
openGauss数据库性能调优概述及实例分析
目录调优思路概述调优流程确定性能调优范围性能因素调优范围确定硬件瓶颈点分析CPU内存I/O网络查询最耗性能的SQL分析作业是否被阻塞调优思路概述openGauss的总体性能调优思路为性能瓶颈点分析、关键参数调整以及SQL调优。在调优过程中,通过系统资源、吞吐量、负载等因素来帮助定位和分析性能问题,使系统性能达到可接受的范围。openGauss性能调优过程需要综合考虑多方面因素,因此,调优人员应对系
目录
调优思路概述
openGauss的总体性能调优思路为性能瓶颈点分析、关键参数调整以及SQL调优。在调优过程中,通过系统资源、吞吐量、负载等因素来帮助定位和分析性能问题,使系统性能达到可接受的范围。
openGauss性能调优过程需要综合考虑多方面因素,因此,调优人员应对系统软件架构、软硬件配置、数据库配置参数、并发控制、查询处理和数据库应用有广泛而深刻的理解。

须知:
性能调优过程有时候需要重启openGauss,可能会中断当前业务。因此,业务上线后,当性能调优操作需要重启openGauss时,操作窗口时间需向管理部门提出申请,经批准后方可执行。
调优流程
调优流程如图1所示。
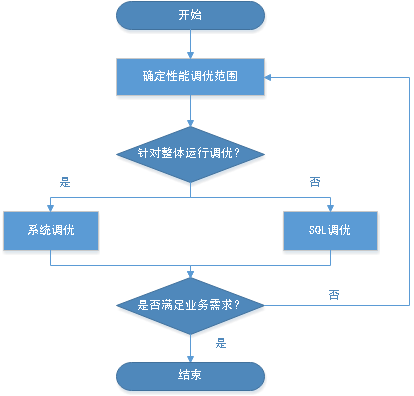
调优各阶段说明,如表1所示。
表 1 openGauss性能调优流程说明
| 获取openGauss节点的CPU、内存、I/O和网络资源使用情况,确认这些资源是否已被充分利用,是否存在瓶颈点。 | |
| 进行操作系统级以及数据库系统级的调优,更充分地利用机器的CPU、内存、I/O和网络资源,避免资源冲突,提升整个系统查询的吞吐量。 | |
|
确定性能调优范围
数据库性能调优通常发生在用户对业务的执行效率不满意,期望通过调优加快业务执行的情况下。正如性能因素小节所述,数据库性能受影响因素多,从而性能调优是一项复杂的工程,有些时候无法系统性地说明和解释,而是依赖于DBA的经验判断。尽管如此,此处还是期望能尽量系统性的对性能调优方法加以说明,方便应用开发人员和刚接触openGauss的DBA参考。
性能因素
多个性能因素会影响数据库性能,了解这些因素可以帮助定位和分析性能问题。
-
系统资源
数据库性能在很大程度上依赖于磁盘的I/O和内存使用情况。为了准确设置性能指标,用户需要了解openGauss部署硬件的基本性能。CPU、硬盘、磁盘控制器、内存和网络接口等这些硬件性能将显著影响数据库的运行速度。
-
负载
负载等于数据库系统的需求总量,它会随着时间变化。总体负载包含用户查询、应用程序、并行作业、事务以及数据库随时传递的系统命令。比如:多用户在执行多个查询时会提高负载。负载会显著地影响数据库的性能。了解工作负载高峰期可以帮助用户更合理地利用系统资源,更有效地完成系统任务。
-
吞吐量
使用系统的吞吐量来定义处理数据的整体能力。数据库的吞吐量以每秒的查询次数、每秒的处理事务数量或平均响应时间来测量。数据库的处理能力与底层系统(磁盘I/O、CPU速度、存储器带宽等)有密切的关系,所以当设置数据库吞吐量目标时,需要提前了解硬件的性能。
-
竞争
竞争是指两组或多组负载组件尝试使用冲突的方式使用系统的情况。比如,多条查询视图同一时间更新相同的数据,或者多个大量的负载争夺系统资源。随着竞争的增加,吞吐量下降。
-
优化
数据库优化可以影响到整个系统的性能。在执行SQL制定、数据库配置参数、表设计、数据分布等操作时,启用数据库查询优化器打造最有效的执行计划。
调优范围确定
性能调优主要通过查看openGauss节点的CPU、内存、I/O和网络这些硬件资源的使用情况,确认这些资源是否已被充分利用,是否存在瓶颈点,然后针对性调优。
-
如果某个资源已达瓶颈,则:
- 检查关键的操作系统参数和数据库参数是否合理设置,进行系统调优指南。
- 通过查询最耗时的SQL语句、跑不出来的SQL语句,找出耗资源的SQL,进行SQL调优指南。
-
如果所有资源均未达瓶颈,则表明性能仍有提升潜力。可以查询最耗时的SQL语句,或者跑不出来的SQL语句,进行针对性的SQL调优指南。
-
硬件瓶颈点分析
获取openGauss节点的CPU、内存、I/O和网络资源使用情况,确认这些资源是否已被充分利用,是否存在瓶颈点。
-
查询最耗性能的SQL
-
分析作业是否被阻塞
硬件瓶颈点分析
- CPU:通过top命令查看openGauss内节点CPU使用情况,分析是否存在由于CPU负载过高导致的性能瓶颈。
- 内存:通过top命令查看openGauss节点内存使用情况,分析是否存在由于内存占用率过高导致的性能瓶颈。
- I/O:通过iostat、pidstat命令或openGauss健康检查工具查看openGauss内节点I/O繁忙度和吞吐量,分析是否存在由于I/O导致的性能瓶颈。
- 网络:通过sar或ifconfig命令查看openGauss内节点网络使用情况,分析是否存在由于网络导致的性能瓶颈。
CPU
通过top命令查看openGauss内节点CPU使用情况,分析是否存在由于CPU负载过高导致的性能瓶颈。
查看CPU状况
查询服务器CPU的使用情况主要通过以下方式:
在所有存储节点,逐一执行top命令,查看CPU占用情况。执行该命令后,按“1”键,可查看每个CPU核的使用率。
复制代码top - 17:05:04 up 32 days, 20:34, 5 users, load average: 0.02, 0.02, 0.00
