Ubuntu20.04搭建hadoop集群
❀因为学业原因,我需要学习在Ubuntu系统上面搭建出hadoop集群,此贴记录下我的搭建过程,防止以后自己忘记首先需要提前搭建好Ubuntu系统,在系统中配置上静态ipUbuntu20.04静态ip的配置:第一步:cd /etc/netplan第二步:修改其下名为01-network-manager-all.yaml的文件vi 01-network-manager-all.yaml第三步:文件初
❀因为学业原因,我需要学习在Ubuntu系统上面搭建出hadoop集群,此贴记录下我的搭建过程,防止以后自己忘记
首先需要提前搭建好Ubuntu系统,在系统中配置上静态ip
Ubuntu20.04静态ip的配置:
第一步:cd /etc/netplan
第二步:修改其下名为01-network-manager-all.yaml的文件
vi 01-network-manager-all.yaml
第三步:
文件初始状态

增加内容
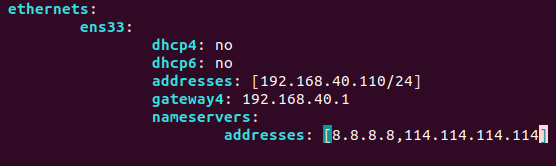 我的虚拟网络编辑器NAT模式下的WMnet8的子网地址为192.168.40.0,故而如此设定,每个人的都不相同,根据自己的来设定
我的虚拟网络编辑器NAT模式下的WMnet8的子网地址为192.168.40.0,故而如此设定,每个人的都不相同,根据自己的来设定
第四步:更新设置sudo netplan apply
第五步:ip addr查看ip地址,此时已经发生变化
叮叮叮!!!!意外发现一种更简单的方法:
在网络-有线-设置里面
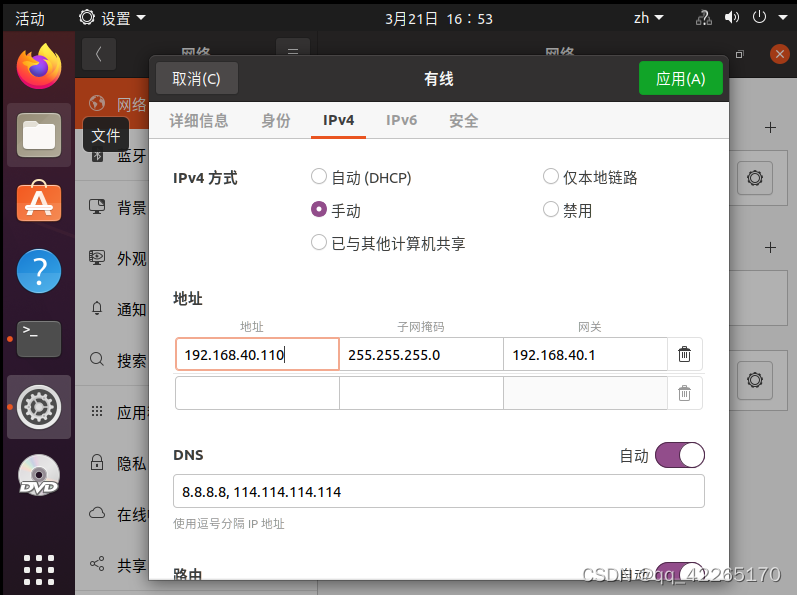 可以直接手动更改,然后应用。。。。。。
可以直接手动更改,然后应用。。。。。。
虚拟机名称的修改:
hostname:查看现在的主机名称
主机名称修改:hostnamectl set-hostname ‘hadoop01’
 克隆虚拟机:
克隆虚拟机:
hadoop集群的配置需要多台服务器,这里根据个人需要配置克隆虚拟机的数量
*`右键-管理-克隆-虚拟机中的当前状态-创建完整克隆`*
克隆完毕要修改克隆之后的虚拟机的静态ip地址,切记不要同时点开多个虚拟机,因为此时他们的ip地址都相同
jdk配置:
首先需要下载安装好jdk包,我用的是jdk1.8.0_211,8版本的好像比较好用,根据自己的需要去安装,将jdk的安装包解压到/usr/local/java/之下
解压指令网上都是,例如tar -zxvf jdkXXX -C /usr/local/java/
随后配置jdk环境:
vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_211
export PATH=$PATH:$JAVA_HOME/bin
修改完成后更新配置
source /etc/profile
服务器之间互传资料:
配置host映射:vi /etc/hosts
最后一行增加 (每一个虚拟机中都要做此操作哦,因为交朋友是双向的)
192.168.40.110 hadoop01
192.168.40.120 hadoop02
192.168.40.130 hadoop03
传文件scp -r /usr/local/jdkXXX hadoop02:/usr/local/
输入传输语句后,我在这个部分报错了:
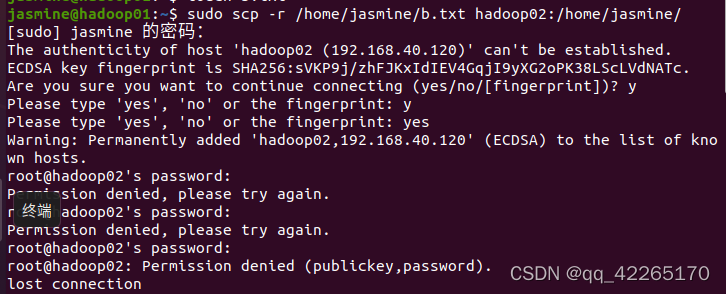 解决办法:
解决办法:
- 修改/etc/ssh/ssh_config文件的配置,以后则不会再出现此问题
修改内容中:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
之后传输就成功了
2. 修改目标服务器的/etc/ssh/sshd_config中的PermitRootLogin 为 yes ,然后重启ssh : service ssh restart
免密操作(很重要):
1.各个服务器各自生成各自的密码:ssh-keygen
2.每个服务器告诉其他服务器自己的密码,别忘了告诉自己:
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
Hadoop集群配置
以Hadoop01为主节点为例,首先下载hadoop的安装包并解压到/usr/local/hadoop下
进入解压后的hadoop文件包里,到etc中,修改配置文件:
1.先修改hadoop依赖的环境(hadoop的底层代码使用的是java语言)
vi hadoop-env.sh

