 500
添加依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.1.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.1.0</version>
</dependency>
注入ES配置类
package com.example.test_docker.config;
import lombok.Data;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
/**
* @Author: yjj
* @Date: 2022/06/29/16:33
* @Description:
*/
@Data
@Component
public class EsConfig {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Value("${elasticsearch.connTimeout}")
private int connTimeout;
@Value("${elasticsearch.socketTimeout}")
private int socketTimeout;
@Value("${elasticsearch.connectionRequestTimeout}")
private int connectionRequestTimeout;
}
在 config 包下创建 ElasticsearchConfiguration 类,会从配置文件中读取到对应的参数,接着申明一个 initRestClient 方法,返回的是一个 RestHighLevelClient,同时为它添加 @Bean(destroyMethod = “close”) 注解,当 destroy 的时候做一个关闭,这个方法主要是如何初始化并创建一个 RestHighLevelClient。
package com.example.test_docker.config;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Author: yjj
* @Date: 2022/06/29/10:58
* @Description:
*/
@Slf4j
@Configuration
public class ElasticsearchConfiguration {
@Autowired
EsConfig esConfig;
@Bean(destroyMethod = "close", name = "client")
public RestHighLevelClient initRestClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost(esConfig.getHost(), esConfig.getPort()))
.setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder
.setConnectTimeout(esConfig.getConnTimeout())
.setSocketTimeout(esConfig.getSocketTimeout())
.setConnectionRequestTimeout(esConfig.getConnectionRequestTimeout()));
return new RestHighLevelClient(builder);
}
// 注册 rest高级客户端
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost(esConfig.getHost(), esConfig.getPort(), "http")
)
);
return client;
}
}
ES操作demo
package com.example.test_docker.service;
import com.alibaba.fastjson.JSON;
import com.example.test_docker.constant.Constant;
import com.example.test_docker.enerty.UserDocument;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.Avg;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
/**
* @Author: yjj
* @Date: 2022/06/29/11:03
* @Description:
*/
@Slf4j
@Service
public class EsService {
@Autowired
@Qualifier("restHighLevelClient")
public RestHighLevelClient client;
public boolean createUserIndex(String index) throws IOException {
//创建索引(建表)
CreateIndexRequest createIndexRequest = new CreateIndexRequest(index);
createIndexRequest.settings(Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 0)
);
createIndexRequest.mapping("{\n" +
" \"properties\": {\n" +
" \"city\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"sex\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"age\": {\n" +
" \"type\": \"integer\"\n" +
" }\n" +
" }\n" +
"}", XContentType.JSON);
CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
return createIndexResponse.isAcknowledged();
}
//删除索引(删表)
public Boolean deleteUserIndex(String index) throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(index);
AcknowledgedResponse deleteIndexResponse = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
return deleteIndexResponse.isAcknowledged();
}
//创建文档(插入数据)
public Boolean createUserDocument(UserDocument document) throws Exception {
UUID uuid = UUID.randomUUID();
document.setId(uuid.toString());
IndexRequest indexRequest = new IndexRequest(Constant.INDEX)
.id(document.getId())
.source(JSON.toJSONString(document), XContentType.JSON);
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
return indexResponse.status().equals(RestStatus.OK);
}
//批量创建文档
public Boolean bulkCreateUserDocument(List<UserDocument> documents) throws IOException {
BulkRequest bulkRequest = new BulkRequest();
for (UserDocument document : documents) {
String id = UUID.randomUUID().toString();
document.setId(id);
IndexRequest indexRequest = new IndexRequest(Constant.INDEX)
.id(id)
.source(JSON.toJSONString(document), XContentType.JSON);
bulkRequest.add(indexRequest);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
return bulkResponse.status().equals(RestStatus.OK);
}
//查看文档
public UserDocument getUserDocument(String id) throws IOException {
GetRequest getRequest = new GetRequest(Constant.INDEX, id);
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
UserDocument result = new UserDocument();
if (getResponse.isExists()) {
String sourceAsString = getResponse.getSourceAsString();
result = JSON.parseObject(sourceAsString, UserDocument.class);
} else {
log.error("没有找到该 id 的文档");
}
return result;
}
//更新文档
public Boolean updateUserDocument(UserDocument document) throws Exception {
UserDocument resultDocument = getUserDocument(document.getId());
UpdateRequest updateRequest = new UpdateRequest(Constant.INDEX, resultDocument.getId());
updateRequest.doc(JSON.toJSONString(document), XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
return updateResponse.status().equals(RestStatus.OK);
}
//删除文档
public String deleteUserDocument(String id) throws Exception {
DeleteRequest deleteRequest = new DeleteRequest(Constant.INDEX, id);
DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);
return response.getResult().name();
}
//搜索操作
public List<UserDocument> searchUserByCity(String city) throws Exception {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(Constant.INDEX);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", city);
searchSourceBuilder.query(termQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
return getSearchResult(searchResponse);
}
//聚合搜索
public List<UserCityDTO> aggregationsSearchUser() throws Exception {
SearchRequest searchRequest = new SearchRequest(Constant.INDEX);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_city")
.field("city")
.subAggregation(AggregationBuilders
.avg("average_age")
.field("age"));
searchSourceBuilder.aggregation(aggregation);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
Terms byCityAggregation = aggregations.get("by_city");
List<UserCityDTO> userCityList = new ArrayList<>();
for (Terms.Bucket buck : byCityAggregation.getBuckets()) {
UserCityDTO userCityDTO = new UserCityDTO();
userCityDTO.setCity(buck.getKeyAsString());
userCityDTO.setCount(buck.getDocCount());
// 获取子聚合
Avg averageBalance = buck.getAggregations().get("average_age");
userCityDTO.setAvgAge(averageBalance.getValue());
userCityList.add(userCityDTO);
}
return userCityList;
}
}
调用(因为测试 所以直接通过controller调用)
package com.example.test_docker.controller;
import com.example.test_docker.enerty.UserDocument;
import com.example.test_docker.service.EsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
/**
* @Author: yjj
* @Date: 2022/06/28/16:26
* @Description:
*/
@RestController
@RequestMapping("con")
public class HelloWordController {
@Autowired
EsService esService;
@RequestMapping("test")
public String hello() {
return "hello Word !";
}
@RequestMapping("creIndex")
public String creIndex() throws IOException {
esService.createUserIndex("user");
return "hello Word !";
}
@RequestMapping("creUser")
public String creIndex(@RequestBody UserDocument user) throws Exception {
if (esService.createUserDocument(user)){
return "插入用户成功"+user.toString();
}
return "失败 !";
}
@RequestMapping("getUser")
public UserDocument getUser(@RequestBody UserDocument user) throws Exception {
return esService.getUserDocument(user.getId());
}
}
参考
https://www.bilibili.com/video/BV1h3411P7cM?p=9&spm_id_from=pageDriver
https://blog.csdn.net/qq_24950043/article/details/121348252
https://zhuanlan.zhihu.com/p/159138736

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)