网络工程师——正则表达式(模糊匹配)
网络工程师——正则表达式1.什么是正则表达式正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工
网络工程师——正则表达式(模糊匹配)
(本博客借鉴《网络工程师的python之路这本书》
1.什么是正则表达式
正则表达式,又称规则表达式,计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
(来源百度百科)
2.正则表达式的规则(模糊匹配)
| 匹配符号 | 用法 |
|---|---|
| . | 匹配除换行符之外的所有字符(一次) |
| * | 用来匹配紧靠该符号左边的符号,匹配次数0次或多次。 |
| + | 用来匹配紧靠该符号左边的符号,匹配次数1次或多次。 |
| ? | 用来匹配紧靠该符号左边的符号,匹配次数0次或1次。 |
| {m} | 用来匹配紧靠该符号左边的符号,指定匹配次数为m次,例如字符串’abbbbcccd’,使用ab{2}将匹配到abb,使用bc{3}d将匹配到bcccd。 |
| {m,n} | 用来匹配紧靠该符号左边的符号,指定匹配次数为最少m次,最多n次。 例如字符串’abbcccd’,使用ab{2,3}将只能匹配到abb,如果字符串为’abbbbcccdabbccd’,使用ab{2,3}将能同时匹配到abbb和abb。如果字符串内容为’abcd’使用ab{2,3}将匹配不到任何东西。 |
| {m,} | 用来匹配紧靠该符号左边的符号,指定匹配次数为最少m次,最多无限次。 |
| {,n} | 用来匹配紧靠该符号左边的符号,指定匹配次数为最少0次,最多n次。 |
| \ | 例如字符串内容中出现了问号"?”,而你又想精确匹配这个问号,那就要使用?来进行匹配。除此之外,\也用来表示一个特殊序列。 |
| [] | 表示字符集合,用来精确匹配。比如想要精确匹配一个数字,可以使用[0-9]。如果要精确匹配一个小写字母,可以用[a-z],如果要精确匹配一个大写字母,可以用[A-Z],如果要匹配一个数字、字母或者下划线,可以用[0-9a-zA-Z_]。另外在[]中加^表示取非,比如[^O-9]表示匹配一个非数字的字符,[^a-z]表示匹配一个非字母的字符,以此类推。 |
| | | 表示或匹配(两项中匹配其中任意一项),比如要匹配FastEthernet和GigabitEthernet这两种端口名,可以写作Fa|Gi。 |
| (…) | 组合,匹配括号内的任意正则表达式,并标识出组合的开始和结尾,例如(blcd)ef表示bef或cdef。 |
| \d | 匹配任意一个十进制数字,等价于[0-9] |
| \D | ld取非,匹配任意一个非十进制数字,等价于[^0-9] |
| \w | 匹配任意一个字母,十进制数字以及下划线,等价于[a-zA-Z0-9_] |
| \W | 匹配任意个一个空白字符,包括空格,换行符\n等等。 |
| \s | 匹配任意个一个空白字符,包括空格,换行符\n等等。 |
在使用表达式之前一定要先import re
2.1[]的应用
>>> re.match('a[a-z]c',`在这里插入代码片`'abc')
<re.Match object; span=(0, 3), match='abc'>匹配a-z之间任意字符
>>> re.match('a[a-z]c','a1c')
>>> re.match('a[0-9]c','a1c')
<re.Match object; span=(0, 3), match='a1c'>匹配0-9之间任意字符
>>> re.match('a[^a-z]c','a1c')
<re.Match object; span=(0, 3), match='a1c'>匹配除了a-z之间任意
2.2* ?()的应用
>>> re.match('ba(na)?','ba')
<re.Match object; span=(0, 2), match='ba'>
>>> re.match('ba(na)?','bana')
<re.Match object; span=(0, 4), match='bana'>
>>> re.match('ba(na)?','banana')
<re.Match object; span=(0, 4), match='bana'>
>>> re.match('ba(na)*','ba')
