
Ceph分布式存储
ceph集群运用
目录
一、ceph简介
1、什么是ceph
Ceph是一个开源的、统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。其中“统一”是说Ceph可以一套存储系统同时提供块设备存储、文件系统存储和对象存储三种存储功能。
Ceph项目最早起源于加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能及高可靠性,并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。
Ceph是一个开源的分布式文件系统。因为它还支持块存储、对象存储,所以很自然的被用做云计算框架openstack或cloudstack整个存储后端。当然也可以单独作为存储,例如部署一套集群作为对象存储、SAN存储、NAS存储等
官网:https://ceph.com/
2、ceph支持的三种存储方式
1)块存储RBD
RBD(RADOS Block Devices)即为块存储的一种,RBD 通过 librbd 库与 OSD 进行交互,RBD 为 KVM 等虚拟化技术和云服务(如 OpenStack 和 CloudStack)提供高性能和无限可扩展性的存储后端,这些系统依赖于 libvirt 和 QEMU 实用程序与 RBD 进行集成,客户端基于 librbd 库 即可将 RADOS 存储集群用作块设备,不过,用于 rbd 的存储池需要事先启用 rbd 功能并进行初始化。
优点:
- 使用磁盘映射,如RAID/LVM的方式提供磁盘空间给主机使用,进一步维护了数据的安全性
- 因为是多块磁盘组合而成的逻辑盘空间,所以多块盘可以并行执行读写操作,提升IO效率
- 很多大型企业或数据中心使用SAN架构组网,数据传输速度和读写效率进一步得到提升
缺点:
- 如果采取FC_SAN的方式,需要HBA光纤通道卡和光纤交换机,成本较高
- 不利于不同操作系统主机间的数据共享,例如Linux主机把盘给格式化为ext4格式,那么在Windows中对这个盘的操作使用就不太友好了,或者无法操作
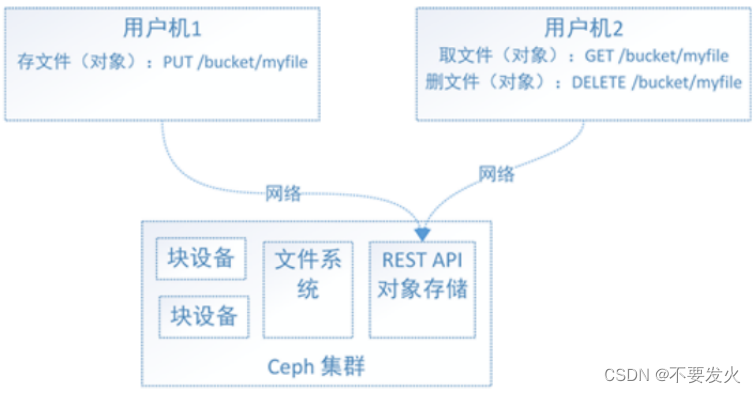
2)对象存储RGW
对象存储,也就是键值存储,通过其接口指令,也就是简单GET、PUT、DEL和其他扩展指令,向存储服务上传下载数据等
RGW 提供的是 REST 接口,客户端通过 http 与其进行交互,完成数据的增删改查等管理操作。 radosgw 用在需要使用 RESTful API 接口访问 ceph 数据的场合,因此在使用 RBD 即块存储得场合或者使用 cephFS 的场合可以不用启用 radosgw 功能。
优点:
缺点:
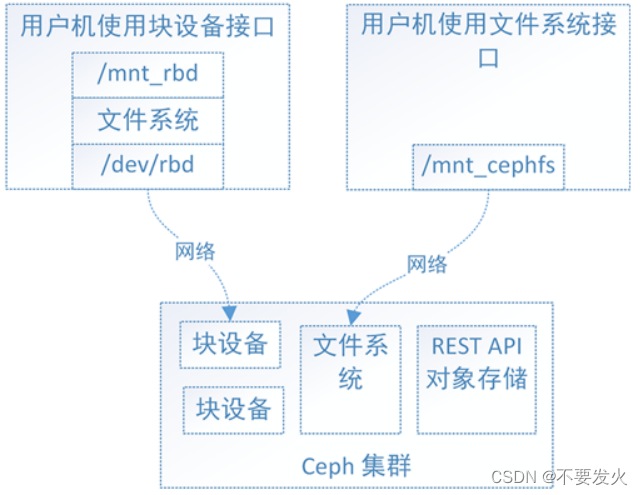
3)文件系统存储ceph-fs
Ceph文件系统(CEPH FS)是一个POSIX兼容的文件系统,可以将ceph集群看做一个共享文件系统挂载到本地,使用Ceph的存储集群来存储其数据,同时支持用户空间文件系统FUSE。它可以像 NFS 或者 SAMBA 那样,提供共享文件夹,客户端通过挂载目录的方式使用 Ceph 提供的存储。
在CEPH FS中,与对象存储与块存储最大的不同就是在集群中增加了文件系统元数据服务节点MDS(Ceph Metadata Server)。MDS也支持多台机器分布式的部署,以实现系统的高可用性。文件系统客户端需要安装对应的Linux内核模块Ceph FS Kernel Object或者Ceph FS FUSE组件。
用户可以在块设备上创建xfs文件系统,也可以创建ext4等其他文件系统。如下图所示,Ceph集群实现了自己的文件系统来组织管理集群的存储空间,用户可以直接将Ceph集群的文件系统挂载到用户机上使用
优点:
- 成本低,随便一台服务器都可以来搭建
- 方便于公司内部的文件共享,内网云盘共享一些资料等等
缺点:
-
网络带宽影响,读写效率慢,传输速率稍低
3、ceph的主要特点
统一存储
Ceph支持三种调用接口:对象存储,块存储,文件系统挂载。三种方式可以一同使用。在国内一些公司的云环境中,通常会采用ceph作为openstack的唯一后端存储来提升数据转发效率。所以在开源存储软件中,能够一统江湖。
