es集群状态red排查流程
转载https://www.cnblogs.com/tcy1/p/14293423.html#886745359es集群状态red问题描述公司有一套kibana日志收集系统,组合方式为filebeat+elasticsearch+kibana,elasticsearch使用三台服务器组合成集群。近期公司的zabbix服务器持续告警某台服务器cpu使用率在80%以上,登录服务器首先查看是哪个服务器对
转载 https://www.cnblogs.com/tcy1/p/14293423.html#886745359
es集群状态red
问题描述
公司有一套kibana日志收集系统,组合方式为filebeat+elasticsearch+kibana,elasticsearch使用三台服务器组合成集群。近期公司的zabbix服务器持续告警某台服务器cpu使用率在80%以上,
登录服务器首先查看是哪个服务器对cpu占用过多,查看是因为es导致。
排查思路
- 针对es集群占用cpu使用率过高问题
因es集群仅作为kibana日志收集使用,所以使用es-head首先查看集群状态

- 针对es集群red状态问题
# es集群的几种状态
green:所有主分片和副本都可用
yellow:所有主分片都可用,但不是所有副本分片都可用
red:不是所有主分片都可用,这意味着缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
# 查看es集群当前状态(当前集群都在线,没有问题)
[root@VM-30-28-centos logs]# curl -s 172.31.30.28:9200/_cat/nodes
172.31.30.28 63 96 4 0.02 0.16 0.36 dilm - VM-30-28-centos
172.31.30.88 20 98 9 0.32 0.50 0.56 dilm * VM-30-88-centos
172.31.30.48 60 97 9 0.91 0.73 0.83 dilm - VM-30-48-centos
疑问:虽然处于red状态,但是集群状态没有问题
# 1.查看系统最大打开文件描述符数是否够用
[root@VM-30-28-centos logs]# df -i # 使用都在百分之一左右,丝毫不影响
Filesystem Inodes IUsed IFree IUse% Mounted on
devtmpfs 2030545 346 2030199 1% /dev
tmpfs 2033272 7 2033265 1% /dev/shm
tmpfs 2033272 469 2032803 1% /run
tmpfs 2033272 16 2033256 1% /sys/fs/cgroup
/dev/vda1 3276800 65778 3211022 3%
/ tmpfs 2033272 1 2033271 1%
/run/user/0
/dev/vdb1 32768000 161045 32606955 1% /opt
查看当前健康状态,发现未分配分片数居然达到了三千多,并且集群中所有活跃的分片数和主分片数达成了一致,也就是未分配的都是副本分片,主分片处于活跃状态,
由于灾备原则,主分片和其对应副本不能同时在一个节点上,es无法找到其他节点来存放第三个副本的分片,所以导致了集群处于red状态

但是为什么会出现es无法找到其他节点来存放第三个副本分片呢?
原因如下:
① 副本太多,节点太少,es无法完成分片
解决方式:1. 减少副本数 2. 增加节点数
② 分片被锁住了
解决方式: 尝试分配,或者手动分配, 可以指定"accept_data_loss" : true。但这样会导致数据完全丢失。
③ 有节点短暂离开集群,然后重新加入,并且有线程对某个分片做bulk或者scroll等长时间写入操作,等节点重新加入集群,由于分片 lock灭有释放,master无法分配这个分片,
通常/_cluster/reroute?retry_failed=true可以解决问题,如果依然无法解决,可能还有其他原因导致锁住该shard的线程长时间操作该shard无法释放锁(长时间GC?)。 所以有可能是索引过大导致。
# 查看所有索引的状态,大小等
curl -XGET 'http://172.31.30.28:9200/_cat/indices?v'
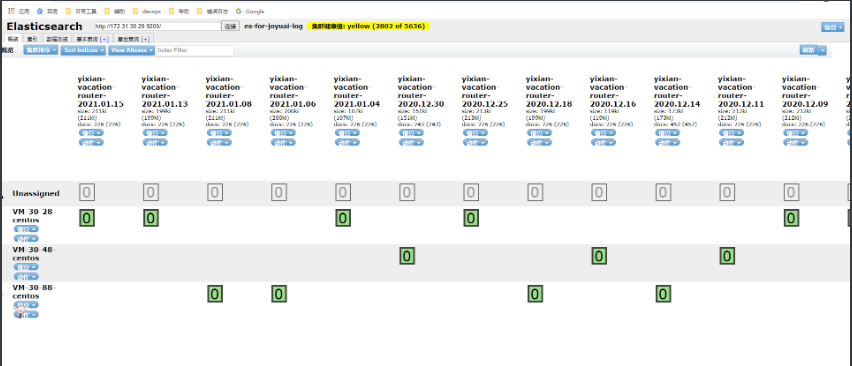
这里的截图并不完整,当时有red状态的索引和yellow状态的索引,这里的解决办法直接将red状态索引删除处理

