【paddleocr】paddleocr服务端部署(CPU版)
paddleocr基于hubserving服务端部署实践。CPU版
最近在折腾使用paddle识别繁体中文,记录一下基于官网hubserving进行服务端部署。
前期准备
- paddleocr 的git仓库先clone下来,后续的操作基本都基于此。
git clone git@github.com:PaddlePaddle/PaddleOCR.git
- 准备我们训练好的推理文件,也可以直接从官网下载:官网模型
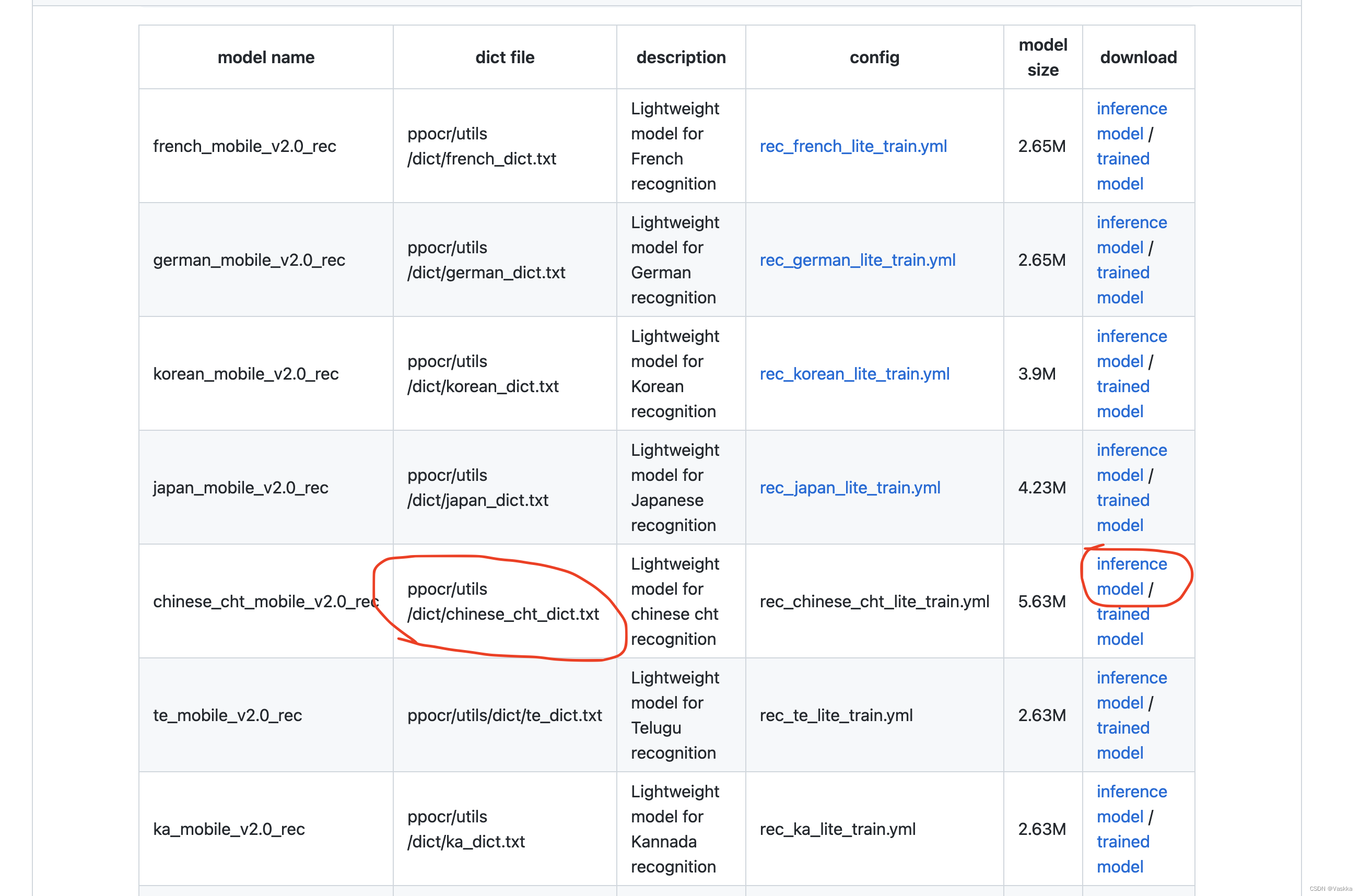 红框中的是我们后面会用到的信息。inference_model的链接是官方推理model,下载下来。
