深度学习服务器配置过程
1、安装系统1.1 系统配置:显卡:Tesla P100;系统:Ubuntu16.04-desktop(英文版)软件:cuda+cudnn+docker+nvidia-docker1.2 换源ubuntu16.04换国内最快源(其它版本也适用)1.3 安装中文输入法System Settings->Language Support(弹出界面,选择install)->Install/Re
1、安装系统
1.1 系统配置:
显卡:Tesla P100;
系统:Ubuntu16.04-desktop(英文版)
软件:cuda+cudnn+docker+nvidia-docker
1.2 换源
1.3 安装中文输入法
System Settings
->Language Support(弹出界面,选择install)
->Install/Remove Languages
->Chinese(Simplified)
->再次打开设置中的语言设置,将汉语拉到最上面
->将键盘输入方法改为fcitx
->重启,注意开机后弹出的路径名称设置依旧选择英文,不然中文的话命令行模式会乱码
1.4 禁止Ubuntu内核更新
- 查看已安装的内核
sudo dpkg --get-selections | grep linux
- 禁止更新内核 (删除末尾为generic的)
sudo apt-mark hold linux-image-5.4.0-84-generic
sudo apt-mark hold linux-headers-5.4.0-84-generic
sudo apt-mark hold linux-modules-5.4.0-84-generic
sudo apt-mark hold linux-modules-extra-5.4.0-84-generic
1.5 挂载非系统的机械硬盘到home文件夹下
- 在home文件夹创建data文件夹
- Gparted添加新分区
sudo apt install gparted
sudo gparted
#在gparted查看要挂载的分区名
- 挂载
sudo mount -t ext4 /dev/sdb1 /home/username/data
#查看一下分区结果
df -h
- 自动挂载硬盘
# 查看新添加分区/dev/sdb1的UUID
sudo blkid /dev/sdb1
#编辑/etc/fstab文件
sudo gedit /etc/fstab
#在末尾添加以下:
#将上面查到的新分区UUID替换掉这个xxxxxxxxx
UUID=xxxxxxxx-xxxx-xxxxxxxxxxxxxxxxx /home/username/data ext4 defaults 0 2
2、安装NVIDIA显卡驱动
2.1 选择驱动版本
- 查询对应显卡型号支持的最新cuda版本
驱动版本查询 - 查询对应cuda版本是否有相应的cudnn,如果没有则返回1重新查询次新版本,直到找到为止
cudnn版本查询 - 找到符合的cudnn后,返回1下载相应的NVIDIA驱动,然后根据自己的需要,下载cuda和cudnn,cuda和cudnn版本要对应
cuda下载
2.1 禁用nouveau驱动
- 编辑文件blacklist.conf:
sudo vim /etc/modprobe.d/blacklist.conf
- 若未安装vim则sudo apt-get install vim安装或使用vi:
sudo vi /etc/modprobe.d/blacklist.conf
- 在文件最后部分插入以下两行内容:
blacklist nouveau
options nouveau modeset=0
- 更新系统:
sudo update-initramfs -u
- 重启系统(一定要重启):
reboot
- 验证nouveau是否已禁用(无输出,则禁用成功):
lsmod | grep nouveau
2.2 安装NVIDIA驱动
- 关闭图形界面:
sudo service lightdm stop
- Ctrl+Alt+F1 进入命令行界面,输入用户名和密码
- 卸载原驱动
sudo apt-get remove nvidia-* //若安装过其他版本或其他方式安装过驱动执行此项
- 将事先准备好的驱动文件放在某个目录下,输入cd进入该目录
给驱动run文件赋予执行权限:
sudo chmod a+x NVIDIA-Linux-x86_64-396.18.run
- 安装:
sudo ./NVIDIA-Linux-x86_64-396.18.run -no-x-check -no-nouveau-check -no-opengl-files
#只有禁用opengl这样安装才不会出现循环登陆的问题
#-no-x-check:安装驱动时关闭X服务
#-no-nouveau-check:安装驱动时禁用nouveau
#-no-opengl-files:只安装驱动文件,不安装OpenGL文件
//弹出选择界面都直接默认选项即可,除了X-config要选择yes
2.3 挂载并验证|NVIDIA驱动
- 挂载Nvidia驱动:
modprobe nvidia
- 检查驱动是否安装成功:
nvidia-smi //出现显卡信息图表,则表示成功
2.4 重启图形化界面
- 执行下面命令,重启图形化界面
sudo service lightdm start
- 如果没有安装lightdm, 先安装之:
sudo apt-get install lightdm
- 查看图形化界面是否启动
sudo service lightdm status
3、安装CUDA和CUDNN
3.1 安装CUDA(第一次)
- 进入CUDA的路径下,使用命令安装:
sudo bash cuda_10.0.130_410.48_linux.run
-
按q到服务条款底部,接着按下面的步骤选择:
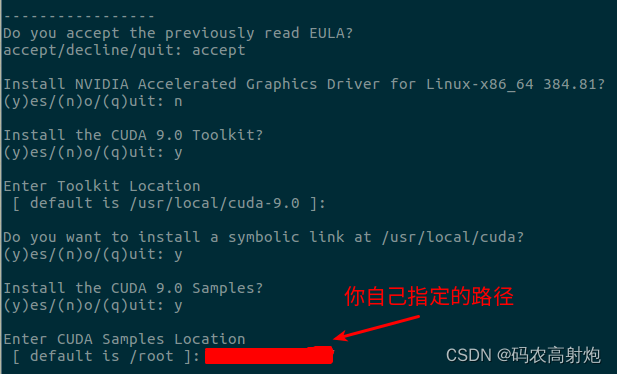