Tasks: 124 total, 1 running, 123 sleeping, 0 stopped, 0 zombie
Cpu0 : 0.0%us, 0.3%sy, 0.0%ni, 69.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu1 : 0.3%us, 0.3%sy, 0.0%ni, 69.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu2 : 0.3%us, 0.3%sy, 0.0%ni, 69.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu3 : 0.3%us, 0.3%sy, 0.0%ni, 69.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 8038844k total, 7165272k used, 873572k free, 530444k buffers
Swap: 4192924k total, 4920k used, 4188004k free, 4742904k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
35184 omm 20 0 822m 421m 128m S 0 5.4 5:28.15 gaussdb
1 root 20 0 13592 820 784 S 0 0.0 1:16.62 init
分析时,请主要关注进程占用的CPU利用率。
其中,统计信息中“us”表示用户空间占用CPU百分比,“sy”表示内核空间占用CPU百分比,“id”表示空闲CPU百分比。如果“id”低于10%,即表明CPU负载较高,可尝试通过降低本节点任务量等手段降低CPU负载。
性能参数分析
-
使用“top -H”命令查看CPU,显示内容如下所示。
复制代码
14 root 20 0 0 0 0 S 0 0.0 0:16.41 events/3 top - 14:22:49 up 5 days, 21:51, 2 users, load average: 0.08, 0.08, 0.06 Tasks: 312 total, 1 running, 311 sleeping, 0 stopped, 0 zombie Cpu(s): 1.3%us, 0.7%sy, 0.0%ni, 95.0%id, 2.4%wa, 0.5%hi, 0.2%si, 0.0%st Mem: 8038844k total, 5317668k used, 2721176k free, 180268k buffers Swap: 4192924k total, 0k used, 4192924k free, 2886860k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3105 root 20 0 50492 11m 2708 S 3 0.1 22:22.56 acc-snf 4015 gdm 20 0 232m 23m 11m S 0 0.3 11:34.70 gdm-simple-gree 51001 omm 20 0 12140 1484 948 R 0 0.0 0:00.94 top 54885 omm 20 0 615m 396m 116m S 0 5.1 0:09.44 gaussdb 1 root 20 0 13592 944 792 S 0 0.0 0:08.54 init -
根据查询结果中“Cpu(s)”分析是系统CPU(sy)还是用户CPU(us)占用过高。
- 如果是系统CPU占用过高,需要查找异常系统进程进行处理。
- 如果是“USER”为omm的openGauss进程CPU占用过高,请根据目前运行的业务查询内容,对业务SQL进行优化。请根据以下步骤,并结合当前正在运行的业务特征进行分析,是否该程序处于死循环逻辑。
a. 使用“top -H -p pid”查找进程内占用的CPU百分比较高的线程,进行分析。
复制代码
top -H -p 54952查询结果如下所示,top中可以看到占用CPU很高的线程,下面以线程54775为主,分析其为何占用CPU过高。
复制代码
top - 14:23:27 up 5 days, 21:52, 2 users, load average: 0.04, 0.07, 0.05 Tasks: 13 total, 0 running, 13 sleeping, 0 stopped, 0 zombie Cpu(s): 0.9%us, 0.4%sy, 0.0%ni, 97.3%id, 1.1%wa, 0.2%hi, 0.1%si, 0.0%st Mem: 8038844k total, 5322180k used, 2716664k free, 180316k buffers Swap: 4192924k total, 0k used, 4192924k free, 2889860k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 54775 omm 20 0 684m 424m 131m S 0 5.4 0:00.32 gaussdb 54951 omm 20 0 684m 424m 131m S 0 5.4 0:00.84 gaussdb 54732 omm 20 0 684m 