红框中的是我们后面会用到的信息。inference_model的链接是官方推理model,下载下来。
下载后解压后理论上有三个文件:
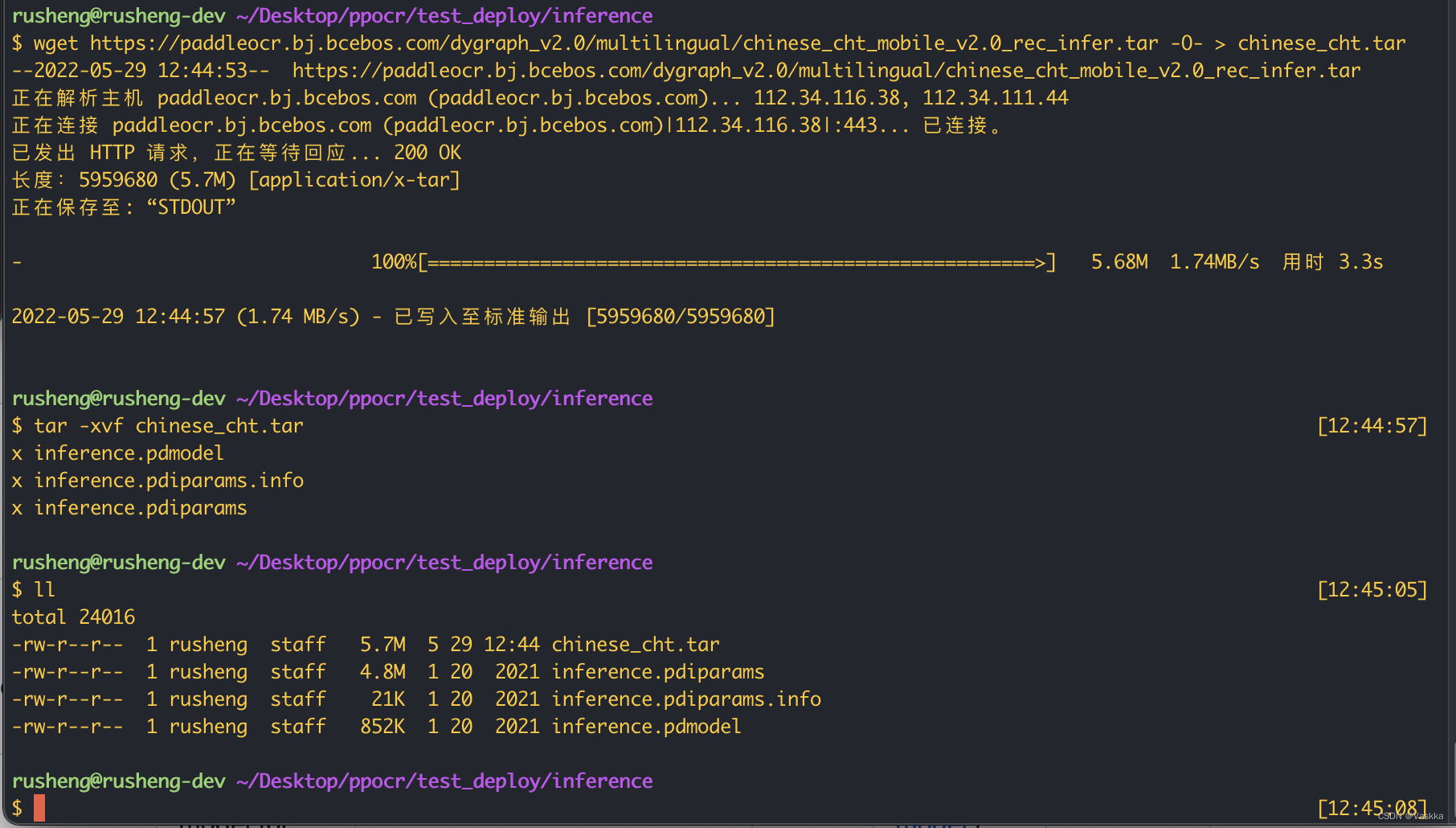 我们可以直接放在刚clone下来的paddleOCR的仓库目录下,这里我模型最终的位置:
我们可以直接放在刚clone下来的paddleOCR的仓库目录下,这里我模型最终的位置:./inference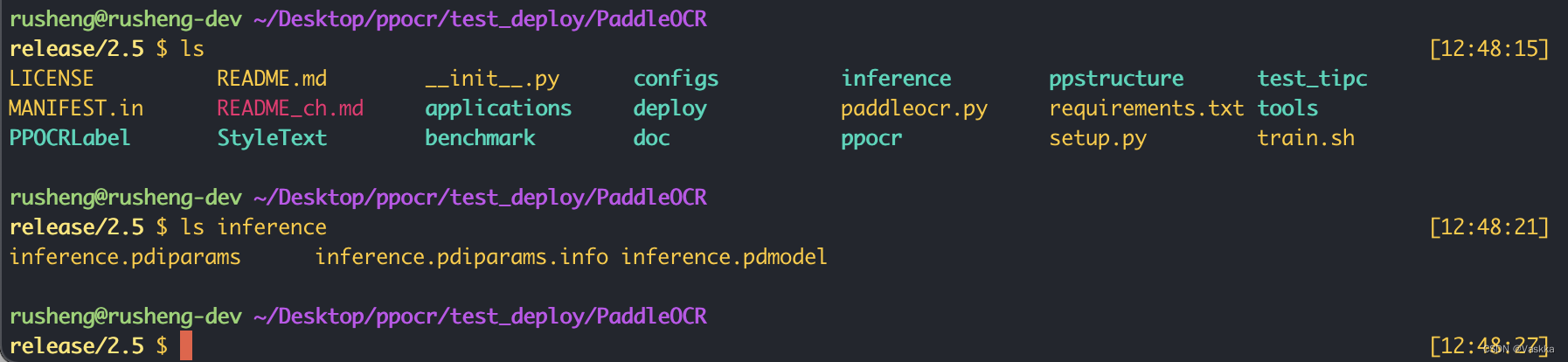
hubserving部署配置修改
官方已经为我们准备好了相关脚手架,在./deploy/hubserving文件夹中。我们以识别场景为例记录如何部署。