删除red状态索引方式,但我这里仅作为日志索引,所以影响不大,删除需要结合实际情况考虑
curl -XGET 'http://172.31.30.28:9200/_cat/indices?v'|grep 'red' |awk '{print $3}'|xargs -i curl -XDELETE "http://172.31.30.88:9200/{}"
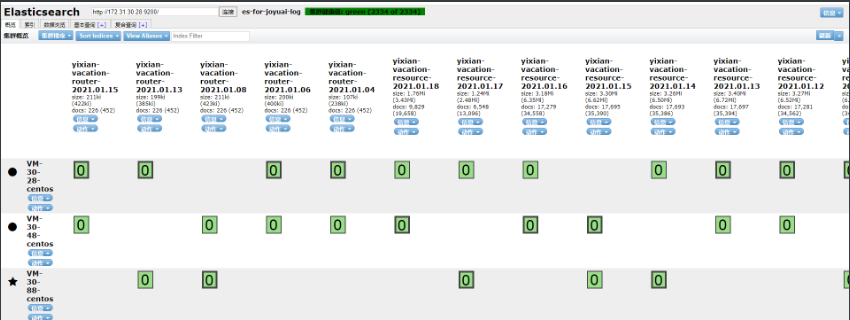
后续查看es-head状态,es集群状态从red转为yellow,删除red索引后个别索引从yellow状态变为green状态
总结:#
遇到集群Red时,我们可以从如下方法排查 :
- 集群层面:curl -s 172.31.30.28:9200/_cat/nodes 或者 GET _cluster/health
- 索引层面:GET _cluster/health?pretty&level=indices
- 分片层面:GET _cluster/health?pretty&level=shards
- 恢复情况:GET _recovery?pretty
有unassigned分片的排查思路 :
- 先诊断:GET _cluster/allocation/explain
- 重新分配: /_cluster/reroute
实在无法分配:
索引重建:
① 新建备份索引:
curl -XPUT ‘http://xxxx:9200/a_index_copy/‘ -d ‘{ “settings”:{ “index”:{ “number_of_shards”:3, “number_of_replicas”:2 } } }② 通过reindex api将a_index数据copy到a_index_copy:
POST _reindex { "source": { "index": "a_index" }, "dest": { "index": "a_index_copy", "op_type": "create" } }③ 删除a_index索引,这个必须要先做,否则别名无法添加
curl -XDELETE 'http://xxxx:9200/a_index'④ 给a_index_copy添加别名a_index
curl -XPOST 'http://xxxx:9200/_aliases' -d ' { "actions": [ {"add": {"index": "a_index_copy", "alias": "a_index"}} ] }'translog总结
translog在节点有问题时,能够帮助阻止数据的丢失
设计目的:
1、帮助节点从失败从快速恢复。
2、辅助flush。避免在flush过程中数据丢失。
插播一下,translog的知识#
- 我们把数据写到磁盘后,还要调用fsync才能把数据刷到磁盘中,如果不这样做在系统掉电的时候就会导致数据丢失,这个原理相信大家都清楚,elasticsearch为了高可靠性必须把所有的修改持久化到磁盘中。
- 我们的数据先写入到buffer里面,在buffer里面的数据时搜索不到的,同时将数据写入到translog日志文件之中。如果buffer快满了,或是一段时间之后,就会将buffer数据refresh到一个新的OS cache之中。
- translog的作用:在执行commit之前,所有的而数据都是停留在buffer或OS cache之中,无论buffer或OS cache都是内存,
一旦这台机器死了,内存的数据就会丢失,所以需要将数据对应的操作写入一个专门的日志文件之中。- 一旦机器出现宕机,再次重启的时候,es会主动的读取translog之中的日志文件数据,恢复到内存buffer和OS cache之中。
整个commit过程就叫做一个flush操作- 其实translog的数据也是先写入到OS cache之中的,默认每隔5秒之中将数据刷新到硬盘中去,也就是说,
可能有5秒的数据仅仅停留在buffer或者translog文件的OS cache中,如果此时机器挂了,
会丢失5秒的数据,但是这样的性能比较好,我们也可以将每次的操作都必须是直接fsync到磁盘,但是性能会比较差。
附:
查看es状态
# 附,命令方式查看es:
curl -uelastic:pwd -XGET "http://172.31.30.28:9200/_cluster/health?pretty"
{
"cluster_name" : "es-for-joyuai-log", # es集群名称
"status" : "green", # es集群状态
"timed_out" : false, # 是否出现超时
"number_of_nodes" : 3, # es节点数
"number_of_data_nodes" : 3, # es数据节点数
"active_primary_shards" : 1167, # 集群中所有活跃的主分片数
"active_shards" : 2334, # 集群中所有活跃的分片数
"relocating_shards" : 0, # 当前节点迁往其他节点的分片数量,通常为0,当有节点加入或者退出时该值会增加
"initializing_shards" : 0, # 正在初始化的分片
"unassigned_shards" : 0, # 未分配的分片数,通常为0,当有节点加入或者退出时该值会增加。 "delayed_unassigned_shards" : 0, # 延迟未分配的分片数
"number_of_pending_tasks" : 0, # 是指主节点创建索引并分配shards等任务,如果该指标数值一直未减小代表集群存在不稳定因素
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0 # 集群分片的可用性百分比,如果为0则表示不可用
}
脚本删除30天前的日志索引
#!/bin/bash
#删除ELK30天前的日志
DATE=`date -d "30 days ago" +%Y.%m.%d`
curl -s -XGET http://172.31.30.88:9200/_cat/indices?v| grep $DATE | awk -F '[ ]+' '{print $3}' >/tmp/elk.log
for elk in `cat /tmp/elk.log`
do
curl -XDELETE "http://172.31.30.88:9200/$elk"
done

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)