linux启动spark命令,在linux上安装spark
第一、通过xftp工具将spark安装包上传到linux上第二、解压spark到指定目录:tar -zxf /opt/software/spark-2.1.0-bin-hadoop2.7.tgz -C /opt/module/第三、配置1、在spark安装路径配置spark-env.sh,我的路径是/opt/module/spark-2.1.0-bin-hadoop2.7/conf输入命令:vi
第一、通过xftp工具将spark安装包上传到linux上
第二、解压spark到指定目录:
tar -zxf /opt/software/spark-2.1.0-bin-hadoop2.7.tgz -C /opt/module/
第三、配置
1、在spark安装路径配置spark-env.sh,我的路径是/opt/module/spark-2.1.0-bin-hadoop2.7/conf
输入命令:vi spark-env.sh,如下
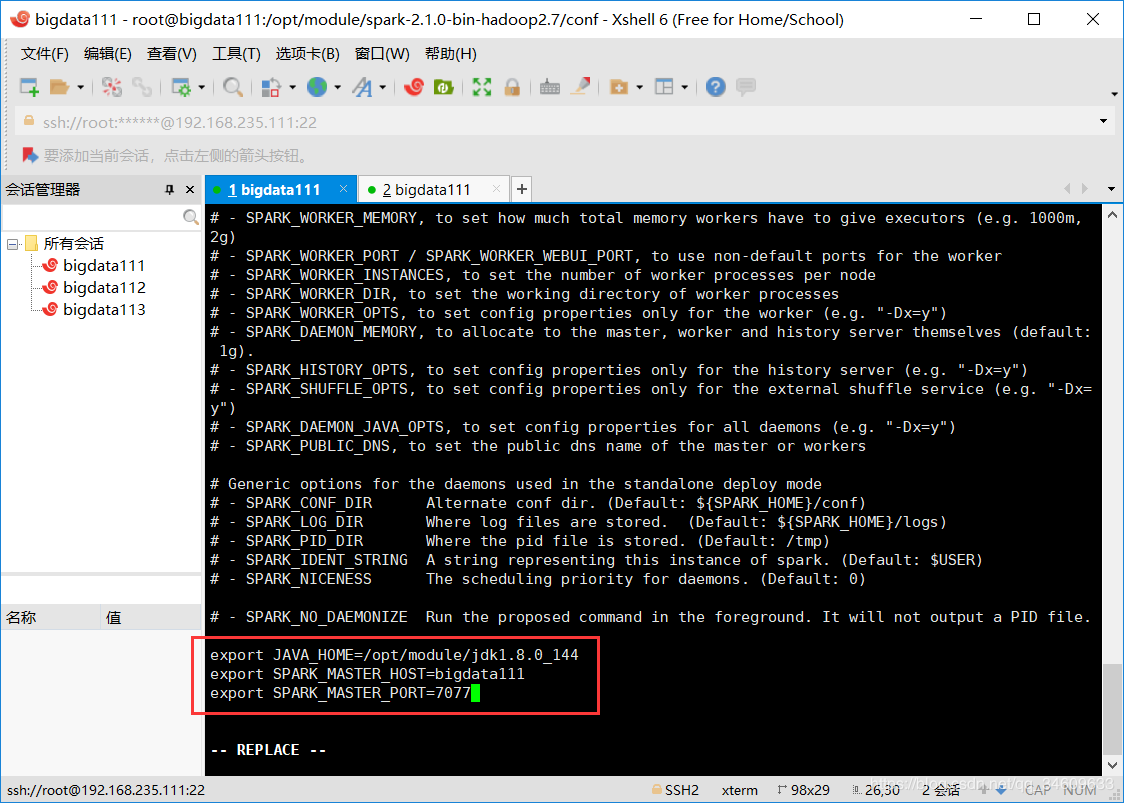
export JAVA_HOME=/root/training/jdk1.7.0_75(填自己的java_home配置路径)
export SPARK_MASTER_HOST=bigdata111(填自己的主节点)
export SPARK_MASTER_PORT=7077
