哈工大操作系统系统调用实验二
文章目录前言一、实验内容二、系统调用三、内核中断处理 INT 80四、实现 sys_iam() 和 sys_whoami()五、开始实验1.增加系统调用号2.增加系统调用数3.函数调用表修改4.系统调用函数5.修改MakeFile6.编写应用程序7.运行和测试总结前言本次实验建立在前一个实验上,但是,请将 Linux 0.11 的源代码恢复到原始状态提示:以下是本篇文章正文内容一、实验内容此次实验
文章目录
前言
本次实验建立在前一个实验上,但是,请将 Linux 0.11 的源代码恢复到原始状态
提示:以下是本篇文章正文内容
一、实验内容
此次实验的基本内容是:在 Linux 0.11 上添加两个系统调用,并编写两个简单的应用程序测试它们。
(1)iam()
第一个系统调用是 iam(),其原型为:
int iam(const char * name);
完成的功能是将字符串参数 name 的内容拷贝到内核中保存下来。要求 name 的长度不能超过 23 个字符。返回值是拷贝的字符数。如果 name 的字符个数超过了 23,则返回 “-1”,并置 errno 为 EINVAL
在 kernal/who.c 中实现此系统调用
(2)whoami()
第二个系统调用是 whoami(),其原型为:
int whoami(char* name, unsigned int size);
它将内核中由 iam() 保存的名字拷贝到 name 指向的用户地址空间中 并且printf出来,同时确保不会对 name 越界访存(name 的大小由 size 说明)。返回值是拷贝的字符数。如果 size 小于需要的空间,则返回“-1”,并置 errno 为 EINVAL。
也是在 kernal/who.c 中实现。
(3)测试程序
运行添加过新系统调用的 Linux 0.11,在其环境下编写两个测试程序 iam.c 和 whoami.c。最终的运行结果是:
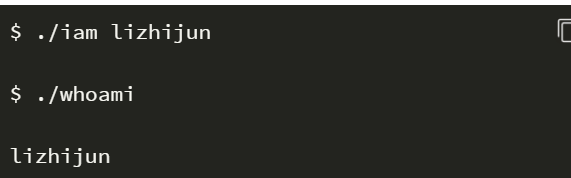
二、系统调用
在通常情况下,调用系统调用和调用一个普通的自定义函数在代码上并没有什么区别,但调用后发生的事情有很大不同。
调用自定义函数是通过 call 指令直接跳转到该函数的地址,继续运行。
而调用系统调用,是调用系统库中为该系统调用编写的一个接口函数,叫 API(Application Programming Interface)。API 并不能完成系统调用的真正功能,它要做的是去调用真正的系统调用,过程是:
1.把系统调用的编号存入 EAX;
2.把函数参数存入其它通用寄存器;
3.触发 0x80 号中断(int 0x80)
linux-0.11 的 lib 目录下有一些已经实现的 API。Linus 编写它们的原因是在内核加载完毕后,会切换到用户模式下,做一些初始化工作,然后启动 shell。而用户模式下的很多工作需要依赖一些系统调用才能完成,因此在内核中实现了这些系统调用的 API
在 lib/close.c,研究一下 close() 的 API:
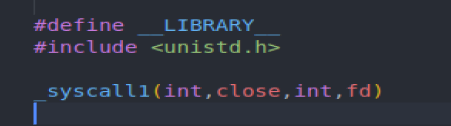
其中 _syscall1 是一个宏,内联汇编,在 include/unistd.h 中定义
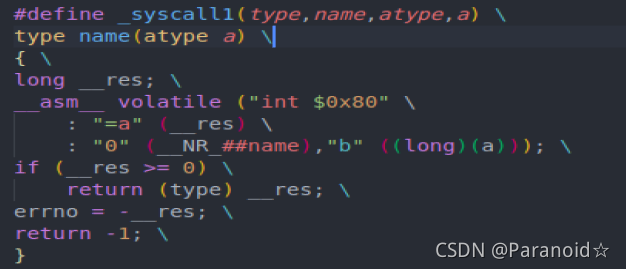
将 _syscall1(int,close,int,fd) 进行宏展开,可以得到:
int close(int fd)
{
long __res;
__asm__ volatile ("int $0x80"
: "=a" (__res)
: "0" (__NR_close),"b" ((long)(fd)));
if (__res >= 0)
return (int) __res;
errno = -__res;
return -1;
}
这就是 API 的定义。它先将宏 __NR_close 存入 EAX,将参数 fd 存入 EBX,然后进行 0x80 中断调用。调用返回后,从 EAX 取出返回值,存入 __res,再通过对 __res 的判断决定传给 API 的调用者什么样的返回值
具体是执行过程,可以看我这篇笔记:
系统调用具体实现
其中 __NR_close 就是系统调用的编号,在 include/unistd.h 中定义
#define __NR_close 6
