接口自动化框架搭建
1.自动化测试流程--需求分析。需求文档,接口文档,抓包接口--测试计划。通常包含项目的进度,是否自动化,优先级--测试用例(是从手工测试提取出来的)--用例评审--执行测试。(写代码)--测试报告接到项目之后,如何去进行需求分析:1.需要文档,功能展示以及交互2.接口文档,后端数据是怎么传输的3.数据库账号,数据库地址,结构帮大家熟悉整个项目的轮廓,字段4.测试环境,环境怎么搭建5.原型图测试计
1.自动化测试流程
-- 需求分析。需求文档,接口文档,抓包接口
-- 测试计划。通常包含项目的进度,是否自动化,优先级
-- 测试用例(是从手工测试提取出来的)
-- 用例评审
-- 执行测试。(写代码)
-- 测试报告
接到项目之后,如何去进行需求分析:
1.需求文档,功能展示以及交互
2.接口文档,后端数据是怎么传输的
3.数据库账号,数据库地址,结构帮大家熟悉整个项目的轮廓,字段
4.测试环境,环境怎么搭建
5.原型图
测试计划:
通常是由测试经理或者项目经理来编写的
1.可行分析,是否要引入自动化,哪此场景引入自动化,哪此功能引入自动化,做自动化不是全量覆盖,不可能是所有用例都进行自动化,
2.风险因子,存在哪此风险
3.时间管控,主要是时间、技术、进度、优先级的管控
4.技术,使用什么技术(python、java),使用什么测试单元框架(unittest、pytest)
测试用例:
写到excel,手工测试用例,指的是全量的测试用例,不是自动化测试用例
案例:
通常来说,任何一个项目或是新功能,会先进行手工测试,也是要进行全量的用例编写
自动化测试主要包括:
1.冒烟测试:主流程是否能正常运行
2.回归测试:验证开发修复的bug是否正常,并没有引入新的bug
3.持续集成:一天要重复测试好几次
2.接口需求分析
接口文档:
-- 纸质(电子 )
-- open api,swagger(网站)
-- 什么都没有,全凭一张嘴(自己抓包)
通过抓包或postman调试工具来设计测试用例,预期结果
3.用例设计
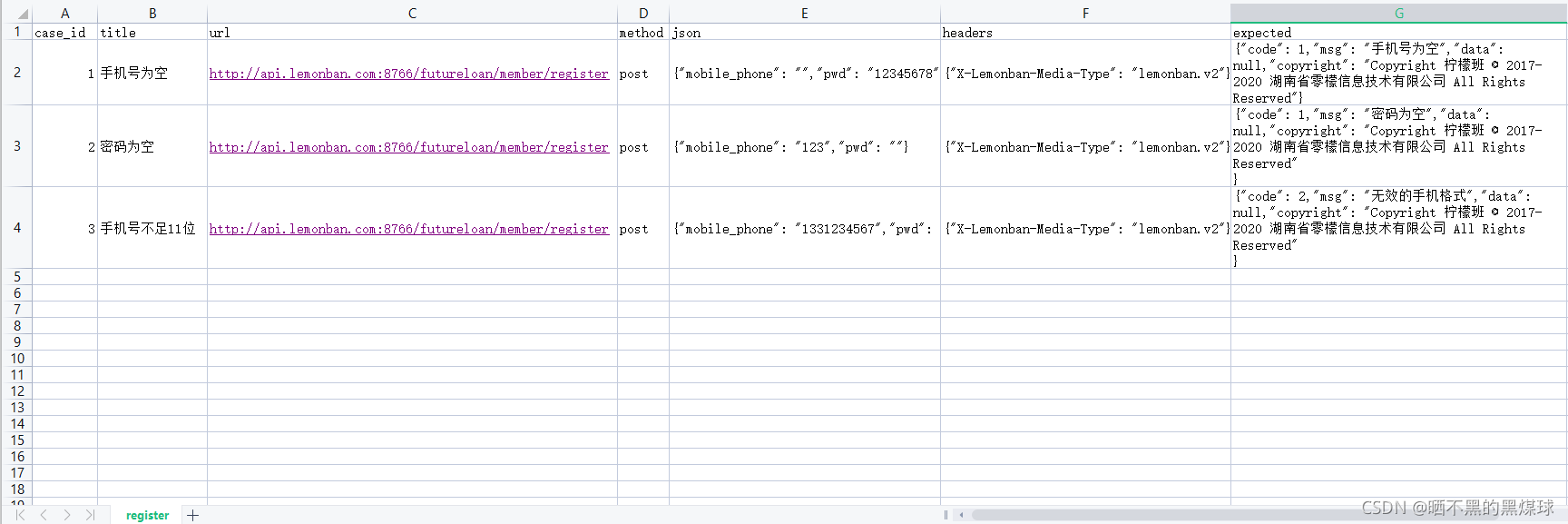
用excel进行编写,最好是一个接口编写一个sheet页,这样好进行测试
注意json格式数据一定要规范,双引号,英文的逗号等
预期结果可以使用postman调试工具来获取
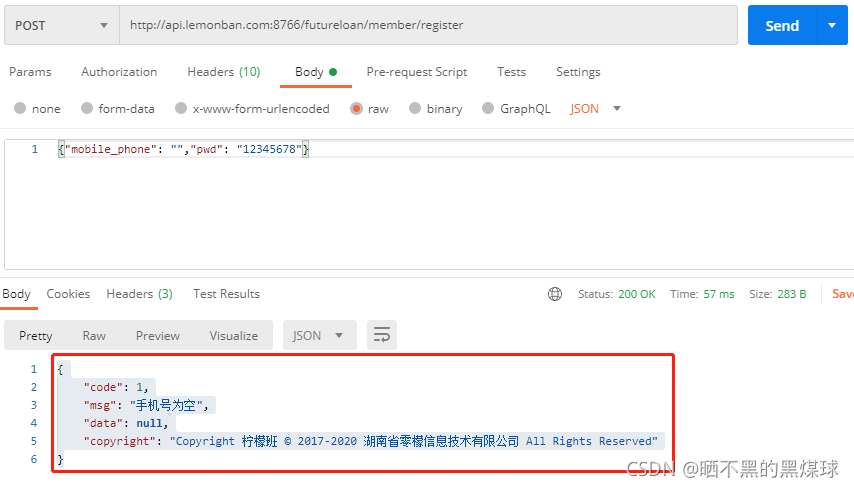
4.编写自动化测试用例函数
领导丢给你一个自动化测试计划
先不要着急做到十全十美,第一步是验证你的自动化测试程序是否能正常运行
先把功能实现
写一个单独的自动化测试用例函数。以test_开头,需要有请求发送,得到响应结果,断言,生成测试报告
新建一个test_register.py,代码如下:
import unittest