Crush算法
Crush算法是ceph的两大创新之一,简单来说,ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作。CRUSH在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。Crush算法有相当强大的扩展性,理论上支持数千个存储节点。
高扩展性
扩容方便、容量大。能够管理数千台服务器、EB级的容量。
可靠性强
Ceph中的数据副本数量可以由管理员自行定义,副本能够垮主机、机架、机房、数据中心存放。所以安全可靠。存储节点可以自管理、自动修复。无单点故障,容错性强。
高性能
因为是多个副本,因此在读写操作时候能够做到高度并行化。理论上,节点越多,整个集群的IOPS和吞吐量越高。另外一点ceph客户端读写数据直接与存储设备(osd) 交互。
4、ceph组件作用
OSD:(Object Storage Device)
Ceph的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补、平衡数据分布,并将数据相关的一些监控信息提供给Ceph Moniter,以便Ceph Moniter来检查其他OSD的心跳状态。一个Ceph OSD存储集群,要求至少两个Ceph OSD,才能有效的保存两份数据。注意,这里的两个Ceph OSD是指运行在两台物理服务器上,并不是在一台物理服务器上运行两个Ceph OSD的守护进程。通常,冗余和高可用性至少需要3个Ceph OSD。
Monitors
Ceph的Monitor守护进程:负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map图,包括监视器图、OSD 图、归置组( PG )图、和 CRUSH 图。
还维护了monitor、OSD和PG的状态改变历史信息,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取最新的Map图,然后根据Map图和object id等计算出数据最终存储的位置。Ceph 存储集群至少需要一个 Ceph Monitor(服务器数量必须是奇数) 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。
MDS
Ceph的MDS(Metadata Server)守护进程,主要保存的是Ceph文件系统的元数据。注意,对于Ceph的块设备和Ceph对象存储都不需要Ceph MDS守护进程。Ceph MDS为基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等,这样可以很大程度降低Ceph存储集群的压力。
Managers
Ceph的Managers(Ceph Manager),守护进程(ceph-mgr)负责跟踪运行时间指标和Ceph群集的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护程序还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的仪表板和REST API。 通常,至少有两名Manager需要高可用性。
5、ceph的架构
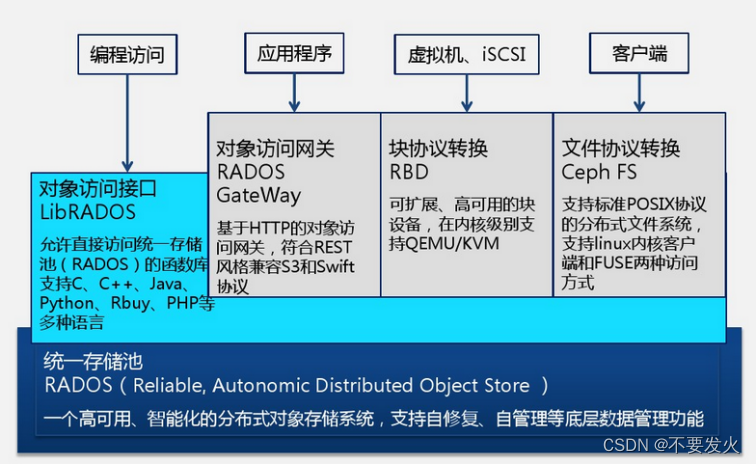
RADOS
Ceph的层是RADOS,RADOS本身也是分布式存储系统,CEPH所有的存储功能都是基于RADOS实现,Ceph的高可靠、高可拓展、高性能、高自动化都是由这一层来提供的,用户数据的存储最终也都是通过这一层来进行存储的,RADOS可以说就是Ceph的核心。
RADOS系统主要由两部分组成,分别是OSD和Monitor。
OSD: Object StorageDevice,提供存储资源。
Monitor:维护整个Ceph集群的全局状态。
LIBRADOS