<re.Match object; span=(0, 2), match='ba'>
>>> re.match('ba(na)*','bana')
<re.Match object; span=(0, 4), match='bana'>
>>> re.match('ba(na)*','banana')
<re.Match object; span=(0, 6), match='banana'>
总结:? 0或1 * 0或无穷
2.3 |的应用
>>> re.match('root|Root','root')
<re.Match object; span=(0, 4), match='root'>
>>> re.match('root|Root','Root')
<re.Match object; span=(0, 4), match='Root'>
2.4贪婪匹配
*, +,?,{m}, {m,}, {m,n}这六种匹配符号默认都是贪婪匹配的,即会尽可能多的去匹配符合条件的内容。举例如下:
举例如下:
假设给定的字符串为’xxzyzyz’,我们使用正则表达式x.*y来做匹配(注:精确匹配和模糊匹配可以混用)。在匹配到第一个x后,开始匹配.*,因为.和*默认是贪婪匹配,这里它会一直往后匹配,直到匹配到最后一个y,因此这里的匹配结果为xxzyzy。
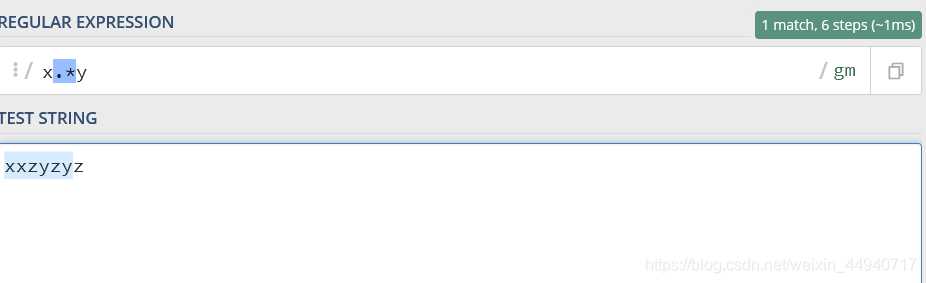
(测试网站为https://regex101.com/)
2.5非贪婪匹配
要实现非贪婪匹配很简单,就是在上述六种贪婪匹配符号后面加上问号?即可,也即是*?, +?, ??, {m}?, {m,}?, {m,n}?。
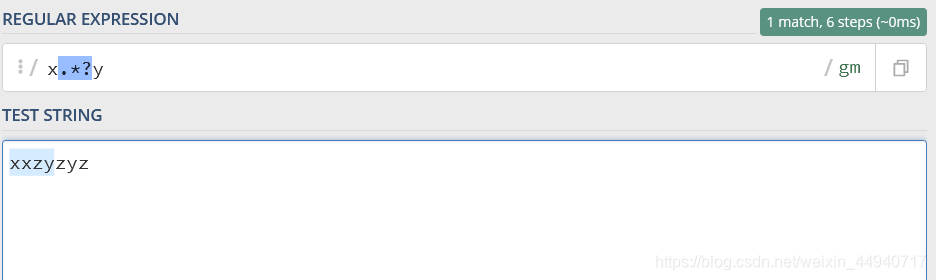 因为.*?是非贪婪匹配,这里它在匹配到第一个y后便随即停止,因此这里的匹配结果为xxzy。
因为.*?是非贪婪匹配,这里它在匹配到第一个y后便随即停止,因此这里的匹配结果为xxzy。
?可以认为是对于?后面的字符生效,只要匹配到一次?后面的字符就结束匹配
2.6实例
匹配思科交换机中日志类型\w{1,9}-\d-\w{6,13}
000459: Feb 17 17:10:35.202: %LINK-3-UPDOWN: Interface FastEthernet0/2, changed state to up
000460: Feb 17 17:10:36.209: %LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
000461: Feb 17 22:39:26.464: %SSH-5-SSH2_SESSION: SSH2 Session request from 10.1.1.1 (tty = 0) using crypto cipher 'aes128-cbc', hmac 'hmac-sha1' Succeeded
000462: Feb 17 22:39:27.748: %SSH-5-SSH2_USERAUTH: User 'test' authentication for SSH2 Session from 10.1.1.1 (tty = 0) using crypto cipher 'aes128-cbc', hmac 'hmac-sha1' Succeeded
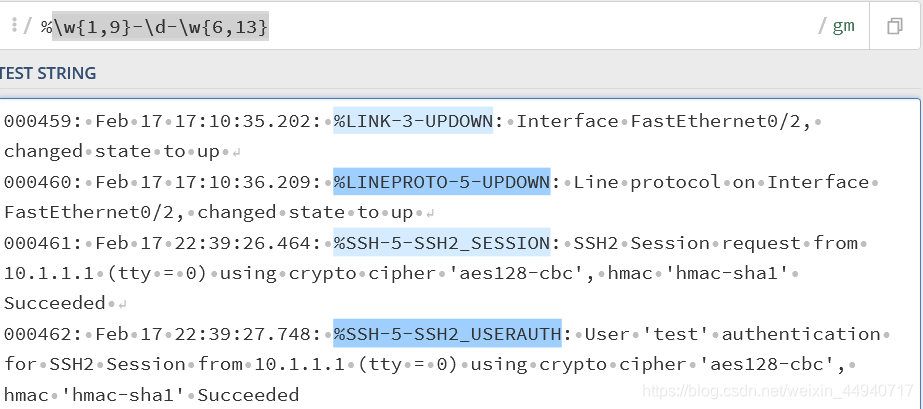
用LINK-3-UPDOWN举例
%:匹配%
w{1,9}:匹配 link
-:匹配-
\d:匹配3
w{6,13}:匹配 UPDOWN
3 各种方法
3.1 re.mach()
(前文已经用过了)
这里我们使用re.match()函数,从字符" Test match() function of regular expression. "里去精确匹配模式’Test’,因为’Test’位于该段字符串的起始位置,所以匹配成功,并且返回了一个匹配到的对象<re.Match object; span=(0, 4), match=‘Test’>,为了查看该对象的具体的值,我们可以对该对象调用group()方法,得到具体的值’Test’,该值的数据类型为字符串。
import re
test='Test match() function or regular expression.'
