操作系统:为什么要区分用户态和内核态
文章目录前言一、用户态和内核态的区分二、为什么要区分用户态和内核CPU指令集权限三、用户态和内核态切换切换开销用户态到内核态切换的场景总结前言这篇文章记录笔者对于操作系统用户态和内核态的复习整理一、用户态和内核态的区分所谓用户态和内核态针对是CPU,是不同权限的资源范围内核态可以执行一切特权代码用户态只能执行那些受限权限的代码二、为什么要区分用户态和内核如此设计的本质意义是进行权限保护。限定用户的
前言
这篇文章记录笔者对于操作系统用户态和内核态的复习整理
一、用户态和内核态的区分
所谓用户态和内核态针对是CPU,是不同权限的资源范围
- 内核态可以执行一切特权代码
- 用户态只能执行那些受限权限的代码
二、为什么要区分用户态和内核
如此设计的本质意义是进行权限保护。
限定用户的程序不能乱搞操作系统,如果人人都可以任意读写任意地址空间软件管理便会乱套.
CPU指令集权限
指令集是CPU实现软件只会硬件执行的媒介,每一条汇编指令对应一条CPU指令,而非常非常多的CPU指令集在一起,就可以组成一个、甚至多个集合,指令的集合就叫CPU指令集
CPU指令集是有权限分级的,毕竟CPU指令集是可以直接操作硬件的,若将全部的CPU指令集放开给非操作系统开发使用,则极其容易出现问题,因指令操作的不规范,导致操作系统内核、及其他所有正在运行的程序,都可能会因为操作失误操作不可挽回的错误
在intel的设计下操作系统分为4个Ring,分别是Ring0,1,2,3
- 用户态的程序工作在3,Ring0完全在操作系统内核中运行
- 内核态的程序工作在0,Ring3完全在应用程序中运行
从以上可以看到,Ring0权限最高,Ring3权限最低,Linux系统仅能使用Ring0和Ring3这两个权限
执行内核空间的代码,具有ring 0保护级别,有对硬件的所有操作权限,可以执行所有C P U指令集,访问任意地址的内存,在内核模式下的任何异常都是灾难性的,将会导致整台机器停机
在用户模式下,具有ring 3保护级别,代码没有对硬件的直接控制权限,也不能直接访问地址的内存,程序是通过调用系统接口(System Call APIs)来达到访问硬件和内存,在这种保护模式下,即时程序发生崩溃也是可以恢复的,在电脑上大部分程序都是在,用户模式下运行的
三、用户态和内核态切换
切换开销
我们总说用户态和内核态切换的开销大,那么切换的开销具体大在哪里呢?
具体来说有以下几点
- 保留用户态现场(上下文、寄存器、用户栈等)
- 复制用户态参数,用户栈切到内核栈,进入内核态
- 额外的检查(因为内核代码对用户不信任)
- 执行内核态代码
- 复制内核态代码执行结果,回到用户态
- 恢复用户态现场(上下文、寄存器、用户栈等)
用户态要切换到内核态,需要有对应的接口才行,下面是Linux整体架构图
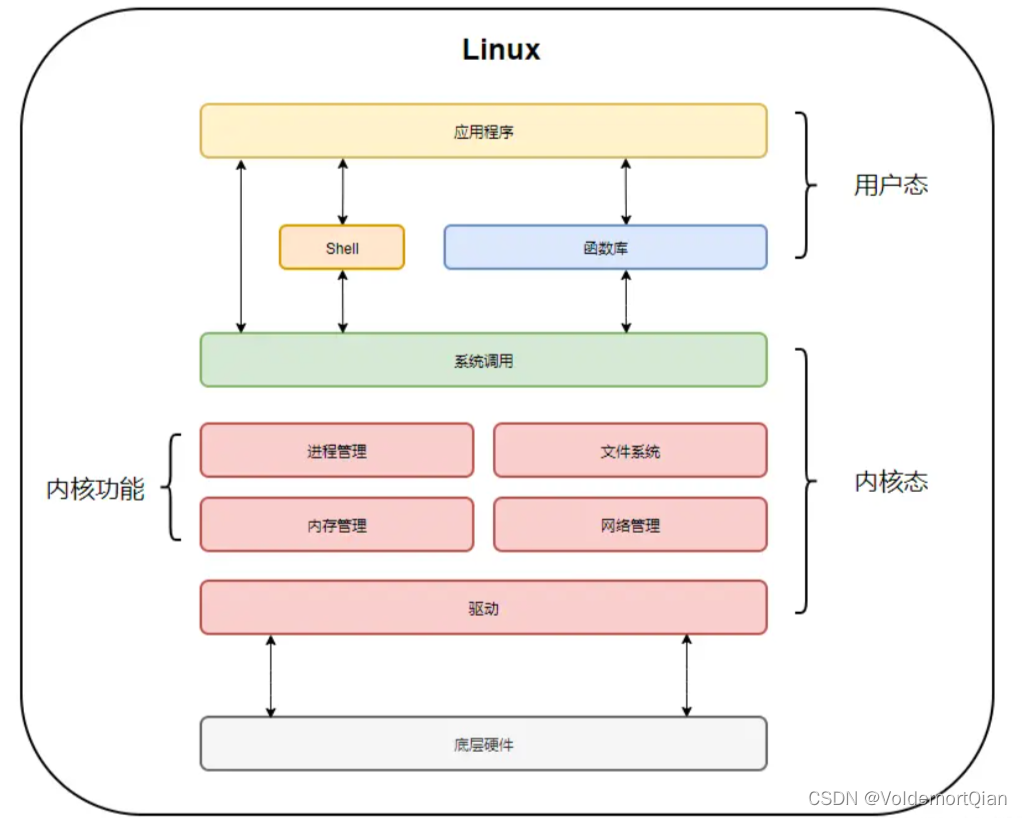
用户态到内核态切换的场景
-
系统调用:用户态进程主动切换到内核态的方式,用户态进程通过系统调用向操作系统申请资源完成工作,例如 fork()就是一个创建新进程的系统调用,系统调用的机制核心使用了操作系统为用户特别开放的一个中断来实现,如Linux 的 int 80h 中断,也可以称为软中断
-
异常:当 C P U 在执行用户态的进程时,发生了一些没有预知的异常,这时当前运行进程会切换到处理此异常的内核相关进程中,也就是切换到了内核态,如缺页异常
-
中断:当 C P U 在执行用户态的进程时,外围设备完成用户请求的操作后,会向 C P U 发出相应的中断信号,这时 C P U 会暂停执行下一条即将要执行的指令,转到与中断信号对应的处理程序去执行,也就是切换到了内核态。如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后边的操作等。
总结
以上就是笔者关于用户态和内核态的相关整理啦

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)