linux内核分析一CFS (完全公平调度算法)
进程优先级,进程nice值和%nice的解释用top或者ps命令会输出PRI/PR、NI、%ni/%nice这三种指标值,这些到底是什么东西?先给出大概的解释如下:PRI :进程优先权,代表这个进程可被执行的优先级,其值越小,优先级就越高,越早被执行NI :进程Nice值,代表这个进程的优先值%nice :改变过优先级的进程的占用CPU的百分比 (呵呵,这句好难理解是吧,不急慢慢来_)PRI是比较
进程优先级,进程nice值和%nice的解释
用top或者ps命令会输出PRI/PR、NI、%ni/%nice这三种指标值,这些到底是什么东西?先给出大概的解释如下:
PRI :进程优先权,代表这个进程可被执行的优先级,其值越小,优先级就越高,越早被执行
NI :进程Nice值,代表这个进程的优先值
%nice :改变过优先级的进程的占用CPU的百分比 (呵呵,这句好难理解是吧,不急慢慢来_)
PRI是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值。如前面所说,PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice。由此看出,PR是根据NICE排序的,规则是NICE越小PR越前(小,优先权更大),即其优先级会变高,则其越快被执行。如果NICE相同则进程uid是root的优先权更大。
在LINUX系统中,Nice值的范围从-20到+19(不同系统的值范围是不一样的),正值表示低优先级,负值表示高优先级,值为零则表示不会调整该进程的优先级。具有最高优先级的程序,其nice值最低,所以在LINUX系统中,值-20使得一项任务变得非常重要;与之相反,如果任务的nice为+19,则表示它是一个高尚的、无私的任务,允许所有其他任务比自己享有宝贵的CPU时间的更大使用份额,这也就是nice的名称的来意。
对nice值一个形象比喻,假设在一个CPU轮转中,有2个runnable的进程A和B,如果他们的nice值都为0,假设内核会给他们每人分配1k个cpu时间片。但是假设进程A的为0,但是B的值为-10,那么此时CPU可能分别给A和B分配1k和1.5k的时间片。故可以形象的理解为,nice的值影响了内核分配给进程的cpu时间片的多少,时间片越多的进程,其优先级越高,其优先级值(PRI)越低。%nice,就是改变过优先级的进程的占用CPU的百分比,如上例中就是0.5k/2.5k=1/5=20%。
由此可见,进程nice值和进程优先级不是一个概念,但是进程nice值会影响到进程的优先级变化。
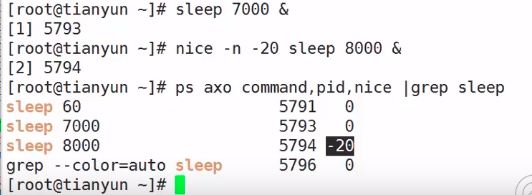
进程的nice值是可以被修改的,修改命令分别是nice和renice。
1、nice命令就是设置一个要执行command进程的nice值,其命令格式是 nice –n adjustment command command_option,如果这里不指定adjustment,则默认为10。
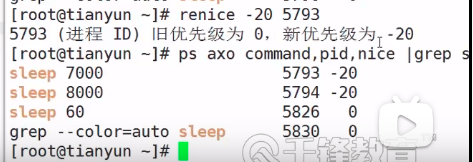
2、renice命令就是设置一个已经在运行的进程的nice值,假设一运行进程本来nice值为0,renice为3后,则这个运行进程的nice值就为3了。
说明:如果用户设置的nice值超过了nice的边界值(LINUX为-20到+19),系统就取nice的边界值作为进程的nice值。
举例如下:
对非root用户,只能将其底下的进程的nice值变大而不能变小。若想变小,得要有相应的权限。
[oracle@perf_dbc ~]$ nice
0
[oracle@perf_dbc ~]$ nice -n 3 ls