所以添加系统调用时需要修改include/unistd.h文件,使其包含__NR_whoami和__NR_iam。
/* iam()在用户空间的接口函数 */
_syscall1(int, iam, const char*, name);
/* whoami()在用户空间的接口函数 */
_syscall2(int, whoami,char*,name,unsigned int,size);
在 0.11 环境下编译 C 程序,包含的头文件都在 /usr/include 目录下
该目录下的 unistd.h 是标准头文件(它和 0.11 源码树中的 unistd.h 并不是同一个文件,虽然内容可能相同),没有 __NR_whoami 和 __NR_iam 两个宏,需要手工加上它们,也可以直接从修改过的 0.11 源码树中拷贝新的 unistd.h 过来。
三、内核中断处理 INT 80
在内核初始化时,主函数(在 init/main.c 中,Linux 实验环境下是 main(),调用了 sched_init() 初始化函数:
void main(void)
{
// ……
time_init();
sched_init();
buffer_init(buffer_memory_end);
// ……
}
sched_init() 在 kernel/sched.c 中定义为:
void sched_init(void)
{
// ……
set_system_gate(0x80,&system_call);
}
set_system_gate 是个宏,在 include/asm/system.h 中定义为:
#define set_system_gate(n,addr) \
_set_gate(&idt[n],15,3,addr)
_set_gate 的定义是:
#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
"o" (*((char *) (gate_addr))), \
"o" (*(4+(char *) (gate_addr))), \
"d" ((char *) (addr)),"a" (0x00080000))
上面这些其实都是为了填写 IDT(中断描述符表),将 system_call 函数地址写到 0x80 对应的中断描述符中,也就是在中断 0x80 发生后,自动调用函数 system_call
定义在 kernel/system_call.s 中:system_call
!……
! # 这是系统调用总数。如果增删了系统调用,必须做相应修改
nr_system_calls = 72
!……
.globl system_call
.align 2
system_call:
! # 检查系统调用编号是否在合法范围内
cmpl \$nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx
! # push %ebx,%ecx,%edx,是传递给系统调用的参数
pushl %ebx
! # 让ds, es指向GDT,内核地址空间
movl $0x10,%edx
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx
! # 让fs指向LDT,用户地址空间
mov %dx,%fs
call sys_call_table(,%eax,4)
pushl %eax
movl current,%eax
cmpl $0,state(%eax)
jne reschedule
cmpl $0,counter(%eax)
je reschedule
system_call 用 .globl 修饰为其他函数可见。
call sys_call_table(,%eax,4) 之前是一些压栈保护,修改段选择子为内核段,call sys_call_table(,%eax,4) 之后是看看是否需要重新调度,这些都与本实验没有直接关系,此处只关心 call sys_call_table(,%eax,4) 这一句。
根据汇编寻址方法它实际上是:call sys_call_table + 4 * %eax,其中 eax 中放的是系统调用号,即 __NR_xxxxxx
sys_call_table 是一个函数指针数组的起始地址,它定义在 include/linux/sys.h 中:
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,...
