
【参赛作品53】openGauss SQL执行器
一、源码分析:1、ExecutorStart 代码调试过程以及分析ExecutorStart 部分代码主要需要的数据结构有:QueryDesc:查询描述符,实际是需要执行的SQL语句的相关信息,包含由CreateQueryDesc函数设置的操作类型、规划器的输出计划树、元组输出的接收器、查询环境变量以及由ExecutorStart函数设置的结果元组tuples描述、执行器状态、和per-plan-
作者:的个人主页
源码分析:
ExecutorStart 部分代码主要需要的数据结构有:QueryDesc:查询描述符,实际是需要执行的SQL语句的相关信息,包含由CreateQueryDesc函数设置的操作类型、规划器的输出计划树、元组输出的接收器、查询环境变量以及由ExecutorStart函数设置的结果元组tuples描述、执行器状态、和per-plan-node状态树。具体结构见后面的执行器的主要数据结构分析 CmdType:由 Query 或 PlannedStmt 表示的操作类型的枚举;包括CMD_SELECT、CMD_UPDATE, CMD_INSERT, CMD_DELETE, CMD_MERGE,等
PlanState :PlanState是所有PlanState-type节点的虚父类,从未被实例化另外一个传入 Executor 的参数是 eflag,它的定义在 executor.h 中

从 ExecutorStart 开始调试:这个例程必须在任何执行的开始被调用,这个函数先检查是否存在 hook 函数,hook 是官方留给第三方插件使用的。如果存在则执行 hook 函数,否则执行标准 Executor。
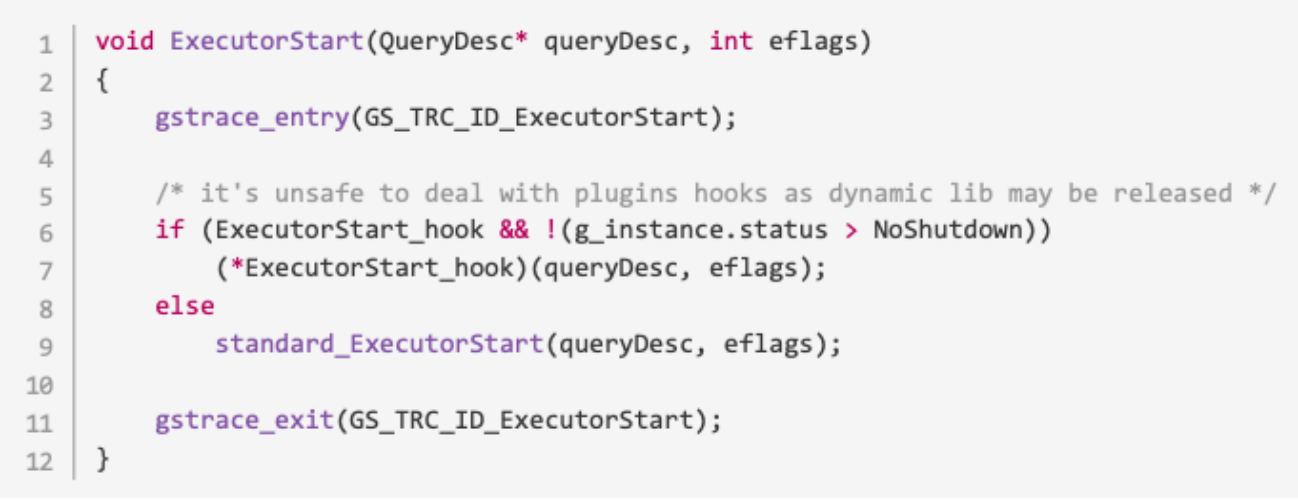
调试过程如下:
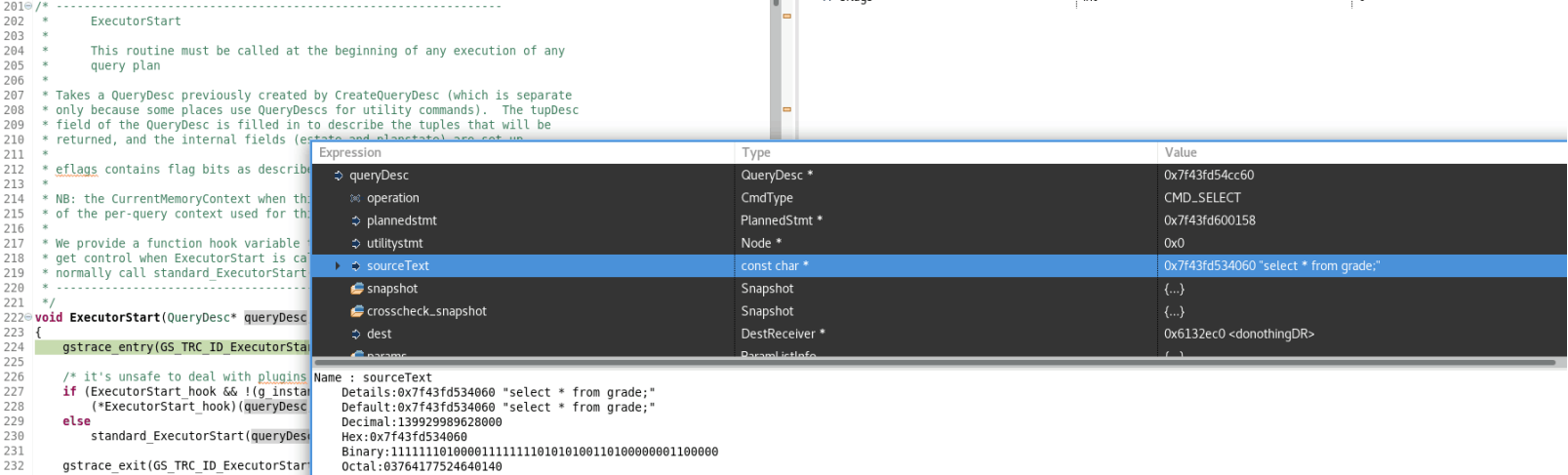
1、执行命令 select * from student; ,分析传入的数据结构queryDesc和eflags:

2、向下执行,发现此时 hook 上挂载了 explain_ExecutorStart 函数,于是进入开始执行函数,该函数负责检查是否需要启动审计功能。

3、 explain_ExecutorStart 函数首先调用prev_ExecutorStart函数,而 prev_ExecutorStart 又挂载了 gs_audit_executor_start_hook 函数,该函数负责启动审计功能 4、之后调用了标准 ExecutorStart()函数。分别进入如下几个函数,进行了一些操作。
(1)estate = CreateExecutorState();

创建并初始化一个EState节点,它是用于整个Executor调用的工作存储。*主要地,这将创建每查询内存上下文用于保存直到查询结束为止的所有工作数据。
注意,每查询上下文将成为调用者的子上下文
(2)ExecAssignExprContext。
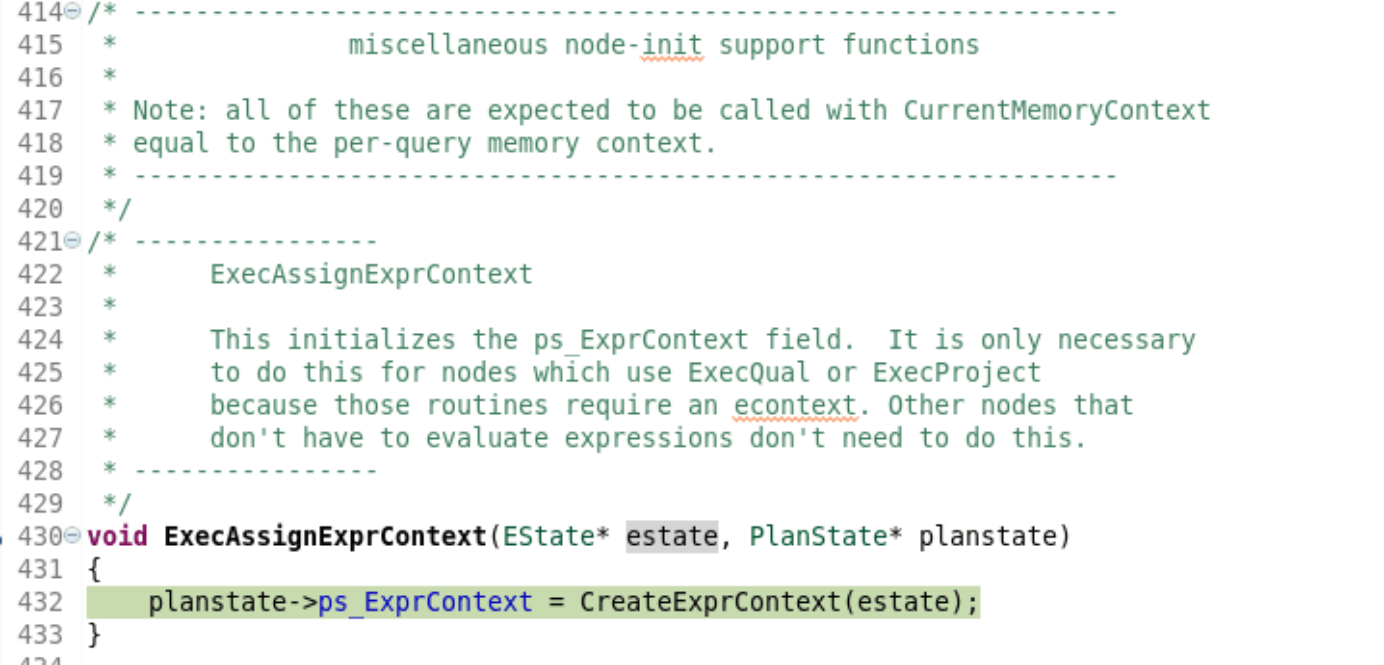
