【哈工大李治军】操作系统课程笔记9:设备驱动与文件管理(显示器、键盘和磁盘)
1、I/O与显示器本次所学的I/O设备主要归为两大类:键盘和显示器、磁盘要想让外设工作,只需要给相应外设中的控制器或存储器发送指令(写入数据)即可,这个外部设备就会根据这个数据操作自己的硬件设备。当外部设备完成工作后,会向CPU发送中断,表示已经完成工作,处理过程中可能就会进行传输数据等操作。如果只是上述的方式,那么我们会想能否直接向设备控制器的寄存器写数据不就行了吗?答:不能。因为需要查在这个过
(应粉丝催更,笔记提前放出来了,还剩最后一个视频,等有空了再整理)
1、I/O与显示器(终端设备输出)
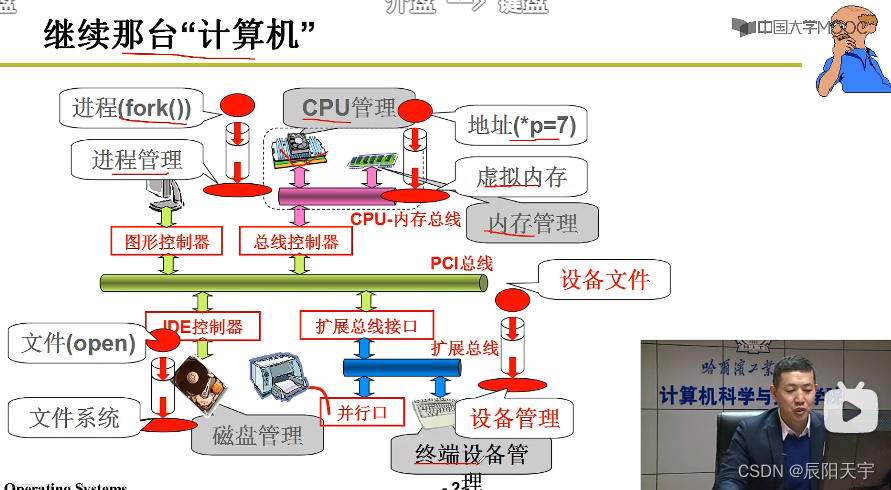
本次所学的I/O设备主要归为两大类:键盘和显示器、磁盘

要想让外设工作,只需要给相应外设中的控制器或存储器发送指令(写入数据)即可,这个外部设备就会根据这个数据操作自己的硬件设备。
当外部设备完成工作后,会向CPU发送中断,表示已经完成工作,处理过程中可能就会进行传输数据等操作。

如果只是上述的方式,那么我们会想能否直接向设备控制器的寄存器写数据不就行了吗?
答:不能。因为需要查在这个过程中,需要查寄存器地址、内容的格式和语义等等,操作系统要给用户提供一个简单统一的视图——文件视图,这样更方便的对设备进行操作。
实际上只需做出三件事:形成文件视图、发出out指令(向控制器发出指令)、做出中断处理。

不论什么设备,操作系统都为用户提供统一的接口,可以让用户无需考虑不同设备的具体要求,而使用统一的入口函数进行驱动。
操作系统通过将设备映射到文件视图,从而便于用户去区分设备,不同的设备对应不同的设备文件名(/dev/xxx)

不同的设备对应不同的设备文件名,系统调用接口函数写入设备属性数据,输入后对其进行解释,然后设备驱动会根据不同的设备文件名对相应的设备控制器输入命令,设备控制器又把它作用在设备上。完成后,返回中断设备工作完成命令,最后又回到文件视图上。

fd文件描述符,用于描述区分不同的设备。实际上便是filp数组的索引,每个文件的信息都对应存储在filp数组中,通过fd找到需要的文件。
进程视图带动整个系统的视图,current->filp[fd]对应获取一个文件file。file->f_inode对应文件内的一个信息,也就是这个设备里的某一个硬件。

除0号进程外,其余进程都是通过fork()所创建,因此所有进程打开文件的指针也都是从父进程那里拷贝来的。而所有进程都是由0号进程创建1号进程,做出shell再往下继续做的,因此我们应该分析shell。
我们可以看到在init()时,打开了一个文件open("dev/tty0", 0_RDWR, 0); ,并且还拷贝了两份dup(0),它们三个的文件描述符分别对应0、1和2。
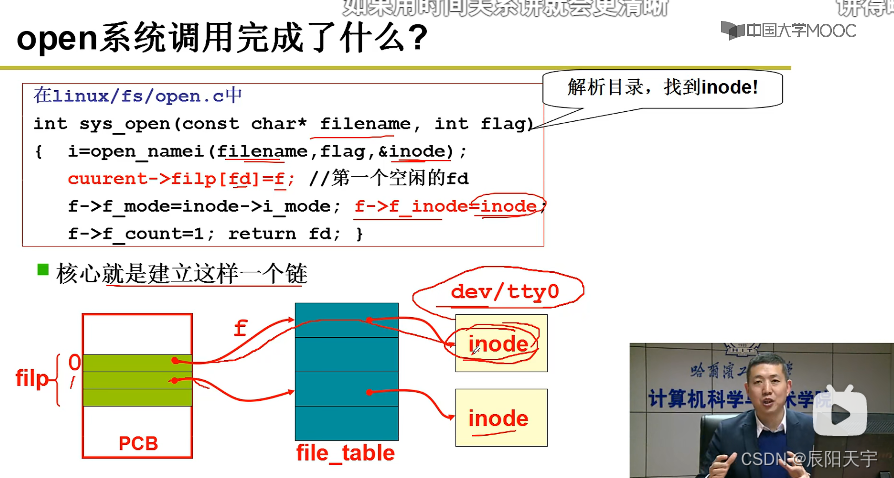
而open里调用了sys_open()。首先是传递文件名filename,然后根据文件的名字,把文件中的indoe读进来open_namei(filename, flag ,&inode)
filename文件名;
flag文件标记;
&inode存放在磁盘上这个文件的信息。
sys_open的核心就是建立了上图中的一个链。current->filp[fd] = f将第一个空闲的fd指向文件表,在表内关联设备文件dev/tty里的数据信息。
在表内的inode继续向下寻找,直到找到关键性的操作显示器的指令。
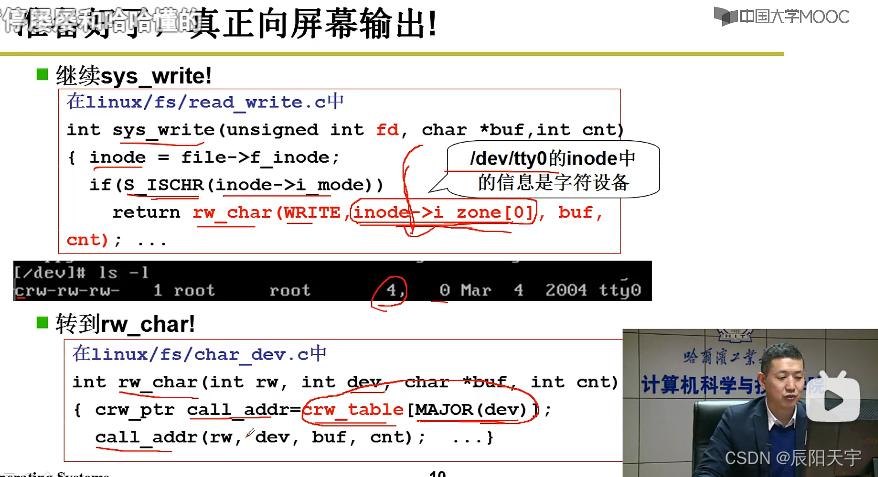
先从文件中读取信息file->f_inode,然后再判定inode是不是字符设备if(S_ISCHR(inode->i_mode)),如果是的话,就继续往下走rw(),输入参数:进行写操作WRITE、选择哪个设备(字符设备中的第几个设备)inode->i_zone[0]
向字符设备输入信息,然后再根据主设备号MAJOR(dev)在rw_char里查表,得到表里存放的函数指针,然后根据这个函数指针,根据第几号设备,就可再找到处理函数,接下来就是对应的处理函数。