a=re.match(r"Test",test)
print(a)
print(a.group())
输出:
<re.Match object; span=(0, 4), match='Test'>
Test
如果这里我们不从字符串的起始位置去匹配,而是去匹配中间或末尾的字符串内容的话,那么re.match()将匹配不到任何东西,从而返回None,比如这里我们去匹配’function’这个词,因为function不在’Test match() function of regular expression.'这句字符串的开头,所以这里re.match()返回的值为None。
import re
test='Test match() function or regular expression.'
a=re.match(r"function",test)
print(a)
print(a.group())
输出
None
re.match 必须从开头匹配
a=re.match(r"function",test)中的r什么意思?意思是“ ”中的是原始字符串,总之在正则表达式中,建议都使用原始字符串。
3.2 re.search()
import re
test='Test match() function or regular expression.'
a=re.search(r"function",test)
print(a)
print(a.group())
输出:
<re.Match object; span=(13, 21), match='function'>
function
re.search方法可以匹配字符串中的任意位置的内容。
但是它和re.match()一样一次只能匹配到一个字串内容,比如下面是某台路由器上show ip int brief的输出结果,我们希望用正则表达式来匹配到在该输出内容中出现的所有IPv4地址:
R6#sh ip int br
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 192.168.1.1 YES manual up up
FastEthernet1/0 192.168.2.1 YES manual up up
FastEthernet2/0 192.168.3.1 YES manual up up
import re
ip='''R6#sh ip int br
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 192.168.1.1 YES manual up up
FastEthernet1/0 192.168.2.1 YES manual up up
FastEthernet2/0 192.168.3.1 YES manual up up
'''#用'''可以匹配大段字符串
ip_address=re.search(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",ip)
print(ip_address.group())
输出:
192.168.1.1
这里我们用正则表达式\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}做为模式来匹配任意IPv4地址,注意我们在分割每段IP地址的‘.’前面加了转义符号\,如果不加\,写成\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}的话,那么将会匹配到’GigabitEthernet1/1’中的’1/1’.
print (a.group())后可以看到这里我们只匹配到了192.168.1.1这一个IPv4地址,如果想匹配到其他所有的IPv4地址,必须用到grre.findall()。
3.3 re.findall()
如果字符串中有多个关键词都能被匹配出来,那么可以使用re.findall()。与re.match()和re.search()不一样的是,re.findall()的返回值是列表,不需要.group()。
import re
ip='''R6#sh ip int br
Interface IP-Address OK? Method Status Protocol
FastEthernet0/0 192.168.1.1 YES manual up up
FastEthernet1/0 192.168.2.1 YES manual up up
FastEthernet2/0 192.168.3.1 YES manual up up
'''#用'''可以匹配大段字符串
ip_address=re.findall(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}",ip)
print(type(ip_address))
print(ip_address)
结果:
<class 'list'>
['192.168.1.1', '192.168.2.1', '192.168.3.1']
这样就匹配到了4个人ip地址。
3.4 re.sub()
re.sub()函数用来替换字符串里被匹配到的字符串的内容。
R1#sh ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.13.1 - cc01.3ed8.0000 ARPA FastEthernet0/0
Internet 192.168.13.3 13 cc03.1048.0000 ARPA FastEthernet0/0
以路由器的arp表为例,替换两个mac地址。
import re
mac='''R1#sh ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.13.1 - cc01.3ed8.0000 ARPA FastEthernet0/0
Internet 192.168.13.3 13 cc03.1048.0000 ARPA FastEthernet0/0
'''#用'''可以匹配大段字符串
mac_address=re.sub(r"\w{4}\.\w{4}\.\w{4}",'1234.abcd.12ab',mac)
print(type(mac_address))
print(mac_address)
结果:
<class 'str'>
R1#sh ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.13.1 - 1234.abcd.12ab ARPA FastEthernet0/0
Internet 192.168.13.3 13 1234.abcd.12ab ARPA FastEthernet0/0
用1234.abcd.12ab替换了两个mac地址,默认是匹配的到的都替换。用re.sub()返回值是str,也就是字符串,也不用.goup()
如果只想改变某一个位置的mac地址可以加上参数
import re
mac='''R1#sh ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.13.1 - cc01.3ed8.0000 ARPA FastEthernet0/0