agent bin important_bak logs statistics_import.log TMP_FORUM_STATS.dmp TMP_TAOBAO_STATS.dmp TMP_TBCAT_STATS.dmp top.dmp worksh
[oracle@perf_dbc ~]$ nice -n -3 ls
nice: cannot set priority: Permission denied
对root用户,可以给其子进程赋予更小的nice值。
[root@dbbak root]# nice
0
[root@dbbak root]# nice -n -3 ls
192.168.205.191.txt anaconda-ks.cfg clariion.log Desktop disk1 emc.sh File_sort install.log install.log.syslog log OPS rhel_os_soft root_link_name
同样,renice的执行也必须要有相应的权限方可执行。


调度的发展历史
| 字段 | 版本 |
|---|---|
| O(n) 调度器 | linux0.11 - 2.4 |
| O(1) 调度器 | linux2.6 |
| CFS调度器 | linux2.6至今 |
-
O(n) 调度器是在内核2.4以及更早期版本采用的算法,其调度算法非常简单和直接,就绪队列是个全局列表,从就绪队列中查找下一个最佳任务,由于每次在寻找下一个任务时需要遍历系统中所有的任务(全局列表),因此被称为 O(n) 调度器(时间复杂度)。
-
内核2.6采用了O(1) 调度器,让每个CPU维护一个自己的就绪队列,从而减少了锁的竞争。就绪队列由两个优先级数组组成,分别是
active优先级数组和expired优先级数组。每个优先级数组包含140个优先级队列,也就是每个优先级对应一个队列,其中前100个对应实时进程,后40个对应普通进程。如下图所示:
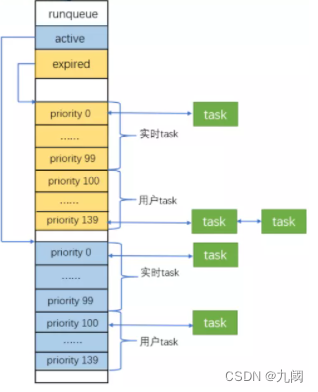
这样设计的好处,调度器选择下一个被调度任务就变得高效和简单多了,只需要在active优先级数组中选择优先级高,并且队列中有可运行的任务即可。这里使用位图来定义该队列中是否有可运行的任务,如果有,则位图中相应的位就会被置1。这样选择下一个被调用任务的时间就变成了查询位图的操作。
- 但上面的算法有个问题,一个高优先级多线程的应用会比低优先级单线程的应用获得更多的资源,这就会导致一个调度周期内,低优先级的应用可能一直无法响应,直到高优先级应用结束。CFS调度器就是站在一视同仁的角度解决了这个问题,保证在一个调度周期内每个任务都有执行的机会,执行时间的长短,取决于任务的权重。下面详细看下CFS调度器是如何动态调整任务的运行时间,达到公平调度的。
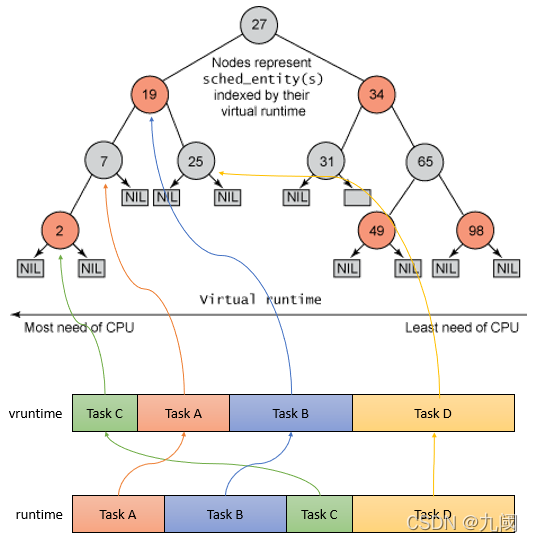
实际运行时间
CFS是Completely Fair Scheduler简称,即完全公平调度器。CFS调度器和以往的调度器不同之处在于没有时间片的概念,而是公平分配cpu使用的时间。例如:2个相同优先级的进程在一个cpu上运行,那么每个进程都将会分配50%的cpu运行时间。这就是要实现的公平。
但现实中,必然是有的进程优先级高,有的进程优先级低。CFS调度器引入权重的概念,用权重代表进程的优先级,各个进程按照权重的比例分配cpu的时间。比如:2个进程A和B。A的权重是1024,B的权重是2048。那么A获得cpu的时间比例是1024/(1024+2048) = 33.3%。B进程获得的cpu时间比例是2048/(1024+2048)=66.7%。
在引入权重之后,分配给进程的时间计算公式如下:
实际运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
CFS调度器用nice值表示优先级,取值范围是[-20, 19],nice和权重是一一对应的关系。数值越小代表优先级越大,同时也意味着权重值越大,nice值和权重之间的转换关系:
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
数组值计算公式是:
weight = 1024 / 1.25nice
公式中的1.25取值依据是:进程每降低一个nice值,将多获得10% cpu的时间。公式中以1024权重为基准值计算得来,1024权重对应nice值为0,其权重被称为NICE_0_LOAD。默认情况下,大部分进程的权重基本都是NICE_0_LOAD。
虚拟运行时间
根据上面的理解,这里看个例子。假如一个CPU的调度周期是6ms,进程A和B的权重分别是1024和820(nice值分别是0和1),那么进程A获得的运行时间是6x1024/(1024+820)=3.3ms,进程B获得的执行时间是6x820/(1024+820)=2.7ms。进程A的cpu使用比例是3.3/6x100%=55%,进程B的cpu使用比例是2.7/6x100%=45%。(符合上面说的“进程每降低一个nice值,将多获得10% CPU的时间”)
很明显,2个进程的实际执行时间是不相等的,但是CFS想保证每个进程运行时间相等。因此CFS引入了虚拟时间的概念,也就是说上面的2.7ms和3.3ms经过一个公式的转换可以得到一样的值,这个转换后的值称作虚拟时间。这样的话,CFS只需要保证每个进程运行的虚拟时间是相等的即可。
虚拟时间vriture_runtime和实际时间(wall time)转换公式如下:
虚拟运行时间 = 实际运行时间 * NICE_0_LOAD / 进程权重 = (调度周期 * 进程权重 / 所有进程权重之和) * NICE_0_LOAD / 进程权重 = 调度周期 * 1024 / 所有进程总权重
vruntime = (调度周期 * 进程权重 / 所有进程总权重) * 1024 / 进程权重 = 调度周期 * 1024 / 所有进程总权重
从公式可以看出,在一个调度周期里,所有进程的虚拟运行时间是相同的。所以在进程调度时,只需要找到虚拟运行时间最小的进程调度运行即可。
为了能够快速找到虚拟运行时间最小的进程,Linux 内核使用红黑树来保存可运行的进程。CFS跟踪调度实体sched_entity的虚拟运行时间vruntime,将sched_entity通过enqueue_entity()和dequeue_entity()来进行红黑树的出队入队,vruntime少的调度实体sched_entity排列到红黑树的左边。
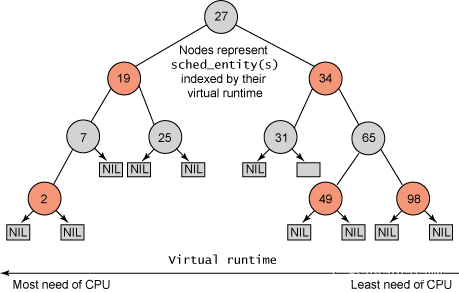
如上图所示,红黑树的左节点比父节点小,而右节点比父节点大。所以查找最小节点时,只需要获取红黑树的最左节点即可。
相关步骤如下:
- 每个sched_latency周期内,根据各个任务的权重值,可以计算出运行时间runtime;
- 运行时间runtime可以转换成虚拟运行时间vruntime;
- 根据虚拟运行时间的大小,插入到CFS红黑树中,虚拟运行时间少的调度实体放置到左边;
- 在下一次任务调度的时候,选择虚拟运行时间少的调度实体来运行(pick_next_task从就绪队列中选择最适合运行的调度实体,即虚拟时间最小的调度实体);
CFS 数据结构
- task_struct: 任务描述符,包含很多进程相关的信息,例如,优先级、进程状态以及调度实体等。
struct task_struct {
...
struct sched_entity se;
...