/* ----------------------------------------------------------------
*其他node-init支持函数
*注意:所有这些都被CurrentMemoryContext调用等于每个查询的内存上下文。<o:p></o:p>
初始化ps_ExprContext字段。这只是必要的为使用ExecQual或ExecProject的节点执行此操作,因为那些例程需要一个上下文。其他节点,不需要计算表达式不需要这样做。 ————————(3)createexprcontext在EState中为表达式计算创建上下文。一个executor运行可能需要多个exprcontext(我们通常为每个Plan节点创建一个exprcontext,并为每个输出元组处理(如约束检查)单独创建一个exprcontext)。每个ExprContext都有自己的“per-tuple”内存上下文。注意,我们没有对调用者的内存上下文做任何假设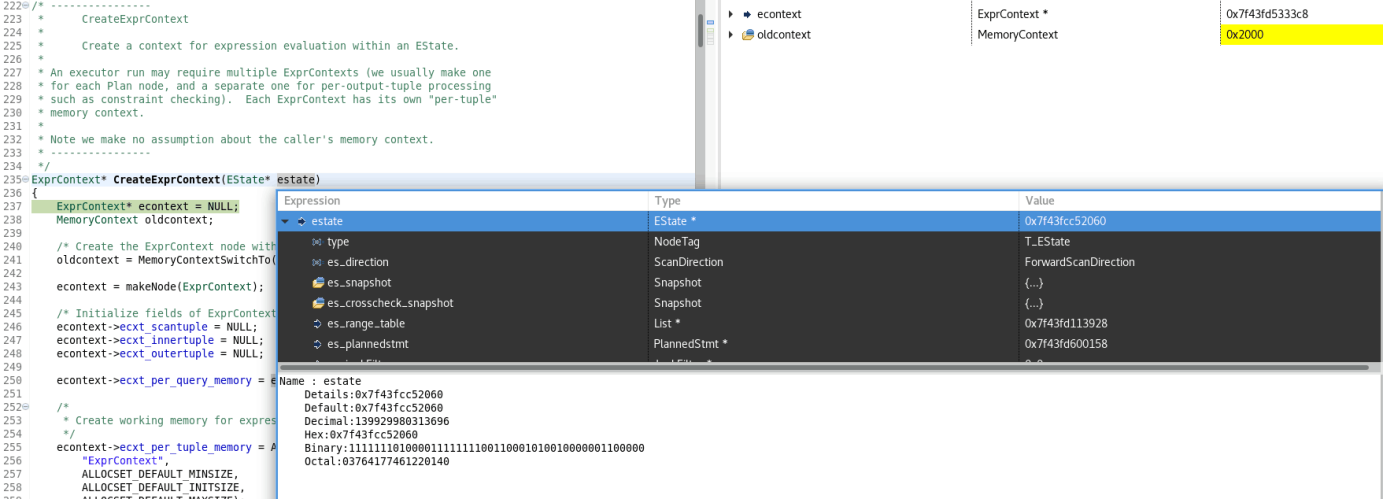 (4) execopenscanrelation打开堆关系被扫描一个基本级别的扫描计划节点。*这应该在节点的ExecInit例程中调用。
(4) execopenscanrelation打开堆关系被扫描一个基本级别的扫描计划节点。*这应该在节点的ExecInit例程中调用。
默认情况下,获取关联的AccessShareLock。但是,如果关系已经被InitPlan锁定,我们就不需要获得任何额外的锁定。这节省了到共享锁管理器的访问。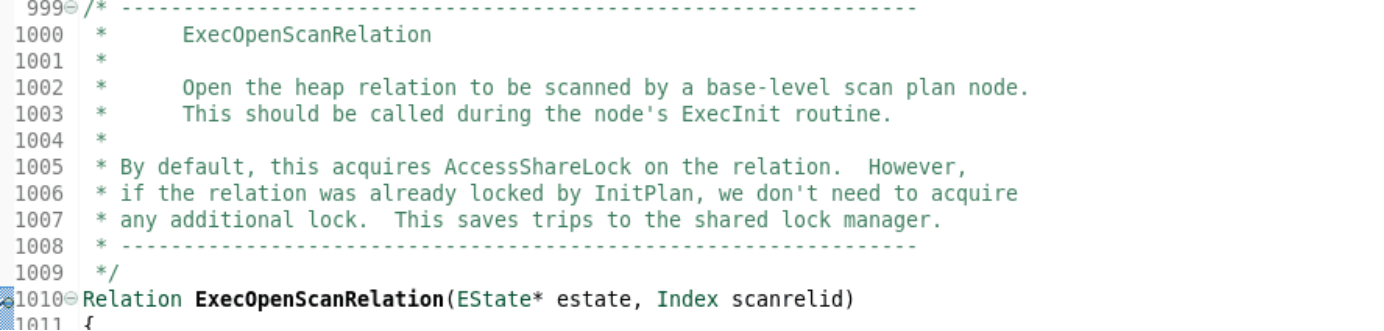
/ ----------------------------------------------------------------2、ExecutorRun 代码调试过程以及分析这是执行器运行的部分 这一部分传入的参数有 QueryDesc 这个和上部分传入的参数相同 ScanDirection 这个是一个枚举类型变量 • -1 表示反方向扫描 • 0 表示无扫描方向 • 1 表示正方向扫描 count
元组最大数目 ExecutorRun 函数是执行器模块的主要例程。它接受来自交通警察(traffic cop)的查询描述符并执行查询计划。 执行此部分时 ExecutorStart 必须已经被调用。
如果 direction 是 NoMovementScanDirection,即为 0,那么除了启动/关闭目的地之外什么都不做。 否则,我们将 在指定方向检索最多 ‘count’ 个元组。注意:count = 0 被解释为没有入口限制,即运行直到完成。 另请注意,计数限制仅适用于检索到的元组,例如不适用于由 ModifyTable 计划节点插入/更新/删除的元组。没有返回值,但输出元组(如果有)被发送到 QueryDesc 中指定的目标接收者;顶层处理的元组数量可以在 Estate- >es_processed 中找到。openGauss 提供了一个函数 hook 变量,让可加载插件在调用 ExecutorRun 时获得控制。这样的插件通常会调用 standard_ExecutorRun()。调试过程如下:1、同样以 select * from student; 为例,此时参数取值如下<o:p></o:p>

