linux下读写emmc,nand,硬盘下的文件(一)
一、在linux环境下常用文件接口函数:open、close、write、read、lseek。二、文件操作的基本步骤分为:a、在linux系统中要操作一个文件,一般是先open打开一个文件,得到一个文件扫描描述符,然后对文件进行读写操作(或其他操作),最后关闭文件即可。b、对文件进行操作时,一定要先打开文件,然后再进行对文件操作(打开文件不成功的话,就操作不了),最后操作文件完毕后,一定要关闭文
部分摘抄自:https://blog.csdn.net/weixin_35032509/article/details/112311755
感谢作者的精彩分析,
一、文件系统框架:
Linux系统文件操作主要是通过块设备驱动来实现的。 块设备主要指的是用来存储数据的设备,类似于SD卡、U盘、Nor Flash、Nand Flash、机械硬盘和固态硬盘等。块设备驱动就是用来访问这些存储设备的,其与字符设备驱动不同的是:
块设备只能以块为基本单位实现读写,块是 linux 虚拟文件系统(VFS)基本的数据传输单位。字符设备是以字节为单位进行数据传输的,不需要缓冲。
块设备在结构上是可以进行随机访问的,对于这些设备的读写都是按块进行的,块设备使用缓冲区来暂时存放数据,等到条件成熟以后在一次性将缓冲区中的数据写入块设备中;字符设备是按照字节进行读写访问的。不需要缓冲区,对于字符设备的访问都是实时的,而且也不需要按照固定的块大小进行访问。
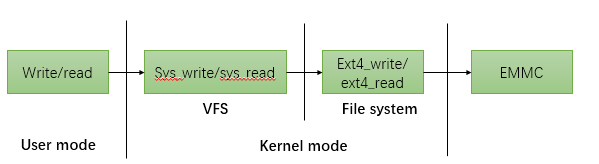
从上图中可以看出linux文件系统的读写通过调用虚拟文件系统(VFS)的对应接口,从而调用到实际文件系统的读写接口,来进行emmc的操作,这样可以实现多文件系统兼容,ext4的格式,f2fs的文件系统格式,但VFS层的调用接口是不变的
既然硬盘可以有这么多种分区格式,假如我要将数据从A分区复制到B分区,Linux是如何将数据在两种不同格式的分区之间快速转换的呢?Linux又是如何为操作系统的使用者屏蔽掉分区的细节,从而让使用者无需关注分区信息的呢?这就是Linux的虚拟文件系统的作用。
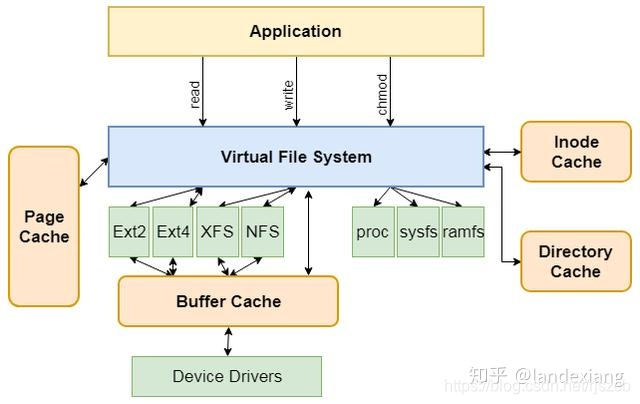
VFS架构图
从VFS的架构图可以看到,其作为一个黑盒,向Application(应用)提供了统一的文件操作接口,比如读取数据的read接口、写入数据的write接口、修改权限信息的chmod接口等。而VFS本身不仅兼容了个各种硬盘分区格式,还兼容了proc、sysf、ramfs等内存文件系统。总而言之,对于Linux的使用者来说,可以将整个Linux看做只有一块大的物理存储介质,而这个存储介质只有一个分区,分区格式为VFS
二、Linux硬盘分区
同Windows一样,Linux中同样支持MBR格式的硬盘分区。硬盘在Windows中作为一个设备接口,Windows通过磁盘驱动器与其进行交互,在Linux中同样如此。不过由于Linux中一切接文件,所以这个设备接口是以文件的形式存在的。
无论是实体设备比如硬盘还是虚拟设备如云打印机,其设备接口文件都存在与/dev目录下,实体设备接口文件的通常名字为sd[a-z],虚拟设备接口文件的通常名字为vd[a-z]。
以实体设备硬盘为例:
形如sda1、sda2、sda3…sdan的文件,就是硬盘sda的分区了,类似于Windows系统中的D、E盘的概念。
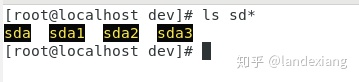
可以通过下面命令查看Linux中的硬盘设备和硬盘分区情况:
1、fdisk -l
 从显示信息可以看出当前Linux操作系统只有一块总容量32.2GB的硬盘,一共包含62914560个扇区,每个扇区为512B,且该硬盘有三个主分区sda1、sda2和sda3。
从显示信息可以看出当前Linux操作系统只有一块总容量32.2GB的硬盘,一共包含62914560个扇区,每个扇区为512B,且该硬盘有三个主分区sda1、sda2和sda3。
对比一下Windows系统下的分区,除了有设备驱动文件之外,每个分区还关联了一个叫做盘符的东西,如下面的D、E、F