那么,我们就来看一看表里是什么。发现crw_table里第四个设备是rw_ttyx。而rw_ttyx里对应的是向显示器上进行写操作。
在tty_write里实现输出。tty会根据tty_table和channel找到对应的一项。在往显示器里写之前,为了弥补CPU计算与显示器写时两种速度的不平衡,所以会将数据先写在缓冲区(队列形式tty->write_q,类似于生产着消费者模型中的共享缓冲区)里,如果队列时满的就会睡眠sleep_if_full()。
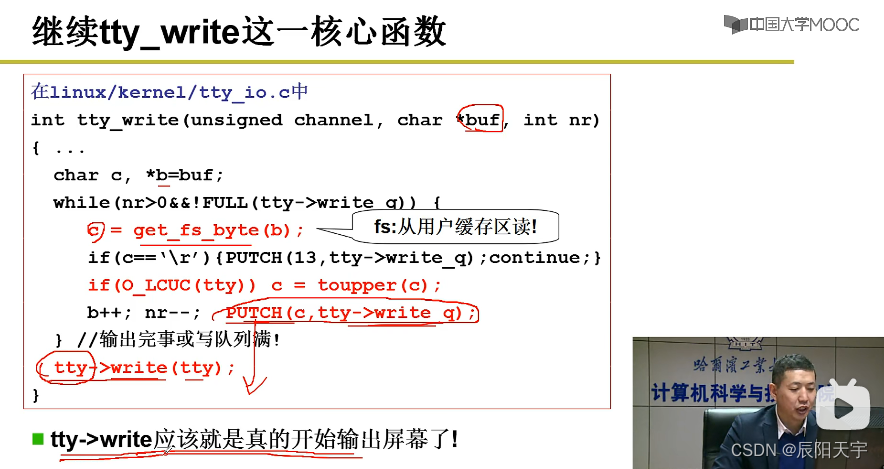
如果缓冲区没有满,就会继续往里放。从用户态内存中取一个字符buf,再将这个字符放到队列中PUTCH(c, tty->write_q)。最后,调用tty-write(tty)实现真正的输出。

在tty_struct中查找到con_write,然后使用con_write往显示器上写。
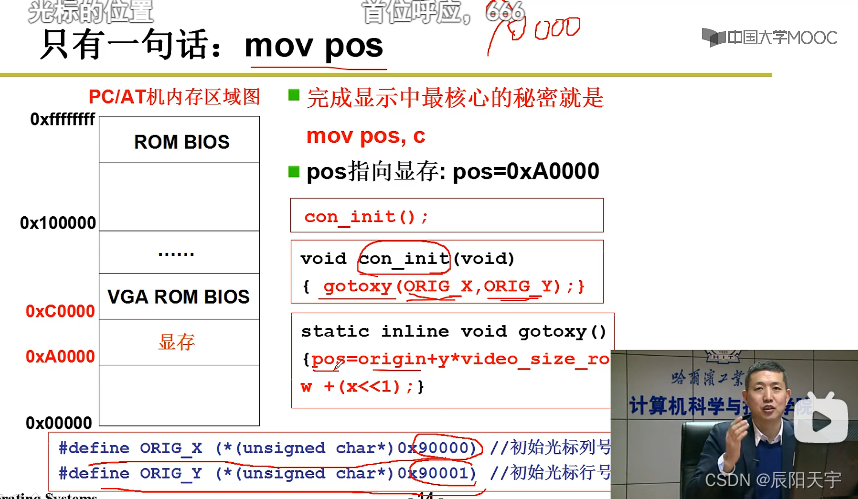
在con_write()中使用GETCH(tty->write_q, c)从队列中取出字符,然后使用内嵌汇编编写将其字符写在显示器上的指令,即写出out指令。
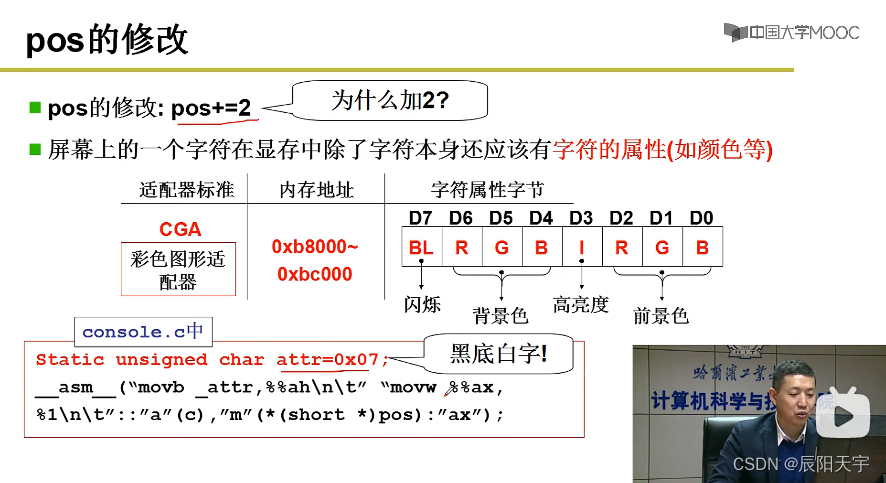
_attr属性赋给ah,然后将字符c赋给ax,因为是字符实际上是放在al当中,现在的ax里低字节是字符,高字节是属性。然后,将ax赋给1也就是pos(显卡寄存器),最后得到的语句便是mov ax, pos,也就是把ax中的值放到显存上。while()每循环一次在显示器上输出一个字符,直至while()结束为止。
注: 有的外设的控制器中的东西,可以和内存统一编址,此时寻址使用mov指令;如果是独立编址,则需要用out指令。因显存特别大,所有通常是和内存统一编制的,所以使用的是mov。
总结
这些代码形成的就是设备驱动,设备驱动无非就是在驱动的时候,写出核心的out指令,再根据你的目标设备中所存放的信息(设备号等等)来注册相应的函数放到表中,创建一个dev/xxx,这个文件要和你注册的表相对应。将来在执行时就会根据这个设备文件名再调用这个函数。
printf的整个过程
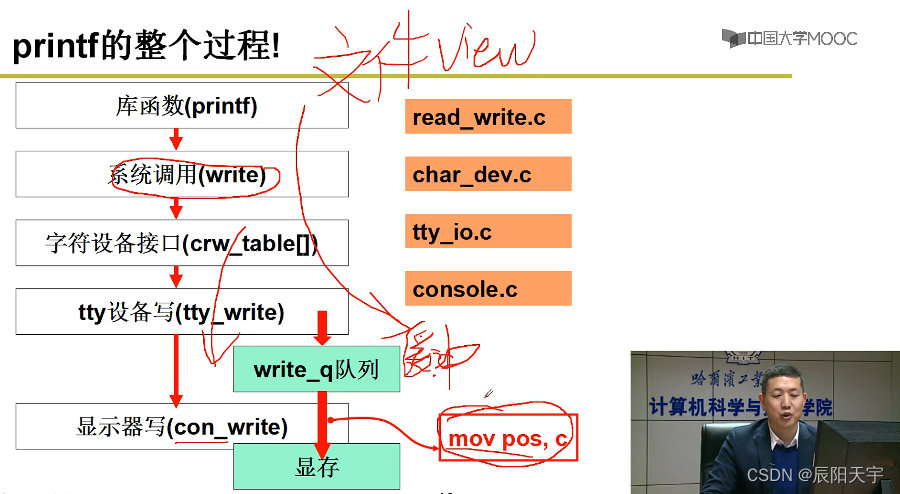
printf的整个过程就是从系统调用write开始,然后移动找这些函数,最后找到了驱动终端设备,再发送命令输入给终端设备中的控制器或寄存器进行操作。
将这些过程包装成一个文件视图。
2、键盘(终端设备输入)
-
有两条主线:
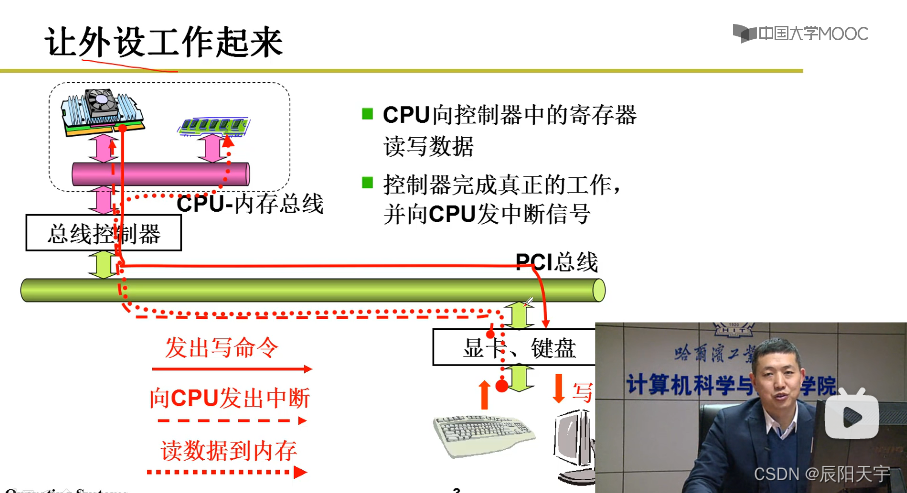
CPU向外设发出out指令;外设向CPU发出中断处理请求 -
操作系统进行外设驱动的三大部分:
(1)将out指令发送给外设的控制器中的寄存区或存储器来控制外设
(2)通过文件将外设形成统一的文件视图
(3)进行中断处理