进入./deploy/hubserving/ocr_rec我们有一些配置文件要修改。

建议checkout到新分支修改,容易恢复。这里方便演示直接在release2.5的发布分支修改了。
先是指定模型版本,在module.py文件中,可以指定本次部署模型的名字和版本,这里我们不变用默认的名字ocr_rec和版本1.0.0
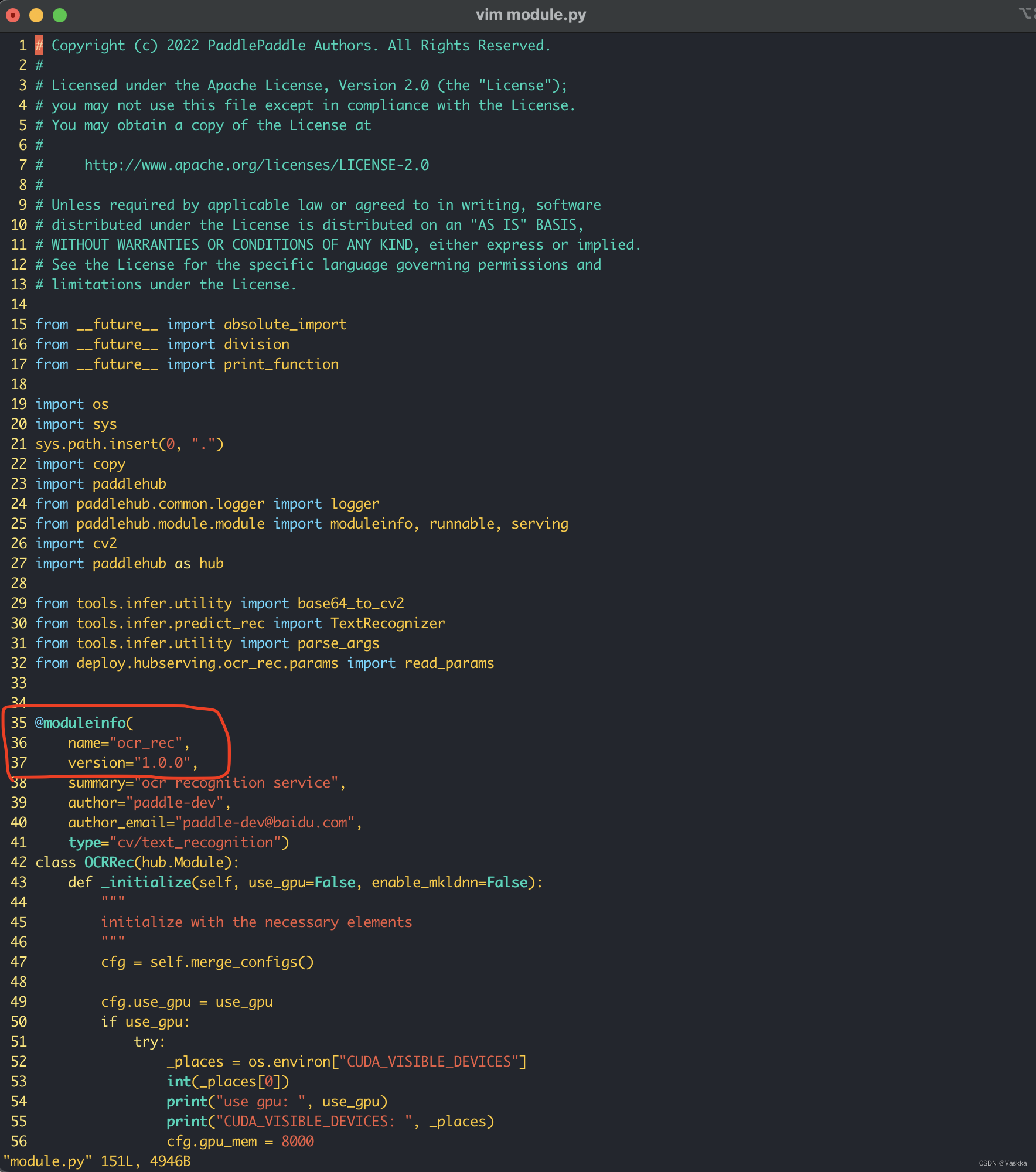 接着修改
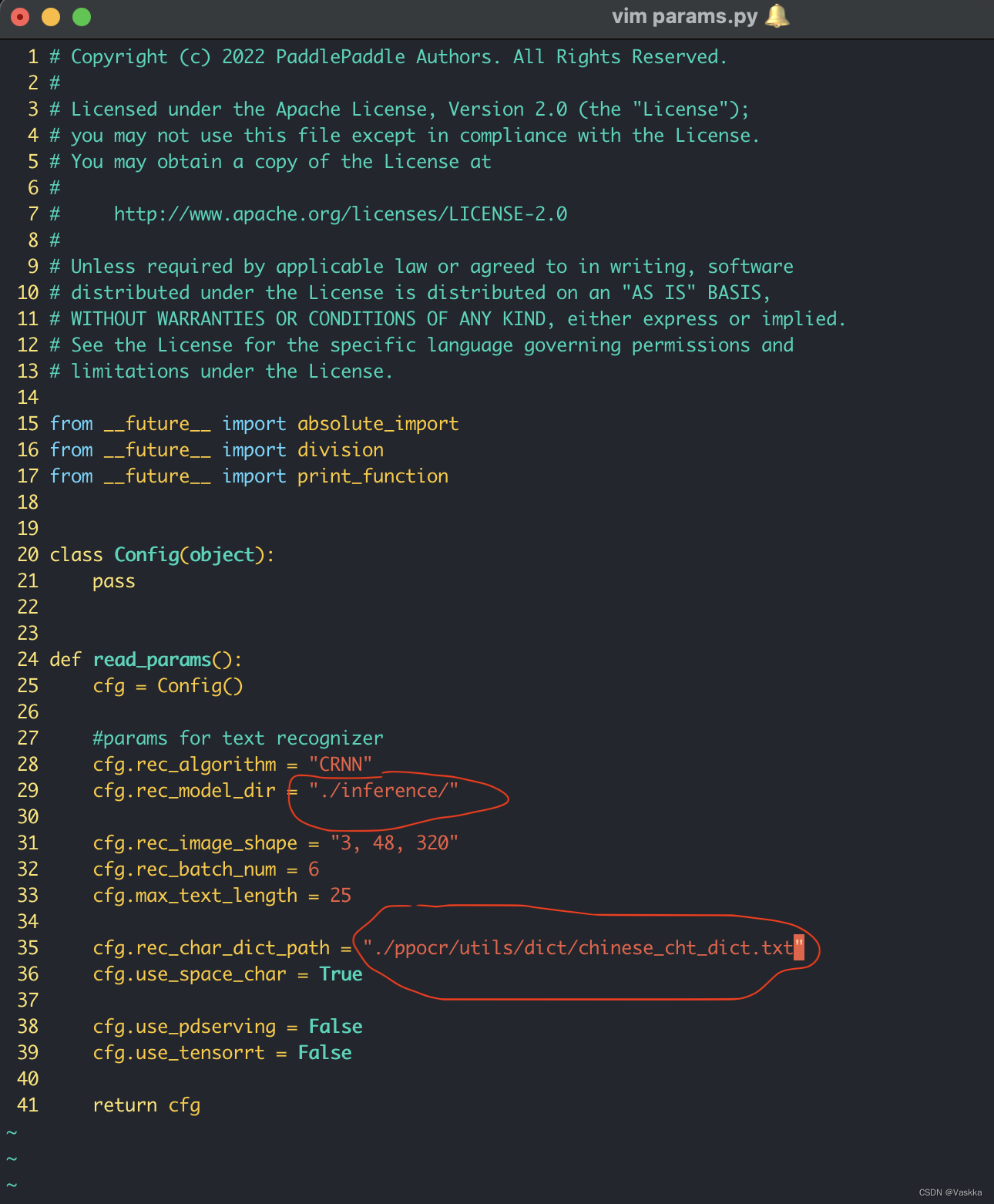
接着修改params.py,指定好推理文件的位置和字典的位置,填入前期准备红圈圈住的信息。