增加实验要求的系统调用,需要在这个函数表中增加两个函数引用 ——sys_iam 和 sys_whoami。该函数在 sys_call_table 数组中的位置必须和 __NR_xxxxxx 的值对应上
同时还要仿照此文件中前面各个系统调用的写法,加上:
extern int sys_whoami();
extern int sys_iam();
不然,编译会出错的
四、实现 sys_iam() 和 sys_whoami()
添加系统调用的最后一步,是在内核中实现函数 sys_iam() 和 sys_whoami()。
每个系统调用都有一个 sys_xxxxxx() 与之对应,它们都是我们学习和模仿的好对象。
比如在 fs/open.c 中的 sys_close(int fd):
int sys_close(unsigned int fd)
{
// ……
return (0);
}
它没有什么特别的,都是实实在在地做 close() 该做的事情。
所以只要自己创建一个文件:kernel/who.c,然后实现两个函数
五、开始实验
上面大大小小的介绍了这么多,对实验有了一定的了解,这里正式开始。
1.增加系统调用号
在 oslab/linux-0.11/include/unistd.h中:添加这个系统调用号
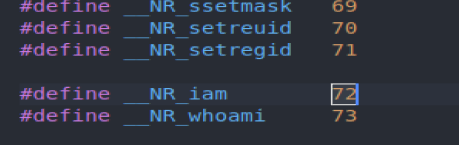
还需要再虚拟机中的 /usr/include/unistd.h 中修改
文件查找:
文件修改:
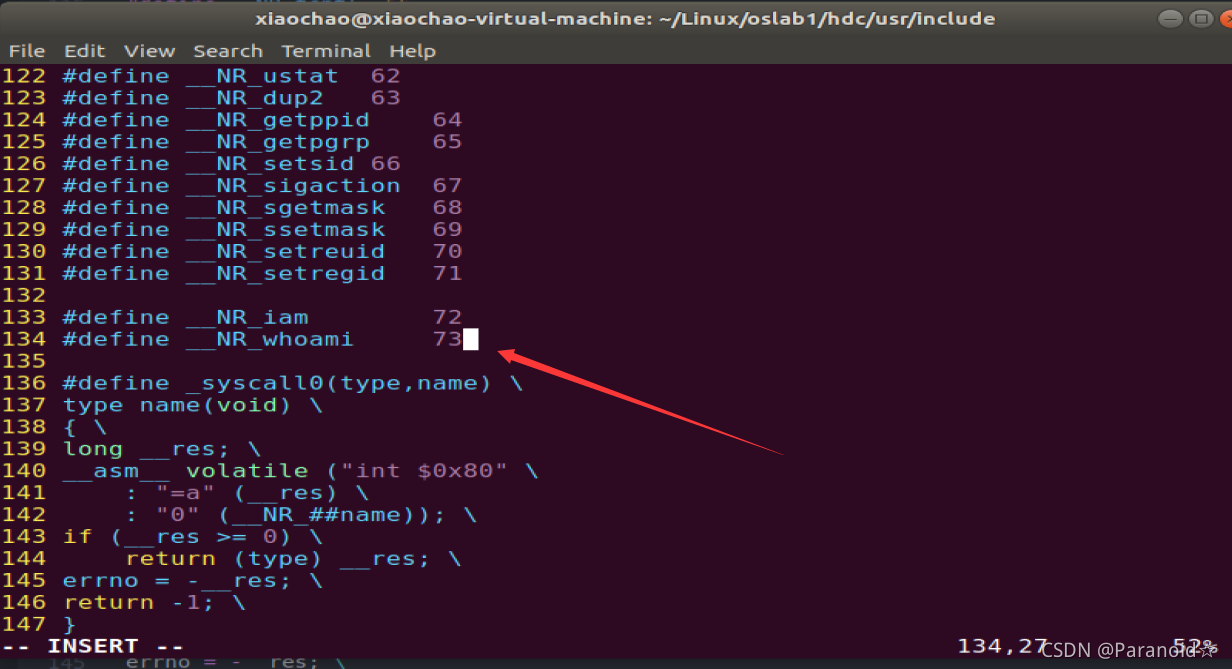
2.增加系统调用数
文件名 system_call.s 路径 oslab/linux-0.11/kernel/system_call.s
之前默认的系统调用数是 72 ,增加了sys_iam sys_whoami调用 就需要增加两个

3.函数调用表修改
文件名 sys.h 路径 include/linux/sys.h
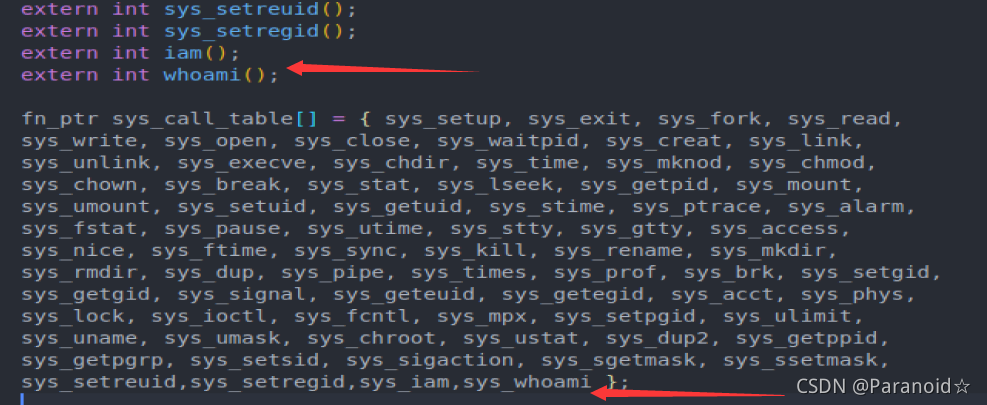
这两个部分都有添加
上面已经为两个系统调用分配空间,并表明了会在其他的文件中使用这两个系统调用函数,其他文件就是who.c,在sys.h中的sys_call_table其实就是一个数组名(首元素的地址)
4.系统调用函数
在linux-0.11\kernel中新建一个文件并命名为who.c