}
- cfs_rq:跟踪就绪队列信息以及管理就绪态调度实体,并维护一棵按照虚拟时间排序的红黑树。tasks_timeline->rb_root是红黑树的根,tasks_timeline->rb_leftmost指向红黑树中最左边的调度实体,即虚拟时间最小的调度实体。
struct cfs_rq {
...
struct rb_root_cached tasks_timeline
...
};
- sched_entity:可被内核调度的实体。每个就绪态的调度实体sched_entity包含插入红黑树中使用的节点rb_node,同时vruntime成员记录已经运行的虚拟时间。
struct sched_entity {
...
struct rb_node run_node;
...
u64 vruntime;
...
};
这些数据结构的关系如下图所示:

CFS 算法实现
时钟中断 scheduler_tick 更新虚拟运行时间,检查是否需要抢占。
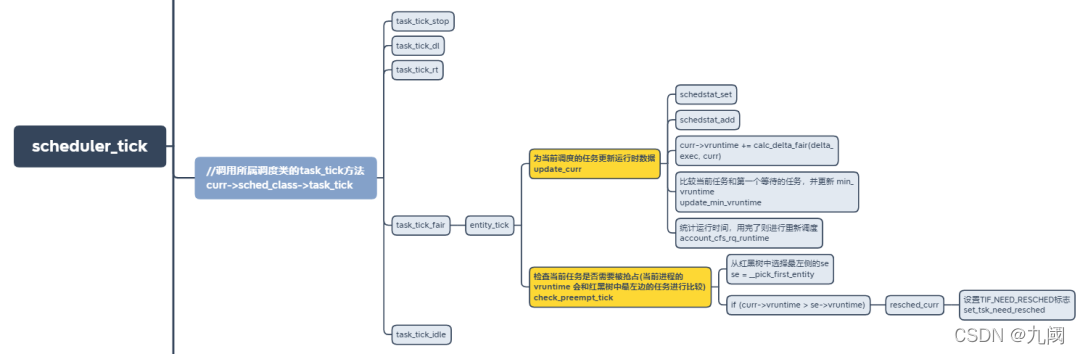
更新运行时的各类统计信息,比如vruntime, 运行时间、负载值、权重值等。
检查是否需要抢占,主要是比较运行时间是否耗尽,以及vruntime的差值是否大于运行时间等。
2、 任务出队入队
当任务进入可运行状态时,用 enqueue_task_fair 将调度实体放入到红黑树中,完成入队操作;当任务退出可运行状态时,用 dequeue_task_fair 将调度实体从红黑树中移除,完成出队操作;队操作。

调用 __enqueue_entity 函数后,就可以把进程调度实体插入到运行队列的红黑树中。同时会把红黑树最左端的节点缓存到运行队列的 rb_leftmost 字段中,用于快速获取下一个可运行的进程。
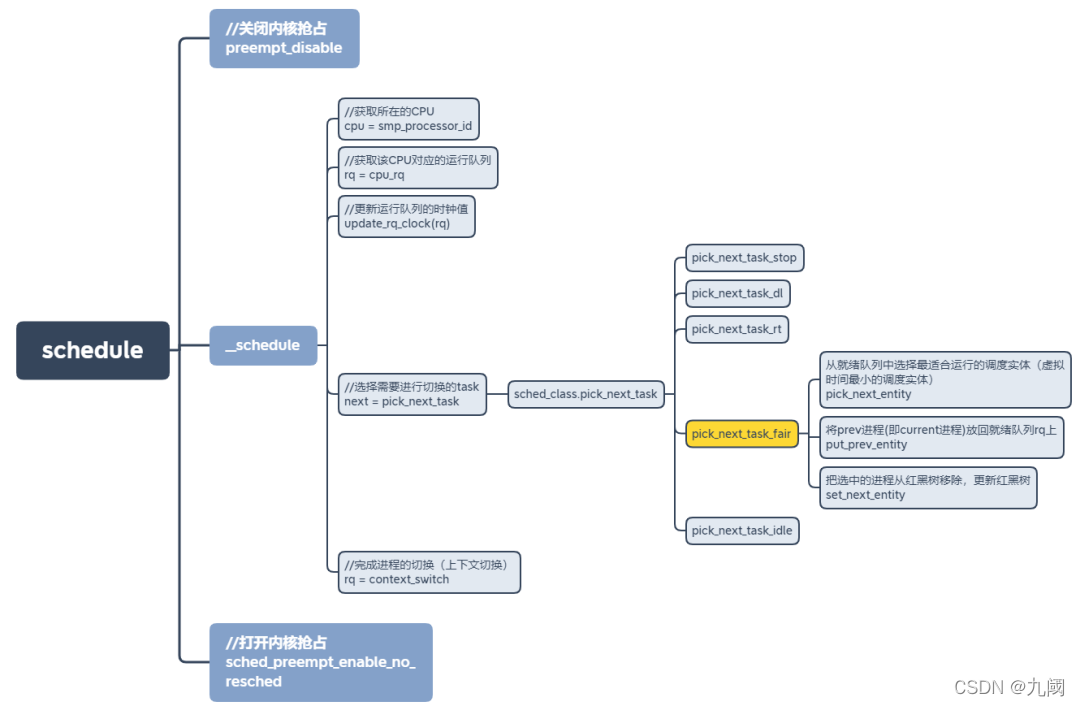
3、从 cfs_rq 中获取下一个可运行的任务
每当进程任务切换的时候,也就是schedule函数执行时,调度器都需要选择下一个将要执行的任务。在CFS调度器中,是通过 pick_next_task_fair 函数完成的,其本质是从就绪队列中选择最适合运行的调度实体(虚拟时间最小的调度实体)。
补充进程优先级(nice值)
进程特性nice值运行进程间接地影响内核的调度算法:
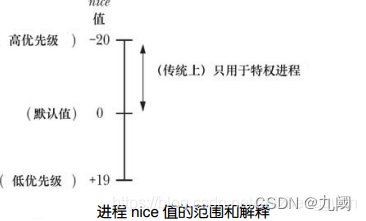
- 每个进程都拥有一个 nice 值,其取值范围为−20(高优先级)~19(低优先级),默认值为 0
- 在传统的 UNIX 实现中,只有特权进程才能够赋给自己(或其他进程)一个负(高)优先级
- 非特权进程只能降低自己的优先级,即赋一个大于默认值 0 的nice 值。
使用fork()创建子进程时会继承nice值并且该值会在exec()调用中得到保持
getpriority()系统调用服务例程不会返回实际的nice值,相反,它会返回一个范围在 1(低优先级)~40(高优先级)之间的数字,这个数字是通过公式 unice=20-knice 计算得来的。这样做是为了避免让系统调用服务例程返回一个负值,因为负值一般都表示错误
nice值的影响
- 进程的调度不是严格按照nice值的层次进行的,nice值只是一个权重因素,会导致内核调度器倾向于调度高优先级的进程