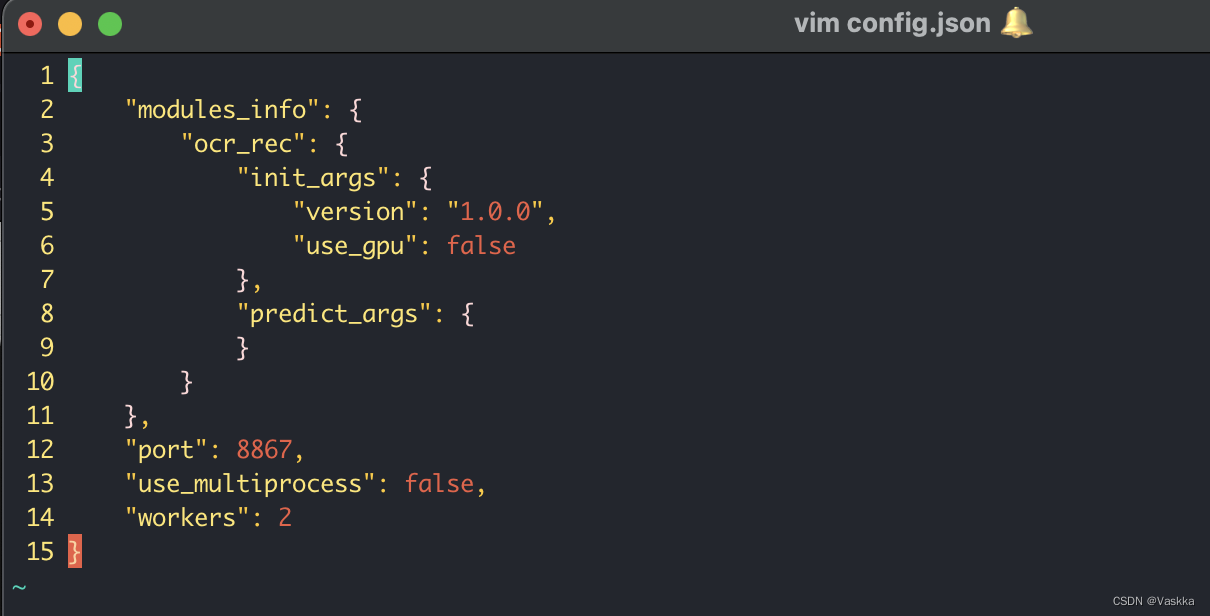
 最后修改config.json,我们基于cpu,这里把use_gpu置为false。也可以指定是否多核处理和指定子进程数,这里暂时不变。
最后修改config.json,我们基于cpu,这里把use_gpu置为false。也可以指定是否多核处理和指定子进程数,这里暂时不变。
基于hubserving运行、测试
我们先安装hubserving,基于pip:
# 安装paddlehub
# paddlehub 需要 python>3.6.2
pip3 install paddlehub==2.1.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
