利用 Linux grep 和 awk 完成日志过滤
利用 Linux grep 和 awk 完成日志过滤
·
导语:有时候系统的日志信息的量是很庞大的,这时要查看具体问题可能比较麻烦。此时可以过滤掉无用的日志信息,从而获取预期想获取的信息。或者在排查问题时,查看具体的某一个错误。
Linux grep 命令用于查找文件里符合条件的字符串
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
场景:系统报警显示了时间,但是日志文件太大无法直接 cat 查看。(查询含有特定文本的文件,并拿到这些文本所在的行)

grep 的与或操作:
grep 与操作(其实就是多次筛选)
grep k1 | grep k2
grep 或操作
grep -E 'k1|k2'
egrep 'k1|k2'
awk '/k1|k2/'
awk 是一种处理文本文件的语言,是一个强大的文本分析工具。

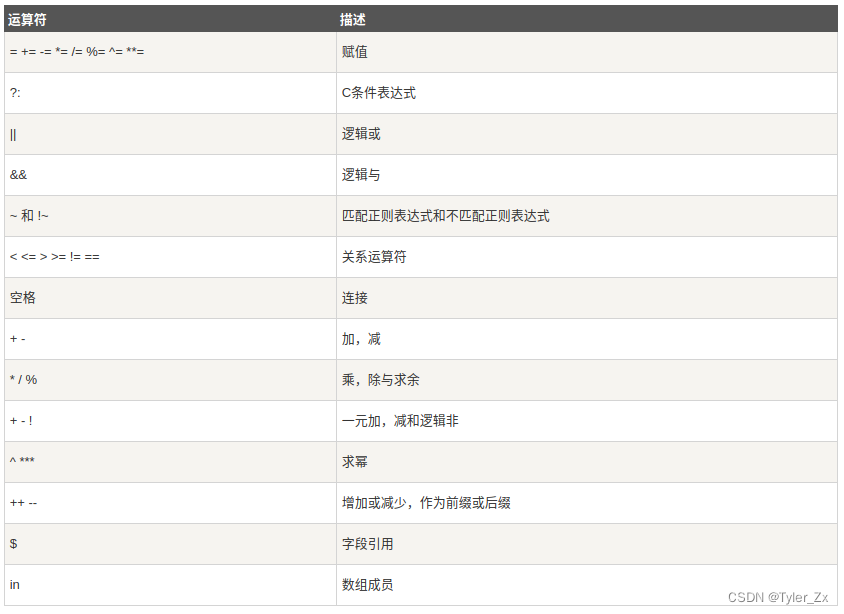
以 test.log 的内容为例:
2022-06-1 NameError
2022-06-2 NameError
2022-06-3 NameError
2022-06-4 NameError
123
456
abc
def
2022-06-5 NameError
2022-06-6 NameError
2022-06-7 NameError
读取日志中时间大于 2022-06-4 && 出现 NameError 关键字的信息,$0 表示整行文本,$1 表示输出第一列。
#!/bin/bash
while read line;
do
echo $line | grep 'NameError' \\
| awk -F ' ' '{if($1 > "2022-06-4") print $0}' ;
done < test.log
此时,可以用 awk 输出到另一个文件中,结果放到 result.log :
#!/bin/bash
while read line;
do
echo $line | grep 'NameError' \\
| awk -F ' ' '{if($1 > "2022-06-4") print $0}' >> result.log
done < test.log
或者用更为简单方法:
#!/bin/bash
# awk '{if($0~"filter-string") print}' xxx.log
# 解释说明:抽取 xxx.log 整个日志文件中,包含 "filter-string" 的行,打印输出
awk '{if($0~"NameError" && $1 > "2022-06-4") print}' test.log >> result.log
# 要附加条件,只需要在 if 里面添加内容即可,例如:
# 将 $0~"NameError" -> ($0~"NameError" || $0~"Error")
参考内容:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)