2、之后函数调用 exec_explain_plan()对 queryDesc 进行解析3、解析成功后检查是否存在 ExecutorRun_hook, 如果 不存在则执行标准 ExecutorRun。这里同样已经被挂载了 explain_ExecutorRun() <o:p></o:p>
正如注释所说,该函数负责跟踪嵌套深度。一旦深度超出限制,则抛出一个异常。 4、执行完成这部分后,进入到standard_ExecutorRun(queryDesc, direction, count);函数中调用了CreateExprContext函数,在EState中为表达式计算创建上下文。

一个executor运行可能需要多个exprcontext(我们通常为每个Plan节点创建一个exprcontext,并为每个输出元组处理(如约束检查)单独创建一个exprcontext)。每个ExprContext都有自己的“per-tuple”内存上下文。注意,我们没有对调用者的内存上下文做任何假设。每一个元组都在execProcnode中获得分发函数按节点调用函数,之后在三个execScan中一起进行组合扫描,扫描结束回到run函数5、最后回到 ExecutorRun 函数,进行 SQL 自调,查询执行完毕时,基于运行时信息分析查询计划问题。本次调试中, 查询中并没有问题。之后顺利退出此函数。 3、ExecutorFinish & ExecutorEnd 代码调试过程以及分析此例程必须在最后一次 ExecutorRun 调用之后调用。它执行清理,例如触发 AFTER 触发器。它与 ExecutorEnd 是分开的,因为 EXPLAIN ANALYZE 需要在总运行时间中包含这些操作。调试过程如下:1、ExecutorFinish这一部分代码比较简短,依旧是用select from student;来观察;2、hook 上同样被挂载了函数 explain_ExecutorFinish ,该函数的任务依旧是在清理时跟踪嵌套深度,如果深度超出限制则抛出异常。该部分执行结束后退出。3、进入standard_ExecutorFinish(queryDesc),该部分标准执行代码比较短:主要是运行 ModifyTable 节点完成 以及执行队列后触发器,除非被告知不要;4、最后轮到 ExecutorEnd:

5、hook 上被挂载了函数 hypo_executorEnd_hook
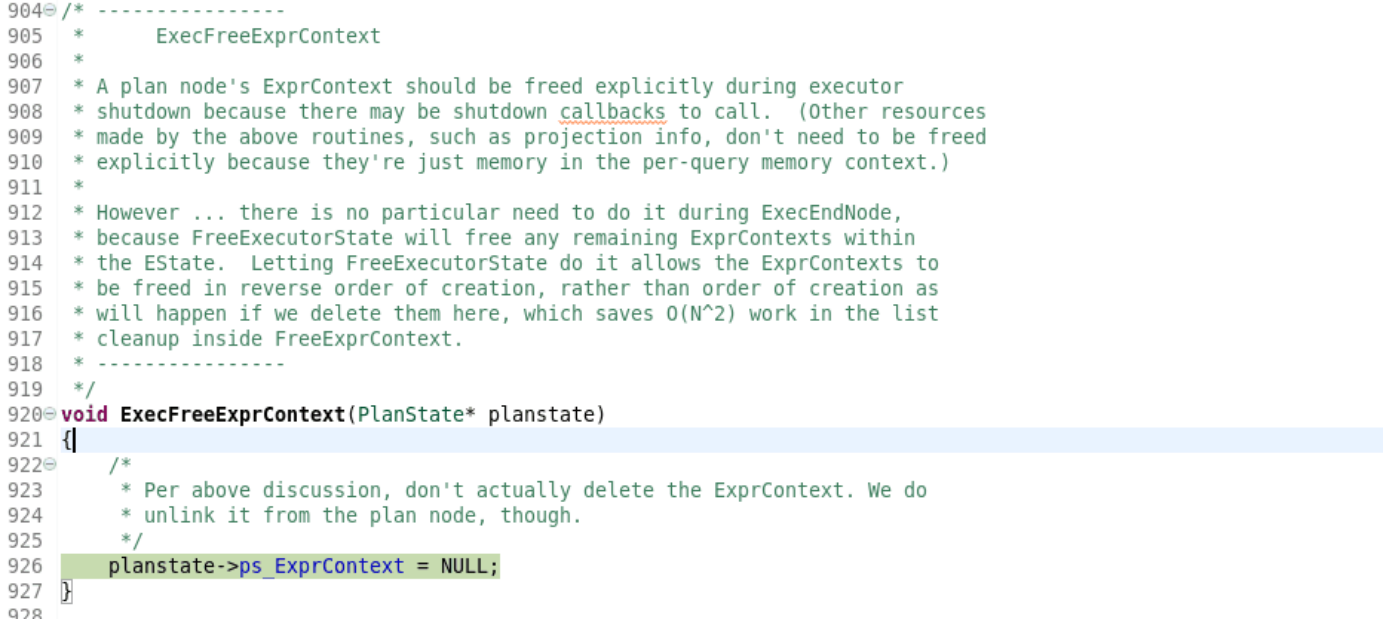
它的作用是重置 isExplain 标志,此时查询已经执行完了,所以对标志进行重置。为下一轮查询做好工作。6、进入standard_ExecutorEnd;相关函数有:(1)ExecFreeExprContex计划节点的ExprContext应该在执行器关闭期间被显式释放,因为可能有需要调用的关闭回调。(上述例程生成的其他资源,如投影信息,不需要显式释放,因为它们只是每查询内存上下文中的内存。)然而……在ExecEndNode期间不需要这样做,因为FreeExecutorState会释放EState中的任何剩余的ExprContexts。让FreeExecutorState这样做,可以让ExprContexts以相反的创建顺序被释放,而不是像我们在这里删除它们时那样按照创建顺序被释放,这就节省了在FreeExprContext中清除列表的O(N^2)工作。