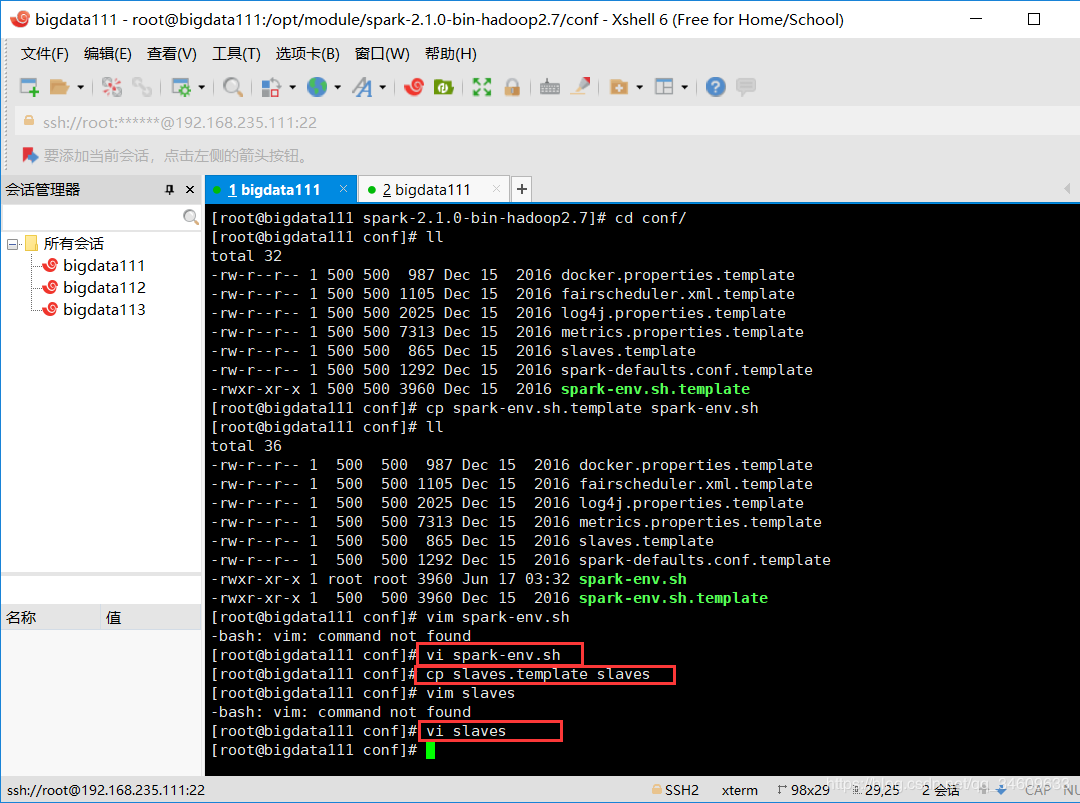
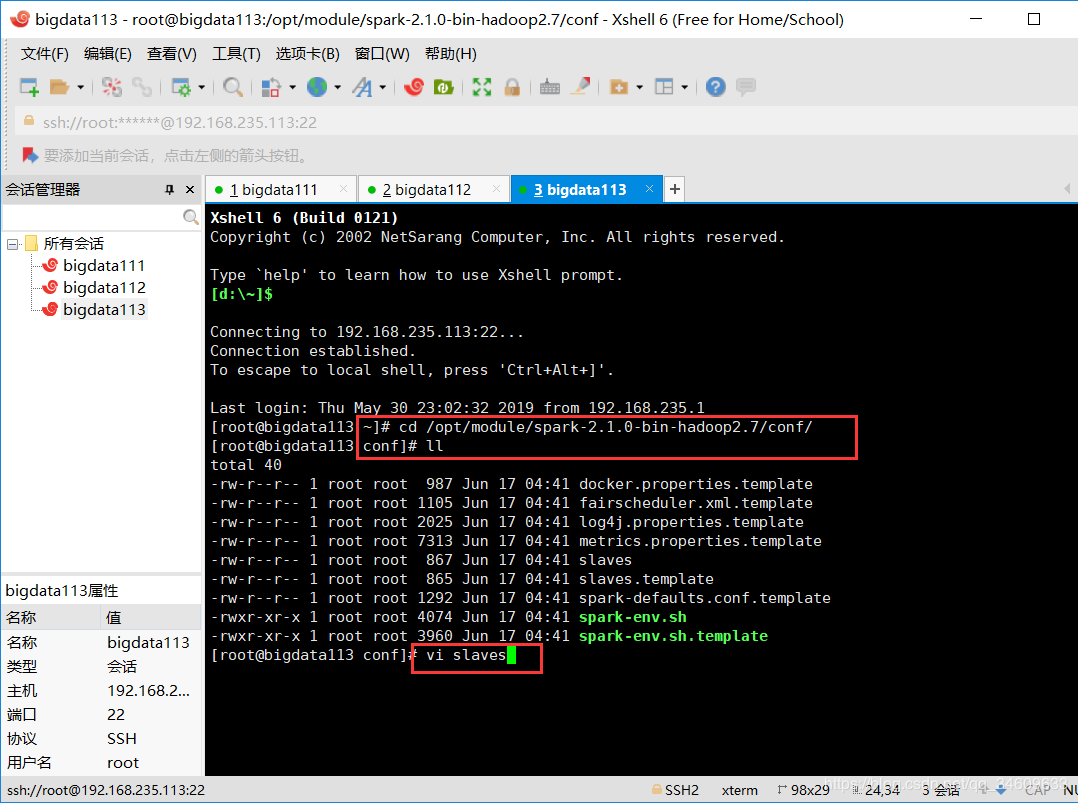
2、在conf文件夹下配置slaves文件,
先输入命令:cp slaves.template slaves
再输入命令:vi slaves
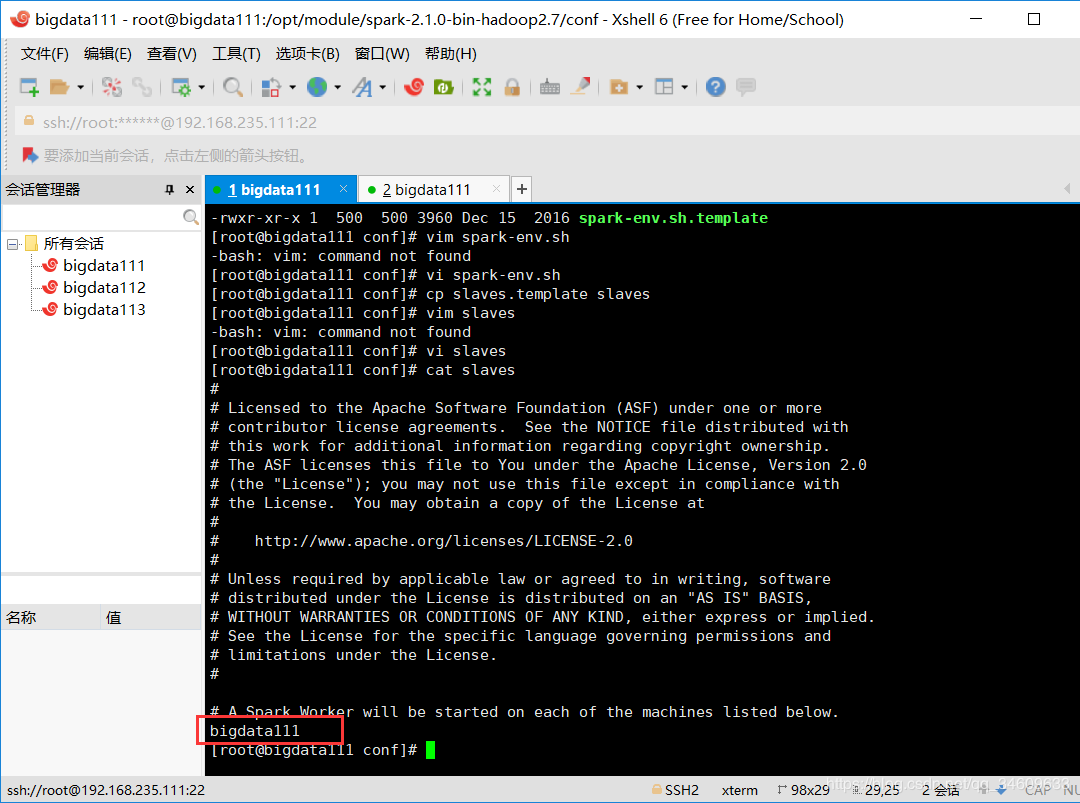
然后添加自己的节点域名:
我的是:bigdata111