#include <string.h> //memset
#include <errno.h> //errno 实验册上面说要用
//get_fs_byte put_fs_byte要用 这两个函数是穿越内核区和外核区数据访问关键
#include <asm/segment.h>
char msg[24];//内核区保存我们的字符串的全局变量
int sys_iam(const char* name)
{
int count = 0;
errno = 0;//初始化
char temp;
memset(msg,'\0',sizeof(msg));//置0
while((temp = get_fs_byte(name+count)) != '\0')
{
if(count >= 23){errno = EINVAL;break;}//修改EINVAL状态
msg[count++] = temp;
}
//注意这里为什么return -(EINVAL) 呢
//因为linux 系统返回整数及0的时候意味着正常访问
//而返回负数表示错误访问 此时我们返回错误值是正的错误码加个符号
//他就会再进一步检测错误类型
return (errno == EINVAL) ? -(EINVAL) : count;
}
int sys_whoami(char* pos,unsigned int size)
{
errno = 0;
int len = strlen(msg),i;
if(len > size){errno = EINVAL;return -(EINVAL);}
for(i=0;i<len;++i) put_fs_byte(msg[i],pos+i);
return len;
}
要把用户态地址name处的字符串传入核心态,name是一个指针,那么是不能直接用 * name代表name指向的字符串的,因为指针传递的是应用程序所在地址空间的逻辑地址,在内核中如果直接访问这个地址,访问到的是内核空间中的数据,不会是用户空间的。
所以这里需要通过get_fs_byte()和put_fs_byte()函数来实现用户态与核心态数据的交换。其中get_fs_byte()函数的参数是用户空间的逻辑地址,返回值是该地址处的一个字符的内容;其中put_fs_byte()函数的功能是向用户空间中地址处写一个字节的内容,有两个参数,第一个参数是要写入的数据,第二个参数是用户空间中的逻辑地址