用户按下键盘时,就会产生中断。将21号中断和keyboard_interrupt所绑定,当一敲键盘产生中断时,就会调用这个中断处理函数。
inb读入一个字节,会将60端口(扫描码,每一个按键都对应一个码)中的数据读入到al当中。call key_table(, %eax, 4)根据不同的码,要调用key_table来执行相应的工作。
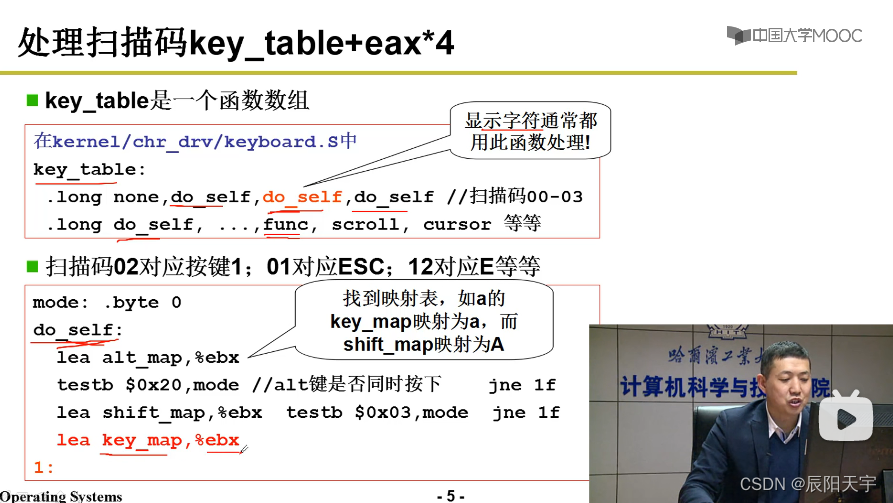
在key_table中,根据不同的码,要做不同的指令,其中do_self为显示字符函数。
do_self会将key_map载入ebx

key_map中是一堆存放在里面的ASCII码。这个表的起始地址已经赋给了ebx再加上扫描码,也是这个表的偏移eax,将其赋给al,便可找到按下的这个键所对应的ASCII码。

接下来便将ASCII码放到了缓冲队列当中call put_queue,等着上面的进程去拿。
得到终端设备的列表和read_q的head,然后将ASCII码输出到这个缓冲队列的头部。
然后,再将其回显到屏幕上。
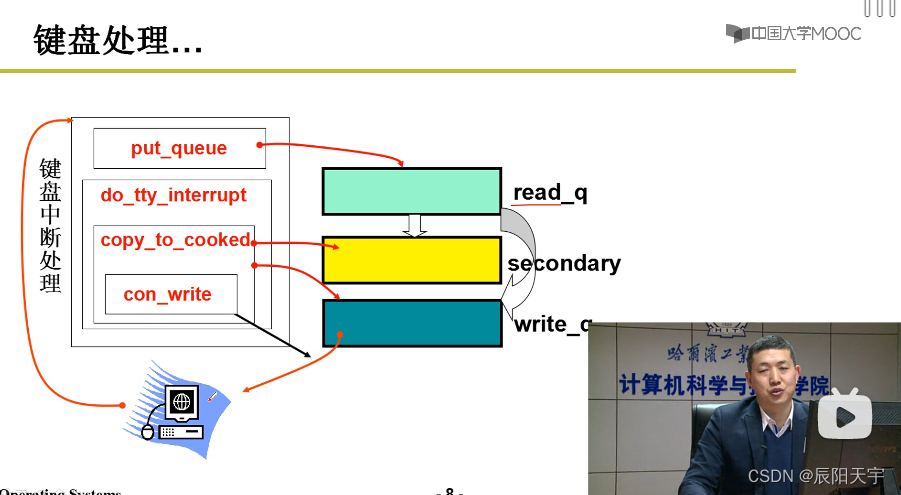
总结一下键盘中断处理的过程:取出ASCII码放到read_q里面,然后再从read_q里面放入secondary(转移等中间处理)队列中,scanf再从secondary队列中取出ASCII码。最后,将这个码再放到write_q队列中,从该队列中取出码回写输出到屏幕上。
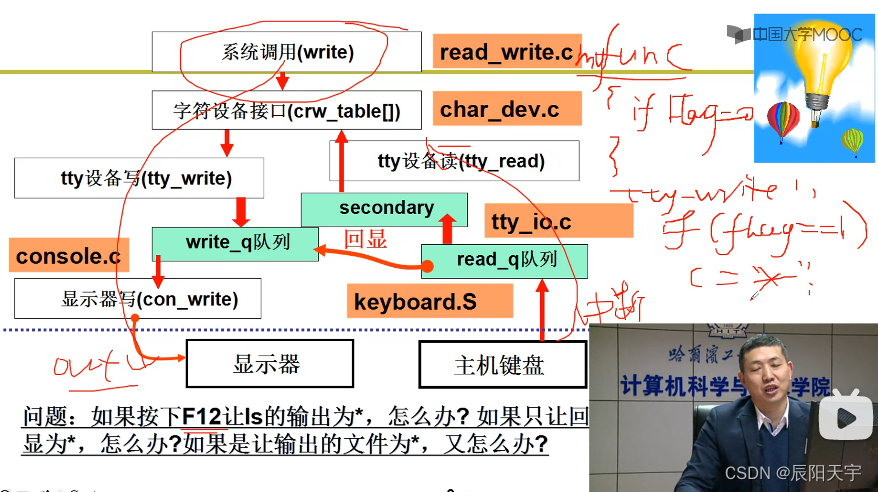
将上一节的printf屏幕输出串联起来就得到了从键盘输入,到屏幕输出的过程。
使用scanf输入,扫描键盘上是否有所输入,如果有则调用中断处理,查找到对应的ASCII码将改码放入read_q队列当中,再经过一些列的处理放入secondary队列当中,此时队列中的元素可以被scanf正确读入。读入后,便会再调用回写指令,把ASCII码再放入write_q队列中,向屏幕发出out指令,让数据可在屏幕上输出。
3、磁盘
(1)生磁盘的使用
(1)读写磁盘的过程
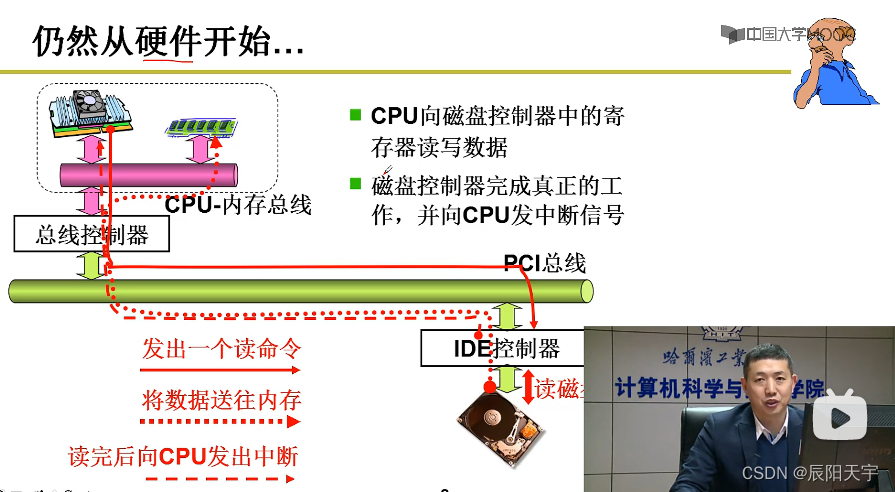
向磁盘控制器发出out指令读写磁盘,磁盘工作完毕后,向CPU发出中断,做一些后续处理。
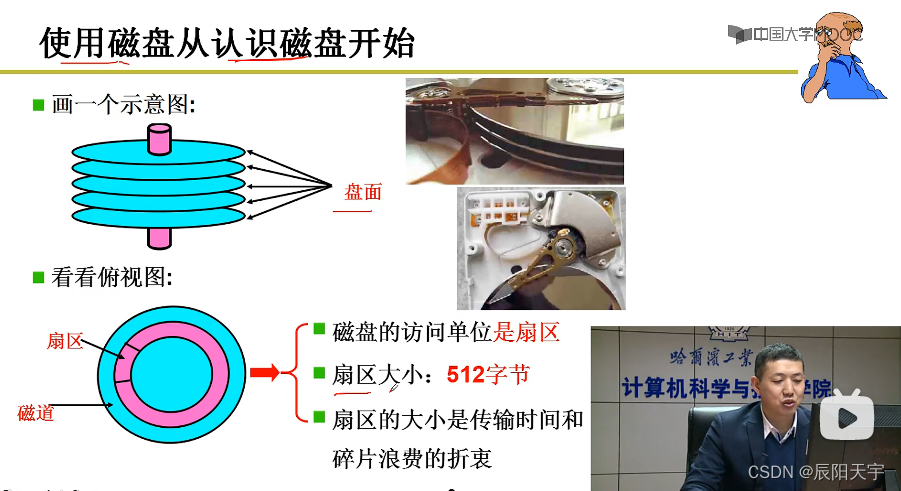
磁盘就是用一根柱子连接一堆盘片,每个盘面上都有一堆磁道。在磁盘旋转过程中,通电的磁头里的磁信号和电信号相互转化,会让扇区上的磁信号变成电信号,从而从磁盘中读出了数据。在读写过程中,读写磁盘的基本单位是扇区,一个扇区是512字节。