(2)FreeExecutorState*释放一个EState以及所有剩余的工作存储。
注意:这不是负责释放非内存资源,如打开关系或缓冲引脚。但是它将关闭EState内任何仍然活跃的exprcontext。对于EState仅用于表达式求值而不是运行完整的Plan的情况,这已经是足够的清理工作了这可以在任何内存上下文中调用…只要它不是被释放的那一种。

运行机制:1、Postgres进程opengauss与PostgreSQL类似,是多进程结构的数据库。在PostgreSQL中主要有postmaster, postgres, vacuum, bgwriter, pgarch, walwriter, pgstat等进程,postmaster负责在启动数据库的时候创建共享内存 并初始化各种内部数据结构,如锁表,数据库缓冲区等,该进程在数据库中只有一个。在数据库启动以后负责监听用户 请求,创建postgres进程来为用户服务。
Postgres进程负责执行客户端发出的所有的SQL语句及自定义函数。在opengauss中与Postgres进程相关的代码在src/gusskernel/process/tcop/postgres.cpp文件中,Postgres进程的入口函数是PostgresMain。

PostgresMain首先进行一些初始化工作,然后使用语句for (; 进入一个无限循环状态,等待客户端发来命令请求,接受客户端命令,执行客户端命令,将执行结果返回给客户端。
for (; 无限循环体首先调用ReadCommand从客户端读取一条命令,然后根据命令类型,调用相应的处理函数。<o:p></o:p>
对于可以直接执行的SQL语句(simple query),命令类型的代码是“Q”,主要的处理代码如下:
语句exec_simple_query(query_string)负责解析SQL语句,生成查询计划,执行查询计划,将查询结果返回给客户端。我们组主要进行分析的是opengauss执行查询计划的过程。<o:p></o:p>
<o:p> 2、执行器的整体执行流程执行器(executor)采用优化器创建的计划,并对其进行递归处理以提取所需的行的集合。这本质上是一种需求驱动的流水线执行机制。即每次调用一个计划节点时,它都必须再传送一行,或者报告已完成传送所有行。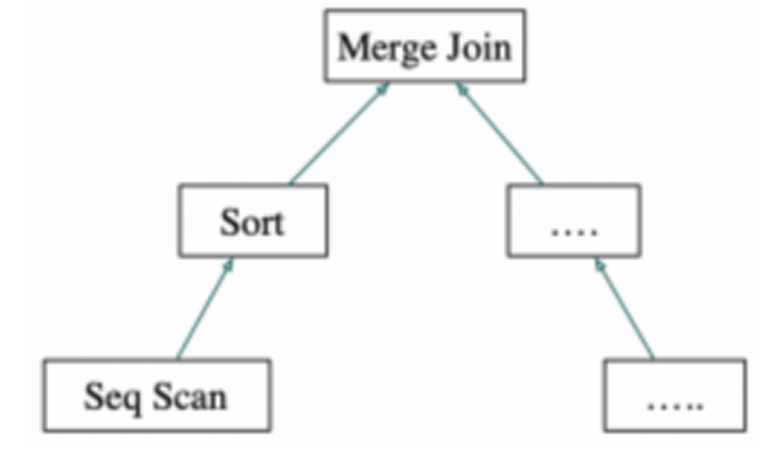
图1:执行计划树示例