424m 131m S 0 5.4 0:00.24 gaussdb 54758 omm 20 0 684m 424m 131m S 0 5.4 0:00.00 gaussdb 54759 omm 20 0 684m 424m 131m S 0 5.4 0:00.02 gaussdb 54773 omm 20 0 684m 424m 131m S 0 5.4 0:02.79 gaussdb 54780 omm 20 0 684m 424m 131m S 0 5.4 0:00.04 gaussdb 54781 omm 20 0 684m 424m 131m S 0 5.4 0:00.21 gaussdb 54782 omm 20 0 684m 424m 131m S 0 5.4 0:00.02 gaussdb 54798 omm 20 0 684m 424m 131m S 0 5.4 0:16.70 gaussdb 54952 omm 20 0 684m 424m 131m S 0 5.4 0:07.51 gaussdb 54953 omm 20 0 684m 424m 131m S 0 5.4 0:00.81 gaussdb 54954 omm 20 0 684m 424m 131m S 0 5.4 0:06.54 gaussdbb. 使用“gstack ”查看进程内各线程的函数调用栈。查找上一步骤中占用CPU较高的线程ID对应的线程号。
复制代码
gstack 54954查询结果如下所示,其中线程ID54775对应线程号是10。
复制代码
192.168.0.11:~ # gstack 54954 Thread 10 (Thread 0x7f95a5fff710 (LWP 54775)): #0 0x00007f95c41d63c6 in poll () from /lib64/libc.so.6 #1 0x0000000000d3d2d3 in WaitLatchOrSocket(Latch volatile*, int, int, long) () #2 0x000000000095ed25 in XLogPageRead(XLogRecPtr*, int, bool, bool) () #3 0x000000000095f6dd in ReadRecord(XLogRecPtr*, int, bool) () #4 0x000000000096aef0 in StartupXLOG() () #5 0x0000000000d5607a in StartupProcessMain() () #6 0x00000000009e19f9 in AuxiliaryProcessMain(int, char**) () #7 0x0000000000d50135 in SubPostmasterMain(int, char**) () #8 0x0000000000d504ec in MainStarterThreadFunc(void*) () #9 0x00007f95c79b85f0 in start_thread () from /lib64/libpthread.so.0 #10 0x00007f95c41df84d in clone () from /lib64/libc.so.6 #11 0x0000000000000000 in ?? ()
内存
通过top命令查看openGauss节点内存使用情况,分析是否存在由于内存占用率过高导致的性能瓶颈。
查看内存状况
查询服务器内存的使用情况主要通过以下方式:
执行top命令,查看内存占用情况。执行该命令后,按“Shift+M”键,可按照内存大小排序。
复制代码top - 11:38:26 up 2 days, 17:59, 10 users, load average: 0.01, 0.05, 0.15
Tasks: 685 total, 1 running, 684 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 19740646+total, 23503420 free, 15947100 used, 15795595+buff/cache
KiB Swap: 8242172 total, 8242172 free, 0 used. 13366219+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
29838 omm 20 0 1373104 456904 175248 S 3.6 0.2 98:53.16 gaussdb
27789 omm 20 0 150732 4136 3216 S 0.0 0.0 0:00.00 gsql
45659 omm 20 0 117164 4052 1860 S 0.0 0.0 0:00.24 bash
8087 omm 20 0 117164 4000 1848 S 0.0 0.0 0:00.05 bash
27459 omm 20 0 117160 4000 1848 S 0.0 0.0 0:00.04 bash
33619 omm 20 0 117120 3852 1740 S 0.0 0.0 0:00.04 bash
27282 omm 20 0 117120 3840 1728 S 0.0 0.0 0:00.03 bash
9923 omm 20 0 158064 2932 1612 R 0.3 0.0 0:00.04 top