移动磁头,旋转磁盘,此时从磁信号变成了电信号,磁头从磁盘上读取数据。将从扇区上读取到的数据存入内存的缓冲区,当我们在内存的缓冲区修改一个字节后,又会将这个数据再写入磁盘中,此时就是将磁头上的电信号变成磁信号改变磁道上的磁性。
基本过程:控制器—》寻道—》旋转—》传输

因此,只要计算机高速磁盘控制器这几个输入参数:柱面C(移动到哪个磁道,一堆盘的磁道就会形成一个柱面)、磁头H(根据磁头决定读写哪个盘面)、扇区S、缓存位置,磁盘控制器就会自动驱动马达完成磁盘的读写。
hd_out()中使用一堆的out指令将柱面、磁头、扇区和缓存位置参数写入给磁盘控制器。
(2)FCFS先来先服务
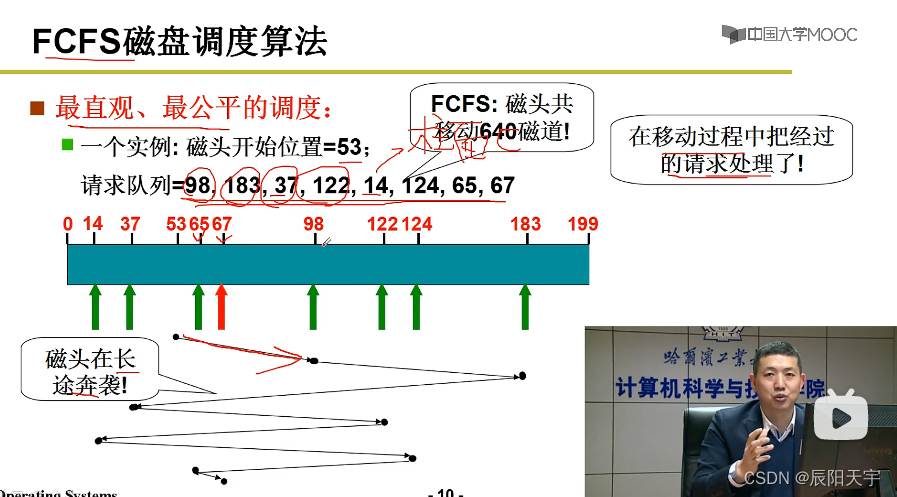
最初磁盘调度算法是最直观的先来先服务FSFC算法。
但磁盘在调度过程中,可能磁头在旋转到98时,之前的65和67也会被使用,既然如此的话,如果在读98之前就把这两个一块读了就可以减少一些移动时间。因此,就需要对磁盘调度进行优化。
(3)SSTF短作业优先
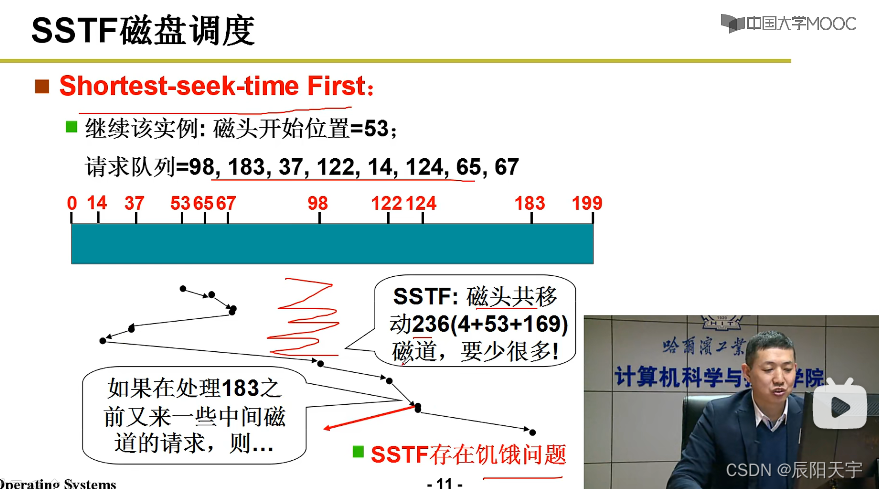
然后,我们就想到了使用SSTF短寻道优先的算法,哪个磁道距离磁头最近就先去哪个磁道读数据。
但是,由于每次都选择距离磁头最近的磁道,那么可能造成频繁在中间来回去读磁道,但距磁头较远距离磁道的请求,磁头可能不会划过去,就会造成饥饿问题。
(4)SCAN扫描调度
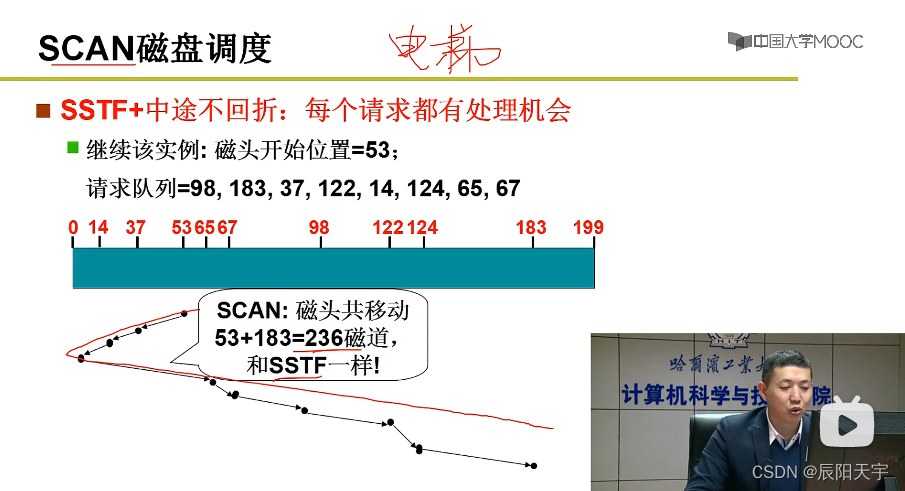
为了让每个请求都可以被相应,我们在SSTF的基础上进行来改进,以SSTF方式调度的同时,让其在中途不回折。每次,扫一圈再扫回来,从而保证每个作业都有机会被读到,这就是SCAN调度算法。