如图所示的执行计划树示例,顶部节点是Merge Join节点。在进行任何合并操作之前,必须获取2个元组(MergeJoin节点的2个子计划各返回1个元组)。因此,执行器以递归方式调用自身以处理其子计划(如从左子树的子计划开始)。Merge Join由于要做归并操作,因此它要子计划按序返回元组,从图中可以看出,它的子计划是一个Sort节点。Sort的子节点可能是Seq Scan节点,代表对表的实际读取。执行SeqScan节点会使执行程序从表中获取一行并将其返回到调用节点。Sort节点将反复调用其子节点以获得所有要排序的行。当输入完毕时(如子节点返回NULL而不是新行),Sort算子对获取的元组进行排序,它每次返回1个元组,即已排序的第1行。然后不断排序并向父节点传递剩余的排好序的元组。
如图所示的执行计划树示例,顶部节点是Merge Join节点。在进行任何合并操作之前,必须获取2个元组(MergeJoin节点的2个子计划各返回1个元组)。因此,执行器以递归方式调用自身以处理其子计划(如从左子树的子计划开始)。<o:p></o:p>
Merge Join由于要做归并操作,因此它要子计划按序返回元组,从图中可以看出,它的子计划是一个Sort节点。Sort的子节点可能是Seq Scan节点,代表对表的实际读取。执行SeqScan节点会使执行程序从表中获取一行并将其返回到调用节点。Sort节点将反复调用其子节点以获得所有要排序的行。当输入完毕时(如子节点返回NULL而不是新行),Sort算子对获取的元组进行排序,它每次返回1个元组,即已排序的第1行。然后不断排序并向父节点传递剩余的排好序的元组。
清理阶段。因为执行器在初始化阶段向系统申请了资源,所以在这个阶段要完成对资源的清理。比如在 HashJoin初始化时对 Hash表内存申请的释放。入口函数为 ExecutorFinish ()、ExecutorEnd ()3、执行器的主要数据结构分析QueryDescs: 查询描述符,实际是需要执行的SQL语句的相关信息,包含由CreateQueryDesc函数设置的操作类型、规划器的输出计划树、元组输出的接收器、查询环境变量以及由ExecutorStart函数设置的结果元组tuples描述、执行器状态、和per-plan-node状态树。具体结构如下:
EState:执行器在调用时的主要工作状态,由ExecutorStart函数设置执行器全局状态estate中保存了査询涉及的范围表(es_range_table)、Estate所在的内存上下文(es_query_cxt,也是执行过程中一直保持的内存上下文)、用于在节点间传递元组的全局元组表(es_TupleTable)和每获取一个元组就会回收的内存上下文(es_per_tuple_exprContext) 。;PlanState:PlanState是所有PlanState-type节点的虚父类执行器初始化时,ExecutorStart会根据査询计划树构造执行器全局状态(estate)以及计划节点执行状态(planstate)。在査询计划树的执行过程中,执行器将使用planstate来记录计划节点执行状态和数据,并使用全局状态记录中的es_tupleTable字段在节点间传递结果元组。执行器的清理函数ExecutorEnd将回收执行器全局状态和计划节点执行状态。状态节点之间通过lefttree和righttree指针组织成和査询计划树结构类似的状态节点树,同时,每个状态节点都保存了指向其对应的计划节点的指针(PlanState类型中的Plan字段)。