基于RADOS层的上一层是LIBRADOS,LIBRADOS是一个库,它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言,比如C、C++、Python等。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作。
6、ceph存储概念
存储数据和object的关系
无论使用哪种存储方式(对象、块、挂载),当用户要将数据存储到Ceph集群时,存储数据都会被分割成多个object,每个object都有一个object id,每个object的大小是可以设置的,默认是4MB,object可以看成是Ceph存储的最小存储单元。
object与pg的关系
由于object的数量很多,对象的size很小,在一个大规模的集群中可能有几百到几千万个对象。这么多对象光是遍历寻址,速度都是很缓慢的,为了解决这些问题,ceph引入了归置组(Placcment Group即PG)的概念用于管理object,每个object最后都会通过CRUSH算法计算映射到某个pg中,一个pg可以包含多个object。
pg与osd的关系
pg也需要通过CRUSH计算映射到osd中去存储,如果是二副本的,则每个pg都会映射到二个osd,比如[osd.1,osd.2],那么osd.1是存放该pg的主副本,osd.2是存放该pg的从副本,保证了数据的冗余。
pg与pgp的关系
pg是用来存放object的,pgp相当于是pg存放osd的一种排列组合,我举个例子,比如有3个osd,osd.1、osd.2和osd.3,副本数是2,如果pgp的数目为1,那么pg存放的osd组合就只有一种,可能是[osd.1,osd.2],那么所有的pg主从副本分别存放到osd.1和osd.2,如果pgp设为2,那么其osd组合可以两种,可能是[osd.1,osd.2]和[osd.1,osd.3],很像我们高中数学学过的排列组合
存储池pool
存储池(pool):是对Ceph集群进行的逻辑划分,主要设置其中存储对象的权限、备份数目、PG数以及CRUSH规则等属性。
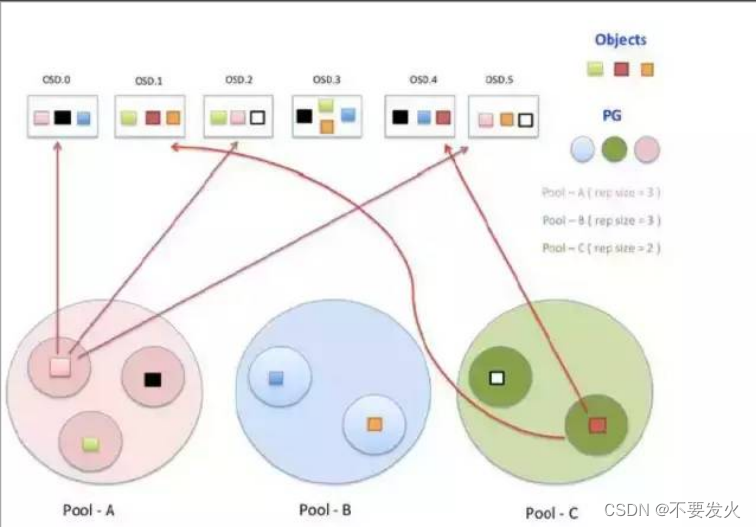
Pool是管理员自定义的命名空间,像其他的命名空间一样,用来隔离对象与PG。我们在调用API存储即使用对象存储时,需要指定对象要存储进哪一个POOL中。除了隔离数据,我们也可以分别对不同的POOL设置不同的优化策略,比如副本数、数据块及对象大小等。
ceph存储数据的过程
Ceph存储集群从客户端接收文件,每个文件都会被客户端切分成一个或多个对象,然后将这些对象进行分组,再根据一定的策略存储到集群的OSD节点中,其存储过程如图所示:
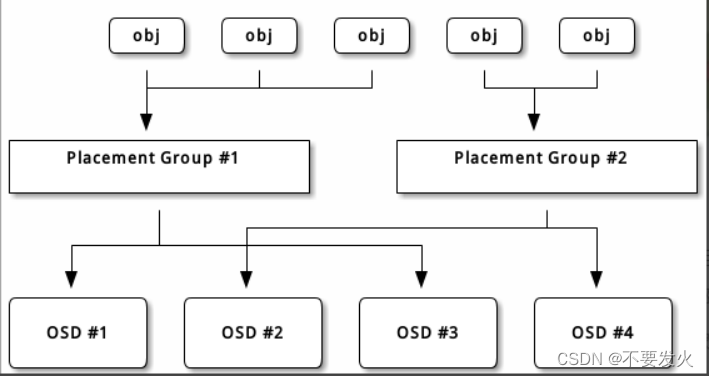
图中,对象的分发需要经过两个阶段的计算,才能得到存储该对象的OSD,然后将对象存储到OSD中对应的位置。
(1)对象到PG的映射逻辑集合。PG是系统向OSD节点分发数据的基本单位,相同PG里的对象将被分发到相同的OSD节点中(一个主OSD节点多个备份OSD节点)。对象的PG是由对象ID号通过Hash算法,结合其他一些修正参数得到的。
(2)PG到相应的OSD的映射。RADOS系统利用相应的哈希算法根据系统当前的状态以及PG的ID号,将各个PG分发到OSD集群中。OSD集群是根据物理节点的容错区域(比如机架、机房等)来进行划分的。
7、ceph存储流程
正常IO流程
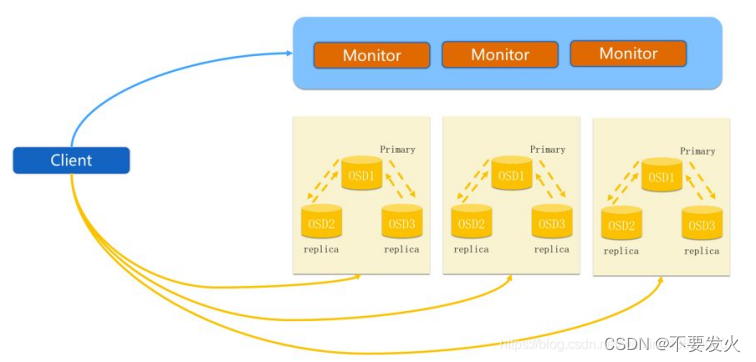
步骤:
- client 创建cluster handler。(集群处理信息)
- client 读取配置文件。
- client 连接上monitor,获取集群map信息。
- client 读写io 根据crushmap 算法请求对应的主osd数据节点。
- 主osd数据节点同时写入另外两个副本节点数据。
- 等待主节点以及另外两个副本节点写完数据状态。
- 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
新主IO流程
如果新加入的OSD1取代了原有的 OSD4成为 Primary OSD, 由于 OSD1 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,怎样工作的呢?