这样子的效率几乎和SSTF一样,但有一个小问题就是每次的的时候,还是中间的要比两边先读完。
(4)C-SCAN循环扫描(电梯调度)
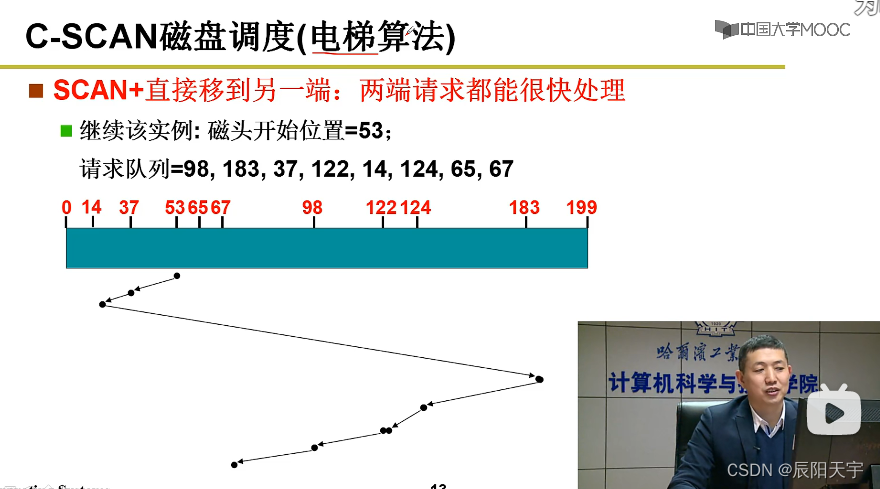
C-SCAN磁盘调度(电梯调度算法)为了让两端请求可以被很快相应,就规定每次折回时都折回到另外一端的端头,然后再从端头往回读。
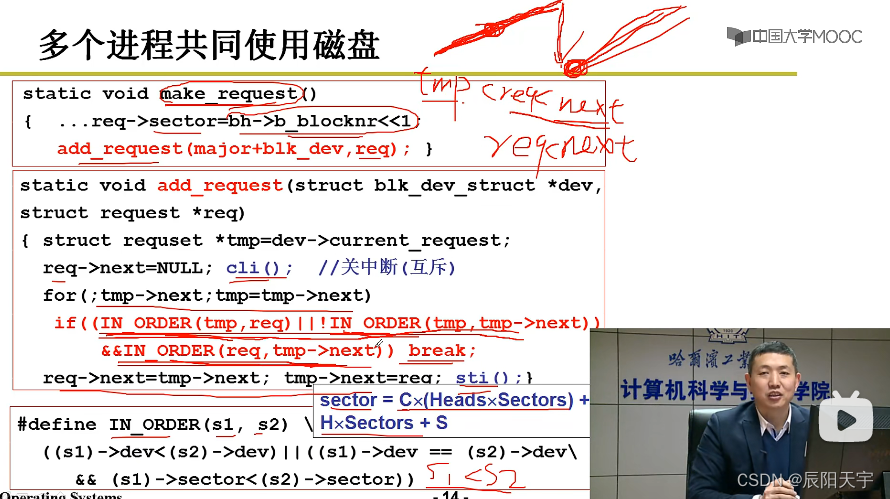
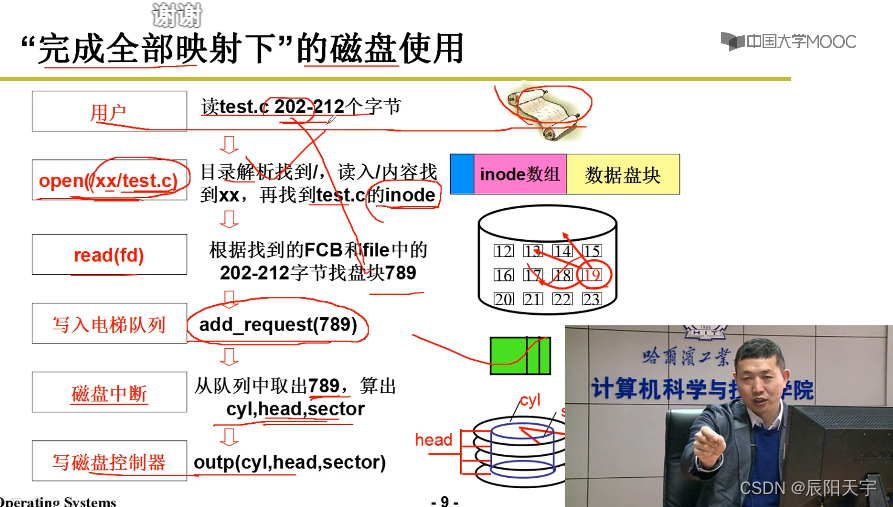
多个进程访问磁盘时,会将产生的请求放到请求队列上,然后再磁盘中断处理时,从请求取出这个盘块号,再转换成柱面C、磁头H、扇区S,再通过out指令发给磁盘控制器。
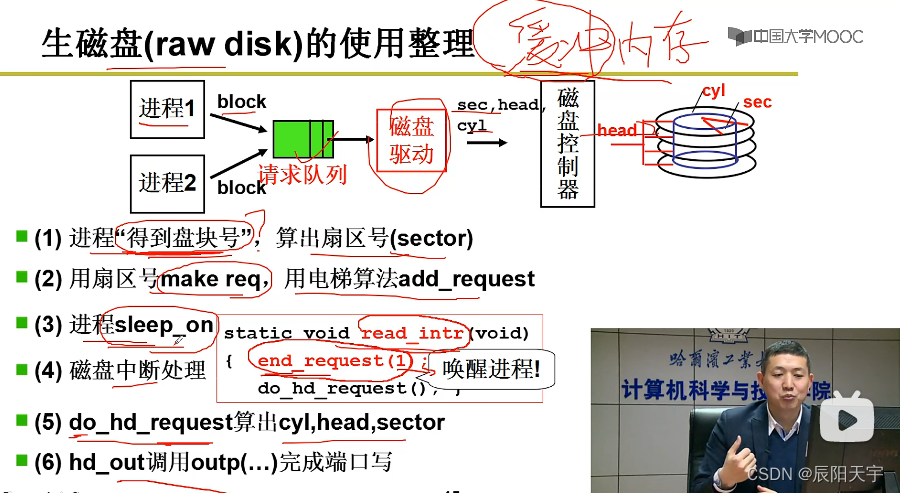
总结
(1)根据文件得到盘块号,然后算出扇区号(sector)。
(2)用扇区号去做出一个磁盘请求make req(其中有内存缓冲区申请和管理代码),然后用电梯算法add_request将其放到缓冲区请求队列中。
(3)放入后,进程就可以睡眠了sleep_on,接下来的工作就交给硬件处理。
(4)磁盘中断就会处理这个请求。
(5)磁盘驱动处理磁盘请求do_hd_request算出cyl, head, sector,并根据out来发出指令。
(6)当工作完成后,又会进行中断处理结束这个请求end_request(1)。处理完后,将进程唤醒,进程可以发现在内存缓冲区内已经有要读写的内容,进程就可以继续的工作了。
(2)从生磁盘到文件