4、执行器的主要函数分析在opengauss中与执行器主要相关的代码在src/gusskernel/runtime/executor/execMain.cpp文件中,主要函数有 ExecutorStart ()、 ExecutorRun ()、ExecutorFinish ()、ExecutorEnd ()。初始化阶段:在这个阶段执行器会完成一些初始化工作,通常的做法是遍历整个执行树,根据每个算子的不同特征进行初始化执行。入口函数为ExecutorStart ()。这个例程必须在任何查询计划的开始执行时调用。它接受一个以前由CreateQueryDesc创建的QueryDesc(它是分开的,只是因为一些地方使用QueryDescs实用命令)。填充QueryDesc的tupDesc字段来描述将返回的元组,并设置内部字段(estate和planstate)。ExecutorStart ()函数代码如下所示:

其中ExecutorStart_hook为钩子函数,是PostgreSQL预留的接口,通过重新编写的钩子函数可以改变postgresql的默认功能,钩子函数通常以hook最为结尾,PostgreSQL预留了非常丰富的接口。因此如果没有特殊需求,一般进入standard_ExecutorStart(queryDesc, eflags)函数。
standard_ExecutorStart(queryDesc, eflags)函数主要做的工作是:构建EState:调用CreateExecutorState()函数,创建每个查询的上下文,切换到每个查询的内存上下文进行启动;如果是非只读查询,设置命令ID以标记输出元组初始化计划状态树: 调用InitPlan(queryDesc, eflags)实现;执行器中对査询计划树的初始化都是从其根节点开始,并递归地对其子节点进行初始化。计划节点的初始化过程一般都会经历如下图所示的几个基本步骤,该过程在完成计划节点的初始化之后会输出与该计划节点对应的PlanState结构指针,计划节点的PlanState结构也会按照査询计划树的结构组织成计划节点执行状态树。对计划节点初始化的主要工作是根据计划节点中定义的相关信息,构造对应的PlanStale结构并对相关字段赋值。
执行阶段。这个阶段是执行器最重要的部分。在这个阶段,执行器完成对于执行树的迭代(Pipeline)遍历,通过从磁盘读取数据,根据执行树的具体逻辑完成查询语义。入口函数为 ExecutorRun ()。
ExecutorRun ()首先调用standard_ExecutorStart()完成查询。然后ExecutorRun ()函数在之后进行SQL 自调优,即查询执行完毕时,基于运行时信息分析查询计划问题。standard_ExecutorRun()函数主要做的工作就是运行计划,在执行过程中会调用ExecutePlan完成査询计划的执行;该函数的主体部分是一个大的循环,每一次循环都通过ExecProcNode函数从计划节点状态树中获取一个元组,然后对该元组进行相应的处理(增删查改),然后返回处理的结果。当ExecProcNode从计划节点状态树中再也取不到有效的元组时结束循环过程。