2.配置外界去访问hadoop的时候,所依赖的端口
vi core-site.xml
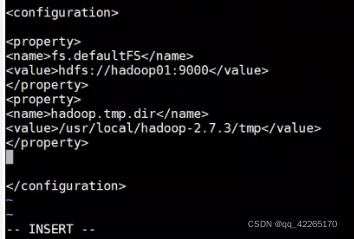
3.配置元数据与真实数据保存的位置
vi hdfs-site.xml
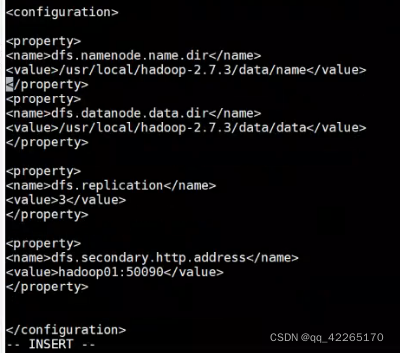
replication用作数据备份,可以为3可以为2,根据从节点的数量设置最好,hadoop02与hadoop03最好就设置为2
4.配置mapreduce计算框架交给yarn资源来管理
vi mapred-site.xml(先不操作)
发现是一个临时文件,需修改成正式文件
mv mapred-site.xml.template mapred-site.xml
然后再Vi mapred-site.xml
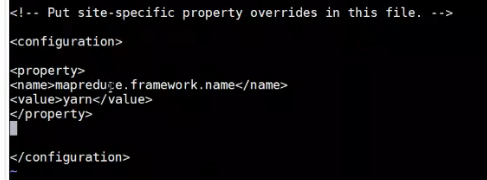
5.配置yarn资源调度
vi yarn-site.xml
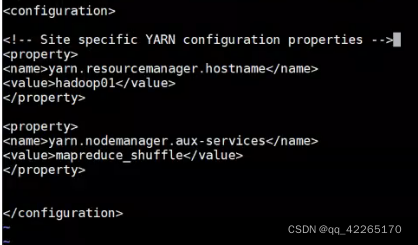
6.告诉集群,谁是从节点 hadoop02 hadoop03
vi slaves
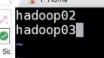
主节点设置为hadoop01,不要把01也写进去
将配置的hadoop分发到所有的服务器:
scp -r /usr/local/hadXXX hadoop02:/usr/local/
scp -r /usr/local/hadXXX hadoop03:/usr/local/