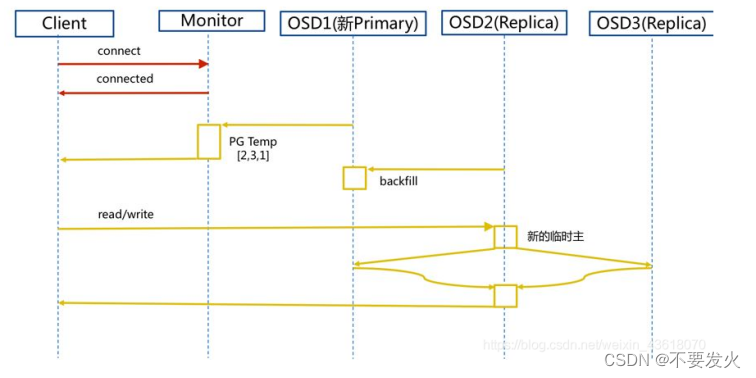
步骤:
- client连接monitor获取集群map信息。
- 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
- 临时主osd2会把数据全量同步给新主osd1。
- client IO读写直接连接临时主osd2进行读写。
- osd2收到读写io,同时写入另外两副本节点。
- 等待osd2以及另外两副本写入成功。
- osd2三份数据都写入成功返回给client, 此时client io读写完毕。
- 如果osd1数据同步完毕,临时主osd2会交出主角色。
- osd1成为主节点,osd2变成副本。
二、ceph集群详解
ceph存储集群是所有ceph存储方式的基础。基于RADOS,ceph存储集群由3种类型的守护进程组成
- ceph osd守护进程(osd)将数据作为对象存储在存储节点上
- ceph monitor(mon)维护集群映射的主副本
- ceph manager管理器守护进程
一个ceph存储集群可能包含数千个存储节点。一个最小的系统至少有一个Ceph monitor和两个ceph osd daemons用于数据复制
Ceph 文件系统、Ceph 对象存储和 Ceph 块设备从 Ceph 存储集群读取数据并将数据写入到 Ceph 存储集群。
1、集群部署
环境准备
| 服务器 | ip | 角色 |
| ceph01(管理节点) | 192.168.1.115 | admin、osd、mon、mgr |
| ceph02 | 192.168.1.116 | osd、mds、mon、mgr |
| ceph03 | 192.168.1.117 | osd、mds、mon、mgr |
| client | 192.168.1.118 | client |
关闭防火墙,selinux,添加主机名解析
ssh免密码登陆
[root@ceph01 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:Urb2cNLdlknlgW9tUNASswe6e0H5AjGKj8e3GX5ENQo root@ceph1
The key's randomart image is:
+---[RSA 2048]----+
| Eo *B+|
| . ..=+O+|
| + . o.Bo+|
| o * . B Bo|
| . S * = X..|
| o * o B o |
| . = o |
| o |
| |
+----[SHA256]-----+
# 发送到各个节点
[root@ceph01 ~]# for i in ceph01 ceph02 ceph03 client ; do ssh-copy-id $i ; done配置yum源
# 安装阿里源 集群所有节点
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# 添加ceph源 集群所有节点
cat> /etc/yum.repos.d/ceph.repo <<eof
[ceph]
name=ceph
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/x86_64/
gpgcheck=0
[ceph-noarch]
name=ceph-noarch
baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/noarch/
gpgcheck=0
eof
yum clean all && yum makecache
# 集群所有节点安装epel-release
yum -y install epel-release yum-plugin-priorities yum-utils ntpdate配置时间同步
# 安装chrony服务 所有节点
yum -y install chrony
vim /etc/chrony.conf
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
...
systemctl enable chronyd && systemctl restart chronyd安装ceph-deploy相关工具
yum install -y ceph-deploy ceph ceph-radosgw snappy leveldb gdisk python-argparse gperftools-libs创建新的集群
# 管理节点,多个mon模式
cd /etc/ceph/
ceph-deploy new ceph01 ceph02 ceph03执行完毕后,可以看到/etc/ceph目录中生成了三个文件
ceph.conf 为 ceph 配置文件,ceph-deploy-ceph.log 为 ceph-deploy 日志文件,ceph.mon.keyring 为 ceph monitor 的密钥环。
把 Ceph 配置文件里的默认副本数从 3 改成 2 ,这样只有两个 OSD 也可以达到 active + clean 状态。把下面这行加入 [global] 段:
ceph.conf 配置文件,增加副本数为 2。
echo "osd_pool_default_size = 2" >> ceph.conf初始化mon节点并收集所有秘钥
# 管理节点
ceph-deploy mon create-initial
# 查看集群状态
ceph -s2、添加osd服务
Ceph 12版本部署osd格式化命令跟之前不同
添加完硬盘直接使用,不要分区
ceph自动分区
接下来需要创建 OSD 了,OSD 是最终数据存储的地方,这里我们准备了3个 OSD 节点。官方建议为 OSD 及其日志使用独立硬盘或分区作为存储空间,也可以使用目录的方式创建。
# 使用ceph自动分区
[root@ceph01 ceph]# ceph-deploy disk zap ceph01 /dev/sdb
[root@ceph01 ceph]# ceph-deploy disk zap ceph02 /dev/sdb
[root@ceph01 ceph]# ceph-deploy disk zap ceph03 /dev/sdb添加osd节点
[root@ceph01 ceph]# ceph-deploy osd create ceph01 --data /dev/sdb