-
测试cuda是否安装成功
cd ~/NVIDIA_CUDA-9.0_Samples/1_Utilities/deviceQuery
make
./deviceQuery
- 配置环境变量和添加共享库路径
sudo vim /etc/profile
- 末尾添加以下内容:
#cuda9.0
export PATH=/usr/local/cuda/bin:${PATH} # 必须
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:${LD_LIBRARY_PATH}
- 保存,使配置生效
reboot
- 测试cuda环境配置是否成功
nvcc --version
3.2 安装CUDNN
- 切换到root用户,将下载好的cudnn文件放在某个路径,进入并解压:
tar -xvf cudnn-10.0-linux-x64-v7.6.4.38.tgz
- 解压后可以看到cuda文件夹,在当前目录打开终端,执行如下命令,将cudnn相关的文件复制过去:
sudo cp cuda/include/cudnn*.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn*.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
3.3 查看安装的版本
- cuda 版本 :
cat /usr/local/cuda/version.txt
- cudnn 版本 :
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
# 注意8.0以上版本不同
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
# docker容器内查看的话,为/usr/include,以上两个都是
3.4 安装多个CUDA和CUDNN版本并随意切换
- 重复3.1和3.2步骤,在安装cuda时注意以下事项:
#添加软链接
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
#如果你之前安装过另一个版本的cuda,除非你确定想要用这个新版本的cuda,
#否则就选no,因为指定该链接后会将cuda指向这个新的版本
#这里因为后续还需要安装CUDNN,所以选择
- cuda多个版本的切换:
在安装了多个cuda版本后,可以在/usr/local/目录下查看自己安装的cuda版本
#查看当前cuda软链接指向的哪个cuda版本
stat cuda
#删除原有链接
sudo rm -rf cuda
#重新建立指向cuda-11.2版本的软链接
sudo ln -s /usr/local/cuda-11.2 /usr/local/cuda
4、 安装Docker和NVIDIA-DOCKER
4.1 安装Docker
- 通过https,允许apt使用repository安装软件包
sudo apt-get install -y \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
- 添加Docker官方GPG key
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
- 验证key的指纹
sudo apt-key fingerprint 0EBFCD88
- 添加稳定版repository
sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs) \
stable"
- 更新apt包索引
sudo apt-get update
- 安装最新版本的Docker CE
sudo apt-get install -y docker-ce
4.2 安装Nvidia-Docker2
- 添加repositories
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
#分开执行
sudo apt-get update
- 安装nvidia-docker2
sudo apt-get install -y nvidia-docker2
- 加入docker组,以允许非root用户免sudo执行docker命令
sudo gpasswd -a 用户名 docker
#如果不重启电脑的话,需要手动重启服务并刷新docker组成员
sudo service docker restart
newgrp - docker
- 备份daemon.json
sudo cp /etc/docker/daemon.json /etc/docker/daemon.json.bak
- 修改daemon.json
sudo vim /etc/docker/daemon.json
#配置如下:注意graph为存储位置,根据自己需要进行更改
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"registry-mirrors": [
"https://kuamavit.mirror.aliyuncs.com",
"https://6kx4zyno.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn"
],
"max-concurrent-downloads": 10,
"storage-driver": "overlay2",
"graph": "/home/zj/data/docker",
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
- 保存退出,并在/home/zj/data下建立docker文件夹
sudo mkdir docker
- 重启服务
sudo service docker restart
- 查看信息,Root dir是否为自己设置的路径