分析时,请主要关注gaussdb进程占用的内存百分比(%MEM)、整系统的剩余内存。
显示信息中的主要属性解释如下:
- total:物理内存总量。
- used:已使用的物理内存总量。
- free:空闲内存总量。
- buffers:进程使用的虚拟内存总量。
- %MEM:进程占用的内存百分比。
- VIRT:进程使用的虚拟内存总量,VIRT=SWAP+RES。
- SWAP:进程使用的虚拟内存中已被换出到交换分区的量。
- RES:进程使用的虚拟内存中未被换出的量。
- SHR:共享内存大小。
性能参数分析
-
以root用户执行“free”命令查看cache的占用情况。
复制代码
free查询结果如下所示:
复制代码
total used free shared buffers cached Mem: 8038844 6336184 1702660 0 375896 2880912 -/+ buffers/cache: 3079376 4959468 Swap: 4192924 0 4192924 -
若“cache”占用过高,请执行如下命令开启自动清除缓存功能。
复制代码
sh openGauss-server/src/bin/scripts/run_drop_cache.sh其中,openGauss-server为仓库代码,下载地址
https://gitee.com/opengauss/openGauss-server.git -
若用户内存占用过高,需查看执行计划,重点分析以下内容。
是否有不合理的join顺序。例如,多表关联时,执行计划中优先关联的两表的中间结果集比较大,导致最终执行代价比较大。
I/O
通过iostat、pidstat命令或openGauss健康检查工具查看openGauss内节点I/O繁忙度和吞吐量,分析是否存在由于I/O导致的性能瓶颈。
查看I/O状况
查询服务器I/O的方法主要有以下三种方式:
-
使用iostat命令查看I/O情况。此命令主要关注单个硬盘的I/O使用率和每秒读取、写入的数量。
复制代码
iostat -xm 1 //1为间隔时间 Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sdc 0.01 519.62 2.35 44.10 0.31 2.17 109.66 0.68 14.62 2.80 15.25 0.31 1.42 sdb 0.01 515.95 5.84 44.78 0.89 2.16 123.51 0.72 14.19 1.55 15.84 0.31 1.55 sdd 0.02 519.93 2.36 43.91 0.32 2.17 110.16 0.65 14.12 2.58 14.74 0.30 1.38 sde 0.02 520.26 2.34 45.17 0.31 2.18 107.46 0.80 16.86 2.92 17.58 0.34 1.63 sda 12.07 15.72 3.97 5.01 0.07 0.08 34.11 0.28 30.64 10.11 46.92 0.98 0.88“rMB/s”为每秒读取的MB数,“wMB/s”为每秒写入的MB数,“%util”为硬盘使用率。
-
使用pidstat命令查看I/O情况。此命令主要关注单个进程每秒读取、写入的数量。
复制代码
pidstat -d 1 10 //1为采样间隔时间,10为采样次数 03:17:12 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command 03:17:13 PM 1006 36134 0.00 59436.00 0.00 gaussdb“kB_rd/s”为每秒读取的kB数,“kB_wr/s”为每秒写入的kB数。
-
使用gs_checkperf工具对openGauss进行性能检查,需要以omm用户登录。
复制代码
gs_checkperf Cluster statistics information: Host CPU busy time ratio : .69 % MPPDB CPU time % in busy time : .35 % Shared Buffer Hit ratio : 99.92 % In-memory sort ratio : 100.00 % Physical Reads : 8581 Physical Writes : 2603 DB size : 281 MB Total Physical writes : 1944 Active SQL count : 3 Session count : 11显示结果包括每个节点的I/O使用情况,物理读写次数。
也可以使用gs_checkperf –detail命令查询每个节点的详细性能信息。
性能参数分析
-
检查磁盘空间使用率,建议不要超过60%。
复制代码
df -T -
若I/O持续过高,建议尝试以下方式降低I/O。
- 降低并发数。
-
对查询相关表做VACUUM FULL。
复制代码
vacuum full tablename;
说明:
建议用户在系统空闲时进行VACUUM FULL操作,VACUUM FULL操作会造成短时间内I/O负载重,反而不利于降低I/O。
网络
通过sar或ifconfig命令查看openGauss内节点网络使用情况,分析是否存在由于网络导致的性能瓶颈。
查看网络状况