ExecProcNode的执行过程也和ExecInitNode类似:从计划节点状态树的根节点获取数据,上层节点为了能够完成自己的处理将会递归调用ExecProcNode从下层节点获取输入数据(一般为元组),然后根据输入数据进行上层节点对应的处理,最后进行选择条件的运算和投影运算,并向更上层的节点返回结果元组的指针。同ExecInitNode 一样,ExecProcNode 也是一个选择函数,它会根据要处理的节点的类型调用对应的处理函数。例如,对于NestLoop类型的节点,其处理函数为ExecNestLoop。ExecNestLoop函数同样会对NestLoop类型的两个子节点调用ExecProcNode以获取输入数据。如果其子节点还有下层节点,则以同样的方式递归调用ExecProcNode进行处理,直到到达叶子节点。每一个节点被ExecProcNode处理之后都会返回一个结果元组,这些结果元组作为上层节点的输入被处理形成上层节点的结果元组,最终根节点将返回结果元组。
每当通过ExecProcNode从计划节点状态树中获得一个结果元组后,ExecutePlan函数将根据整个语句的操作类型调用相应的函数进行最后的处理。对于不扫描表的简单查询(例如select 1),调用的是Result节点,通过ExecResult函数直接输出“査询”结果。对于需要扫描表的查询(例如select xx from tablexx这种),系统在扫描完节点后直接返回结果,而对于增删改查询,情况特殊,有一个专门的ModifyTable节点来处理它:主要调用了ExecInsert、ExecDelete、ExecUpdate这三个函数进行处理。对于插入语句,则首先需要调用ExecConstraints对即将插入的元组进行约束检査,如果满足要求,ExecInsert会调用函数heap_insert将元组存储到存储系统。对于删除和更新,则分别由 ExecDelete 和 ExecUpdate 调用 heap_delete 和 heap_update 完成。清理阶段:因为执行器在初始化阶段向系统申请了资源,所以在这个阶段要完成对资源的清理。入口函数为 ExecutorFinish ()、ExecutorEnd ()。ExecutorFinish:此例程必须在最后一次ExecutorRun调用之后调用。它执行清理操作,比如触发AFTER触发器。它与ExecutorEnd是分开的,因为EXPLAIN ANALYZE需要在整个运行时中包含这些操作。 standard_ExecutorFinish()主要做的工作就是运行ModifyTable节点,执行队列后触发器,除非告诉不需要。ExecutorEnd ():此例程必须在任何查询计划执行结束时调用,之后会调用standard_ExecutorEnd()函数,然后调用ExecEndPlan处理执行状态树根节点释放已分配的资源,最后释放执行器全局状态EState完成整个执行过程。清理过程的任务主要是回收初始化过程中分配的资源、投影和选择结构的内存、结果元组存储空间等,计划节点执行状态树清理完之后,ExecutorEnd还将调用FreeExecutorState清理执行器全局状态。(4)函数调用关系:对Sort节点的整个查询执行周期里的节点的函数调用栈如下: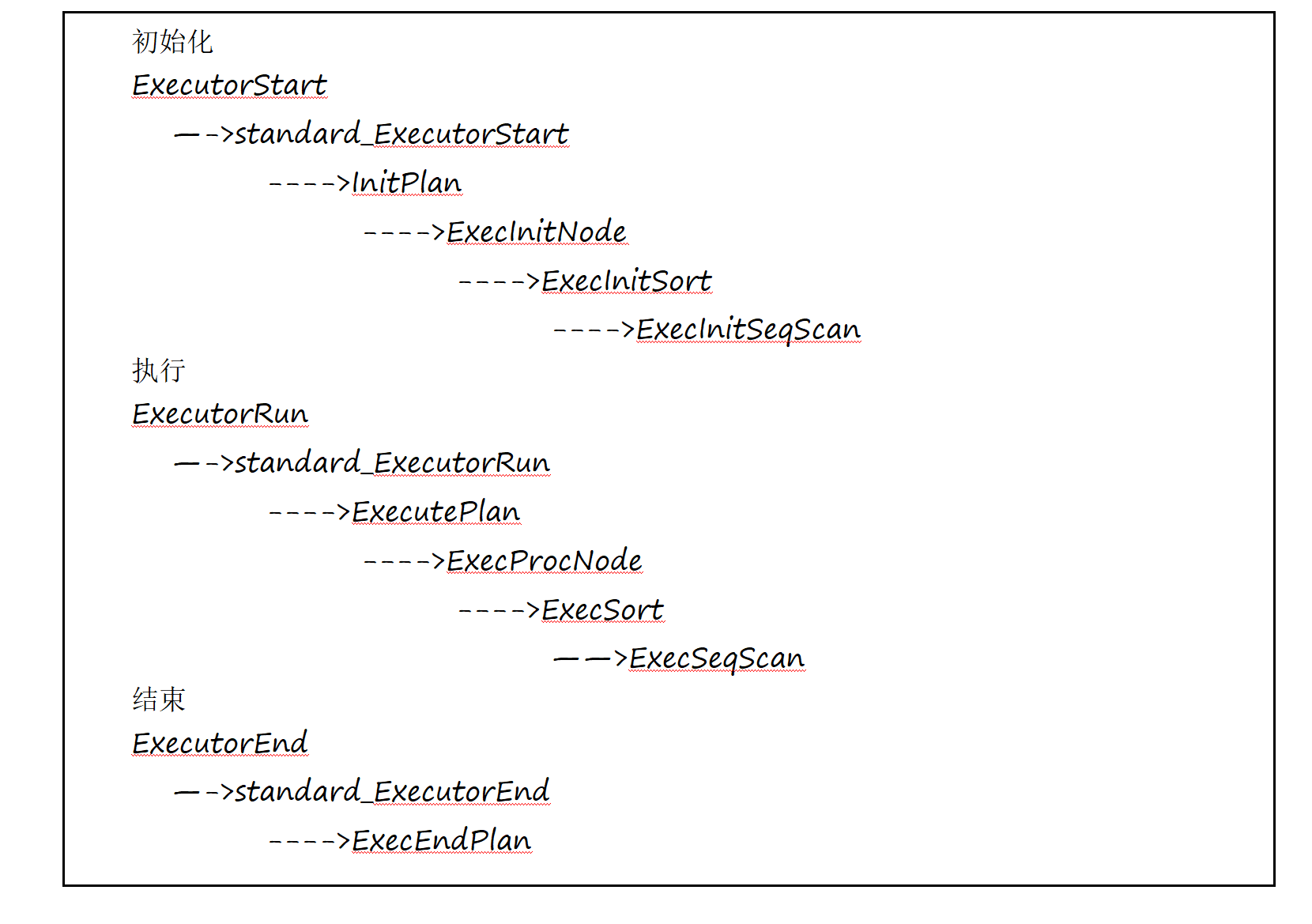