docker info
4.3 安装Docker 管理面板Portainer
- 拉取portainer
docker pull portainer/portainer
- 创建portainer容器并启动
docker run -d --name portainerUI -p 8000:9000 -v /var/run/docker.sock:/var/run/docker.sock portainer/portainer
- 访问portainer界面
本地界面网址 - 初始化设置密码,首次登陆时
4.4 Docker 容器开启ssh登录
- 创建容器时指定映射的端口
docker run -it --privileged=true --name tf -p 2222:22 ubuntu:16.04 /bin/bash
#--privileged=true:容器共享宿主机硬件
#--name tf:容器名为tf
#-p 2222:22:将宿主机2222端口映射到容器的22端口
#ubuntu:16.04:镜像名
#镜像可在docker hub官网搜索自己需要的
- 登录容器中,修改root密码,安装openssh服务
#修改容器中ROOT账户的密码
passwd
apt-get update
#安装openssh服务
apt-get -y install openssh*
- 修改容器/etc/ssh/sshd_config
apt-get install vim
vim /etc/ssh/sshd_config
PermitRootLogin yes #允许root用户ssh登录
UsePAM no
- 宿主机添加端口放行
iptables -A INPUT -p tcp --dport 2222 -j ACCEPT
iptables-restore < /etc/iptables.rules
- 容器开启ssh服务
#开机自启
vim /root/.bashrc
service ssh start
- 主机Windows系统安装Xshell连接服务器,服务器输入ifconfig,inet为服务器的ip地址。Xshell在主机项填入服务器ip,端口为上面设置的2222端口。用户名root,密码为上面设置的。连接即可。
- Ubuntu宿主机也可安装ssh服务,只需要2(需要passwd改密码)、5即可
# 宿主机ssh开机自启
sudo systemctl enable ssh
- 容器换源跟宿主机换源一样,只是命令不需要打sudo
- 容器开机自启
# 1、创建新容器时,加--restart=always
docker run -it --privileged=true --restart=always --name tf -p 2222:22 ubuntu:16.04 /bin/bash
# 2、容器已存在时
docker update --restart=always 容器名或者id
# 3、取消开机自启,no是默认值
docker update --restart=no 容器名或id
4.5 容器环境配置
- 安装Anaconda并配置环境
apt-get install -y wget
cd home
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh
/bin/bash /home/Anaconda3-5.3.1-Linux-x86_64.sh -b -p /opt/conda && \
ln -s /opt/conda/etc/profile.d/conda.sh /etc/profile.d/conda.sh
apt-get install vim
vim ~/.bashrc
#在最后一行加上Anaconda安装目录
export PATH=$PATH:/opt/conda/bin
#保存更改,运行
source ~/.bashrc
#conda创建环境
conda create –n tf python=3.6
source activate tf
conda install packagename(根据需要下载相应包)
#如果配置的是别人的environment.yml,参考以下(前提是本地主机安装了Xshell
apt-get -y install lrzsz
rz #上传本地的environment.yml
#conda创建环境
conda env create -f environment.yml
# 当environment.yml的pip里某一个无法下载时,建议删掉再单独下载,方便查看错误,然后进行修改
-
容器需要安装cuda、cudnn的话,可参考以下链接
Nvidia-docker 配置深度学习环境服务器(cuda+cudnn+anaconda+python)GPU服务器的配置 -
容器中文乱码问题:
ubuntu locale-gen: command not found bypy list docker中文显示错误 -
Anaconda和pip换源
# Anaconda
vim ~/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pip换源
conda换源报错:
CondaHTTPError: HTTP 000 CONNECTION FAILED for url …
Elapsed: -
原因是conda源加入了不知名的URL,现在不能使用了(或者废弃)
解决方法:删除bioconda那行即可
conda报错:
ERROR conda.core.link:_execute(502):
FileNotFoundError
更新conda:conda update conda --yes
pip安装某个包报错:
tensorflow 2.6.0 requires typing-extensions~=3.7.4, but you have typing-extensions 3.10.0.2 which is incompatible.
