运维面试和笔试常见问题
面试问题线上有遇到什么故障?带宽资源耗尽 阿里云监控平台->iftop->ss->ps>程序->查看日志磁盘容量不足内存容量不足进行rsync+sersync数据同步导致内存不足ip冲突,导致设备连接不上服务器selinux临时关闭,重启后,导致nginx起不来ssl证书失效,导致小程序和app应用资源请求失败nginx算法策略轮询、加权轮询、ip_hashnignx
运维全靠百度,面试一问不知,笔试填空全留空,还是要多刷题
总结一下最近碰到的面试问题和笔试问题
面试问题
线上有遇到什么故障?
带宽资源耗尽 阿里云监控平台->iftop->ss->ps>程序->查看日志
磁盘容量不足
内存容量不足
进行rsync+sersync数据同步导致内存不足
ip冲突,导致设备连接不上服务器
selinux临时关闭,重启后,导致nginx起不来
ssl证书失效,导致小程序和app应用资源请求失败
nginx算法策略
轮询(默认)
加权轮询(轮询+weight)
ip_hash
每一个请求的访问IP,都会映射成一个hash,再通过hash算法(hash值%node_count),分配到不同的后端服务器,访问ip相同的请求会固定访问同一个后端服务器,这样可以做到会话保持,解决session同步问题。
least_conn(最少连接)
使用最少连接的负载平衡,nginx将尝试不会使繁忙的应用程序服务器超载请求过多,而是将新请求分发给不太繁忙的服务器。
nignx常用模块
upstream
rewrite
location
proxy_pass
数据库类
MySQL
mysql主从同步的原理
在master机器上,主从同步事件会被写到特殊的log文件中(binary-log);在slave机器上,slave读取主从同步事件,并根据读取的事件变化,在slave库上做相应的更改。
mysql主从的搭建大概过程
1.master启用binlog
log-bin=mysql-bin 2.master创建一个slave同步权限账号
grant replication slave,replication client on *.* to repl@'192.168.0.%' identified by "repl123";
flush privileges;3.slave配置主从复制
change master to master_host='192.168.0.103',master_user='repl',master_password='repl123',master_log_file='mysql-bin.000007',master_log_pos=120;4.启动主从同步
start slave;mysql主备高可用集群
双master+keepalive+slave只读
mysql主从延迟问题
如果延迟比较大,就先确认以下几个因素:
1.硬件问题:从库硬件比主库差,导致复制延迟
2.主从复制单线程,如果主库写并发太大,来不及传送到从库就会导致延迟。更高版本的mysql可以支持多线程复制
3.慢SQL语句过多
4.网络问题:网络延迟
MySQL数据库主从同步延迟解决方案
1.读写分离,主库的DDL快速执行,从库只读
2.还有就是主库是写,对数据安全性较高,比如sync_binlog=1,innodb_flush_log_at_trx_commit
= 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog
innodb_flushlog也可以设置为0来提高sql的执行效率。另外就是使用比主库更好的硬件设备作为slave
redis持久化和集群问题
redis持久化: rdb和aof
rdb:在指定的时间间隔内将内存中的数据集快照写入磁盘,数据量大时恢复比较快
aof:redis每次接收到一条写命令,就会写入日志文件中,aof数据恢复比较完整
生产环境可以同时开rdb和aof,然后根据实际情况,选择一个恢复数据。
域名解析流程
迭代查询
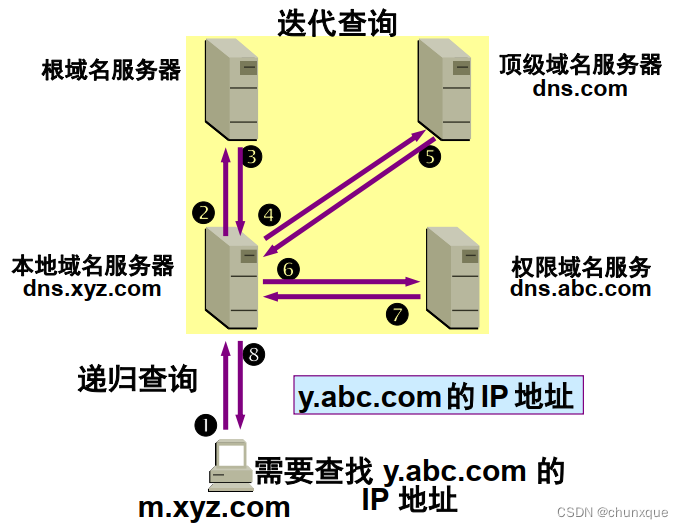
我们以中科三方的官网http://www.sfn.cn为例进行讲解,当我们在地址栏输入该域名之后,会发生以下这些步骤。
第一步:检查浏览器缓存中是否缓存过该域名对应的IP地址
如果用户之前浏览过该网站,浏览器会自动缓存该域名对应的IP地址,当用户再次访问时,如果缓存的时间尚未到期,浏览器会从缓存中查找对应的IP地址,整个域名解析过程结束。
如果没有找到对应IP,或者缓存时间已经到期,那么就会进行下一步骤。