import requests
class TestRegister(unittest.TestCase):
def test_register_01(self):
'''步骤:
1.准备测试数据
2.发送接口请求,得到实际结果
3.预期结果和实际结果的断言
'''
# 1.准备测试数据
url = 'http://api.lemonban.com:8766/futureloan/member/register'
method = 'post'
headers = {'X-Lemonban-Media-Type': 'lemonban.v2'}
json_data = {"mobile_phone": "", "pwd": "12345678"}
expected = {
"code": 1,
"msg": "手机号为空",
"data": None,
"copyright": "Copyright 柠檬班 © 2017-2019 湖南省零檬信息技术有限公司 All Rights Reserved"
}
# 2.发送接口请求,得到实际结果
response = requests.request(method=method,url=url,
headers=headers,json=json_data)
actual = response.json()
# 3.预期结果和实际结果的断言
self.assertEqual(expected,actual)
# 有多少条用例就可以写多少个自动化测试函数,这里就不写所有的了新建一个run.py来收集用例,运行用例,代码如下:
import unittest
import unittestreport
# 收集测试用例
suite = unittest.defaultTestLoader.discover('tests')
# 生成测试报告
runner = unittestreport.TestRunner(suite)
runner.run()运行结果:

有了以上的基础后,我们可以引入ddt,优化下测试用例函数,降低代码重复率。
ddt适用的场景:不同的数据,测试步骤是一样的
之前有一章是讲框架搭建,然后我们创建的共同的包可以拿来直接使用Python框架模型搭建_晒不黑的黑煤球的博客-CSDN博客

直接复制之前的common,config,data包来用,
注意:第一点:设置根目录,第二点:将data目录里的数据更换成新建的excel表格
主要是用到excel.py,config.py
excel.py代码如下:
from openpyxl import load_workbook
def read_excel(file_name, sheet_name):
wb = load_workbook(file_name)