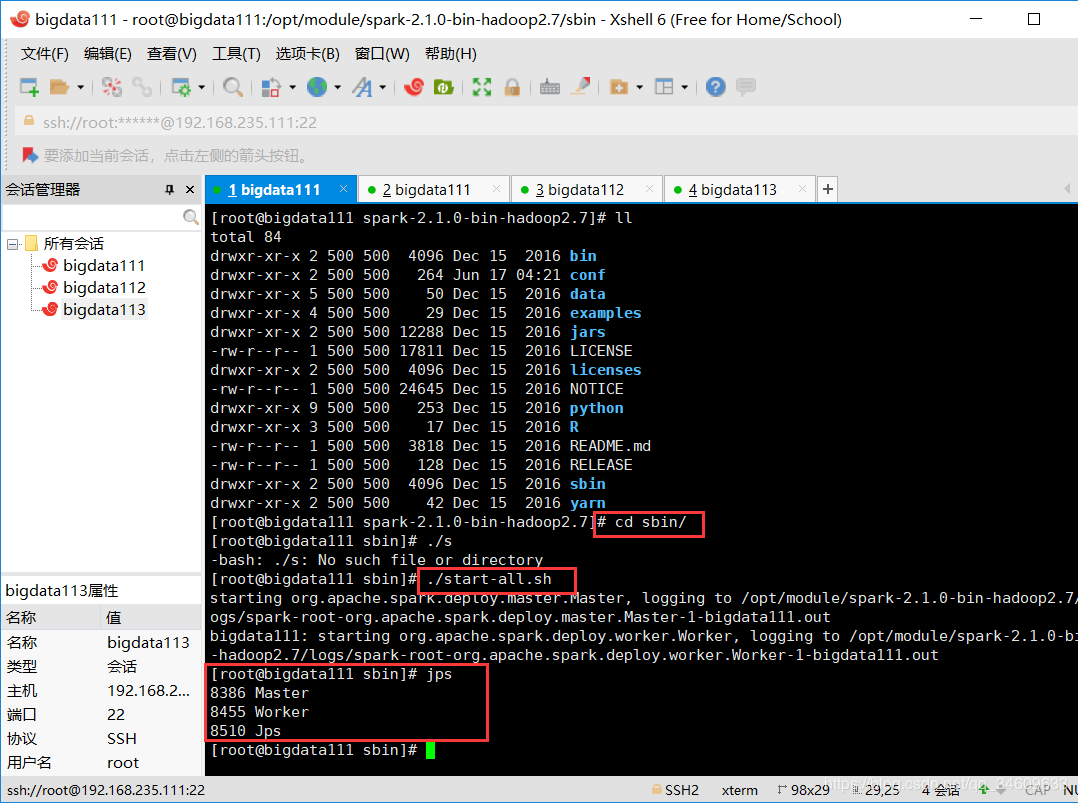
3.在sbin文件夹下用命令./start-all.sh启动spark,用jps命令查看进程
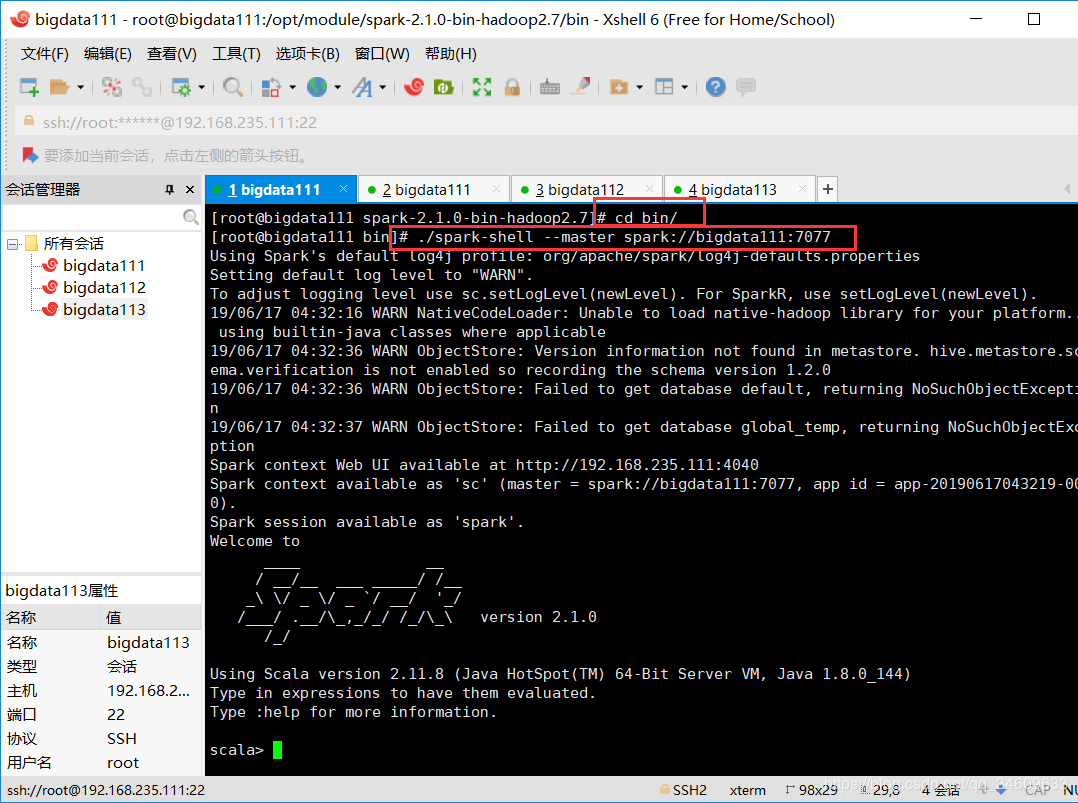
4.进入bin文件夹下,输入./spark-shell --master spark://bigdata111:7077,显示如下,则表示spark的伪分布式搭建成功