查询服务器网络状况的方法主要有以下两种方式:
-
使用root用户身份登录服务器,执行如下命令查看服务器网络连接。
复制代码
SIA1000056771:~ # ifconfig eth0 Link encap:Ethernet HWaddr 28:6E:D4:86:7D:D5 inet addr:10.180.123.163 Bcast:10.180.123.255 Mask:255.255.254.0 inet6 addr: fe80::2a6e:d4ff:fe86:7dd5/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:5669314 errors:0 dropped:0 overruns:0 frame:0 TX packets:4955927 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:508077795 (484.5 Mb) TX bytes:818004366 (780.1 Mb) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:711938 errors:0 dropped:0 overruns:0 frame:0 TX packets:711938 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:164158862 (156.5 Mb) TX bytes:164158862 (156.5 Mb)- “errors”表示收包错误的总数量。
- “dropped”表示数据包已经进入了Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃的总数量。
- “overruns”表示Ring Buffer队列中被丢弃的报文数目,由于Ring Buffer(aka Driver Queue)传输的IO大于kernel能够处理的IO导致。
分析时,如果发现上述三个值持续增长,则表示网络负载过大或者存在网卡、内存等硬件故障。
-
使用sar命令查看服务器网络连接。
复制代码
sar -n DEV 1 //1为间隔时间 Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil Average: lo 1926.94 1926.94 25573.92 25573.92 0.00 0.00 0.00 0.00 Average: A1-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: A1-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: NIC0 5.17 1.48 0.44 0.92 0.00 0.00 0.00 0.00 Average: NIC1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: A0-0 8173.06 92420.66 97102.22 133305.09 0.00 0.00 0.00 0.00 Average: A0-1 11431.37 9373.06 156950.45 494.40 0.00 0.00 0.00 0.00 Average: B3-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: B3-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00“rxkB/s”为每秒接收的kB数,“txkB/s”为每秒发送的kB数。
分析时,请主要关注每个网卡的传输量和是否达到传输上限。
检查完后,按“Ctrl+Z”键退出查看。
查询最耗性能的SQL
系统中有些SQL语句运行了很长时间还没有结束,这些语句会消耗很多的系统性能,请根据本章内容查询长时间运行的SQL语句。
- 以操作系统用户omm登录数据库节点。
-
使用如下命令连接数据库。
gsql -d postgres -p 8000postgres为需要连接的数据库名称,8000为数据库节点的端口号。
连接成功后,系统显示类似如下信息:
gsql ((openGauss 1.0 build 290d125f) compiled at 2020-05-08 02:59:43 commit 2143 last mr 131 Non-SSL connection (SSL connection is recommended when requiring high-security) Type "help" for help. openGauss=# -
查询系统中长时间运行的查询语句。
SELECT current_timestamp - query_start AS runtime, datname, usename, query FROM pg_stat_activity where state != 'idle' ORDER BY 1 desc;查询后会按执行时间从长到短顺序返回查询语句列表,第一条结果就是当前系统中执行时间最长的查询语句。返回结果中包含了系统调用的SQL语句和用户执行SQL语句,请根据实际找到用户执行时间长的语句。
若当前系统较为繁忙,可以通过限制current_timestamp - query_start大于某一阈值来查看执行时间超过此阈值的查询语句。