sheet = wb[sheet_name]
data = list(sheet.values)
titles = data[0]
rows = [dict(zip(titles, row)) for row in data[1:]]
return rowsconfig.py代码如下:
import os
# 获取config.py当前文件的路径
curren_path = os.path.abspath(__file__)
# 配置文件目录的路径
config_dir = os.path.dirname(curren_path)
# config包的路径
cf_dir = os.path.dirname(config_dir)
# 拼接出data的路径
data_dir = os.path.join(cf_dir, 'data')
# 拼接出测试用例cases.xlsx的路径
cases_dir = os.path.join(data_dir, 'cases.xlsx')
# host地址
host = 'http://api.lemonban.com:8766'因为测试跟开发环境不是同一个,会经常替换,所以把host写到配置文件里,这样方便操作,不用修改excel表格中的每一条

新建一个test_register_ddt.py,代码如下:
import unittest
import requests
import json
from common.excel import read_excel
from config import config
from ddt import ddt,data
from common.logger import log
# 得到测试数据
excel_data = read_excel(file_name=config.cases_dir, sheet_name='register')
@ddt
class TestRegister(unittest.TestCase):
@data(*excel_data)
def test_register(self,info):
'''步骤:
1.准备测试数据
2.发送接口请求,得到实际结果
3.预期结果和实际结果的断言
'''
# 1.准备测试数据
log.info(f'正在测试{info}')
# 要把配置文件的host跟取出来excel表中的url进行拼接
url = config.host + info['url']
method = info['method']
# 将json格式字符串转化成字典,因为requests.request需要字典格式
headers = json.loads(info['headers'])
json_data = json.loads(info['json'])
