一个C程序的编译经过了几个步骤
深入了解一个程序的诞生(一个源文件是如何变成我们的可执行程序exe的)
目录
二、 进行完预处理后即是进行编译:该编译是将预处理后的源文件转换生成汇编代码
#include<...>和#include"..."的区别
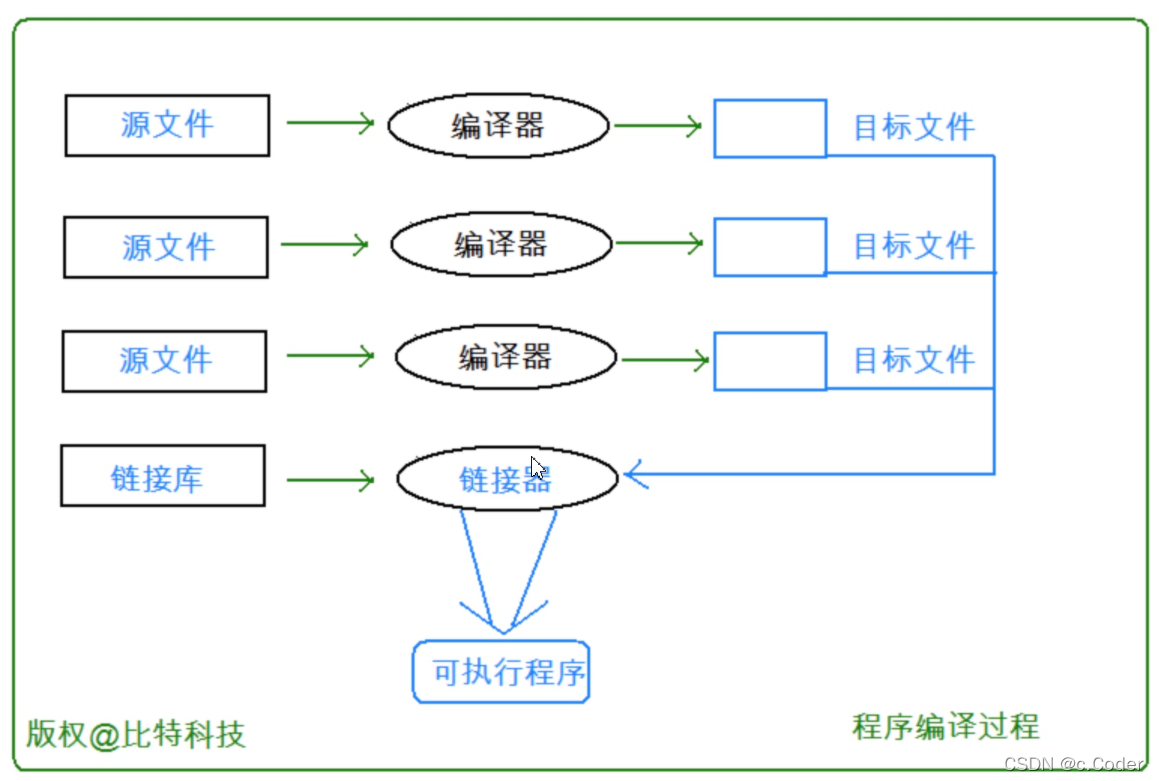
一个C语言程序从源代码到可执行程序一共经过了两个大步骤:编译和链接
编译又细分为三个小步骤:预处理(预编译)->编译->汇编
本文则主要介绍了编译和链接中的编译步骤(链接作了简单说明)
ps:以下实例演示均在Linux环境Centos7下进行
预处理
进行头文件的展开、去除注释、进行宏替换以及条件编译等
详情见实例

我们首先写了一段简单的代码如上,然后在Linux下,分布编译该源文件
具体指令不作详解,仅做一个简单说明
一、将cpp文件进行编译的第一步:预处理
g++ -E text.cpp -o text.i
(-E选项即说明让编译器只进行预处理步骤,-o选项即说明让处理完毕的文件重定向至text.i)
我们来看输出的text.i中的情况
我们可以看到,进行预处理完毕后,编译器将代码中的NUM替换成了20,并将define去除。
(因为进行替换之后该行代码已经没有其它作用了)
还可以看到,text.i中的代码量骤增成了一万多行,这里是因为其将我们包含的头文件iostream给展开了(因为我们要用到c++标准库中的cout类与endl类)
二、 进行完预处理后即是进行编译:该编译是将预处理后的源文件转换生成汇编代码
g++ -S text.i -o text.o
(-S选项即说明将预处理完后的文件text.i只进行编译,-o选项即将输出的内容重定向到text.s文件中。ps:这里也可以直接对text.cpp进行-S选项的编译,只是会重复进行一遍预处理,即不会生成中间文件text.i)
我们来看进行编译处理后的文件情况:
我们可以看到,进行编译后的代码大家如果没学过汇编的话应该都是看的一头雾水,但还是可以看出一些指令的,如mov指令,call指令,push/pop指令等。这里经过编译后生成的即为汇编代码了
三、对编译完成后生成的汇编代码进行最后一个步骤:汇编
汇编即是将编译生成的汇编代码转换成机器可识别的代码(二进制文件),生成二进制文件,即目标文件(vs中即是后缀为.obj的文件)
g++ -c text.o -o text.o
(-c选项即说明对编译生成的汇编文件进行汇编指令,生成可执行程序,-o仍是将输出的内容重定向至text.o)
我们来看一下生成的二进制文件(.obj文件)里面是什么内容
我们可以看到text.o文件里面的内容对于我们来说基本就是一堆乱码了,但其实这才是机器可以识别的二进制文件(也就是.obj文件)
至此,我们编译和链接两大步骤中的编译就已经结束了,接下来就是进行链接了
(这里是源文件到可执行程序的大体步骤图,也就是编译链接)
如何链接呢?
在Linux下对目标文件(.o文件)执行下述指令
g++ text.o -o mybin
(直接不带任何选项,即对目标文件执行链接操作,-o只是将其生成的可执行程序重定向(命名)成mybin,默认生成的可执行程序为a.out,我们可以看到可执行程序在Linux中是会标绿的)
./mybin运行即可(前面./是相对路径,即在当前目录下)