5.修改MakeFile
要想让我们添加的 kernel/who.c 可以和其它 Linux 代码编译链接到一起,必须要修改 Makefile 文件,Makefile 里记录的是所有源程序文件的编译、链接规则,
Makefile 在代码树中有很多,分别负责不同模块的编译工作。我们要修改的是 kernel/Makefile。需要修改两处
(1)第一处
OBJS = sched.o system_call.o traps.o asm.o fork.o \
panic.o printk.o vsprintf.o sys.o exit.o \
signal.o mktime.o
改为:

这就把 who.o添加了
(2)第二处
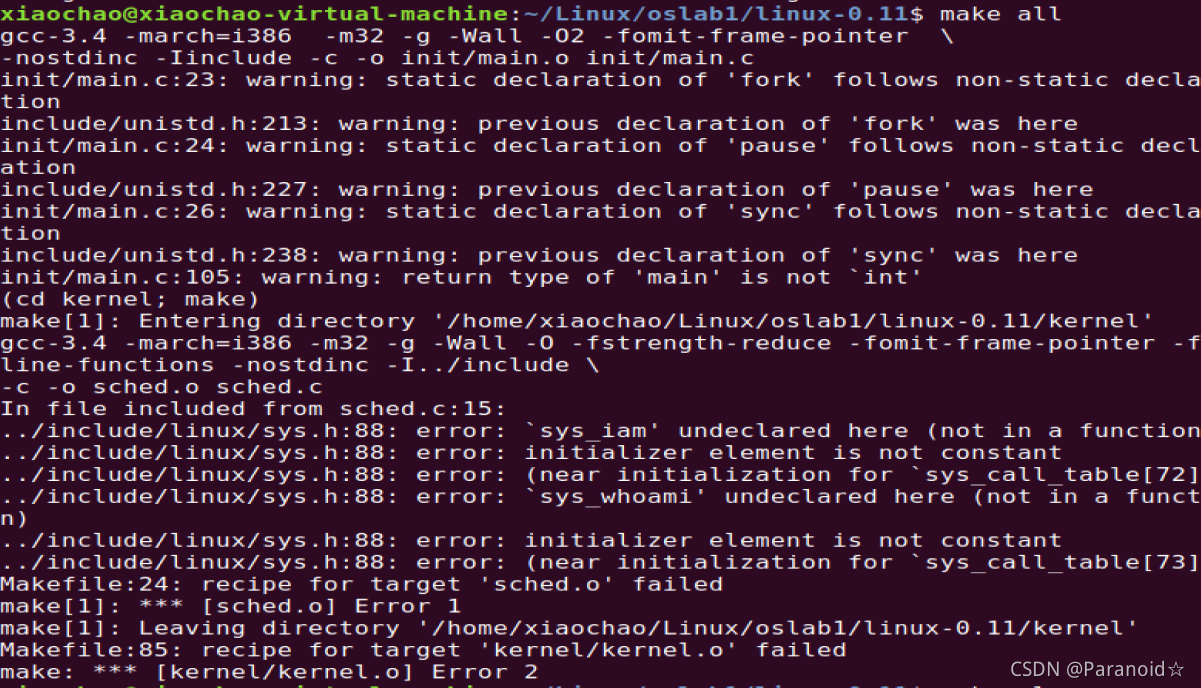
### Dependencies:
exit.s exit.o: exit.c ../include/errno.h ../include/signal.h \
../include/sys/types.h ../include/sys/wait.h ../include/linux/sched.h \
../include/linux/head.h ../include/linux/fs.h ../include/linux/mm.h \
../include/linux/kernel.h ../include/linux/tty.h ../include/termios.h \
../include/asm/segment.h
改为:
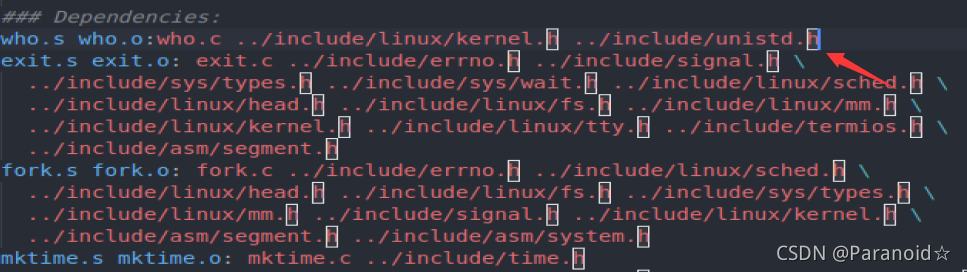
who.s who.o: who.c ../include/linux/kernel.h ../include/unistd.h
Makefile 修改后,和往常一样 make all 就能自动把 who.c 加入到内核中了。
如果编译时提示 who.c 有错误,就说明修改生效了。所以,有意或无意地制造一两个错误也不完全是坏事,至少能证明 Makefile 是对的。
6.编写应用程序
进入虚拟机文件系统,oslab/hdc/usr/boot
建立iam.c和whoami.c
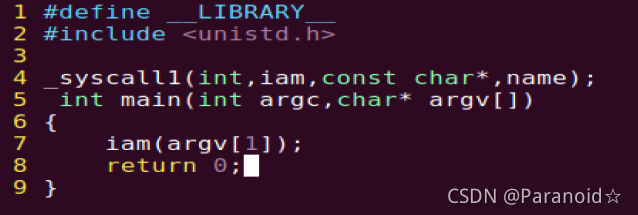