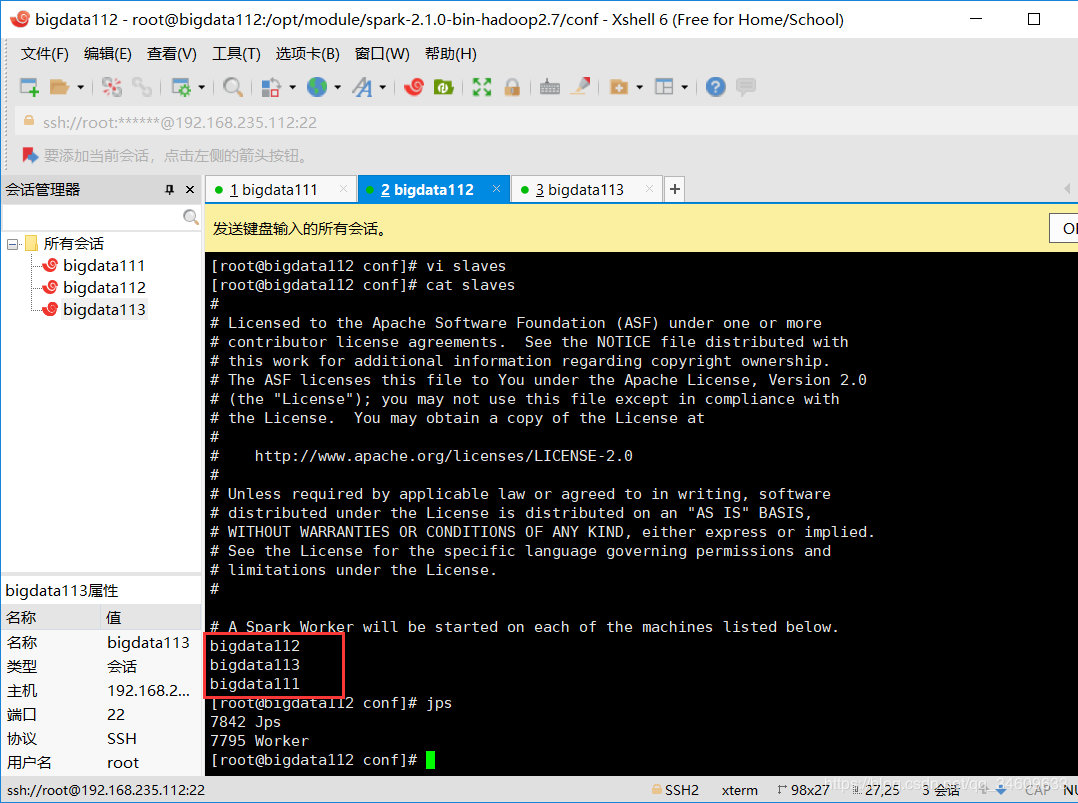
5.配置完全分布式环境,首先修改conf文件夹下的slaves文件,我的是添加
bigdata111
bigdata112
bigdata113
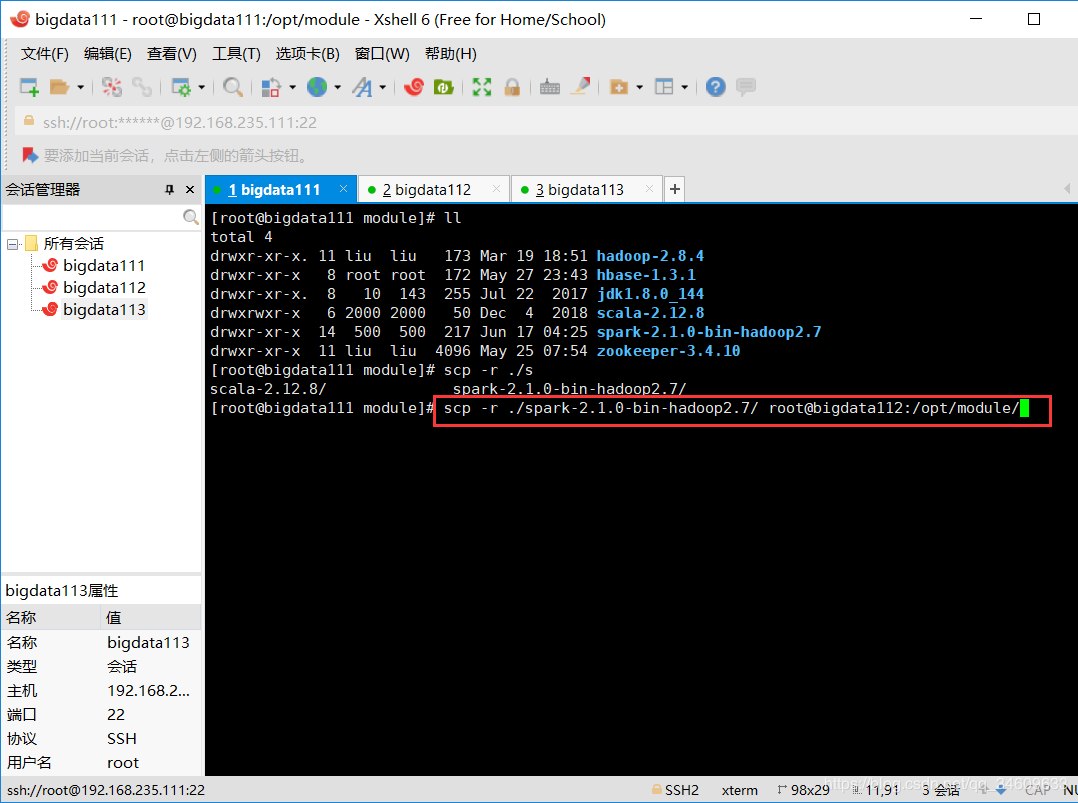
6.将配置好的虚拟机的配置信息复制到其他虚拟机的同名目录下
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata112:/opt/module/