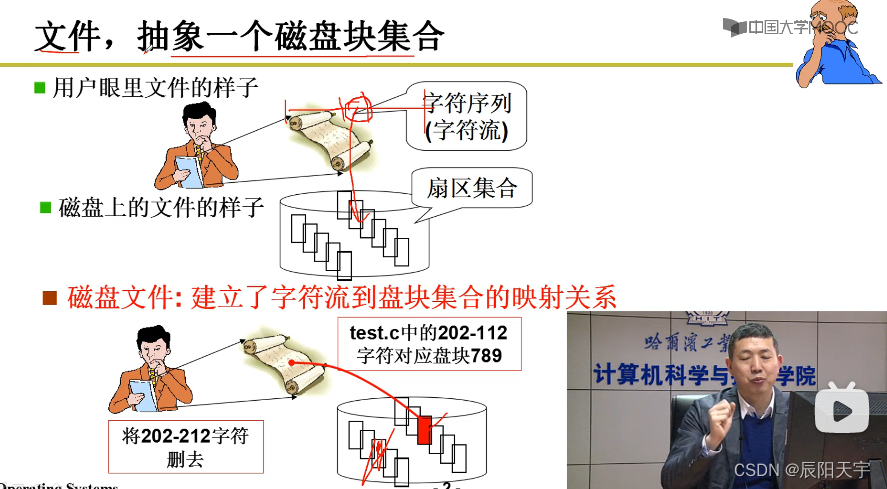
引入文件的目的就是对磁盘使用的第三层抽象,让用户使用起来更加方便。

文件:建立字符流到盘块集合的映射关系。有了这个映射关系后,就可以根据字符流来算出对应的盘块。
(1)顺序存储
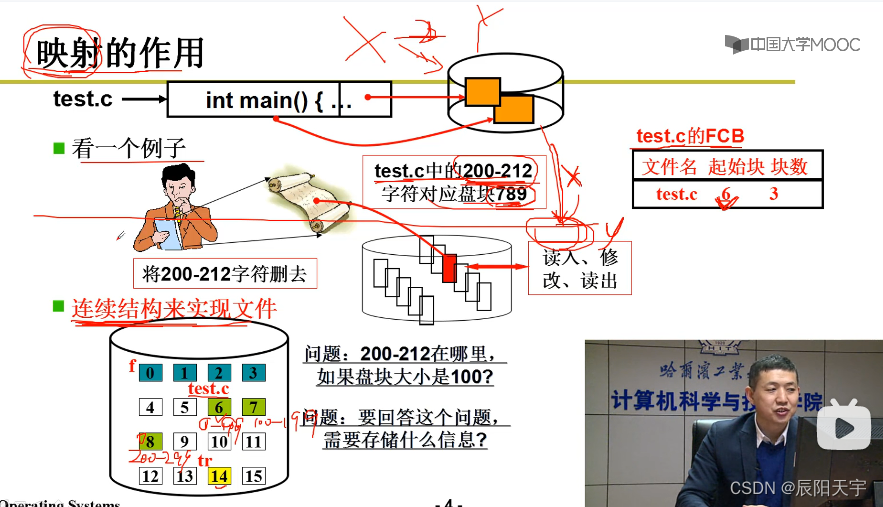
程序通过字符在映射表中寻找到对应的盘块号。图中是以连续的方式存放盘块号。数据存放在文件中会形成右侧的表,会记录起始块号和块数,当再需要读文件时,就会使用字符流,再表中的信息去查找对应的盘块读数据。
这种连续存储方式不太适合于动态变化, 但适合于查找和顺序存取。
(2)链式存储
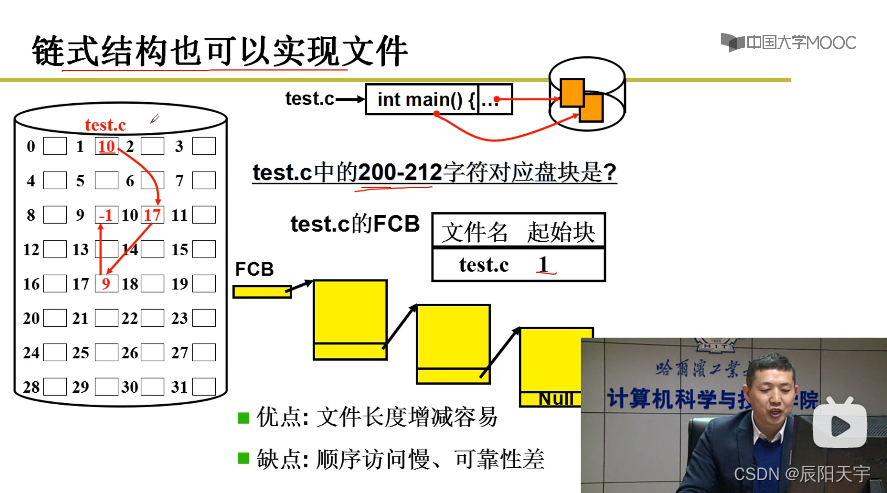
对于要经常改动的文件,采用链式结构更好一些,这是链表在磁盘上的形式。这里在FCB中存放起始块号。访问下一块时根据已存有链接关系查询。
这种方式文件的增减容易,但文件的顺序访问慢、可靠性差。
(3)索引结构
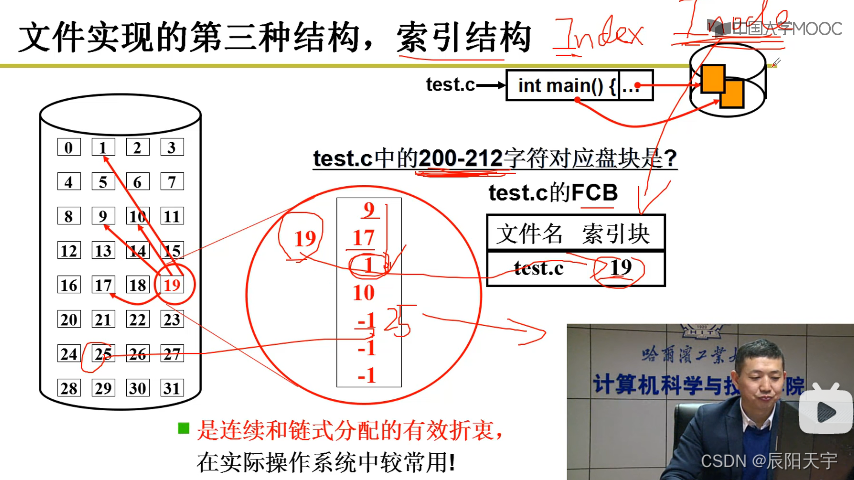
选择一块磁盘用来专门存放盘块号,在这个索引表中按顺序存放字符对应的盘块号。例如,0-99在第9块上,100-199在第17块上。当查找盘块号时,先找到这个索引块inode,将它读进来,然后对照着字符查找对应的盘块号。
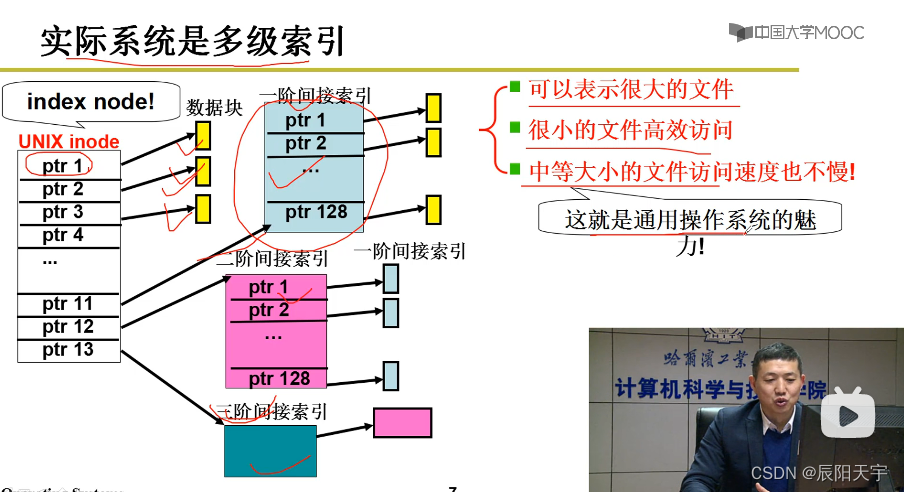
实际系统中用的是多级索引,前几个小文件直接对应到数据块。中等大小的文件使用一层间接索引。对于更大一些的文件,使用两层间接索引。越大的文件层级越多,通常做到三阶就够了(可以表示非常大的文件)。
这种折中的设计方式,可以让很小的文件高效访问,对于很大的文件也可以存储表示,对于中等大小的文件访问速度也不是很慢。