[root@ceph01 ceph]# ceph-deploy osd create ceph02 --data /dev/sdb
[root@ceph01 ceph]# ceph-deploy osd create ceph03 --data /dev/sdb查看osd节点的状态
[root@ceph01 ceph]# ceph-deploy osd list ceph01 ceph02 ceph03 
3、添加mgr服务
[root@ceph01 ceph]# ceph-deploy mgr create ceph01 ceph02 ceph034、统一集群配置
用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点,这样你每次执行 Ceph 命令行时就无需指定 monitor 地址和 ceph.client.admin.keyring 了。
# 管理节点
[root@ceph01 ceph]# ceph-deploy admin ceph01 ceph02 ceph03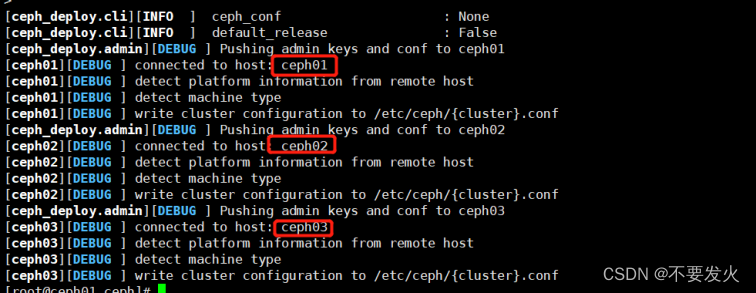
# 集群每一个节点授权
[root@ceph01 ceph]# chmod +r /etc/ceph/ceph.client.admin.keyring
[root@ceph02 ceph]# chmod +r /etc/ceph/ceph.client.admin.keyring
[root@ceph03 ceph]# chmod +r /etc/ceph/ceph.client.admin.keyring5、添加mds服务
Mds是ceph集群中的元数据服务器,而通常它都不是必须的,因为只有在使用cephfs的时候才需要它,而目在云计算中用的更广泛的是另外两种存储方式。
Mds虽然是元数据服务器,但是它不负责存储元数据,元数据也是被切成对象存在各个osd节点中的,如下图:
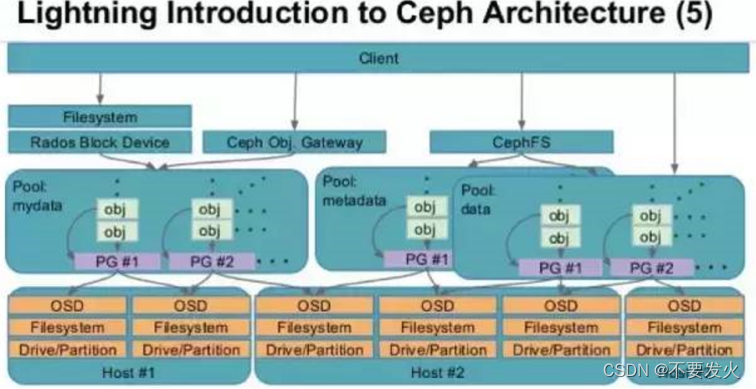
在创建CEPH FS时,要至少创建两个POOL,一个用于存放数据,另一个用于存放元数据。Mds只是负责接受用户的元数据查询请求,然后从osd中把数据取出来映射进自己的内存中供客户访问。所以mds其实类似一个代理缓存服务器,替osd分担了用户的访问压力,如下图:
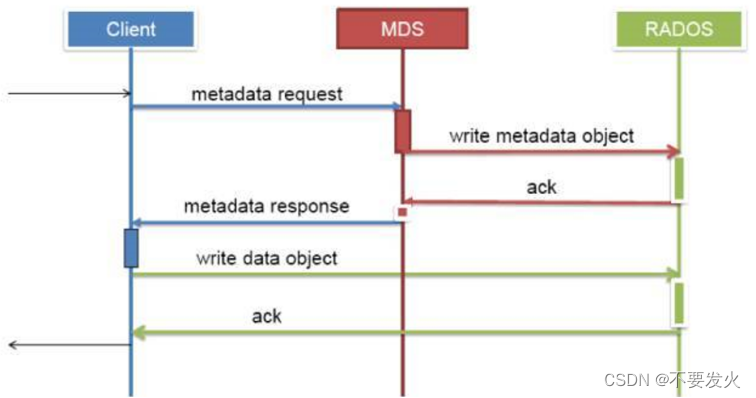
# 管理节点
[root@ceph01 ceph]# ceph-deploy mds create ceph02 ceph03
# 查看mds服务状态
[root@ceph01 ceph]# ceph mds stat
, 2 up:standby
# 查看集群状态
[root@ceph01 ceph]# ceph -s 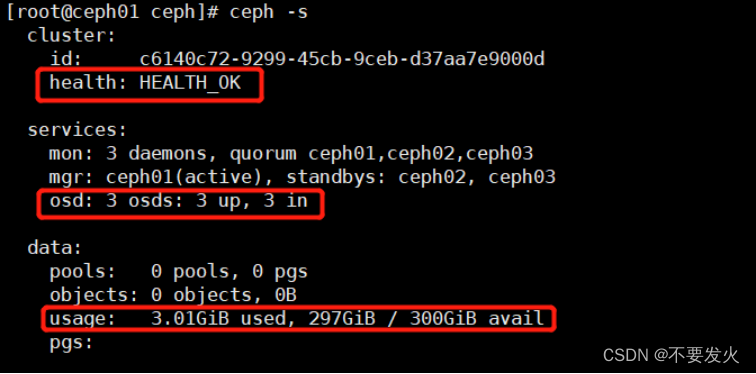
集群完成
三、ceph集群运用
1、文件系统运用
创建文件系统存储池
# 查看文件系统
[root@ceph01 ~]# ceph fs ls
No filesystems enabled ## 没有文件系统
# 首先创建存储池
语法:
ceph osd pool create cephfs_data <pg_num>
ceph osd pool create cephfs_metadata <pg_num>
其中:<pg_num> = 128 ,
关于创建存储池
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
*少于 5 个 OSD 时可把 pg_num 设置为 128
*OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
*OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
*OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
*自己计算 pg_num 取值时可借助 pgcalc 工具
https://ceph.com/pgcalc/
#CephFS 需要两个 Pools - cephfs-data 和 cephfs-metadata, 分别存储文件数据和文件元数据
[root@ceph01 ~]# ceph osd pool create ceph_data 128
pool 'ceph_data' created
[root@ceph01 ~]# ceph osd pool create ceph_metadata 128
pool 'ceph_metadata' created创建文件系统
创建好存储池后,你就可以用 fs new 命令创建文件系统了
命令:ceph fs new <fs_name> cephfs_metadata cephfs_data
其中:<fs_name> = cephfs 可自定义
# 给创建的2个存储池创建文件系统
[root@ceph01 ~]# ceph fs new cephfs ceph_metadata ceph_data
new fs with metadata pool 2 and data pool 1
# 查看文件系统
[root@ceph01 ~]# ceph fs ls
name: cephfs, metadata pool: ceph_metadata, data pools: [ceph_data ]
# 查看mds的状态
[root@ceph01 ~]# ceph fs status cephfs
cephfs - 0 clients
======
+------+--------+--------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+--------+---------------+-------+-------+
| 0 | active | ceph03 | Reqs: 0 /s | 10 | 12 |
+------+--------+--------+---------------+-------+-------+
+---------------+----------+-------+-------+
| Pool | type | used | avail |
+---------------+----------+-------+-------+