启动的操作只需要在hadoop01主机中进行,0203不需要做
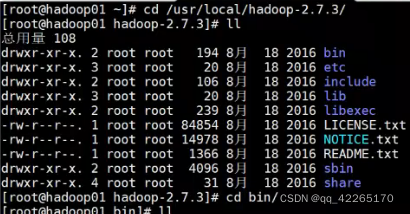
进入到sbin中
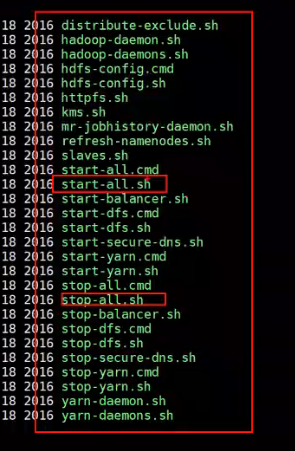
需要配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local.hadoop-2.7.3
PATH中加一句:$HADOOP_HOME/bin:%HADOOP_HOME/sbin

然后更新环境配置 source /etc/profile
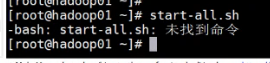
随后不要立刻start-all.sh!!!
第一次创建的hadoop集群,必须先初始化,初始化仅需一次,以后不要再进行初始化!!!
初次初始化会给主节点和从节点分配一致的clusterID,如果再初始化一次的话,主节点的clusterID就会改变,而从节点的不变,那么二者的ID就不一致了,就会出问题,无法管理。
clusterID的存放位置在/usr/local/hadXXX/data/name(data)/current,其下有一个VERSION,cat一下就会出现clusterID
hadoop namenode -format
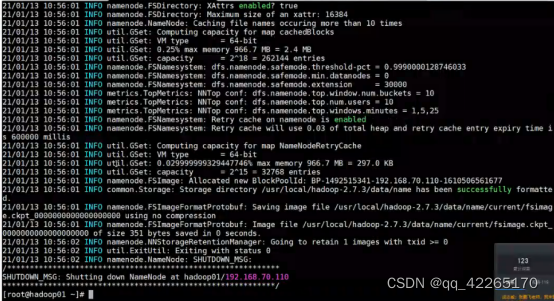
这样就初始化成功啦!
随后可以开启集群

集群启动了之后可以通过jps查看一下节点名称
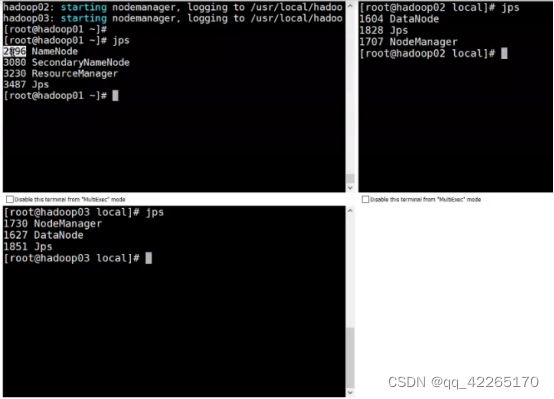
出现这个界面就证明hadoop集群配置成功了!
注意:每次对集进行修改后都需要停掉集群!!!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)