SELECT query FROM pg_stat_activity WHERE current_timestamp - query_start > interval '1 days'; -
设置参数track_activities为on。
SET track_activities = on;当此参数为on时,数据库系统才会收集当前活动查询的运行信息。
-
查看正在运行的查询语句。
以查看视图pg_stat_activity为例:
SELECT datname, usename, state FROM pg_stat_activity; datname | usename | state | ----------+---------+--------+ postgres | omm | idle | postgres | omm | active | (2 rows)如果state字段显示为idle,则表明此连接处于空闲,等待用户输入命令。
如果仅需要查看非空闲的查询语句,则使用如下命令查看:
SELECT datname, usename, state FROM pg_stat_activity WHERE state != 'idle'; -
分析长时间运行的查询语句状态。
- 若查询语句处于正常状态,则等待其执行完毕。
-
若查询语句阻塞,则通过如下命令查看当前处于阻塞状态的查询语句:
SELECT datname, usename, state, query FROM pg_stat_activity WHERE waiting = true;查询结果中包含了当前被阻塞的查询语句,该查询语句所请求的锁资源可能被其他会话持有,正在等待持有会话释放锁资源。

说明:
只有当查询阻塞在系统内部锁资源时,waiting字段才显示为true。尽管等待锁资源是数据库系统最常见的阻塞行为,但是在某些场景下查询也会阻塞在等待其他系统资源上,例如写文件、定时器等。但是这种情况的查询阻塞,不会在视图pg_stat_activity中体现。
分析作业是否被阻塞
数据库系统运行时,在某些业务场景下查询语句会被阻塞,导致语句运行时间过长,可以强制结束有问题的会话。
- 以操作系统用户omm登录数据库节点。
-
使用如下命令连接数据库。
gsql -d postgres -p 8000postgres为需要连接的数据库名称,8000为数据库节点的端口号。
连接成功后,系统显示类似如下信息:
gsql ((openGauss 1.0 build 290d125f) compiled at 2020-05-08 02:59:43 commit 2143 last mr 131 Non-SSL connection (SSL connection is recommended when requiring high-security) Type "help" for help. openGauss=# -
查看阻塞的查询语句及阻塞查询的表、模式信息。
SELECT w.query as waiting_query, w.pid as w_pid, w.usename as w_user, l.query as locking_query, l.pid as l_pid, l.usename as l_user, t.schemaname || '.' || t.relname as tablename from pg_stat_activity w join pg_locks l1 on w.pid = l1.pid and not l1.granted join pg_locks l2 on l1.relation = l2.relation and l2.granted join pg_stat_activity l on l2.pid = l.pid join pg_stat_user_tables t on l1.relation = t.relid where w.waiting;该查询返回线程ID、用户信息、查询状态,以及导致阻塞的表、模式信息。
-
使用如下命令结束相应的会话。其中,139834762094352为线程ID。
SELECT PG_TERMINATE_BACKEND(139834762094352);显示类似如下信息,表示结束会话成功。
PG_TERMINATE_BACKEND ---------------------- t (1 row)显示类似如下信息,表示用户正在尝试结束当前会话,此时仅会重连会话,而不是结束会话。
FATAL: terminating connection due to administrator command FATAL: terminating connection due to administrator command The connection to the server was lost. Attempting reset: Succeeded.
说明:
gsql客户端使用PG_TERMINATE_BACKEND函数终止本会话后台线程时,客户端不会退出而是自动重连。
本篇内容就到这里了,感谢小伙伴们的学习。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 35
35 0
0- 0



 已为社区贡献384条内容
已为社区贡献384条内容

所有评论(0)