- 给一个进程赋一个低优先级(即高 nice 值)并不会导致它完全无法用到 CPU,但会导致它使用 CPU 的时间变少
- nice值对进程调度的影响程度则依据Linux内核版本的不同而不同,在不同Unix系统之间也是不同的
从版本号为 2.6.23 的内核开始,nice 值之间的差别对新内核调度算法的影响比对之前的内核中的调度算法的影响要强。因此,低 nice 值的进程使用 CPU 的时间将比以前少,高nice 值的进程占用 CPU 的时间将大大提高
获取和修改优先级
getpriority()和 setpriority()系统调用允许一个进程获取和修改自身或其他进程的 nice 值
NAME
getpriority, setpriority - get/set program scheduling priority
SYNOPSIS
#include <sys/time.h>
#include <sys/resource.h>
int getpriority(int which, int who);
int setpriority(int which, int who, int prio);
RETURN VALUE
由于 getpriority() 可以合法地返回值 -1,因此需要在调用之前清除外部变量 errno,然后再检查
它以确定 -1 是错误还是合法值。 如果没有错误,则 setpriority() 调用返回 0,如果有则返回 -1
两个系统调用都接收参数 which 和 who,这两个参数用于标识需读取或修改优先级的进程。which 参数确定 who 参数如何被解释。这个参数的取值为下面这些值中的一个
- PRIO_PROCESS :操作进程 ID 为 who 的进程。如果 who 为 0,那么使用调用者的进程 ID
- PRIO_PGRP :操作进程组 ID 为 who 的进程组中的所有成员。如果 who 为 0,那么使用调用者的进程组。
- PRIO_USER :操作所有真实用户 ID 为 who 的进程。如果 who 为 0,那么使用调用者的真实用户 ID
who 参数的类型 id_t 是一个大小能容纳进程 ID 或用户 ID 的整型。
getpriority()系统调用返回由which和who指定的进程的nice值。
- 如果有多个进程符号指定的标准(which 为 PRIO_PGRP 或 PRIO_USER),那么返回优先级最高的nice 值(即最小的数值)
- 由于 getpriority()可能会在成功时返回−1,因此在调用这个函数之前必须要将 errno 设置为 0,接着在调用之后检查返回值为−1 以及 errno 不为 0 才能确认调用成功。
setpriority()系统调用会将由 which 和 who 指定的进程的 nice 值设置为 prio。试图将 nice 值设置为一个超出允许范围的值(-20~+19)时会直接将 nice 值设置为边界值。
以前 nice 值是通过调用 nice(incr)来完成的,这个函数会将调用进程的 nice 值加上 incr。现在这个函数仍然是可用的,但已经被更通用的 setpriority()系统调用所取代了。