| ceph_metadata | metadata | 2246 | 140G |
| ceph_data | data | 0 | 140G |
+---------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| ceph02 | ## 热备状态
+-------------+
MDS version: ceph version 12.2.13 (584a20eb0237c657dc0567da126be145106aa47e) luminous (stable)
挂载客户端
要挂载 Ceph 文件系统,如果你知道监视器 IP 地址可以用 mount 命令、或者用 mount.ceph 工具来自动解析监视器 IP 地址。
# 内核驱动的方式挂载文件系统
# 在client创建挂载点
[root@client ~]# mkdir /data
# 查看秘钥
[root@ceph01 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQBbD8ViIbmSCBAA7Bi4WFNDs2AJR0umgkcsmQ==
# 使用秘钥挂载
[root@client ~]# mount -t ceph 192.168.1.115:6789:/ /data/ -o name=admin,secret=AQBbD8ViIbmSCBAA7Bi4WFNDs2AJR0umgkcsmQ==
# 查看挂载结果
[root@client ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos-root xfs 98G 1.5G 96G 2% /
devtmpfs devtmpfs 980M 0 980M 0% /dev
tmpfs tmpfs 992M 0 992M 0% /dev/shm
tmpfs tmpfs 992M 9.5M 982M 1% /run
tmpfs tmpfs 992M 0 992M 0% /sys/fs/cgroup
/dev/sr0 iso9660 4.2G 4.2G 0 100% /mnt/cdrom
/dev/sda1 xfs 497M 123M 375M 25% /boot
tmpfs tmpfs 199M 0 199M 0% /run/user/0
192.168.1.115:6789:/ ceph 141G 0 141G 0% /data
# 取消挂载
[root@client ~]# umount /data/
用户空间的方式挂载文件系统
[root@client ~]# yum install -y ceph-fuse
# 挂载
[root@ceph01 ceph]# scp ceph.client.admin.keyring ceph.conf client:/etc/ceph/
ceph.client.admin.keyring 100% 63 52.5KB/s 00:00
ceph.conf 100% 266 266.9KB/s 00:00
[root@client ~]# ceph-fuse -m 192.168.1.115:6789 /data/
[root@client ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos-root xfs 98G 1.6G 96G 2% /
devtmpfs devtmpfs 980M 0 980M 0% /dev
tmpfs tmpfs 992M 0 992M 0% /dev/shm
tmpfs tmpfs 992M 9.5M 982M 1% /run
tmpfs tmpfs 992M 0 992M 0% /sys/fs/cgroup
/dev/sr0 iso9660 4.2G 4.2G 0 100% /mnt/cdrom
/dev/sda1 xfs 497M 123M 375M 25% /boot
tmpfs tmpfs 199M 0 199M 0% /run/user/0
ceph-fuse fuse.ceph-fuse 141G 0 141G 0% /data
# 取消挂载
[root@client ~]# umount /data/
2、块存储运用
Ceph支持一个非常好的特性,以COW(写时复制copy-on-write)的方式从RBD快照创建克隆,在Ceph中被称为快照分层。分层特性允许用户创建多个CEPH RBD克隆实例。这些特性应用于OpenStack等云平台中,使用快照形式保护ceph RBD 镜像,快照是只读的,但COW克隆是完全可以写 ,可以多次来孵化实例,对云平台来说是非常有用的。
注:
什么是copy-on-write呢?
copy-on-write的意思就是在复制一个对象(数据或文件)的时候并不是真正的把原先的对象复制到内存的另外一个位置上,而是在新对象的内存映射表中设置一个指针,指向原对象的位置,并把那块内存的Copy-On-Write位设置为1.
这样,在对新的对象执行读操作的时候,内存数据不发生任何变动,直接执行读操作;而在对新的对象执行写操作时,将真正的对象复制到新的内存地址中,并修改新对象的内存映射表指向这个新的位置,并在新的内存位置上执行写操作。
什么是快照?
快照是镜像在某个特定时间点的一份只读副本。 Ceph 块设备的一个高级特性就是你可以为映像创建快照来保留其历史。Ceph 还支持分层快照,让你快速、简便地克隆镜像。
Ceph RBD镜像有format-1 和 format-2两种类型。
format-1:新建rbd镜像是使用最初的格式。此格式兼容所有版本的librbd和内核模块,但不支持新功能,像克隆。
format-2:使用第二版本rbd格式,此格式增加了对克隆的支持,日后扩展以增加新功能也变得更加容易。默认RBD创建的镜像是format-2。
创建块存储的存储池
# 查看内核是否支持使用RBD
[root@cong11 ~]# modprobe rbd
如果有错误信息说明内核不支持,那你就先去升级一下内核
[root@ceph01 ceph]# lsmod | grep rbd
rbd 83728 0
libceph 301687 1 rbd
# 创建存储池
[root@ceph01 ceph]# ceph osd pool create rbd 64
pool 'rbd' created
注:
PG计算方式
total PGs = ((Total_number_of_OSD * 100) / max_replication_count) / pool_count