expected = json.loads(info['expected'])
# 2.发送接口请求,得到实际结果
response = requests.request(method=method, url=url,
headers=headers, json=json_data)
actual = response.json()
# 3.预期结果和实际结果的断言
self.assertEqual(expected, actual)
运行结果:
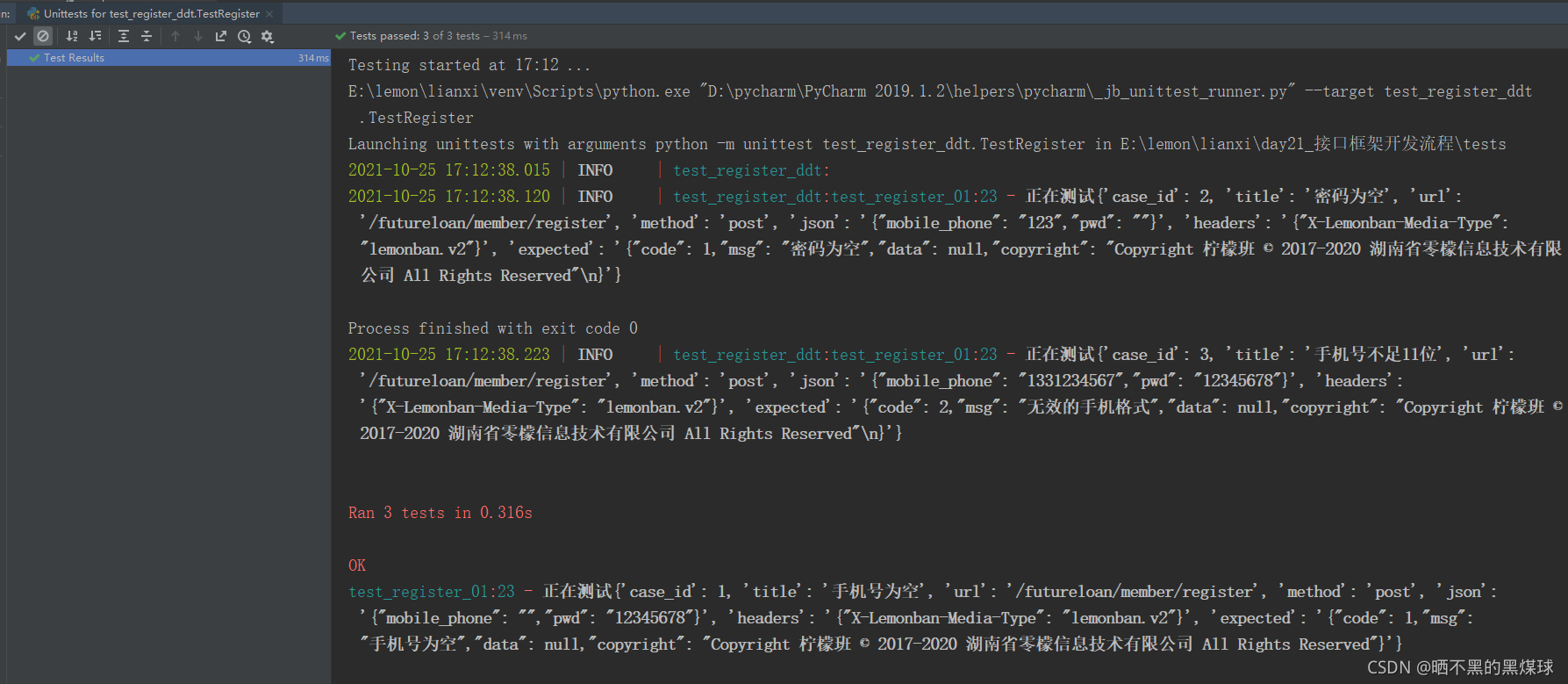
总结:
调试过程:
1.首先程序报错,从报错信息中查看error message:Invalid URL '/futureloan/member/register': No schema supplied
2.找到报错行,报错信息中哪个文件是你写的,行号,跳到行号
3.如果有多个文件是自己编写的,行号都找出来
4.哪一行出错,就在哪一行设置断点,通过debug调试
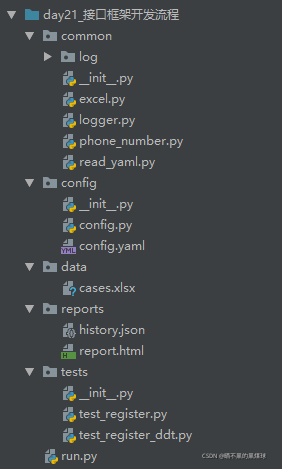
5.分层思想
tests/:存储自动化用例
common/:通用模块
logs/:保存日志文件
data/:保存测试数据,excel文件
setting/:配置文件
reports/:保存测试报告
run.py:收集用例,运行用例,生成测试报告
6.注册接口测试优化
6.1测试报告展示不覆盖
通过时间戳来解决测试报告不覆盖问题
使用BeautifulReport生成测试报告
import unittest
from BeautifulReport import BeautifulReport
from datetime import datetime
# 收集测试用例
suite = unittest.defaultTestLoader.discover('tests')
# 生成测试报告
'''默认的report.html需要改成report-2021-10-26-13-10.html
如何生成文件名
1.获取现在的时间戳 ts = 2021-10-26-13-10
2.字符串拼接f'report-{ts}.html'
3.字符串拼接f'reports/report-{ts}.html'
'''
# 获取时间戳
ts = datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
# 拼接文件目录
filename = f'reports/report-{ts}.html'
runner = BeautifulReport(suite)
runner.report('测试报告',filename=filename)运行结果:

使用unnittestreport生成测试报告