当在Windows中访问C://开头的资源时,操作系统有根据盘符就能够知道目标资源实际位于哪个分区。
同样的Linux中也有类似于盘符的东西,通常被叫做挂载点。使用下面命令可以看到Linux中的所有挂载点:
2、df -lh
 就像结果所显示的那样,Linux是直接将路径和分区进行关联的,比如/boot目录下的所有数据都存放在硬盘sda的1号分区中。
就像结果所显示的那样,Linux是直接将路径和分区进行关联的,比如/boot目录下的所有数据都存放在硬盘sda的1号分区中。
Linux中可以通过下面命令查看硬盘分区的格式:
3、df -T

红框圈出来的Type列就是分区对应的格式,如硬盘sda的1、3号分区的格式都是xfs,Linux中常见的格式有xfs、ext2、ext3、ext4等。
至于Linux的分区实战,直接看下面实战就好
linux硬盘分区blog.csdn.net
如果将Linux硬盘分区的步骤对比到Windows硬盘分区如下:
新加卷大小 -> 分配扇区数量
选择分区格式 -> 格式化分区
生成盘符 -> 将分区挂载到某个目录
三、常见Linux硬盘分区格式——ext2硬盘布局
Linux中常见的硬盘分区格式有xfs、ext2、ext3、ext4等。如果将硬盘本身被抽象为一个数据仓库,则硬盘分区可以看做仓库中的一个个库房,而有的库房用来存储大件物品,数量较少只需要顺序摆放,而有的库房用来存储小件物品,数量较多,需要使用货架并且要更细致的编号。硬盘的分区的格式,就可以比作库房是如何记录和摆放货物的方案。
以ext2格式为例,了解一下硬盘分区格式的基本概念:

ext2分区格式结构图
block
上面已经介绍了硬盘的物理存储单元为扇区,而分区的存储单元是由1个或者多个扇区组成的逻辑存储单元,通常被称为block(块)。block的大小可以在分区格式化的时候由操作者指定,通常为1024B或者4096B,转换成扇区通常就是2个扇区或者8个扇区大小。虽然同是ext2格式的不同分区,block的大小可能不同,但是同一个分区内的所有block的大小一定是相同的。
boot block
boot block(引导块)是位于分区最开始的一个block,可以用来存储类似于硬盘唯一的MBR表中boot loader,即通常被用于在同一个计算机中安装多个操作系统。
block group
block group(块组)是ext2分区格式中用于组织和管理block的逻辑划分。每个block group由super block(超级块)、GDT(group descriptor table 组描述符表)、block bitmap(块位图)、inode bitmap(索引节点位图)、inode table(索引节点表)、data blocks(数据块区)组成。之所以划分block group,可以理解为库房太大,将库房划分成了几个类似的区域分别管理。
super block
super block(超级块)是位于每个block group的最开始的一个block,其用于描述当前block group所在分区的元数据信息,比如每个block的大小、block的总数量、空闲可用的block数量等。

super block部分内容
GDT(group descriptor table)
GDT位于super block之后,通常占据连续的n(>= 1)个block。GDT中主要保存了当前block group的元数据,主要当前block group中其他部分的指针以及block数量相关信息:

GDT部分内容
block bitmap
block bitmap(块位图),其本身占据一个block的大小,记录当前block group的data blocks区域中哪些块是已经被使用的,哪些块是未被使用的。block bitmap将data blocks区域中所有块以线性地址组织起来啊,每一个块用一位来记录信息,比如块位图有1024B,则一共有1024 * 8 = 8192bit,则其最多能记录8192个block的使用情况。假如当前block bitmap状态为10…(8190个0),则说明data blocks区域中,只有第一个block被使用了,其他的都是空闲状态。
inode bitmap
inode bitmap(索引节点位图),本身占据一个block大小,功能类似于block bitmap。inode bitmap用于记录inode table区域中哪些inode是已经被使用的,记录方法和block bitmap相同。
inode Table
inode Table(索引节点表)中包含了需要indoe,每个inode记录了文件的元数据,比如文件类型,权限,文件大小等(没有文件名),即通过
ls -l
命令可以查看的内容都是记录在inode上的。系统中的每一个文件都可以找到一个inode与与之对应,一个inode本身大小通常是128B或者256B。inode中还存储了与其相关的block的指针,以便于通过inode可以快速取出当前inode对应的文件的所有存储在block中的数据。
data blocks
data blocks(数据库区域)就是一组逻辑上连续的block的数组,主要用来存储文件的数据部分。在进行文件存储时,一个block只能被一个文件持有,即只能被一个inode所关联。即使block默认为1KB,但是文件只有1B大小,该文件依然会独占当前block空间,另外999B会浪费掉。
拓展
在简单了解了ext2格式的硬盘布局之后,我们至少可以知道,在硬盘分区设置inode数量时,要结合实际的场景来进行设定。假如当前分区更多的用来存储小文件,则最好将block设置的小一点,inode的数量设置的多一点,以免发生inode数量不足或者大量浪费硬盘空间的情况。假如当前分区更多的用来存储大文件,则可以将block设置的大一些,inode的数量此时可以相应的少一些。
④挂载磁盘:mount /dev/dx_ramdisk /dx_tmp1
三、在linux环境下常用文件接口函数:open、close、write、read、lseek。
1、文件操作的基本步骤分为:
a、在linux系统中要操作一个文件,一般是先open打开一个文件,得到一个文件扫描描述符,然后对文件进行读写操作(或其他操作),最后关闭文件即可。
b、对文件进行操作时,一定要先打开文件,然后再进行对文件操作(打开文件不成功的话,就操作不了),最后操作文件完毕后,一定要关闭文件,否则可能会造成文件损坏
c、文件平时是存放在块设备中的文件系统中的,我们把这个文件叫做静态文件,当我们去打开一个文件时,linux内核做的操作包括:内核在进程中建立了一个打开文件的数据结构,
记录下我们打开的这个文件,内核在内存中申请一段内存,并且将静态文件的内容从块设备中读取到内存中特定地址管理存放(叫动态文件)
d、打开文件后,以后对这个文件的读写操作,都是针对内存中这一份动态文件的,而不是针对静态文件的。
当我们对动态文件进行读写后,此时内存中的动态文件和块设备中的静态文件就不同步了,
当我们close 关闭动态文件时,close内部内核将内存中的动态文件的内容去更新(同步)块设备中的静态文件。
2、为什么是这样操作?
以块设备本身有读写限制(回忆Nandflash、SD、等块设备的读写特征),本身对块设备进行操作非常不灵活。而内存可以按字节为单位来操作。而且进行随机操作。
3、文件描述符是什么?
a、文件描述符:它其实实质是一个数字,这个数字在一个进程中表示一个特定的含义,当我们open打开一个文件时,操作系统在内存中构建了一些数据结构来表示这个动态文件,然后返回给应用程序一个数字作为文件描述符,这个数字就和我们内存中维护这个动态文件的这些数据结构挂钩绑定上了。以后我们应用程序如果要操作这一个动态文件,只需要用这个文件描述符进行区分。简单来说,它是来区分多个文件的(在打开多个文件的时候)。
b、文件描述的作用域就是当前的进程,出了这个当前进程,这个文件描述符就没有意义了。
4、代码实现:
1、打开文件:
1#include <stdio.h>
2#include <sys/types.h>
3#include <sys/stat.h>
4#include <fcntl.h>
5#include <unistd.h>
6int main(int argc, char *argv[])
7{
8 //第一步:打开文件
9 int fd=-1; //fd是文件描述符(在linux中的文件描述符fd
10 的合法范围是0或者是一个正数,不可能是负数)
11 fd=open("/dev/sda/a.txt",O_RDWR);//O_RDWR表示文件可读可写,这个可以
12 用man 手册查看open函数的使用方法里面有它的说明
13 if(-1 ==fd)或者(fd<0)
14 {
15 printf("文件打开错误\n");
16 }
17 else
18 {
19 printf("文件打开成功\n");
20 }
21 //读写文件
22 //关闭文件
23 close(fd);//关闭刚才打开的文件
24 return 0;
25}
2、读文件操作:
1#include <stdio.h>
2#include <sys/types.h>
3#include <sys/stat.h>
4#include <fcntl.h>
5#include <unistd.h>
6int main(int argc,char *argv[])
7{
8 int fd =-1;
9 int ret=-1;
10 char buf[100]={0};
11 fd=open("/dev/sda/a.txt",O_RDWR);
12 if(-1==fd)