实验总结
(一)实验中出现的问题以及解决方案(对于未解决问题请将问题列出来)
1、连接MobaXterm_Personal_20.3失败。原因:IP地址和用户与虚拟机系统不匹配、或是网络超时方法:保证虚拟机网络稳定连接,ifconfig命令查找虚拟机ip地址
2、make失败,产生error。原因:有很多因素,例如绝对路径与相对路径问题、相关文件权限不够等;方法:配置环境变量时使用绝对路径;赋予相关文件更高权限,必要时更改目录用户所属组。
3、启动数据库失败:gs_ctl: command not found…原因:没有在omm用户下配置环境变量。每次启动,重新配置相关环境变量再启动则成功。或者数据库已打开:another server might be running; Please use the restart command。直接连接便好;或者进入安装目录中删除pid文件,再次启动运行。
4、连接数据库失败、端口被占用原因:有其他进程占用端口。方法:使用netstat命令查看占用端口进程,然后杀掉该进程,重新连接数据库
5、调试中没有进入到所设置的断点原因:无法在前端对后端断点进行Debug方法:对后端Gaussdb进行Debug
6、Debug时候有时会突然终止(实际不应该终止)。原因:未知方法:重启数据库
7、make时总是出现error原因:未知方法:初始化脚本要限制进程数量(一般改为1024)
8、将环境变量写入.bash_profile文件使设置的环境变量永久生效,会导致centos虚拟机屏幕变黑、任务栏不可用。原因:未知方法:将文件删除,按部就班,每次启动数据库进行环境变量配置。
(二)对于实验的感受,建议,意见
1、感受这次的实验很艰难,首先在代码的下载和编译中就遇到了很多问题,之后调试的过程中,由于对软件的不熟练,以及对opengauss内核的茫然,让我一度以为最终不能完成实验。但是在最后,通过努力,我认为还是交上了一份不错的答案。
参考文献
[1]CSDN博主「Zhangjay」的原创文章,原文链接:https://blog.csdn.net/Zhangjay/article/details/6565133<o:p></o:p>
[2]CSDN博主「fgh431」的原创文章,原文链接:https://blog.csdn.net/zhoutianzi12/article/details/96166289<o:p></o:p>
[3]CSDN博主「Gauss松鼠会」的原创文章,原文链接:https://blog.csdn.net/GaussDB/article/details/116132257<o:p></o:p>
[4]作者:非我在, 出处:http://www.cnblogs.com/flying-tiger/

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献384条内容
已为社区贡献384条内容

所有评论(0)