第二步:如果在浏览器缓存中没有找到IP,那么将继续查找本机系统是否缓存过IP
除浏览器外,系统自身也具备域名解析的基本能力。如果在浏览器中没有查找到对应IP,就会继续查找本机系统是否缓存过IP。在Windows系统中,可以通过设置hosts文件来将域名手动绑定到某IP上,hosts文件位置在C:\Windows\System32\drivers\etc\hosts。
第三步:向本地域名解析服务系统发起域名解析的请求
如果在本机中无法获取对应的IP,那么系统就只能请求本地域名解析服务系统进行解析,本地域名系统LDNS(local DNS: 本地DNS服务器)一般都是本地区的域名服务器,比如你连接的校园网,那么域名解析系统就在你的校园机房里。LDNS一般都缓存了大部分的域名解析的结果,当然LDNS也存在缓存有效时间,大部分的解析工作到这里就差不多已经结束了,LDNS负责了大部分的解析工作。
第四步:向根域名解析服务器发起域名解析请求
如果在LDNS中无法完成解析,那么LDNS就会向根域名服务器发起解析请求。
第五步:根域名服务器返回gTLD域名解析服务器地址
本地DNS域名解析向根域名服务器发起解析请求后,根域名解析服务器返回的是所查域名的通用顶级域(gTLD)地址。
第六步:本地域名解析服务器向gTLD发起解析请求。
第七步:gTLD服务器接收本地域名服务器的请求后,找到被解析域名对应的Name Sever域名服务器,一般情况下也就是该域名注册时对应的解析服务器,此时注册域名服务商的解析服务器就会承担起域名解析的任务。
第八步:Name Server服务器查找域名对应的IP地址,将IP地址和TTL值返回给本地域名服务器。
第九步:本地域名服务器缓存解析后的结果,缓存时间由TTL时间来控制。
第十步:解析结果将直接返回给用户,用户系统将缓存该IP地址,缓存时间由TTL来控制,至此,解析过程结束。
linux系统
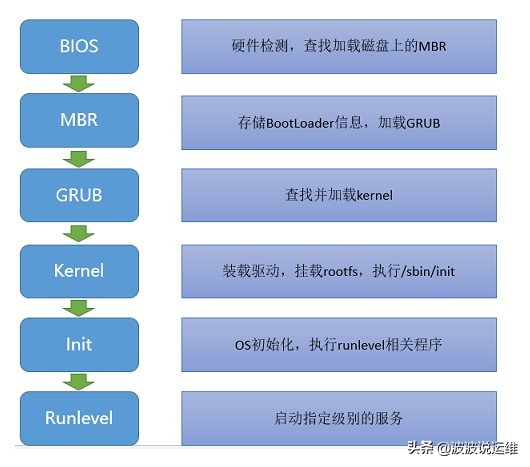
请描述一个linux系统的开机流程
整个过程基本可以分为POST-->BIOS-->MBR(GRUB)-->Kernel-->Init-->Runlevel。下面会详细说明每个过程的作用。
让linux系统中的某个服务开机自启的方法有哪些
1. 在/etc/rc.d/rc.local中写入运行程序的命令
2. 在/usr/lib/systemd/system/**.service 添加service服务,然后使用systemctl enable **
笔试问题
linux类
查看目录大小并按从大到小排序
du -sh * | sort -nr获取nginx access.log中的访问ip,进行统计分类,显示统计的数量和对应的ip,按数量多到少排序,仅显示top10
awk '{print$1}' access.log-20220822 | uniq -c | sort -nr | head -n 10只查询/etc/passwd文件的第5行到第10行(请用三种办法实现)
head -n 10 /etc/passwd | tail -n 5
sed -n '5,10p' /etc/passwd
awk 'NR>=5&&NR<=10' /etc/passwd
查询/etc/passwd文件的内容包含root的行(至少三种方法)
grep root /etc/passwd
sed -n '/root/p' /etc/passwd
awk '{if($0~"root") print$0}' /etc/passwd打印/etc/passwd的行号以及内容(至少两种)
awk '{print NR,$0}' /etc/passwd
cat -n /etc/passwd使用sed 把文件test.txt第20行的test替换为testdb
sed -i '20s/test/testdb' test.txt从etho网卡中捕获ip为192.168.1.2,tcp协议,端口为80的数据包
tcpdump -i eth0 tcp port 80 host 192.168.1.2 -w dm.capiptables和firewall分别开放80端口
#iptables
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
# firewall
firewall-cmd --zone=public --add-port=80/tcp --permanent
firewall-cmd --reload以下centos系统配置文件文件的作用