例如,当前ceph集群是9个osd,3副本,1个默认的rbd pool
所以PG计算结果为300,一般把这个值设置为与计算结果最接近的2的幂数,跟300比较接近的是256
注:
查看当前的PG值
# ceph osd pool get rbd pg_num
手动设置pg数量
# ceph osd pool set rbd pg_num 256
创建块设备镜像
要想把块设备加入某节点,你得先在 Ceph 存储集群中创建一个镜像,使用下列命令:
#rbd create --size {megabytes} {pool-name}/{image-name} -m mon节点的ip地址
如果创建镜像时不指定存储池,它将使用默认的 rbd 存储池
[root@ceph01 ceph]# rbd create --size 102400 rbd/test1
这里需要注意size的大小,这个大小可以超过你实际pool的大小,这个叫做瘦分配(即精简配置),也叫超卖和按需分配。创建块之后可以通过指令rbd resize --size 51200 test1 --allow-shrink来动态的更改。
注:ceph块设备镜像是精简配置,只有在你开始写入数据时它们才会占用物理空间
# 查看rbd的信息
[root@ceph01 ceph]# rbd ls
test1
注:用下列命令罗列某个特定存储池中的块设备,用存储池的名字替换 {poolname} :
# rbd ls {poolname}
# 查看镜像的信息
[root@ceph01 ceph]# rbd info test1
rbd image 'test1':
size 100GiB in 25600 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.196d76b8b4567
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
create_timestamp: Wed Jul 6 17:11:01 2022
注:
用下列命令检索某存储池内的镜像的信息,用镜像名字替换 {image-name} 、用存储池名字替换 {pool-name} :
# rbd info {pool-name}/{image-name}
映射块设备
映射进内核操作之前,首先查看内核版本, 2.x及之前的内核版本需手动调整format为1, 4.x之前要关闭object-map, fast-diff, deep-flatten功能才能成功映射到内核,这里使用的是centos7.5,内核版本3.10。
客户端要确定ceph-common包要安装:yum -y install ceph-common
[root@client ~]# rbd feature disable test1 object-map fast-diff deep-flatten exclusive-lock
[root@client ~]# rbd map test1
/dev/rbd0
[root@client ~]# ls /dev/rbd0
/dev/rbd0
可以看见在/dev下创建了一个叫rbd0的设备文件
挂载使用
挂载rbd的Linux 服务器首先需要机器支持ceph客户端,如果是一台新机器的话,请安装ceph,然后同步下配置文件。
# 创建挂载点
[root@client ~]# mkdir /cephrbd
# 格式化磁盘
[root@client ~]# mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=16, agsize=1638400 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=26214400, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=12800, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# 挂载
[root@client ~]# mount /dev/rbd0 /cephrbd/
[root@client ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos-root xfs 98G 1.6G 96G 2% /
devtmpfs devtmpfs 980M 0 980M 0% /dev
tmpfs tmpfs 992M 0 992M 0% /dev/shm
tmpfs tmpfs 992M 9.5M 982M 1% /run
tmpfs tmpfs 992M 0 992M 0% /sys/fs/cgroup
/dev/sr0 iso9660 4.2G 4.2G 0 100% /mnt/cdrom
/dev/sda1 xfs 497M 123M 375M 25% /boot
tmpfs tmpfs 199M 0 199M 0% /run/user/0
/dev/rbd0 xfs 100G 33M 100G 1% /cephrbd
# 测试写入数据
[root@client ~]# dd if=/dev/zero of=/cephrbd/file bs=100M count=1
1+0 records in
1+0 records out
104857600 bytes (105 MB) copied, 0.218325 s, 480 MB/s
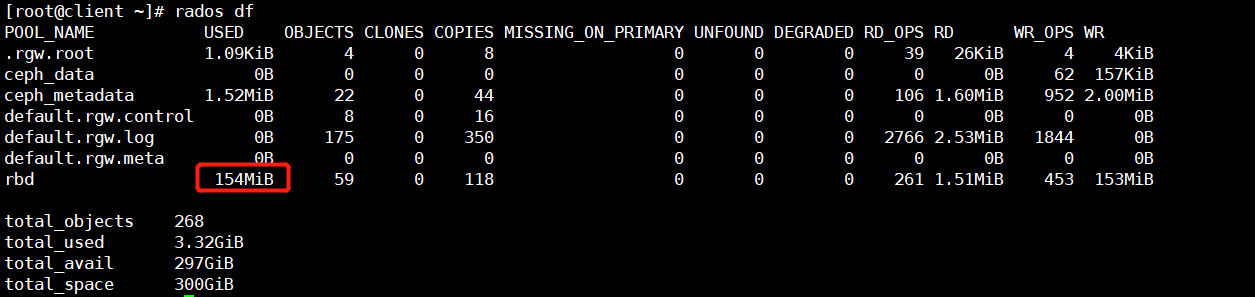
可以看到我写了100M数据,ceph的rbd pool相应的使用了100M的数据,也就是对/cephrbd目录的操作将会直接写到ceph集群的rbd这个pool中,然后写到ceph的osd上。
创建快照并测试回滚
# 创建了一个test1快照,快照的名字叫做mysnap
[root@client ~]# rbd snap create --snap mysnap rbd/test1
# 首先删除文件
[root@client ~]# rm -rf /cephrbd/file
# 取消挂载
[root@client ~]# umount /dev/rbd0
#回滚
[root@client ~]# rbd snap rollback rbd/test1@mysnap
Rolling back to snapshot: 100% complete...done.
