【Python自动化Excel】多个excel文件,按列匹配数据
多个的Excel文件需要基于某一列或多列进行数据的匹配、合并,并提取出匹配数据中的相关数据
·
在办公场景中,我们常常会遇到这样的场景:多个的Excel文件需要基于某一列或多列进行数据的匹配、合并,并提取出匹配数据中的相关数据。
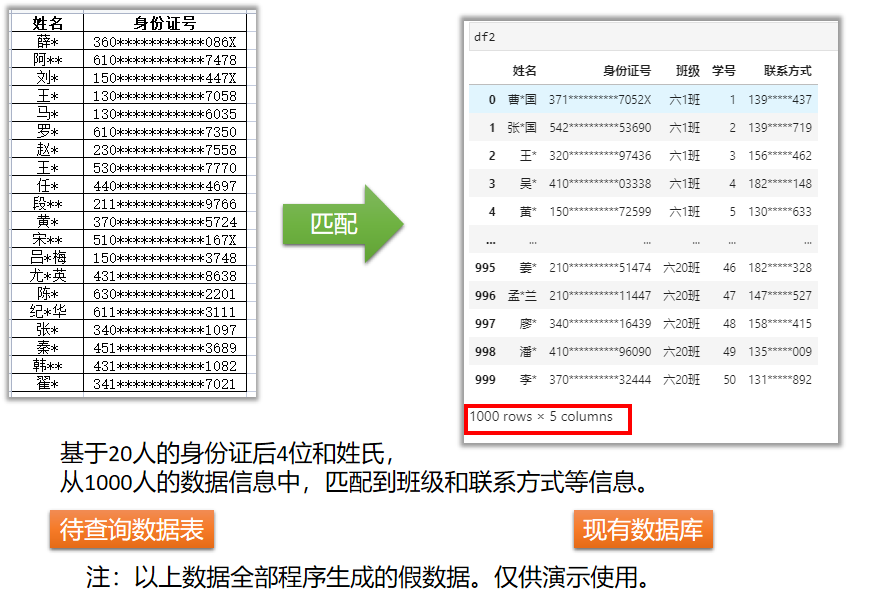
最近遇到了这样一个问题:在核酸检测过程中,某个混检的试管出了问题,而之前采样的20人已经离开了,需要在4000多人中快速找到这20人的联系方式,以便重新采集。最惨的是采集app上只能看到这20人的身份证尾号和姓氏。
要解决这个问题关键有两步:匹配数据和提取数据。
Python中的pandas库提供了这一个问题的解决方案。代码写好后,只需关注两点:按哪列数据匹配、要提取哪些列,便可以解决这类问题。
问题描述
1.辅助列生成
import pandas as pd
# 读取Excel文件
df1 = pd.read_excel('./待查询信息.xlsx')
df2 = pd.read_excel('./学生信息加密表格.xlsx')
# 待查询数据表——生成辅助列:姓氏
df1['姓氏'] = df1['姓名'].str[0]
df1['身份证后四位'] = df1['身份证号'].str[-4:]
# 数据库表——生成辅助列:编号后四位和姓氏
df2['身份证后四位'] = df2['身份证号'].str[-4:]
df2['姓氏'] = df2['姓名'].str[0]

2.合并匹配
mergeDf = pd.merge(df1,df2,how='left',on=['身份证后四位','姓氏'])
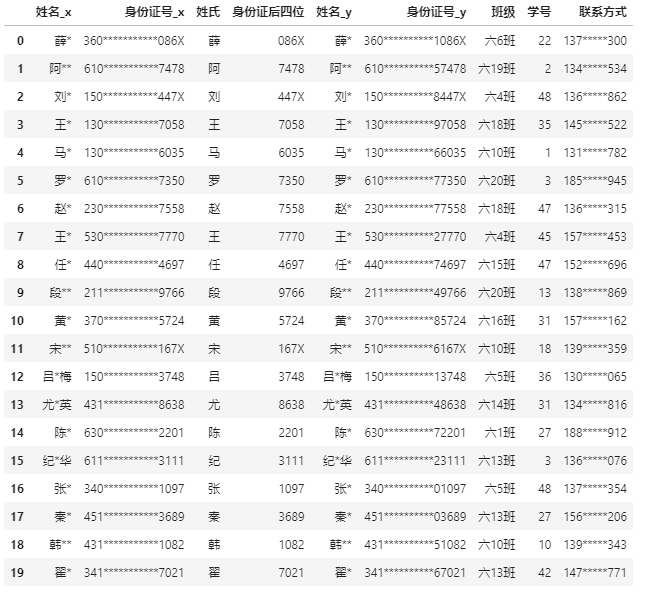
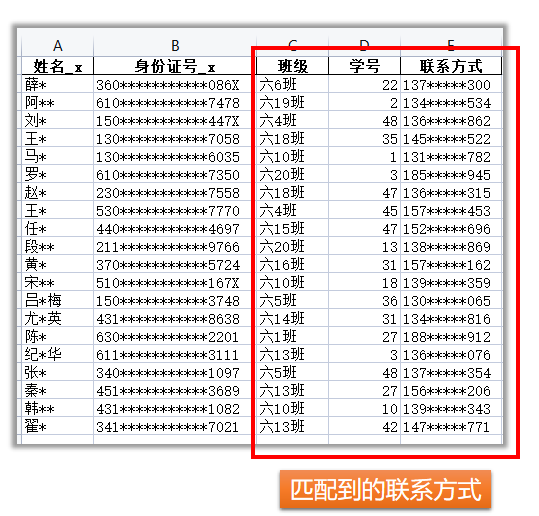
3.选取另存
# 选取需要的列名
outColNames = [
'姓名_x',
'身份证号_x',
'班级',
'学号',
'联系方式',
]
mergeDf[outColNames].to_excel("数据匹配后的结果.xlsx",index=False)
其实对于数据的匹配,excel中的vlookup()函数也可以做,但不同的Excel文件之间处理免不了繁琐的框选、复制、粘贴吧,而且数据量大的时候手工拖动操作不仅效率低,而且有操作失误的风险。
文件之间处理免不了繁琐的框选、复制、粘贴吧,而且数据量大的时候手工拖动操作不仅效率低,而且有操作失误的风险。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 2
2- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)