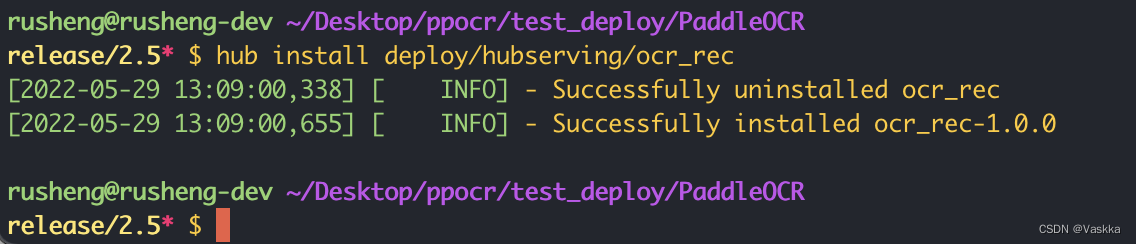
完成上面步骤的配置,***我们回到git仓库的根目录***,执行下面命令安装:
hub install deploy/hubserving/ocr_rec
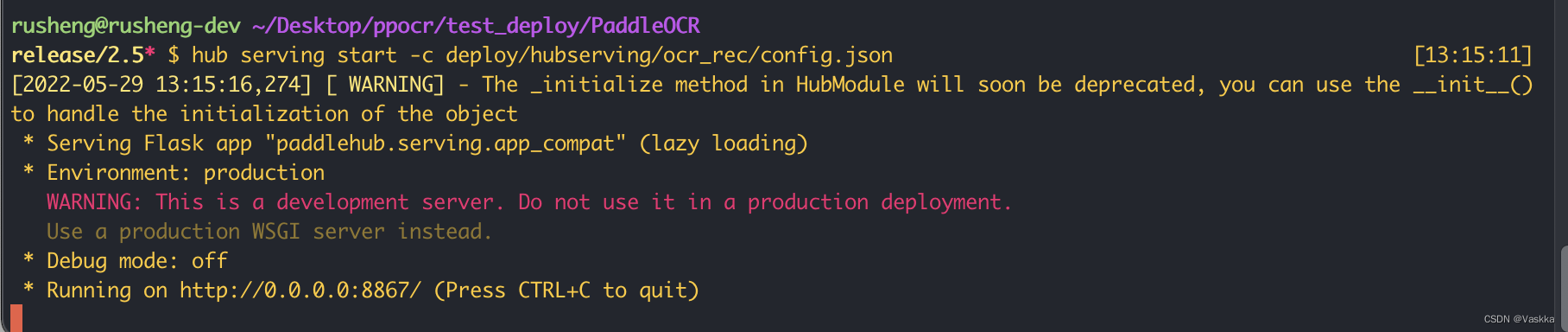
 没有报错我们就可以运行server端了,hubserving会启动一个http服务在我们指定的端口(config.json),执行下面命令:
没有报错我们就可以运行server端了,hubserving会启动一个http服务在我们指定的端口(config.json),执行下面命令:
hub serving start -c deploy/hubserving/ocr_rec/config.json
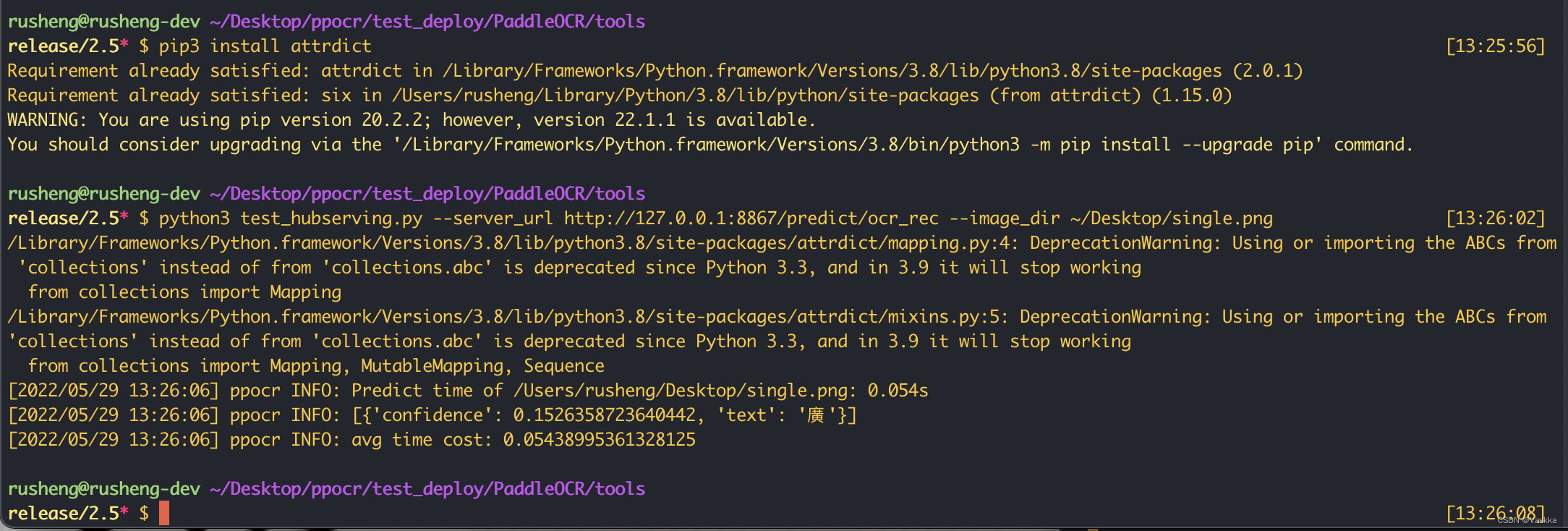
顺利的话会看到服务端已经成功启动了。我们接下来测试一下,客户端demo官方也提供了,位置在./tools/test_hubserving.py 我这里准备了一张繁体字的图片,测试一下效果:
这里发现release/2.5分支的test_hubserving.py运行可能会报错No module named ‘attrdict’,我们可以安装一下
pip3 install attrdict
python3 test_hubserving.py --server_url http://127.0.0.1:8867/predict/ocr_rec --image_dir ~/Desktop/single.png
~/Desktop/single.png 是我们的图片路径

 看test_hubserving.py的实现可以发现本质是发了POST请求,因此可以比较容易的集成到其他系统中。
看test_hubserving.py的实现可以发现本质是发了POST请求,因此可以比较容易的集成到其他系统中。
参考
其他
从hubserving启动的输出可以发现本质是flask,能否直接用于生产环境可能还需要评估。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)