# 查看挂在信息
[root@client ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos-root xfs 98G 1.6G 96G 2% /
devtmpfs devtmpfs 980M 0 980M 0% /dev
tmpfs tmpfs 992M 0 992M 0% /dev/shm
tmpfs tmpfs 992M 9.5M 982M 1% /run
tmpfs tmpfs 992M 0 992M 0% /sys/fs/cgroup
/dev/sr0 iso9660 4.2G 4.2G 0 100% /mnt/cdrom
/dev/sda1 xfs 497M 123M 375M 25% /boot
tmpfs tmpfs 199M 0 199M 0% /run/user/0
# 在挂载
[root@client ~]# mount /dev/rbd0 /cephrbd/
# 查看文件
[root@client ~]# ls /cephrbd/
file
模板与克隆
# 查看块设备的format(format必须为2)
[root@client ~]# rbd info rbd/test1
rbd image 'test1':
size 100GiB in 25600 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.196d76b8b4567
format: 2
features: layering
flags:
create_timestamp: Wed Jul 6 17:11:01 2022
如果不是format 2 可以创建时指定
# rbd create rbd/test1 --size 102400 --image-format 2
# 创建克隆前,把快照保存起来,不然会出错
[root@client ~]# rbd snap protect rbd/test1@mysnap
可以使用rbd snap unprotect rbd/test1@mysnap去掉这个保护,但是这样的话就 不能克隆了
# 克隆块设备
# 卸载挂载点
[root@client ~]# umount /dev/rbd0
#克隆设备
[root@client ~]# rbd clone rbd/test1@mysnap rbd/test2
# 查看rbd
[root@client ~]# rbd ls rbd
test1
test2
如上看到rbd这个池上有两个块设备了,一个是原来的test1,一个是通过test1的镜像模板克隆出来的test2。
# 内核映射块设备
[root@client ~]# rbd map rbd/test2
/dev/rbd2
# 挂载克隆的块设备
[root@client ~]# mkdir /cephrbd1
[root@client ~]# mount /dev/rbd1 /cephrbd1/
[root@client ~]# ls /cephrbd1/
file
因为是克隆test1,test1上有文件系统,所以test2也有文件系统,直接挂载使用就可以
# 查看克隆的块设备
[root@client ~]# rbd info rbd/test2
rbd image 'test2':
size 100GiB in 25600 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.196ee6b8b4567
format: 2
features: layering
flags:
create_timestamp: Wed Jul 6 17:53:15 2022
parent: rbd/test1@mysnap
overlap: 100GiB
这个时候的test2还是依赖test1的镜像mysnap,如test1的mysnap被删除test2也不能够使用了,要想独立出去,就必须将父镜像的信息合并flatten到子镜像中
独立克隆的块设备
拍平克隆映像:
克隆出来的映像仍保留了对父快照的引用。要从子克隆删除这些到父快照的引用,你可以把快照的信息复制给子克隆,也就是“拍平”它。拍平克隆镜像的时间随快照尺寸增大而增加。要删除快照,必须先拍平子镜像。
因为拍平的镜像包含了快照的所有信息,所以拍平的映像占用的存储空间会比分层克隆要大。
[root@client ~]# rbd flatten rbd/test2
Image flatten: 100% complete...done.
[root@client ~]# rbd info rbd/test2
rbd image 'test2':
size 100GiB in 25600 objects
order 22 (4MiB objects)
block_name_prefix: rbd_data.196ee6b8b4567
format: 2
features: layering
flags:
create_timestamp: Wed Jul 6 17:53:15 2022
# 删除镜像
# 去掉镜像test1的保护
root@client ~]# rbd snap unprotect rbd/test1@mysnap
# 删除镜像test1
[root@client ~]# rbd snap rm rbd/test1@mysnap
Removing snap: 100% complete...done.
# 查看test1的快照
[root@client ~]# rbd snap ls rbd/test1
3、对象存储运用
部署ceph03主机作为rgw节点(注:一般rgw节点应为独立主机,且需要配置NTP、相同yun源以及无密码远程,并安装ceph-radosgw)
部署对象存储服务器之后,需要开发相应的程序运用该对象存储服务,这里就跳过了
四、ceph常用命令
1、服务相关
- systemctl status ceph\*.service ceph\*.target #查看所有服务
- systemctl stop ceph\*.service ceph\*.target #关闭所有服务
- systemctl start ceph.target #启动服务
- systemctl stop ceph-osd\*.service # 关闭所有osd服务
- systemctl stop ceph-mon\*.service #关闭所有mon服务
- systemctl start ceph-osd@{id} #启动单个osd服务
- systemctl start ceph-mon@{hostname} #启动单个mon服务
- systemctl start ceph-mds@{hostname} #启动单个mds服务
2、查看
- ceph -help #查看命令帮助
- ceph -s #查看状态
- ceph osd pool set rbd pg_num 1024 # 修改pg_num数量
- ceph osd pool set rbd pgp_num 1024 # 修改pgp_num数量
- ceph osd tree #查看osd树列表
- ceph osd pool ls #查看所有的osd池
- ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show # 查看指定的osd运行中的所有参数
- rados df #查看储存池使用情况
- rados -p rbd ls |sort
- ceph osd pool get rbd pg_num
- ceph osd pool get rbd pgp_num
- ceph osd pool set rbd pg_num 1024
- ceph osd pool set rbd pgp_num 1024
3、rbd相关
rbd create image1 --size 60G
# 默认在rbd pool下创建一个名为image1, 大小为1G的image,等同于
rbd create rbd/image1 --size 60G --image-format 2
rbd list
# 列出所有的块设备image
rbd info image1
# 查看某个具体的image的信息。例如:
rbd feature disable image1 exclusive-lock, object-map, fast-diff, deep-flatten
# 关掉image1的一些feature
rbd map image1
#把test_image块设备映射到操作系统,
例如:h$ sudo rbd map image1
/dev/rbd0
rbd showmapped
#显示已经映射的块设备,
例如:$ rbd showmapped
id pool image snap device
0 rbd image1 - /dev/rbd0
rbd unmap image1 #取消映射
rbd rm image #删除一个rbd image4、rodos相关
rados lspools #查看ceph 集群的pool
rados mkpool <pool-name> #创建名为<pool-name>的ceph pool
rados ls #列出叫rbd的pool里的objects5、清除ceph相关配置
停止所有进程: systemctl stop ceph\*.service ceph\*.target
卸载所有ceph程序:ceph-deploy uninstall [{ceph-node}]
删除ceph相关的安装包:ceph-deploy purge {ceph-node} [{ceph-data}]
例如:ceph-deploy purge node4
删除ceph相关的配置:ceph-deploy purgedata {ceph-node} [{ceph-data}]
删除key:ceph-deploy forgetkeys
卸载ceph-deploy管理:yum -y remove ceph-deploy

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)