kswapd介绍
一、概述众所周知,内存是⼿机的有限资源,而如何在有限的资源基础上,实现更优的性能、更好的用户体验,是每个系统开发⼯程师夜以继⽇攻克的⽬标。Linux系统为了提⾼系统性能,让每个APP有更快的反应速度,会尽量使⽤系统中的内存,例如缓存⼤量的pagecache,驻留更多的anon pages,以便进程可以直接访问,⽽⽆需实时触发缺⻚或IO来加载数据。但是,由于内存是有限的,⽽...
一、概述
众所周知,内存是⼿机的有限资源,而如何在有限的资源基础上,实现更优的性能、更好的用户体验,是每个系统开发⼯程师夜以继⽇攻克的⽬标。
Linux系统为了提⾼系统性能,让每个APP有更快的反应速度,会尽量使⽤系统中的内存,例如缓存⼤量的pagecache,驻留更多的anon pages,以便进程可以直接访问,⽽⽆需实时触发缺⻚或IO来加载数据。但是,由于内存是有限的,⽽APP可以打开更多,内存总有耗尽的时刻,所以内核对于这种内存紧张情况实现了⼀套内存回收机制,包括kswapd回收内存和direct reclaim,例如回收最近很少使⽤的pagecache,把anonpage swap到外存以及触发OOM查杀等。
本⽂介绍的kswapd是Linux内核中⼀个专门负责在内存不⾜时执行回收内存的线程。
二、创建kswapd线程
在创建kswapd线程的时候,系统会为每个NUMA内存节点创建⼀个名为”kswapdx”的内核线程,其中x是内存节点的node id,代码如下:

在系统初始化过程中,start_kernel()函数创建的init线程会调⽤到module_init的代码段,最终调用kswapd_init()来完成kswapd线程的创建;在NUMA系统中,每个内存节点都由⼀个pg_data_t数据结构来描述,对应节点的kswapd线程structtask_struct也是记录在pg_data_t数据结构中。

其中与kswapd线程相关的⼏个关键字段有kswapd_order、kswapd_wait、kswapd、kswapd_failures和kswapd_highest_zoneidx;kswapd_wait是⼀个等待队列,在free_area_init_core函数中初始化,负责kswapd线程睡眠和唤醒功能,kswapd_failures统计kswapd回收内存失败的次数,如果超过一个阈值MAX_RECLAIM_RETRIES,则会触发direct_reclaim或者唤醒kcompactd线程。
从上述代码看出,kswapd_run()调用kthread_run()来创建一个内存线程,线程主体就是kswapd()函数,线程名是”kswapd”和node id组成的字符串,并且把kthread_run()的返回值赋值给pgdat->kswapd。
三、唤醒kswapd线程的时机
当⼀个task(包括进程和内核线程)在分配内存过程中,如果在Low watermark水线之上,从现有Buddy System(系统所有可以直接使⽤的空闲内存)中没有分配到所需的内存时,就会通过wakeup_kswapd()函数来唤醒kswapd线程,以释放部分内存来满⾜当前的内存分配需求。
我们先看下内存分配流程中,唤醒kswapd的上下文:

在alloc_pages_nodemask中,⾸先调⽤get_page_from_freelist()函数尝试分配内存,此时alloc_flags是带有ALLOC_WMARK_LOW flag,说明此次分配前提是free pages⾼于Low Watermark水线,如果此次分配内存失败,则会调⽤alloc_pages_slowpath进⼊慢速分配路径。

从代码中看出只有alloc_flags中是带有ALLOC_KSWAPDFlag时,才能唤醒kswapd,实际上常用的GFP_ATOMIC、GFP_KERNEL、GFP_USER等mask都是带有该flag的,并且所有进程内存分配都是可以唤醒kswapd的。