main函数的两个参数是argc和argv[],其中argc的值是在命令行运行程序时给的参数的个数;argv是一个指针数组,argv[1]是在命令行执行程序时传递给它的第一个参数的地址,== argv[2] 是在命令行执行程序时传递给它的第二个参数的地址==…因此在iam.c文件中的main里直接使用系统调用函数iam,参数即为argv[1]
7.运行和测试
首先把/home/teacher 目录下的两个测试文件testlab2.c和testlab2.sh移动到虚拟机的硬盘中的开机目录里,也就是刚刚编写ami.c的地方
cd ~/oslab
sudo ./mount-hdc
cd ./hdc/usr/root
cp /home/teacher/testlab2.c ./
cp /home/teacher/testlab2.sh ./
然后切换到oslab目录,运行虚拟机
cd ../../../
./run
在弹出的bochs虚拟机窗口中的命令行中,编译几个C语言文件
gcc -o iam iam.c
gcc -o whoami whoami.c
gcc -o testlab2 testlab2.c
编译好了以后,就可以最后的运行测试了:在虚拟机中通过iam将你的名字从用户态传入内核。然后通过whoami将传入内核的名字打印出来
./iam zhaotianhao
whoami
字符串名字
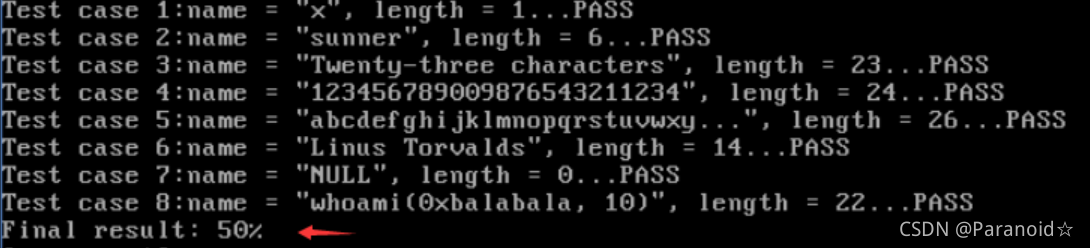
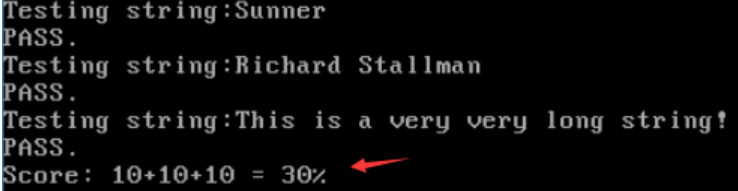
然后我们还可以运行两个测试文件testlab2.c和testlab2.sh
./testlab2
./testlab2.sh
结果如下:第一个满分50%,第二个满分为30%
总结
提示:这里对文章进行总结:
操作系统实现系统调用的基本过程:
1.应用程序调用库函数(API)
2.API 将系统调用号存入 EAX,然后通过中断调用使系统进入内核态
3.内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用)
4.系统调用完成相应功能,将返回值存入 EAX,返回到中断处理函数
5.中断处理函数返回到 API 中
6.API 将 EAX 返回给应用程序

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)