解决方法:pip install xxx => pip3 install xxx
4.6 容器后台运行神经网络模型训练任务
- 安装screen
apt-get install screen
screen -S 窗口名称 #创建screen
screen -r 窗口名称 #进入screen
ctrl+A D #按键;退出但不关闭程序,后台运行
exit #关闭本窗口,同时本窗口运行的程序也会终止。
#列出所有正在运行的screen
screen -ls
- screen -S 创建窗口,进入之后,直接运行代码,ctrl+A D退出即可。
- 下次要查看进度,输入:
#列出所有正在运行的screen
screen -ls
screen -r 窗口名称 #进入screen
- 训练完毕,结束进程
exit #关闭本窗口,同时本窗口运行的程序也会终止。
- tensorboard xshell远程连接
Xshell中添加隧道
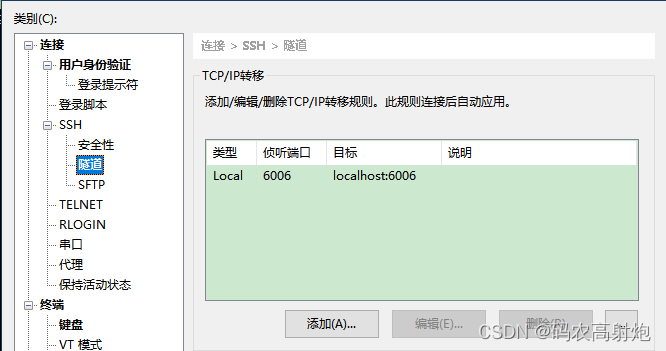
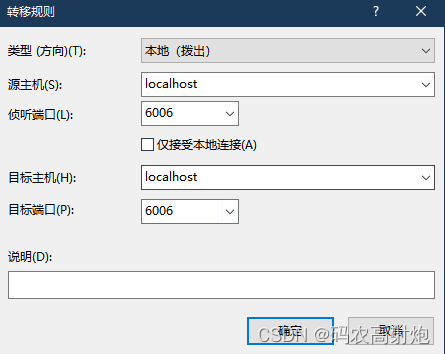
# 前提是有装tensorboard库
# 注意需要在conda创建的环境中运行以下代码
# logdir为日志文件路径,即包含events.out.tfevents...文件的文件夹,port为默认端口6006
tensorboard --logdir=logs/summaries --port=6006
然后在本地浏览器地址栏localhost:6006即可
4.7 将容器保存为镜像
- 保存为镜像
#可以根据自己需求另配容器,我的配置为ssh+anaconda+换源+中文显示+cuda+cudnn
#+Xshell文件传输+后台运行
#dockerimage为保存的镜像的名字, container_ID 为上述查询到的容器器皿地址
docker commit container_ID dockerimage
- 保存为镜像之后,可以创建容器,方便进一步搭建对应网络的环境,端口改为其他的即可,记得在宿主机保存iptable
docker run -it --privileged=true --name tf -p 2223:22 dockerimage /bin/bash
5、配置及编译问题汇总
-
error: invalid static_cast from type ‘const torch::OrderedDict<std::bas
ic_string, std::shared_ptrtorch::nn::Module >’ to type ‘tor
ch::OrderedDict<std::basic_string, std::shared_ptr<torch::nn::M
odule> >&’
error: command ‘/usr/local/cuda-11.6/bin/nvcc’ failed with exit code 1
解决方法 -
ModuleNotFoundError: No module named ‘torch’
已经安装了torch,但还是报错
原因:版本问题,可能是python和torch版本不对应;
也可能是需要用支持cuda版本的,结果下载的cpu版本的,直接conda install torch的话默认是cpu版本,需要到pytorch官网根据自己的情况选择,复制代码(我的是第二种情况)
pytorch历史版本 -
ERROR conda.core.link:_execute(502): An error occurred while installing package
解决方法 -
使用pytorch官网安装torch出现以下错误:
PackagesNotFoundError: The following packages are not available from current channels:
解决方法:
1、添加通道,原本后面为-c pytorch,可尝试添加-c conda-forge(可能在该源的不同文件夹里)
2、1不行的话,使用pip安装,直接在下面的网址里面找。
pip版本的torch
文件名cu开头为CUDA版本,cpu开头为CPU版本;
注意python版本,cp38为python3.8