四、kswapd⼯作流程
kswapd线程的主体主要是kswapd()函数,如下(代码有删减,忽略暂时不关注的代码):

kswapd()函数完成的工作主要在for循环中完成,在kswapd真正开始⼯作之前,需要完成⼏个关键的操作:
1. 绑核:set_cpus_allowed_ptr(tsk, cpumask)
现在主流的⼿机操作系统,使⽤的是UMA(Uniform Memory Access)结构,即只有⼀个内存节点,所以默认只有⼀个kswapd线程(即kswapd0),默认绑定到所有的CPU;⽽对于⼤ 型服务器,使⽤的是NUMA结构,内存按照CPU的拓扑结构分为多个节点,每个节点(node)对应的是一部分cpu,所以每个node上kswapd线程就要绑定到node对应的cpu上⾯,每个kswapd只负责⾃⼰对应的内存节点上⾯的内存回收。
2. 设置kswapd线程的flags:tsk->flags |= PF_MEMALLOC |PF_SWAPWRITE | PF_KSWAPD
a. PF_KSWAPD主要⽤于标记该线程是个kswapd线程,在后续运⾏中,与其他业务线程进行区别,例如在get_scan_count中⽤于调节swappiness等。
b. PF_MEMALLOC 标记该线程是个关键线程,即在紧急情况下能在低于Min Watermark 的情况下继续分配内存,说明该线程分配内存时不受Watermark的限制。这是因为kswapd在运⾏的时候说明系统已经低内存,⽽kswapd有时为了回收更多内存需要临时分配内存用作周转,例如在把Anon page压缩到zram的过程中,⾸先需要分配内存来保存压缩后的内存,如果分配不成功,则可能⽆法完成内存回收工作。
c. PF_SWAPWRITE 表⽰可以写swap,说明kswapd可以回收匿名⻚
3. 初始化kswapd_order和kswapd_highest_zoneidx
这两个参数是从alloc_pages_slowpath()函数传递下来。
a. kswapd_order
在完分配内存的order,⽤于在kswapd成回收内存后,判断可用内存能否满⾜进程的分配需求,如果不满⾜,则需要进⾏内存规整。
b. kswapd_highest_zoneidx
表⽰在⻚⾯分配路径上计算出来第⼀个最适合内存分配的zone的id,也是kswapd完成内存回收时最⾼的zoneid,在每次唤醒kswapd的时候都会更新kswapd_highest_zoneidx。传递该值的目的,是因为alloc_page()是从HIGH->LOW⽅向进⾏内存分配的,如果kswapd回收高于kswapd_highest_zoneidx的zone,对kswapd的唤醒者是没有意义的,相当于kswapd做了⽆⽤功。例如⼀个驱动调⽤alloc_pages()函数分配内存时,设置的gfp_flags是从Normal zone开始分配的,若kswapd回收内存时还回收High ZONE,驱动原本⽤不到这部分内存,所以kswapd在被唤醒后就要提前确定回收的最高的zone。
回到kswapd()函数,在for循环中,首先调⽤kswapd_try_to_sleep()尝试进⼊sleep状态,同时把⾃⼰挂⼊pgdat→kswapd_wait等待队列中,直到kswapd被唤醒;kswapd_wait是一个等待队列,有两个功能,一个是⽅便kswapd被唤醒,⼀个是在尝试唤醒kswapd的时候,判断kswapd是否在运⾏,如果kswapd正在运行,在判断pgdat→kswapd_wait时候,发现该队列已经为空,就不需要重复执⾏唤醒操作。这样做可以有效防止出现kswapd被漏唤醒的问题

在kswapd_try_to_sleep()函数中有个关键操作,即在kswapd完成⼀轮内存回收,并且free pages已经⾼于highwatermark的情况,如果发现内存碎⽚化严重而导致可用内存⽆法满⾜分配内存order请求,就需要回唤醒kcompactd线程进⾏内存规整,在Buddy System中整理出⼀⽚⾼阶内存来满⾜内存分配需求。
kswapd_try_to_sleep最后调用schedule()调度出CPU,进入睡眠状态,直到被某个进程或驱动的唤醒。
唤醒操作的代码如下:

在wakeup_kswapd()函数,⾸先对zone进⾏有效性判断,然后设置pgdat-
>kswapd_highest_zoneidx和pgdat->kswapd_order,最后判断kswapd是否在运⾏waitqueue_active(&pgdat->kswapd_wait),如果在运⾏则不需要再次唤醒,否则调⽤wake_up_interruptible()来唤醒kswapd线程。
当kswapd在被唤醒后,就开始执⾏内存回收,核⼼函数是balance_pgdat()。这⾥涉及⼀个词语:balance,这⾥所说的平衡是指zone中的free pages已经⾼于high watermark,后续多个场景会用到这个概念。
在分析balance_pgdat()函数之前,我们先预习⼀下⼏个关键概念。
五、LRU链表
LRU(LeastRecently Used)是指最近很少使⽤的pages,基于冷热内存的原理,最近不适⽤的内存在后续⼀段时间内也不会被频繁使⽤,所以这⾥“最近”和“很少使⽤”都是相对的;这些最近很少使用pages恰好是内存回收的最佳候选者。内核使⽤双向链表管理这些LRU,根据page的类型分为LRU_ANON和LRU_FILE,每种LRU根据page的活跃度分配Active和Inactive两种,所以内核中共分成5个LRU:
l LRU_INACTIVE_ANON :不活跃匿名⻚
l LRU_ACTIVE_ANON :活跃匿名⻚
l LRU_INACTIVE_FILE :不活跃⽂件⻚
l LRU_ACTIVE_FILE :活跃⽂件⻚
l LUR_UNEVITABLE :不可回收⻚⾯
LRU这么分类是有原因的,即在内存紧缺的时候是优先回收pagecache的,主要由于回收file pages⽐回收Anon pages的开销低,这⾥先介绍⼀下回收两种内存的基本操作:
l 回收⽂件⻚
如果page是clean的,说明page中的内容没有修改过,与磁盘中保存的数据是一致的,此时直接释放即可;如果page是dirty的,则说明page已经修改,⽐磁盘中的数据更新,此时要先进⾏IO操作,把数据写⼊磁盘后再释放page。
l 回收anon pages
回收匿名⻚的操作,把要回收的page中的数据写⼊swap设备,如果系统没有swap设备则⽆法回收anon pages的。在⼿机系统中是通过ZRAM来实现的swap设备,这个swap设备实际是个内存存储设备,即zram中的数据最终还是保存在RAM中的,可用想象成从RAM中划分一部分内存来模拟成swap块设备;在回收anon pages时,把page压缩后再写⼊zram,正常情况下LZ4压缩算法的压缩⽐可用达到33%左右,所以在使⽤zram的时候,可以节省出67%左右的内存。
从两者的差异看出,⽆论是写swap还是写zram,相对cleanfile pages,回收匿名⻚的开销还是很⼤,实际上系统中存在大量的clean file pages。
六、LRU页面老化以及二次机会
当进程新分配⼀个page后,都会加⼊到LRU链表的头部,按照FIFO算法进行老化,这样LRU尾部的内存就是很早分配的,头部是新分配的,为了防⽌频繁访问的page被回收掉,需要Active和Inactive两个链表来实现:
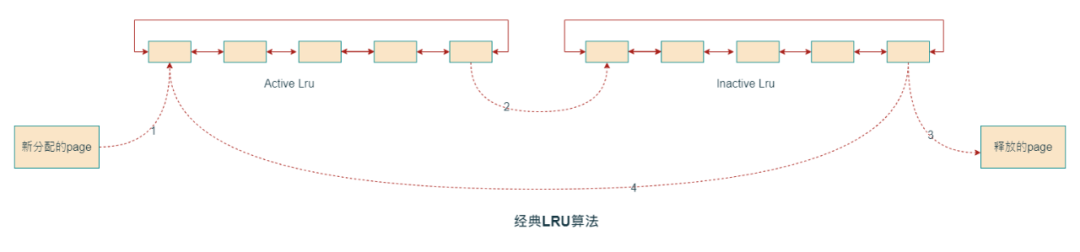
1. 新分配的page直接加⼊到Active LRU链表头部
2. 随着时间增⻓,page⼀步步⽼化,然后从ActiveLRU移动到InactiveLRU链表中
3. page继续在InactiveLRU中⽼化,由于内存紧缺⽽触发内存回收,最终page被释放掉
4. 在回收每个page时,如果发现page有被进程访问过,就会重新放回ActiveLRU。
第4步最关键的是在回收page时,会根据page的访问状态决定是直接释放掉,还是放回
Active LRU,这⾥依据是page是否被访问(pte referenced)。这⾥有个问题,如果系统存在⼤量⼀次访问的内存,而这些page需要⾛完所有⽼化流程才能被回收,那么这些长期驻留的大量内存,导致其他频繁访问的内存被频繁释放和读取,从⽽导致系统颠簸,特别增加系统IO量。这个问题经过社区开发者验证,的确⼤量存在,所以社区对LRU算法进⾏了优化,即⼆次机会算法:
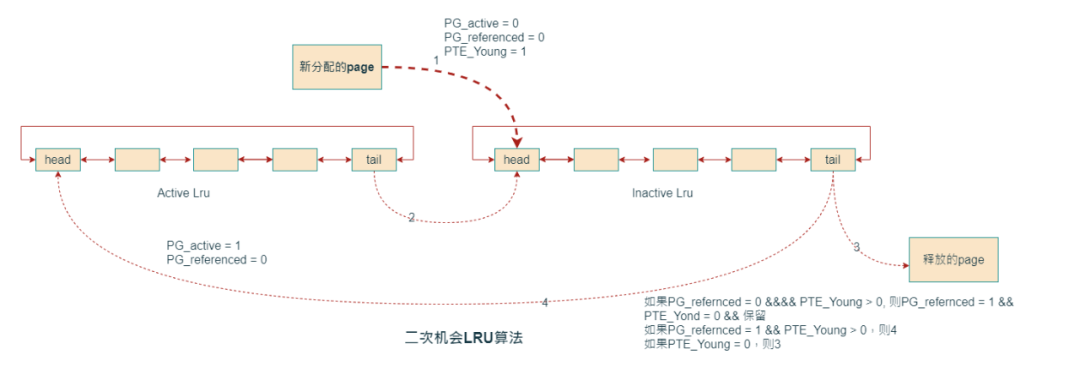
⼆次机会算法依赖PTE访问状态bit(硬件控制,PTE_Young),所以在回收page的时候需要检查page的访问bit,当访问bit是0,就回收page;如果访问bit是1,就给第⼆次机会,选择 下⼀个page来回收。Linux内核中使⽤PG_active和PG_referenced两个标记来实现。新分配的page是直接加⼊到Inactive LRU链表中,在第⼀次回收的时候,由于PTE_young不是0, 所以在InactiveLRU中保留⼀次机会,然后设置page的PG_referenced,以便再次释放内存时识别是第几次扫描到该page。
七、zone→lru迁移到node→lru
在kernel-4.8之前,所有的lru是按照zone的粒度管理的,即每个zone都有5个LRU,通过zone->lru_lock来保证同步;从kernel-4.8开始,所有的lru都是统计在node上⾯的,通过pgdat->lru_lock来保证同步,这么做的原因:
1. 在kernel-2.x/3.x版本的时代,64bit的cpu还没有问世,⼤部分设备的cpu都是32bit,由于32bit地址支持访问的内存空间有限,对于⼤内存设备,系统存在⼤量的⾼端内存(HighZONE), 并且Normal ZONE中的区间有限,为了⽅便内存管理,LRU是按照zone来划分的。
2. 通过ZONE来管理LRU存在⼀个弊端,即每个zone上⾯的page⽼化程度⽆法保持⼀致,例如⼀个进程从不同的zone中分配了内存,从High ZONE中分配的内存在⼀定时间周期内被回收了,⽽Normal ZONE中的内存有可能还在LRU中;理想情况应该是它们能够在同⼀段时间内被回收,保证各个LRU的⽼化程度趋于一致。开源社区针对该问题,已经做了⼤量优化,但是效果不达预期。
3. ⽬前主流的设备很少使⽤32bit的CPU,⽽64bit地址⼏乎可以直接访问所有的物理内 存,已经不存在High ZONE,可以在node的维度来管理所有的LRU。
基于上述原因,现在kswapd在回收内存⽅向与kernel-4.8之前有差异,在之前的版本中,kswapd是从DMA→Normal→High的⽅向来进⾏回收内存,恰好与alloc_pages分配内存的⽅向相反,这样可以减少zone->lru_lock锁的竞争,降低cpu负载。
在kernel-4.8之前内存回收⽰意图:

kerne-4.8之后(包含)内存回收⽰意图:
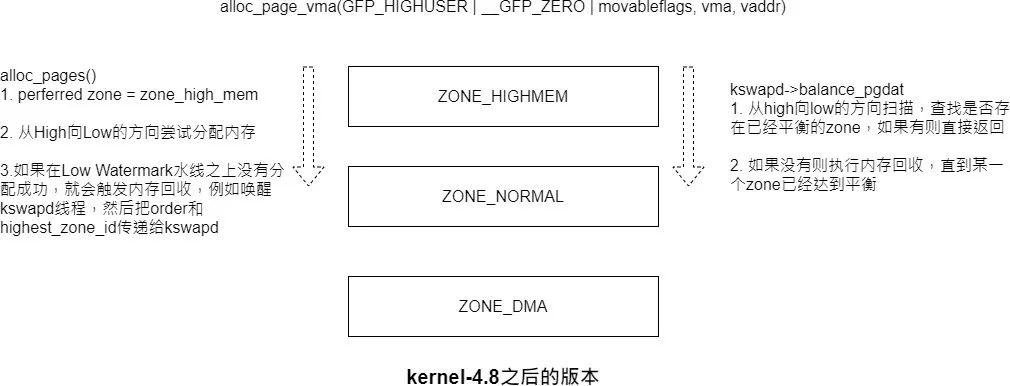
使⽤node->lru⽅式管理LRU后,可以解决不同zone中page老化程度不同步的问题,但是pgdat->lru_lock锁的进程还是十分激烈。
balance_pgdat
balance_pgdat是kswapd线程实现内存回收的核⼼函数,主体代码⽐较⻓,我们先看下该函数调⽤了那些关键函数:


struct scan_control数据结构用于保存管理⻚⾯回收的参数,例如回收⻚⾯的个数(nr_to_reclaim),分配page的mask(gfp_mask),分配page的order,扫描LRU链表的priority等。
a. priority
priority表⽰扫描page的优先级,是来计算每次扫描的page个数,计算⽅法是total_size>> priority;其初始值是12,依次递减。priority越⼩,说明扫描的page个数越多。如果扫描⼀部分page并完成回收了⽬标(其中⼀个zone已经balance)就可以停⽌回收,如果不满⾜扫描⽬标,则需要扫描更多的内存,通过调节priority即可。从balance_pgdat()函数中就可以看出,priority是个⼀步⼀步减⼩的过程,直到priority变成0,此时要扫描所有的page。
pgdat_balanced
pgdat_balanced()函数⽤于判断低于(包含)highest_zoneidx的zone中是否有已经处于balance状态的,回t如果存在则说明已经有满⾜分配需求的内存,返rue。

需要注意,pgdat_balanced()函数是从0向highest_zoneidx的⽅向进⾏遍历的;遍历到每个zone后,调用high_wmark_pages(zone)计算出对应zone的high watermark,然后通过zone_watermark_ok_safe来计算该zone中的free pages是否⾼于high⽔线,且buddy system中是否有⼤于或等于order的内存块,如果有则返回true,否则返回false。
在 zone_watermark_ok()函数中,对于order为0的情景,所有的zone都是平衡的,只要freepages⼤于high watermark即可;如果order⼤于0,则需要从order向MAX_ORDER⽅向扫描,确认buddy system中是否存在大于等于order的内存块,即判断每个free_area的链表是否为空。
balance_pgdat()根据pgdat_balanced()的返回值决定是否继续回收(本⽂暂不介绍watermarkboost功能),如果已经存在balanced zone就可以直接退出内存回收。
age_active_anon
该函数主要是完成anonpages的⽼化处理,其实Active LRU和Inactive LRU中的pages是存在⼀定⽐例的,当Inactive LRU中page个数⽐较少的时候,就会从ActiveLRU链表尾部移动⼀部分page到Inactive LRU链表中。

如果total_swap_pages为0,说明该系统中没有swap设备,从⽽就⽆法回收anon pages,故就不存在回收anon pages的操作。通过inactive_is_low()函数来判断InactiveLRU中的pages是否低于正常⽐例,如果是,则需要进⾏⽼化操作,实际就是从Active LRU移动部分page到Inactive LRU中,正常⽐例设置如下:

shrink_active_list()函数会从Active LRU中选出SWAP_CLUSTER_MAX个page进⾏⽼化处理,SWAP_CLUSTER_MAX的值是32。
这⾥这么做的好处是给anon pages一次机会,如果这些pages在Inactive LRU中被访问过, 则会重新放回ActiveLRU链表头部;如果不迁移,pages在ActiveLRU中,系统是不关注page是否被访问过,有可能在后续内存回收中,直接被迁移到Inactive LRU后,如果Inactive LRU 链表中page⽐较少,有可能很快就被写⼊swap了。
其实kswapd执⾏内存回收,主要包括两部分内存回收,进程的内存回收和内核内存的 回收。进程的内存回收主要回收进程分配的page,例如进程分配的匿名⻚,映射的⽂件⻚、buffer cache等内存;内核内存回收主要是回收各种cache,例如inode cache、dentry cache,slabcache、ION cache以及各种驱动分配的cache等。对于不同的内存,回收路径不同,简化如下:
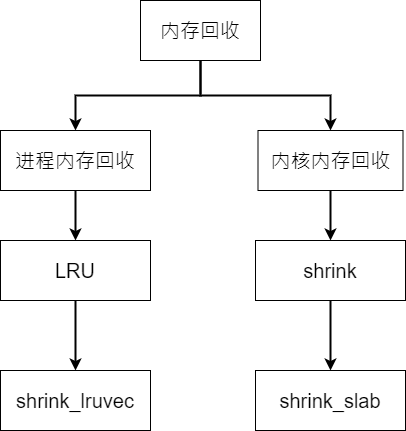
进程分配的page⼤部分都是挂载LRU链表上⾯,最终通过shrink_lruvec()函数依据page的⽼化程度,把最⽼的⼀部分内存回收掉;shrink_slab则是通过回调挂在shrinker_list链表中的回调函数来进⾏回收。
八、shrink_lruvec
shrink_lruvec()函数主要是扫描Active LRU和Inactive LRU链表,根据page的⽼化程度来回收最老的pages。扫描ActiveLRU的⽬的为了保证两个链表中的page个数达到平衡,触发标准主要是通过inactive_is_low()函数来判断,前⾯已经介绍,这⾥不在赘述;扫描InactiveLRU则是真正的开始内存回收操作。


shrink_lruvec()函数⾸先会调⽤get_scan_count()函数来计算本次可以扫描的page个数,保存在nr数组中,nr数组的⻓度NR_LRU_LISTS,主要使⽤的是LRU_INACTIVE_ANON、LRU_ACTIVE_ANON、LRU_INACTIVE_FILE和LRU_ACTIVE_FILE;在get_scan_count()函数中有个关键参数即swappiness,其取值范围是[0,200],用于计算回收anonpages的⽐例,默认值是60,表⽰在回收内存的时候回收60/200的anonpages,回收140/200的⽂件⻚。
get_scan_count()会根据swappiness的值,基于当前各个LRU中的内存状态以及sc->priority优先级计算出4个LRU中应该扫描的page个数.
需要关注的是shrink_lruvec()中while循环的条件是(nr[LRU_INACTIVE_ANON]|| nr[LRU_ACTIVE_FILE] ||nr[LRU_INACTIVE_FILE]),这里唯独是不扫描LRU_ACTIVE_ANON,主要是由于Active Anon Pages不能直接回收,根据内存局部性原理,这些内存会很快被访问,所以匿名页必须经过老化在移动到Inactive LRU后才能被回收掉,从另外一面来说,系统倾向于多回收⽂件⻚。
shrink_active_lru


当InactiveLRU中的pages少于Active LRU的时候,shrink_active()函数就会扫描Active LRU,尝试把部分pages以移动到InactiveLRU中。为了防⽌扫描LRU过程中⻓期持有node->lru_lock锁,采⽤的是批量处理⽅案,即每次加锁后从Active LRU中最多隔离出SWAP_CLUSTER_MAX个page放到lru_hold中,然后⽴即放锁,SWAP_CLUSTER_MAX的值是32;然后从lru_hold中遍历每个page进⾏迁移。扫描l_hold过程中,会判断page的状态,已决定该page是继续保留在ActiveLRU中,还是需要移动到Inactive LRU中,其中部分pages可能在进程运⾏过程中被执⾏了mlock()等操作,导致这些pages不可以被回收,还需要把这些page放⼊到Unevictable LRU中。
由于ActiveLRU中的page原本就是⽐较活跃的内存,⽆法仅凭PG_referenced来决定page的活跃程度,且⼤内存的系统中,当系统用完了所有空闲内存,且每个page都会被访问到时,不仅没有时间扫描Active LRU,而且还需要重新设置referenced bit。所以正常情况下都是直接所有隔离出来的page 直接放⼊到InactiveLRU中,同时清除pte的PTE_Yong,当这些page在Inactive LRU中再次被访问后,硬件会自动设置pte的PTE_Young,这些被访问的page在回收的是会重新返回Active LRU。
有⼀种情况是例外,那就是page保存的是可执⾏的代码段指令,由于这部分内存是⼗分活跃的,需要保留在Active LRU中;这些page在扫描Active LRU过程中可能被再次访问到。
从LRU中隔离出⼀部分page的功能是有isolate_lru_pages()函数实现,这是个通⽤的函数, 在shrink_inactive_lru()函数中也会⽤到,所以这⾥需要介绍⼀下。