(3)文件使用磁盘的实现
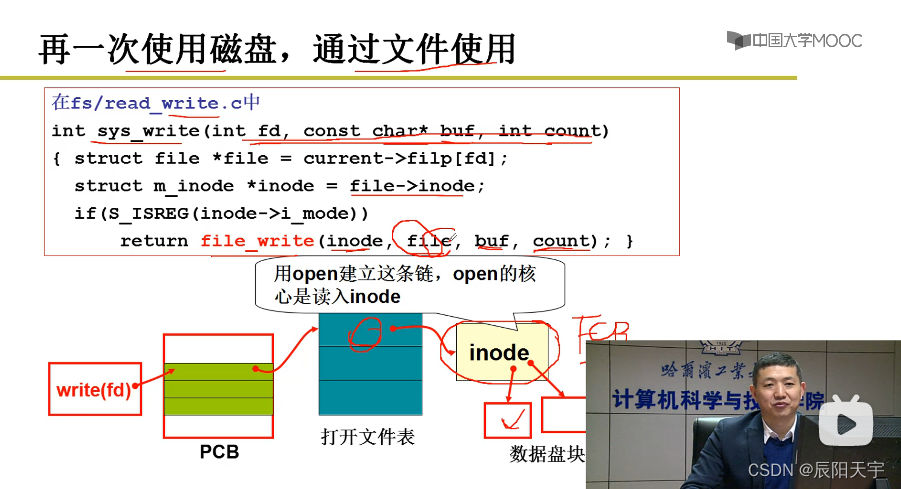
根据用户读写的字符流中的位置来算出是哪一个盘块file->inode,然后读写文件file_write(inode, file, buf, count)将映射表inode,文件file(其中存放字符流中的位置),内存缓冲区buf和读写长度count传入其中。
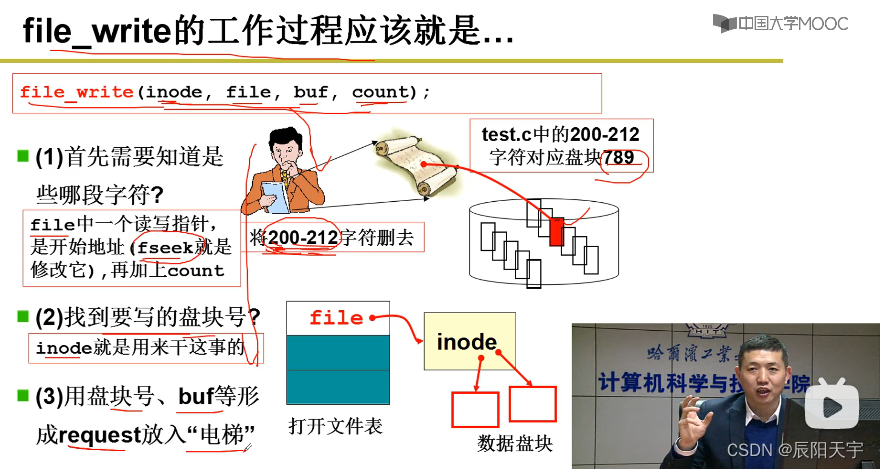

(1)用file知道文件流读写的字符区间,从哪到哪
pos指针存储文件字符流的读写位置。filp->f_pos读写指针指向上一次读写的位置。如果是要在文件后面追加信息使用inode->i_size,使pos读写指针指向文件的末尾。
(2)算出对应的盘块号
然后,根据读写位置和inode找到盘块号create_block(inode, pos/BLOCK_SIZE) = 字符流数值 / 每个盘块的大小 + inode。
(3)放入“电梯”队列当中
有了盘块号后,使用bread(inode->i_dev, block)根据block算出扇区号,再使用buf形成一个内存缓冲区,将其合在一起放在电梯队列中再阻塞自己。等到磁盘中断处理时,再从电梯队列中将其取出来,进行后续处理。
(4)修改读写位置pos
完成上述操作后,需要增加pos的位置pos+=c。
(5)一块一块拷贝用户字符,并且释放写出

算盘块时,首先判断位于几重间接索引表中。再根据对应区域进行查询。
(1)如果是小于7,直接获取一个数据块放进去。
(2)如果不是小于7的话,再判断是在一重间接还是二重间接。
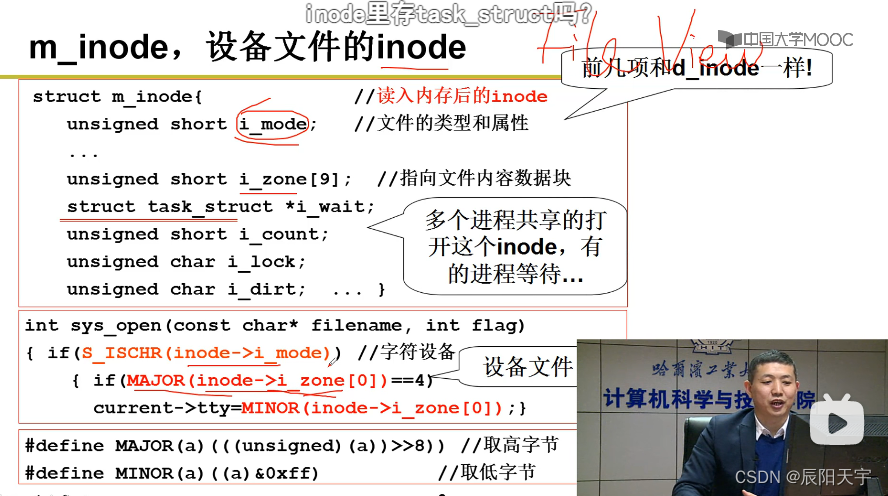
对于非设备文件,数据文件等,使用inode里存放的映射表,就可以找到字符留位置到文件的读写位置,inode充当映射的角色。
对于设备文件不用inode完成映射关系,使用inode来存放一些信息,例如主设备号、次设备号等。
所以,通过inode就可以形成文件视图。