在命令行中与 setpriority()系统调用实现类似功能的命令是 nice(1),非特权用户可以使用这个命令来运行一个优先级更低的命令,特权用户则可以运行一个优先级更高的命令,超级用户则可以使用 renice(8)来修改既有进程的 nice 值。
从版本号为 2.6.12 的内核开始,Linux 提供了 RLIMIT_NICE 资源限制,即允许非特权进程提升 nice 值。非特权进程能够将自己的 nice 值最高提高到公式 20−rlim_cur 指定的值,其中 rlim_cur是当前的 RLIMIT_NICE 软资源限制。
#include <cstdlib>
#include <sys/time.h>
#include <sys/resource.h>
#include <cstdio>
#include <cstring>
#include <errno.h>
int main(int argc, char *argv[])
{
int which, prio;
id_t who;
if (argc != 4 || strchr("pgu", argv[1][0]) == NULL){
printf("%s {p|g|u} who priority\n"
" set priority of: p=process; g=process group; "
"u=processes for user\n", argv[0]);
exit(EXIT_FAILURE);
}
/* Set nice value according to command-line arguments */
which = (argv[1][0] == 'p') ? PRIO_PROCESS :
(argv[1][0] == 'g') ? PRIO_PGRP : PRIO_USER;
who = atoi(argv[2]);
prio = atoi(argv[3]);
if (setpriority(which, who, prio) == -1){
perror("setpriority");
exit(EXIT_FAILURE);
}
/* Retrieve nice value to check the change */
errno = 0; /* Because successful call may return -1 */
prio = getpriority(which, who);
if (prio == -1 && errno != 0){
perror("getpriority");
exit(EXIT_FAILURE);
}
printf("Nice value = %d\n", prio);
exit(EXIT_SUCCESS);
}
文章来源
https://blog.csdn.net/zhizhengguan/article/details/117434191
https://blog.csdn.net/longdel/article/details/7317511
https://www.cnblogs.com/tianguiyu/articles/6091378.html
https://blog.csdn.net/melody157398/article/details/116725115

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)