参数nr_to_scan表⽰从lru链表中需要扫描的page个数,lruvec是LRU链表集合,dst是临时 存放隔离出来page的链表, nr_scaned是已经扫描的page个数, sc是page回收控制的数据结构,lru是要回收的LRUindex;该函数返回值是表⽰已经成功隔离的page个数。
_isolate_lru_page是尝试隔离⼀个page,返回0说明已经成功隔离,返回-EBUSY说明该page正在回收流程中,则不需要隔离。整个隔离流程是在⼀个while循环中完成,判断条件是lru中的page已经为空,或者扫描的page个数是否达到nr_to_scan。
shrink_inactive_lru
该函数扫描Inactive LRU来尝试回收内存,并且返回已经成功回收的page个数。

与shrink_active_list()函数类似,⾸先在加锁的情况下,从lru中最多隔离出32个page,保存在page_list链表中,然后调⽤shrink_page_list()函数执⾏内存回收操作。shrink_page_list()函数中需要考虑很多场景,所以代码很⻓且⼗分复杂,对于dirty和writeback的page会考虑写块设备⽽堵塞的问题,需要考虑逆向映射执⾏unmap的操作,该函数的核⼼主体如下:



真正执⾏page回收操作的时候,需要获取pagelock,如果trylock_page(page)返回0,表示获取page lock失败,说明该page正在被使⽤,是不能回收的。
sc->may_unmap来⽤来判断本次内存回收是否允许回收已经被map的page,如果该page已 经被映射,⽽sc→may_unmap是0,则跳过该page的回收。
page_check_references()是LRU⼆次机会算法的关键函数,后续介绍。
page_mapped(page)判断page是否已经有建⽴映射,如果已经建⽴映射,需要调⽤try_to_unmap()函数来解除所有映射到该page的⻚表,只有全部解除映射,该page才能被 回收,否则只能保留在lru链表中。
PageDirty(page)判断page是否是dirty的,如果是dirty的则需要先把page中的数据写会块设备,通过try_to_unmap_flush_dirty()来完成数据写回。
最后通过free_unref_page_list()把可以回收的内存释放到BuddySystem。
page_check_references
page_check_references()函数主要是在回收page之前,先判断⼀下该page是否的确需要回 收,是LRU⼆次机会算法的核⼼函数。

该函数返回的是page_references枚举类型 :
a. PAGEREF_RECLAIM: 表⽰该page需要放回Active LRU中
b. PAGEREF_KEEP: 表⽰该page还需要继续保留在Inactive LRU中
c. PAGEREF_RECLAIM_CLEAN:表⽰page已经clean,或者是dirty的filepage,可以尝试回收
a. PAGEREF_RECLAIM:表⽰可以回收
page_referenced()函数会通过逆向映射扫描所有的映射到该page的PTE,统计page的被映射 的次数(保存在referenced_ptes中),同时clear掉对应PTE的PTE_YOUNG bit;TestClearPageReferenced()会清理掉page的PG_referencedbit,并且返回其旧的值保存在referenced_page中。接下来根据访问引⽤pte的个数(referenced_ptes)和PG_referenced的状态(referenced_page)来判断该page的回收⾏为,当referenced_ptes⼤于0时,需要放回Active LRU的情况:
a. 该Page是匿名⻚
b. 最近第⼆次访问的file page(referenced_page )或者共享filepage(referenced_ptes > 1)
c. 可执⾏⽂件的file page
除了上述三种情况,继续保留在Inactive LRU中,例如第⼀次访问的filepage。
⽽对于referenced_ptes等于0的情况,说明最近⼀段时间内存,该page没有被访问,可以尝试回收掉。
九、shrink_slab
对于⼀部分内核分配的内存,也是可以回收的:
l 例如inode cache或者dentry cache,虽然这些内存都是slab内存,但是由于这些内存都是从⽂件系统中读取出来的,为了提⾼性能,暂时保存在内存中,以便进程快速访问;但是在内存紧张的时候,这些内存还是可以回收掉,当进程需要再次访问的时候,再从⽂件系统加载回来;
l 有些驱动程序为了⾃⼰能够快速分配到⼤块内存,也会提前从BuddySystem分配部分内存,保存在⾃⼰的cache中,以便需要的时候直接分配,⽽不需要临时从Buddy System分配,以及驱动在释放部分内存的时候也是直接放回cache中。
对于上述两种内存,在代码初始化的时候需要向shrinker_list链表中挂载对应的内存回收函数,通过register_shrinker()函数来完成注册:

数据结构struc shrinker种有两个关键的hook函数:
count_objects⽤于计算可⽤回收的内存个数;
scan_objects⽤于进⾏内存回收;
例如ION驱动中注册ion cache的shrinker:

shrinker_list是个全局变量,通过链表的形式把所有的shrinker给管理起来,⽤shrinker_rwsem保证同步。

memcg采⽤lazy free的⽅法来提⾼性能,即当我们删除⼀个cgroup分组的时候,对应的cgroup管理结构是没有释放的,以便下次可以继续使⽤,在紧急情况下调⽤shrink_slab_memcg来完成内存回收。
最后通过list_for_each_entry()来遍历每个shrinker,通过do_shrink_slab()来完成内存回收。
十、小结
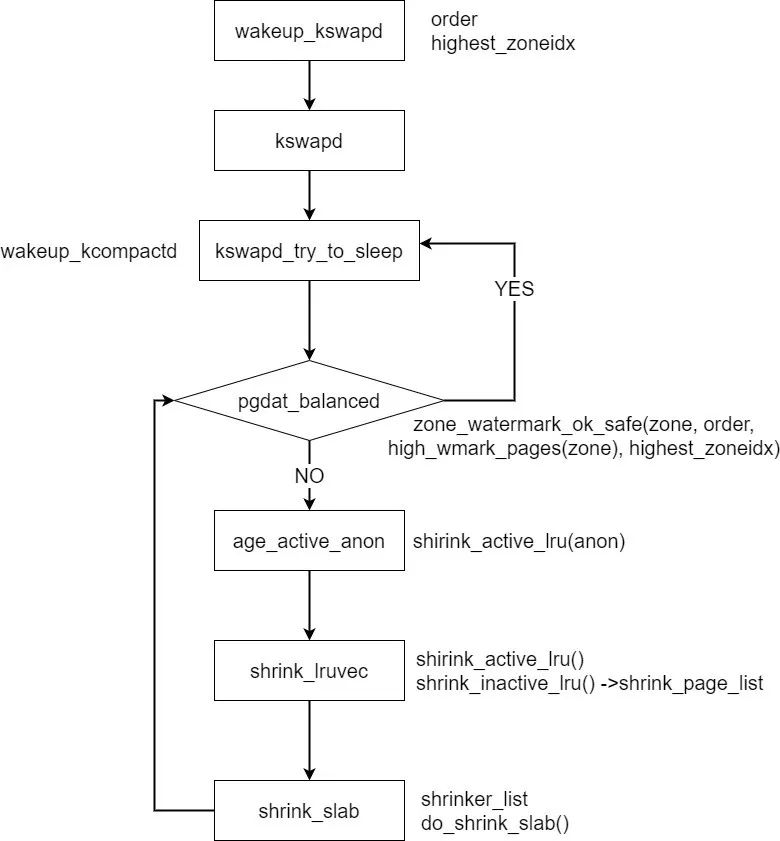
内存回收作为Linux kernel内存管理中比较复杂的部分,需要考虑各种场景,根据page的冷热状态,释放部分内存,满足其他进程的运行,kswapd担当了重要的工作,开源社区还在不断完善和优化中,最后通过⼀个流程图⼤概梳理⼀下kswapd的⼯作流程:
参考⽂献
1. 本⽂引⽤的和解读的代码都来⾃kernel-5.10.14
2. 《奔跑吧Linux内核》
3. 蜗窝科技http://www.wowotech.net/
扫码关注
“内核工匠”微信公众号
Linux 内核黑科技 | 技术文章 | 精选教程

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)