Internet 192.168.13.3 13 cc03.1048.0000 ARPA FastEthernet0/0
'''#用'''可以匹配大段字符串
mac_address=re.sub(r"\w{4}\.\w{4}\.\w{4}",'1234.abcd.12ab',mac,1)
print(type(mac_address))
print(mac_address)
re.sub()里有一个最后一个位置为optional选项,如果是1则只有第一个被匹配到的会被替换,如果是2则是前两个被匹配到的会被替换。
结果:
<class 'str'>
R1#sh ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.13.1 - 1234.abcd.12ab ARPA FastEthernet0/0
Internet 192.168.13.3 13 cc03.1048.0000 ARPA FastEthernet0/0
但是如果你想只替换第二个,那么可以用精确匹配。
4 re.match()拓展与练习
re.match()也可以输出多个结果,但是本质上也是只匹配了一个字符串内容,但是用.groups()使得用正则表达式匹配出来的内容变成元组,再用元组的索引就可以做到输出多个结果了。
例1:
import re
str1='Port-channel1.189 192.168.189.254 YES CONFIG up '
result=re.match('\s*(.*?)\s+(\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})\s*(\w+)\s*\w+\s+(\w+)\s*',str1).groups()
print(type(result))
print(result)
print('-'*80)
print('{0:<10}:{1:<}'.format('接口',result[0]))
print('{0:<10}:{1:<}'.format('IP地址',result[1]))
print('{0:<10}:{1:<}'.format('状态',result[2]))
str2='166 54a2.74f7.0326 DYNAMIC Gi1/0/11'
result1=re.match('\s*(\d+)\s*(\w+.\w+.\w+)\s*(\w+)\s*(\w.*)\s*',str2).groups()
print(result1)
print('-'*80)
print('{:<10}:{:<}'.format('vlan id',result1[0]))
print('{:<10}:{:<}'.format('mac',result1[1]))
print('{:<10}:{:<}'.format('Type',result1[2]))
print('{:<10}:{:<}'.format('interface',result1[3]))
输出:
<class 'tuple'>
('Port-channel1.189', '192.168.189.254', 'YES', 'up')
--------------------------------------------------------------------------------
接口 :Port-channel1.189
IP地址 :192.168.189.254
状态 :YES
('166', '54a2.74f7.0326', 'DYNAMIC', 'Gi1/0/11')
--------------------------------------------------------------------------------
vlan id :166
mac :54a2.74f7.0326
Type :DYNAMIC
interface :Gi1/0/11
Process finished with exit code 0
例2
import re
tr = """TCP Student 192.168.189.167:32806 Teacher 137.78.5.128:65247, idle 0:00:00, bytes 74, flags UIO
TCP Student 192.168.189.167:80 Teacher 137.78.5.128:65233, idle 0:00:03, bytes 334516, flags UIO"""
str_list = tr.split('\n')
#print(str_list )
zidian={}
for x in str_list:
#print('1',x)
result1 = re.match('(\s*\w+\s+\w+)\s+(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}).(\d+)\s+(\w+)\s+(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}).(\d+).\s+(\w+\s+)(\d.\d+.\d+.).*\w+\s(\d+).*\w+\s+(\w+)\s*',x).groups()
#print('s',result1)
key=result1[1],result1[2],result1[4],result1[6]
value=result1[-2],result1[-1]
zidian[key]=value
print("打印字典")
print(zidian)
print("格式化打印输出")
for key in zidian:
print('%10s:%-20s|%10s:%-20s|%10s:%-10s|%10s:%-20s|'%('src',key[0],'src_p',key[1],'dst',key[2],'dit_p',key[3]))
print('%10s:%-20s|%10s:%-20s'%('bytes',zidian[key][0],'flags', zidian[key][1]))
print("=" * 150)
结果:
打印字典
{('192.168.189.167', '32806', '137.78.5.128', 'idle '): ('74', 'UIO'), ('192.168.189.167', '80', '137.78.5.128', 'idle '): ('334516', 'UIO')}
格式化打印输出
src:192.168.189.167 | src_p:32806 | dst:137.78.5.128| dit_p:idle |
bytes:74 | flags:UIO
src:192.168.189.167 | src_p:80 | dst:137.78.5.128| dit_p:idle |
bytes:334516 | flags:UIO
======================================================================================================================================================

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)