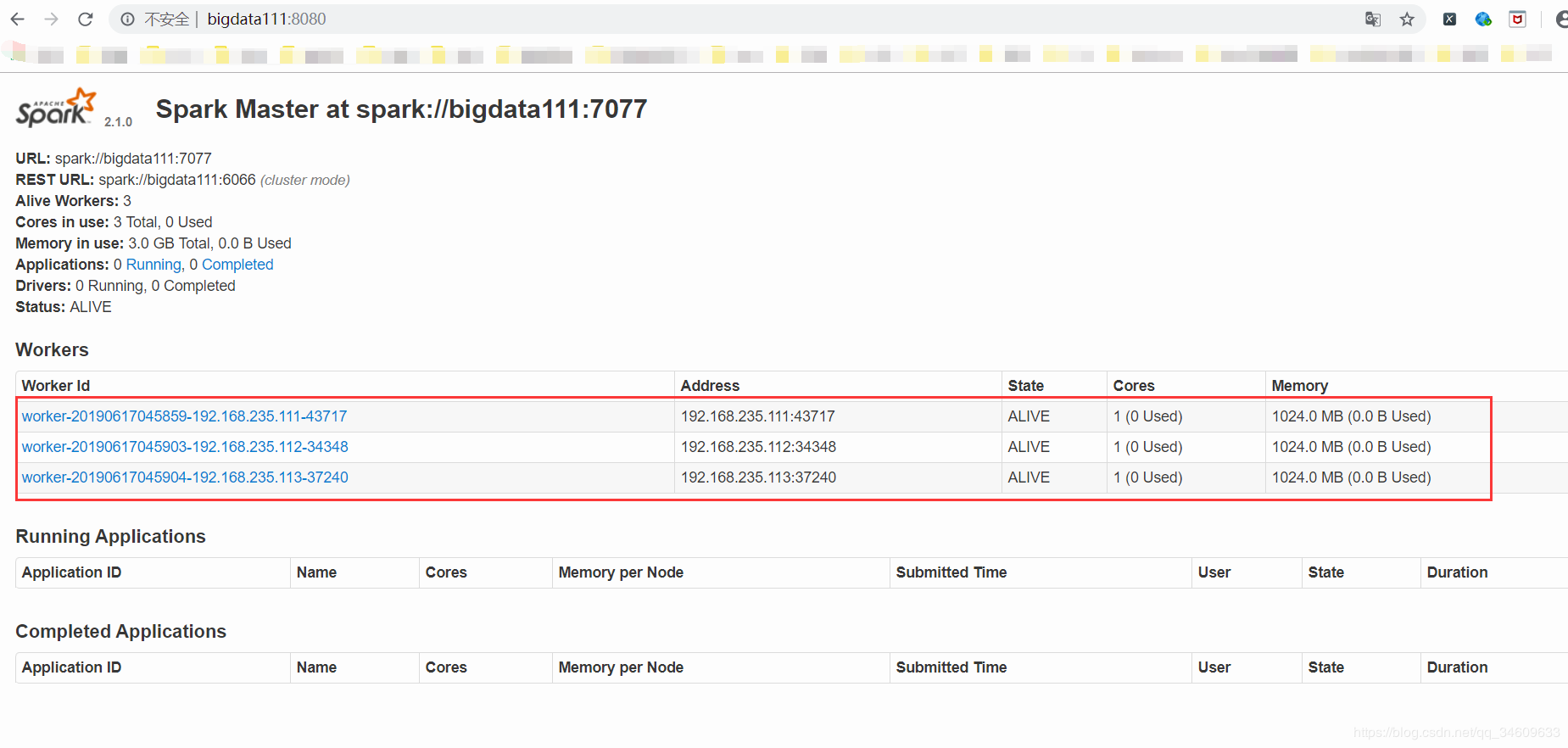
7.在sbin文件夹下用命令./start-all.sh启动spark,用jps命令查看进程,也可以在浏览器上查看:
输入主节点:8080,显示如下,则表示spark完全分布式搭建成功。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)