本地下好再上传到服务器,然后在需要安装的环境(使用conda activate 环境名,激活环境)里使用pip install xxx.whl安装
提醒一下,不要忘记下torchvision,可参考官网的版本对应关系下载。 -
RPC failed; curl 56 GnuTLS recv error (-54): Error in the pull function.
git config --global http.postBuffer 524288000 # httpBuffer加大
git config --global http.maxRequestBuffer 100M
git config --global core.compression 0 # 压缩配置
# 修改配置文件
export GIT_TRACE_PACKET=1
export GIT_TRACE=1
export GIT_CURL_VERBOSE=1
- GnuTLS recv error (-110): The TLS connection was non-properly
terminated
解决方法 - Unknown compute capability.Specify the target compute capabilities in the TCNN_CUDA_ARCHITECTURES
解决方法 - apt-get update报错:key is not available: NO_PUBKEY A4B469963BF863CC
apt-key adv --recv-keys --keyserver keyserver.ubuntu.com A4B469963BF863CC
- fatal: unable to access ‘https://github.com/xxx‘: GnuTLS recv error (-110): The TLS connection…
sudo apt install apt-transport-https
6、服务器中挖矿病毒检测与解决方法
1、内网服务器查杀挖矿病毒
2、服务器中了挖矿病毒的检测及删除方法
7、docker镜像导入远程内网服务器
1、将容器保存为镜像,镜像保存为.tar文件
docker commit 容器ID 镜像名
docker save -o 压缩包名.tar 镜像ID
2、分割tar包
split -b 3G -d --additional-suffix=.tar 待切割文件.tar 切割后的小文件名
# -b:指定每多少字节切成一个小文件,大小是一个整数和可选单位。单位是K,M,G,T等
# -d:使用数字后缀代替字母;从更改开始值(默认为0)
# --additional-suffix:在文件名后面附加一个附加后缀
3、利用Xshell将分割后的tar下载到本地,再上传到内网服务器
下载:sz xxx.tar
上传:rz
4、在内网服务器上合并分割后的tar
cat *.tar > 镜像名.tar
5.最后内网导入即可
参考
- 深度学习服务器配置过程
- 从零开始搭建基于linux(Ubuntu)深度学习服务器
- ubuntu16.04换国内最快源(其它版本也适用)
- 从0开始搭建深度学习多GPU服务器 Ubuntu20.04 Sever + Docker
- conda: command not found解决办法
- ubuntu 安装多个CUDA版本并可以随时切换
- Ubuntu添加新分区,挂载硬盘到/home下
- Failed with result ‘start-limit-hit‘ 解决方案
- 本地采用ssh连接远程服务器并使用docker进行模型训练的步骤
- Ubuntu anaconda 换源
- 【conda】解决 An HTTP error occurred when trying to retrieve this URL.问题
- Conda install FileNotFoundError
- 使用Xshell远程访问tensorboard
- ubuntu中设置docker以及容器开机自启
- docker容器SSH服务自启动
- Linux命令之分割文件split
- RPC failed
PS:配置了好几天,做个总结,方便以后再用

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)