13 {
14 printf("the open the file is failure \n");
15 }
16 else
17 {
18 printf("the open the file is successful,fd=%d.\n",fd);
19 }
20 ret=read(fd,buf,20);//20表示读取的字节
21
22 if(ret<-1)
23 {
24 printf("read失败\n");
25 }
26 else
27 {
28 printf("成功读取了%d字节\n",ret);
29 printf("文件内容是:[%s]\n",buf);
30 }
31 close(fd);
32 return 0;
四、缓存
缓存是用来减少高速设备访问低速设备所需平均时间的组件,文件读写涉及到计算机内存和磁盘,内存操作速度远远大于磁盘,如果每次调用read,write都去直接操作磁盘,一方面速度会被限制,一方面也会降低磁盘使用寿命,因此不管是对磁盘的读操作还是写操作,操作系统都会将数据缓存起来。
Page Cache
页缓存(Page Cache)是位于内存和文件之间的缓冲区,它实际上也是一块内存区域,所有的文件IO(包括网络文件)都是直接和页缓存交互,操作系统通过一系列的数据结构,比如inode, address_space, struct page,实现将一个文件映射到页的级别,这些具体数据结构及之间的关系我们暂且不讨论,只需知道页缓存的存在以及它在文件IO中扮演着重要角色,很大一部分程度上,文件读写的优化就是对页缓存使用的优化
Dirty Page
页缓存对应文件中的一块区域,如果页缓存和对应的文件区域内容不一致,则该页缓存叫做脏页(Dirty Page)。对页缓存进行修改或者新建页缓存,只要没有刷磁盘,都会产生脏页
查看页缓存大小
linux上有两种方式查看页缓存大小,一种是free命令
$ free
total used free shared buffers cached
Mem: 20470840 1973416 18497424 164 270208 1202864
-/+ buffers/cache: 500344 19970496
Swap: 0 0 0
cached那一列就是页缓存大小,单位Byte
另一种是直接查看/proc/meminfo,这里我们只关注两个字段
Cached: 1202872 kB
Dirty: 52 kB
Cached是页缓存大小,Dirty是脏页大小
脏页回写参数
Linux有一些参数可以改变操作系统对脏页的回写行为
$ sysctl -a 2>/dev/null | grep dirty
vm.dirty_background_ratio = 10
vm.dirty_background_bytes = 0
vm.dirty_ratio = 20
vm.dirty_bytes = 0
vm.dirty_writeback_centisecs = 500
vm.dirty_expire_centisecs = 3000
vm.dirty_background_ratio是内存可以填充脏页的百分比,当脏页总大小达到这个比例后,系统后台进程就会开始将脏页刷磁盘(vm.dirty_background_bytes类似,只不过是通过字节数来设置);vm.dirty_ratio是绝对的脏数据限制,内存里的脏数据百分比不能超过这个值。如果脏数据超过这个数量,新的IO请求将会被阻挡,直到脏数据被写进磁盘;vm.dirty_writeback_centisecs指定多长时间做一次脏数据写回操作,单位为百分之一秒;vm.dirty_expire_centisecs指定脏数据能存活的时间,单位为百分之一秒,比如这里设置为30秒,在操作系统进行写回操作时,如果脏数据在内存中超过30秒时,就会被写回磁盘.
这些参数可以通过 sudo sysctl -w vm.dirty_background_ratio=5 这样的命令来修改,需要root权限,也可以在root用户下执行 echo 5 > /proc/sys/vm/dirty_background_ratio 来修改
文件读写流程
在有了页缓存和脏页的概念后,我们再来看文件的读写流程
读文件
1.用户发起read操作
2.操作系统查找页缓存
a.若未命中,则产生缺页异常,然后创建页缓存,并从磁盘读取相应页填充页缓存
b.若命中,则直接从页缓存返回要读取的内容
3.用户read调用完成
写文件
1.用户发起write操作
2.操作系统查找页缓存
a.若未命中,则产生缺页异常,然后创建页缓存,将用户传入的内容写入页缓存
b.若命中,则直接将用户传入的内容写入页缓存
3.用户write调用完成
4.页被修改后成为脏页,操作系统有两种机制将脏页写回磁盘
5.用户手动调用fsync()
6.由pdflush进程定时将脏页写回磁盘
五、提高读写效率的方法之一
mmap
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系,函数原型如下
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。如下图所示

mmap除了可以减少read,write等系统调用以外,还可以减少内存的拷贝次数,比如在read调用时,一个完整的流程是操作系统读磁盘文件到页缓存,再从页缓存将数据拷贝到read传递的buffer里,而如果使用mmap之后,操作系统只需要将磁盘读到页缓存,然后用户就可以直接通过指针的方式操作mmap映射的内存,减少了从内核态到用户态的数据拷贝
mmap适合于对同一块区域频繁读写的情况,比如一个64M的文件存储了一些索引信息,我们需要频繁修改并持久化到磁盘,这样可以将文件通过mmap映射到用户虚拟内存,然后通过指针的方式修改内存区域,由操作系统自动将修改的部分刷回磁盘,也可以自己调用msync手动刷磁盘
相关资源:linux内核中读写文件数据方式详解_内核读取文件,内核读写文件…

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)