import unittest
import unittestreport
from datetime import datetime
# 收集测试用例
suite = unittest.defaultTestLoader.discover('tests')
# 生成测试报告
ts = datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
filename = f'report-{ts}.html'
runner = unittestreport.TestRunner(suite, filename=filename)
runner.run()运行结果:

注意:unnittestreport生成的报告会自动创建reports目录,因此filename = f'report-{ts}.html'不需要手动添加reports目录,但BeautifulReport需要手动添加
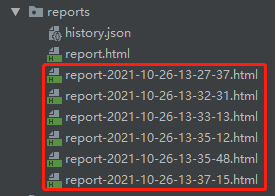
可以看到每次运行一次run.py,就会生成一个当前系统时间命名的.html文件
6.2注册的手机号码生成
方案1:手工把手机号+1,运营商(号段)不支持,或者造成跟别人的号码冲突
方案2:数据库清掉,最好不要清库,不一定有数据库删除权限
方案3:使用第三方库faker来伪造手机号码,使用前需要安装pip install faker
faker用法,安装后一定要导入
from faker import Faker
# 生成手机号
# 不填写locale=['zh-cn'],得到是国外的手机号码
faker = Faker()
print(faker.phone_number())
# 得到是中国的手机号码
faker = Faker(locale=['zh-cn'])
print(faker.phone_number())
# 得到一个地址
print(faker.address())
# 得到一个公司名
print(faker.company())
# 得到一个人的姓名
print(faker.name())
# 得到一个身份证号
print(faker.ssn())运行结果:
218.367.2113
13910723249
河南省玉珍市高港杨街U座 326239
通际名联网络有限公司
张涛
230403194705041796
接着来搞一下动态数据替换,修改之前编写过的代码
把伪造手机号封装成一个函数,方便调用,新建一个phone_number.py放在common目录下
phone_number.py代码如下:
from faker import Faker
def mobile_phone():
faker = Faker(locale=['zh-cn'])
