2.解决Linux中文乱码问题
我们从windows系统上传文件到Linux系统中,经常会遇到中文乱码问题。通常,这是因为Windows的字符编码为GBK,而Linux系统的字符集是UTF-8引起的。为了模拟上述情况,我先在Windows中,创建以GBK编码的文件testGBK.txt,然后上传至CentOS系统。最后,我将转换testGBK.txt的字符编码,解决乱码问题。一、创建testGBK.txt打开Notepad++,
·
我们从windows系统上传文件到Linux系统中,经常会遇到中文乱码问题。通常,这是因为Windows的字符编码为GBK,而Linux系统的字符集是UTF-8引起的。
为了模拟上述情况,我先在Windows中,创建以GBK编码的文件testGBK.txt,然后上传至CentOS系统。最后,我将转换testGBK.txt的字符编码,解决乱码问题。
一、创建testGBK.txt
打开Notepad++,随便写几行中文,然后指定为GBK编码,保存。然后上传至CentOS。
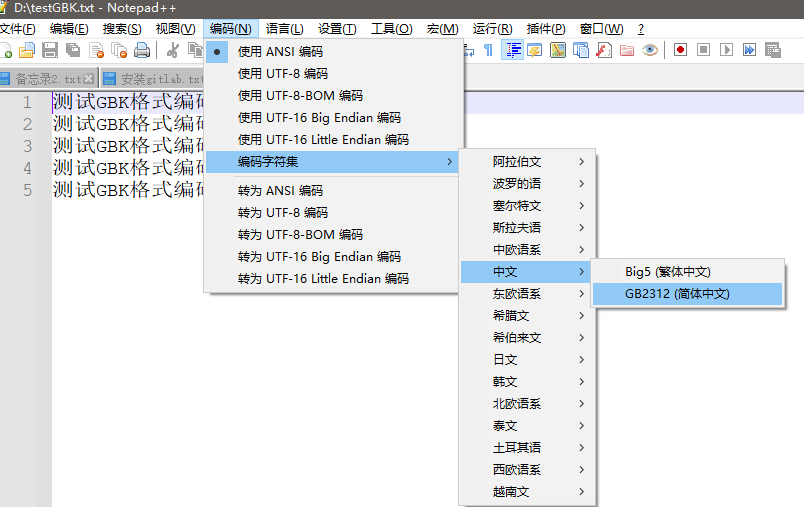
二、在CentOS中,testGBK.txt为乱码

并且,其文件编码已经是latin1,即ISO-8859编码。Latin1是ISO-8859-1的别名。使用file命令可以印证。

三、乱码产生的原因
之所以会有乱码问题,是因为文件的编码是GB2312,但在传输的过程中,因为传输工具用的字符编码是latin1,所以传输上去的文件已经被标识为latin1了。但testGBK.txt里面存放的却是GB2312编码的内容,而CentOS被告知是latin1编码,所以,CentOS就使用latin1的字符编码去解码,结果,当然是乱码。
四、解决乱码问题
使用iconv命令进行转码。具体如下:
#将GB2312的文件testGBK.txt转编码为UTF-8,并输出为:result1.txt
iconv -f GB2312 -t UTF-8 testGBK.txt -o result1.txt
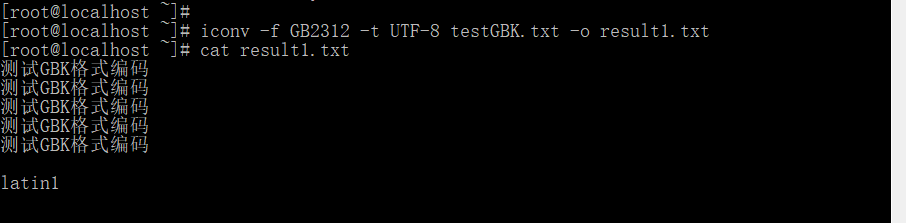
结论:经过转码后,已经无乱码。

五、iconv的用法
用法: iconv [选项...] [文件...]
Convert encoding of given files from one encoding to another.
输入/输出格式规范:
-f, --from-code=NAME 原始文本编码
-t, --to-code=NAME 输出编码
信息:
-l, --list 列举所有已知的字符集
输出控制:
-c 从输出中忽略无效的字符
-o, --output=FILE 输出文件
-s, --silent suppress warnings
--verbose 打印进度信息
-?, --help 给出该系统求助列表
--usage 给出简要的用法信息
-V, --version 打印程序版本号
将GB2312编码的文件内容转换为UTF-8
iconv -f GB2312 -t UTF-8 file-name > new-file-name
将UTF-8编码的文件内容转换为GB2312
iconv -f UTF-8 -t GB2312 file-name > new-file-name
NOTE:
1.原始文本编码:指的是文本真实的编码,而不是Linux系统误认定的字符编码。如上例,file命令显示,testGBK.txt是ISO-8859编码,即西欧编码。但,文件真实的字符编码是GB2312,详见图1.
2.在做文件转码时,对重要的文件,需要做好备份工作。文件转码,有时候,是不可逆的。备份尤为重要。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)