/var/log/messages #系统的日志信息文件
/var/log/secure #记录服务器登陆行为的文件
/var/spool/cron/root #root用户的定时任务文件
/usr/lib/systemd/system # 系统服务的目录
/etc/fstab # 开机自动挂载文件
/etc/rc.d/rc.local # 开机自启文件,里面可以添加要自启动的shell指令
绝对路径打包yum缓存文件目录 /var/cache/yum/ 以便给其它服务器使用,请写出在本机打包命令及在其它服务器解包命令
tar zcfP yum.tar.gz /var/cache/yum
tar xfP yum.tar.gz将 /var/log/目录下所有7天前并且以log结尾的文件,文件的大小超过1M,移动到/tmp/log/文件内,深度为1即可
find /var/log/ -maxdepth 1 -mtime +7 -size +1M -type f -name "*.log" -exec mv {} /tmp/log/ \;Redmat中,dns配置文件与内容
[root@master tmp]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 8.8.8.8
centos系统中,请用linux命令取出ens192中ip地址,至少三种方法(grep,awk,sed)
ip a|grep ens192 |grep inet | awk '{print $2}' | awk -F / '{print $1}'
ip a|grep ens192 |grep inet | cut -d " " -f 6 |cut -d "/" -f 1
ip a |sed -n '/ens192/p' | sed -n '/inet/p' |sed 's/^.*inet//g' |sed 's/\/.*$//g' |sed 's/ //g'把nignx.conf.default中的带#行和空行都去掉,剩下的内容保存到nginx.conf
cat nginx.conf.default |grep -v '^$' |grep -v '^#' >nginx.conf添加一个用户mysql,禁止用户登录,不创建用户目录
useradd -M -s /sbin/nologin mysql添加一个UID为888的虚拟用户mysql
useradd -M -s /sbin/nologin -u 888 mysql说明软件链接的区别
如何创建
含义
特点
写一个ansible拷贝文件的命令
ansible hostgroup -m copy -a "src=/root/test1.sh dest=/tmp/"如何监控PHP的状态
#启用pm.status_path
pm.status_path = /status
#http访问/status检查状态
curl 127.0.0.1/status -s请简要说明一下WAIT_TIME是如何产生的,出现大量的WAIT_TIME如何解决?
产生:
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上。在这种场景下,主动正常关闭TCP连接,都会出现TIMEWAIT
解决:
编辑内核文件/etc/sysctl.conf,加入以下内容:
net.ipv4.tcp_syncookies =1 #表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse=1 #表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为O,表示关闭;
net.ipv4.tcp_tw_recycle=1 #表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为O,表示关闭。
net.ipv4.tcp_fin_timeout=30 #修改系默认的TIMEOUT时间然后执行/sbin/sysctl -p让参数生效.
数据库类
mysql 如何导出数据库test-db中test-table表
# mysqldump -u 用户名 -p 数据库名表名> 导出的文件名
mysqldump -u root -p test test-db test-table> test_users.sql
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)