return faker.phone_number()修改测试用例内容:
需要伪造手机号的地方做个标记
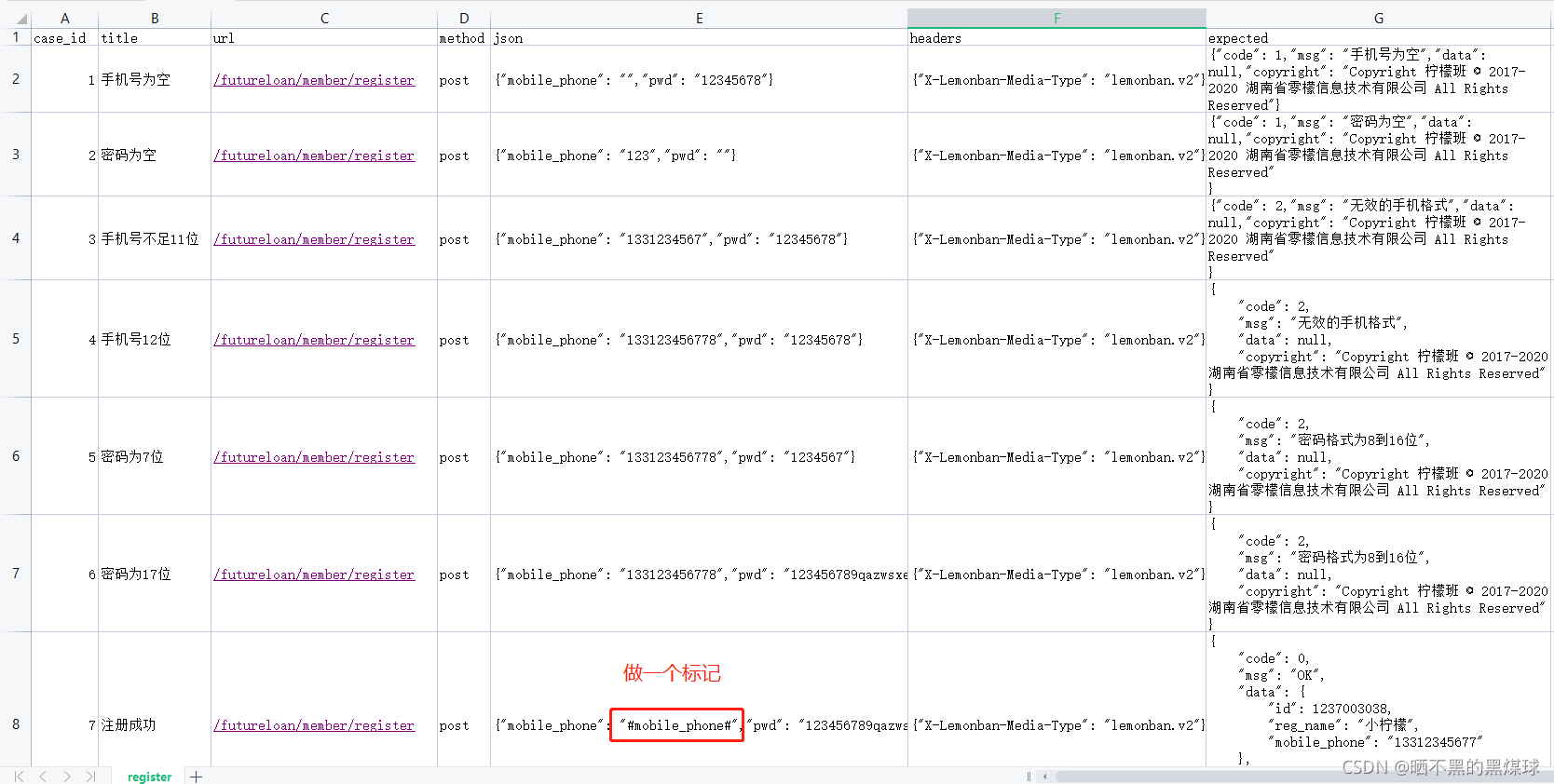
修改test_register_ddt.py代码如下:
import unittest
import requests
import json
from common.excel import read_excel
from config import config
from ddt import ddt, data
from common.logger import log
from common.phone_number import mobile_phone
# 得到测试数据
excel_data = read_excel(file_name=config.cases_dir, sheet_name='register')
@ddt
class TestRegister(unittest.TestCase):
@data(*excel_data)
def test_register(self, info):
'''步骤:
1.准备测试数据
2.发送接口请求,得到实际结果
3.预期结果和实际结果的断言
'''
# 1.准备测试数据
log.info(f'正在测试{info}')
# 要把配置文件的host跟取出来excel表中的url进行拼接
url = config.host + info['url']
method = info['method']
# 将json格式字符串转化成字典,因为requests.request需要字典格式
headers = json.loads(info['headers'])
# json_data不需要反序列化,因为后面需要用str数据类型
json_data = info['json']
# 检测:如果json_data中存在某个标记,就说明需要我自动生成一个手机号码
# 调用 mobile_phone()函数
# 把替换后的新手机号再赋值给json_data,因为得到的新字符串需要变量接收
if "#mobile_phone#" in json_data:
mobile = mobile_phone()
json_data = json_data.replace("#mobile_phone#", mobile)
json_data = json.loads(json_data)
expected = json.loads(info['expected'])
# 2.发送接口请求,得到实际结果
response = requests.request(method=method, url=url,
headers=headers, json=json_data)