至此,一个程序的诞生过程就讲完了,从源代码到我们的可执行程序大体就分为以上这么几个步骤
我们现在对编译过程中的预处理再更深入了解一些
(部分比较抽象的一些指令才再Linux下进行了实例演示)
#define相关
预定义符号:C中内置的一些已有值的符号
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
#define 定义的宏(与预定义符号有一定类似)
定义标识符常量:#define定义的常量
#define定义宏:将参数替换到文本当中
注意宏是仅做一个简单的文本替换,不会进行计算
#define的替换规则
1.首先替换任何由define定义的符号(标识符常量)
2.其次替换define定义的宏
3.最后对结果进行扫描,重复上述操作
tips:字符串常量中的内容不会被搜索替换
“#” 和 “##”
实际过程很少有使用到,了解即可
“#” 修饰了define定义的常量后,该常量在预处理时会被转换成字符串,而不是正常替换
左边为源文件,右边为预处理后的文件,对比很容易理解“#”在其中的作用

运行结果如下
(这里直接进行编译生成的即为a.out可执行程序)

“##” 可以把位于它两边的符号合成一个符号。它允许宏定义从分离的文本片段创建标识符
合成为一个符号后然后再进行替换(连接后产生的标识符必须是一个合法的标识符,否则其结果是未定义的。Linux下会报错)
我们可以看到sum和num在##的作用下结合成了sum5

带副作用的宏参数
副作用:即在达成某些目的的同时对一些变量等产生了实质性影响
参数如果带有副作用,使用宏时可能会导致与原逻辑不符,产生不可预测的结果
我们来看下面的代码,会输出什么呢?
#define MAX(a, b) ( (a) > (b) ? (a) : (b) )
int x = 5;
int y = 8;
int z = MAX(x++, y++);
printf("x=%d y=%d z=%d\n", x, y, z);首先将宏进行替换,替换后如下
int z = ( (x++) > (y++) ? (x++) : (y++));所以输出的结果依次计算判断得:x=6 y=10 z=9
这里x,y,z都因为参数带有副作用而影响了最初的变量值
#undef + 宏名称可以用于移除一个宏定义
命令行定义(编译时定义宏)
(一般用处不大)
#include <stdio.h>
int main()
{
int array [ARRAY_SIZE];
int i = 0;
for(i = 0; i< ARRAY_SIZE; i ++)
{
array[i] = i;
}
for(i = 0; i< ARRAY_SIZE; i ++)
{
printf("%d " ,array[i]);
}
printf("\n" );
return 0;
}在编译时,如下编译,即在编译时定义program.c中的ARRAY_SIZE值为10
gcc -D ARRAY_SIZE=10 programe.c条件编译
1、单个分支的条件编译
#if 常量表达式(常量表达式由预处理器求值。)
#endif
例子:
#define __DEBUG__ 1
#if __DEBUG__//常量表达式(为真则执行下面的内容,反之不执行)
//..
#endif
2、多个分支的条件编译
#if 常量表达式
#elif 常量表达式
#else
#endif
3.判断是否被定义
#if defined(symbol)//如果symbol定义了,则执行下面的代码
...
#ifdef symbol
#if !defined(symbol)//如果symbol没被定义,则不执行下面的代码
#ifndef symbol
4.嵌套指令(即上述的条件编译语句都支持嵌套)
例子:
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif
头文件包含的一些细节
#include<...>和#include"..."的区别
系统对于两种包含方式的查找策略的不同
1、"..."为本地文件包含
查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标
准位置查找头文件。如果找不到就提示编译错误。2、<...>库文件包含
查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
tips:这样是不是可以说,对于库文件也可以使用 “” 的形式包含?答案是肯定的,可以。(但是不推荐啦)
防止头文件被重复包含的方式
1、用条件编译
#ifndef __TEST_H__//如果没定义(如果定义了则下面的不执行)
#define __TEST_H__//则定义
//头文件的内容
#endif //__TEST_H__2、#pragma once
后话
到这里,这篇文章也就结束啦,如果本文内容对你有所帮助,还请点个赞(转发或者评论)让更多人看到呀~Thanks♪(・ω・)ノ
这篇博客应该也是关于C语言这块儿的最后一篇啦,接下来就是有关数据结构的知识干货输出~感兴趣的小伙伴可以点个关注哩!~

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)