打开文件就是从文件名到inode的映射。


4、目录与文件系统
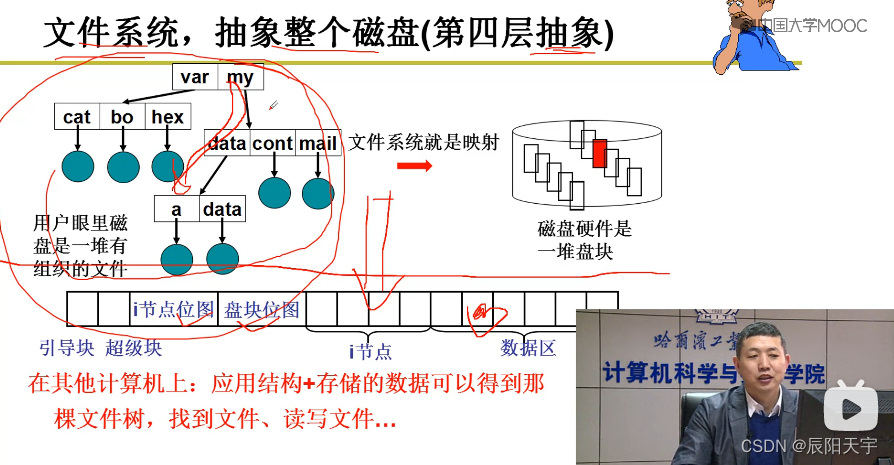

最开始是把一堆文件放在一个大集合中,但当文件的数据多的时候,全都放在一层上就会很乱,不方便用户使用。
后来改进了一下,为每个用户独立的划分集合进行存放。但当每个用户的文件多了起来后,又会变成之前的问题了。
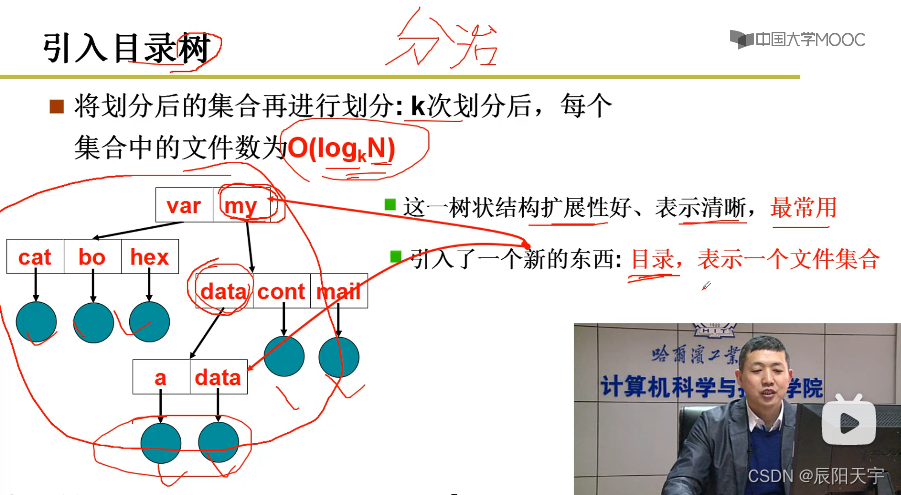
因此为了解决上述文件集合划分问题,就引入了目录树结构,目录树是典型的分治结构。将集合再往下划分。对N个文件经过k次划分后,每个文件数便为
O
(
l
o
g
k
N
)
O(log_kN)
O(logkN)(设文件数为m,则
m
k
=
N
m^k=N
mk=N)。
使用目录来表示一个文件集合。因此,实现目录就成为了关键问题。

目标是根据目录树产生的路径名/my/data/a来找到文件a的FCB,也就是inode。再根据inode和读写位置pos,找到对应的盘块,再使用盘块号算出扇区号二者放到内存缓冲区的电梯队列上后,当产生磁盘中断时,就可以将盘块读出来算出CHS(柱面、磁头、扇区),将指令发给磁盘控制器,从而驱动马达完成磁盘读写。
现在就需要解决,磁盘上应该存放什么信息来实现目录。想法就是将FCB的指针使用编号来标记,在磁盘中存放FCB的编号,每次查询时通过查询编号来找到对应的FCB。
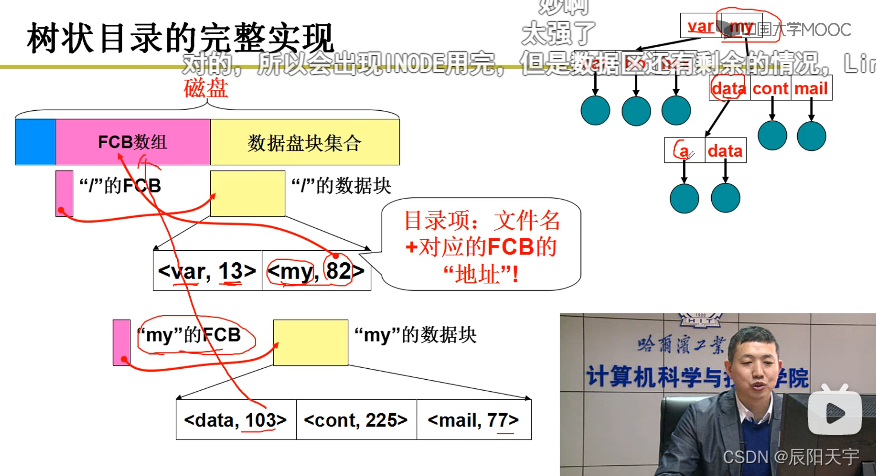
此时分为FCB数组和数据盘块集合。FCB数组中存放对应目录的FCB的指针,数据盘块集合存放下属目录的文件名和对应在FCB中的位置(目录项=文件名+对应的FCB的地址)。
首先从根目录上访问(根目录固定在FCB数组中的0位置)。当访问到一层目录时,会在数据盘块上获取下属文件名和编号集合,再根据路径访问一下个对应的文件,通过这个编号在FCB数据中查找到对应的FCB的位置。逐层向下寻找,最终可以找到目标文件。
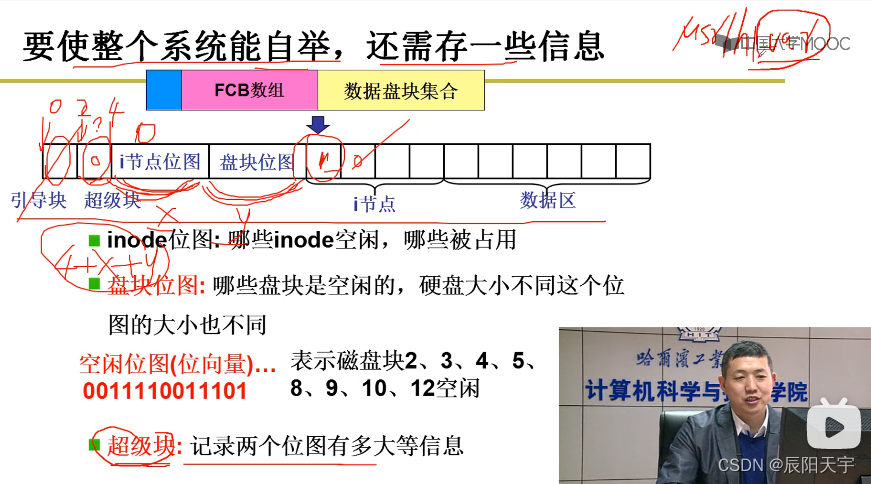
根目录放在inode数组中的第一项,而在此位置之前需要存放盘块位图(记录空闲块和正在使用块)、inode位图(记录正在使用文件和可新建文件的i节点)、超级块(存放盘块位图和inode位图的大小)和引导块(引导扇区)。一旦知道前方这几块的位置后,就可以将根目录存放进后续inode中。
一旦一个磁盘被格式化上述结构后,不论磁盘插到哪里,一旦从超级块中读出信息解析内容后,就可以找到根目录,并且还可以读写文件,修改维护这个数据结构。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)