actual = response.json()
# 3.预期结果和实际结果的断言
self.assertEqual(expected, actual)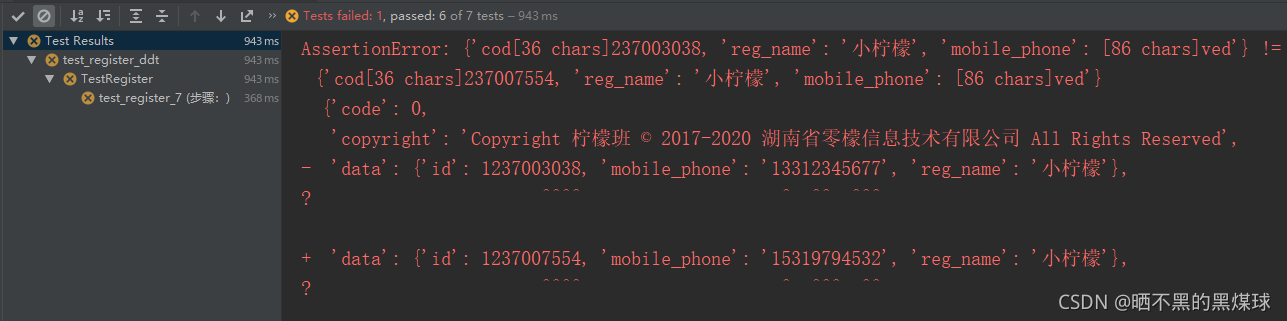
从运行结果可以看到最后一条用例还是失败了,那是因为id,mobile_phone字段的预期结果与实际结果是不一致。对于一些动态的字段值,我们无法提前获得,所以这就是全量断言的缺点。解决此问题就需要使用部分断言
6.3全量断言和部分断言
全量断言:一个字都不能差,麻烦
总分断言:提取有用的关键字段进行断言。如code,msg等。实战当中使用部分断言
修改测试用例中的expected内容
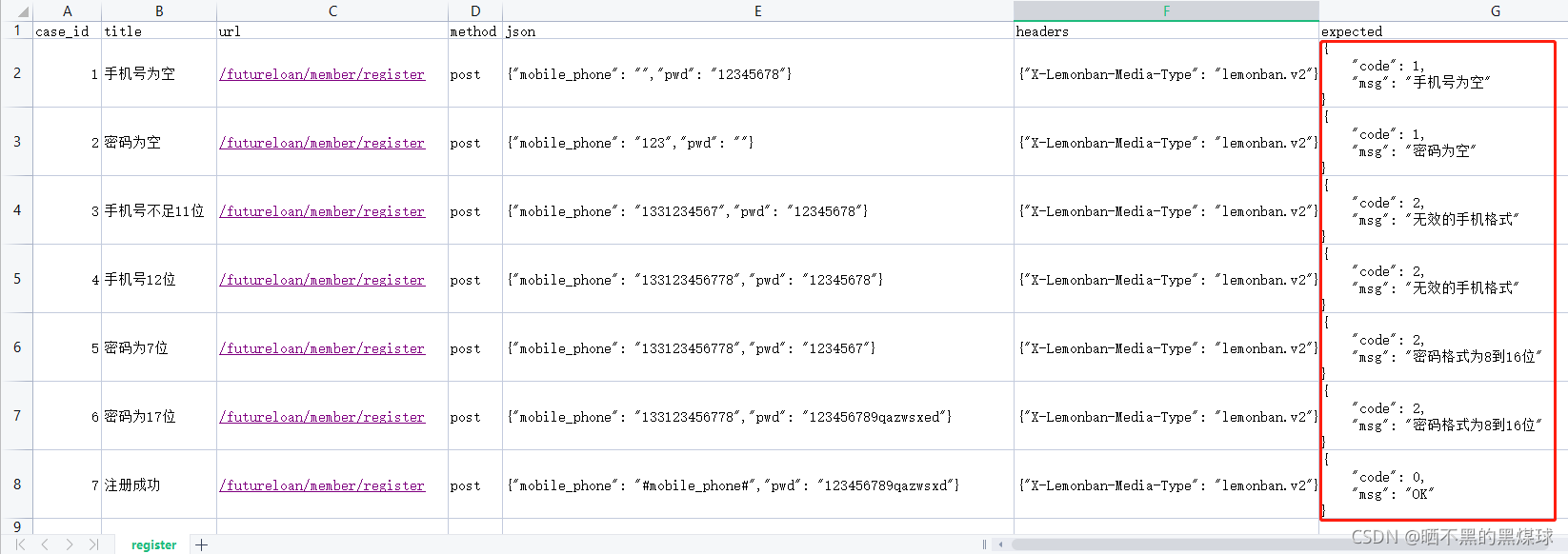
部分断言多种方法可以使用:

修改test_register_ddt.py代码如下:
import unittest
import requests
import json
from common.excel import read_excel
from config import config
from ddt import ddt, data
from common.logger import log
from common.phone_number import mobile_phone
# 得到测试数据
excel_data = read_excel(file_name=config.cases_dir, sheet_name='register')
@ddt
class TestRegister(unittest.TestCase):
@data(*excel_data)
def test_register(self, info):
'''步骤:
1.准备测试数据
2.发送接口请求,得到实际结果
3.预期结果和实际结果的断言
'''
# 1.准备测试数据
log.info(f'正在测试{info}')
# 要把配置文件的host跟取出来excel表中的url进行拼接
url = config.host + info['url']
method = info['method']
# 将json格式字符串转化成字典,因为requests.request需要字典格式
headers = json.loads(info['headers'])
# json_data不需要反序列化,因为后面需要用str数据类型
json_data = info['json']
# 检测:如果json_data中存在某个标记,就说明需要我自动生成一个手机号码
# 调用 mobile_phone()函数
# 把替换后的新手机号再赋值给json_data,因为得到的新字符串需要变量接收
if "#mobile_phone#" in json_data:
mobile = mobile_phone()
json_data = json_data.replace("#mobile_phone#", mobile)
json_data = json.loads(json_data)
expected = json.loads(info['expected'])
# 2.发送接口请求,得到实际结果
response = requests.request(method=method, url=url,
headers=headers, json=json_data)
actual = response.json()
# 3.预期结果和实际结果的断言
# V1版本:一个字段断言
# self.assertEqual(expected['msg'], actual['msg'])
# V2版本:使用for循环遍历expected中的字段
for key, value in expected.items():
self.assertEqual(value, actual[key])
# # V3版本:多个字段分别断言,V2版本不理解可以使用V3版本,好理解
# self.assertEqual(expected['msg'], actual['msg'])
# self.assertEqual(expected['code'], actual['code'])运行结果:

从结果可以看到解决了全量断言带来的用例失败问题
7.扩展内容
7.1测试金字塔
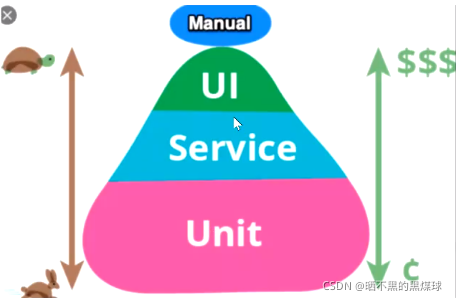
从上往下依次是单元测试,服务/接口测试(后端),UI测试(前端),系统测试(前端,后端通常都测了,也就是俗称的手工测试点点点)
左边的乌龟和兔子代表的意思是速度:越接近顶端,速度越慢,越接近低端,速度越快
右边代表的意思是成本:越接近顶端,成本越高,越接近低端,成本越低
7.2什么样的项目合适做自动化测试
- 需求稳定,不会频繁变更(项目初期不太适合)
- 研发和测试周期长,需要频繁执行回归测试(搞活动)
- 需要在多种平台上重复运行相同测试的场景
- 某些测试项目通过手工测试无法实现,或者手工成本太高
- 被测软件的开发较为规范,能够保证系统的可测试行
7.3图片验证码
测试接口时,遇到图片验证码的问题,该怎么解决?
- 找开发直接关掉验证码的功能
- 找开发要万能的验证码
- 对接第三方的平台(超级鹰)
- 代码的方式去实现(字母识别(OCR)图像识别,图像处理,机器学习(AI))过程比较复杂。而且使用了这些功能也不一定能识别的出来,如12306登录页面的图片验证(专门的爬虫工程师都不好搞出来)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)