
python批量提取pdf内容并存入excel(excel可更新)
python批量提取pdf内容并存入excel(excel可更新)
·
接了一个小单,需求是:
- 用Python实现自动生成并更新Tracker表格。
- Tracker表格中有两个sheet,分别对应相同名字的文件夹,SAV是pdf文件合集,每个文件夹将会有上百个文件(目前只放了几个用于测试,实际上需要录入七八百个文件),需要实现自动按照ID的顺序将信息自动录入Tracker这个excel中。
- 待提取内容部分来自表格,部分来自文本。
- 当文件夹中加入新文件时,再次运行代码可以更新excel。
字段对应关系非常简单,同名即对应。
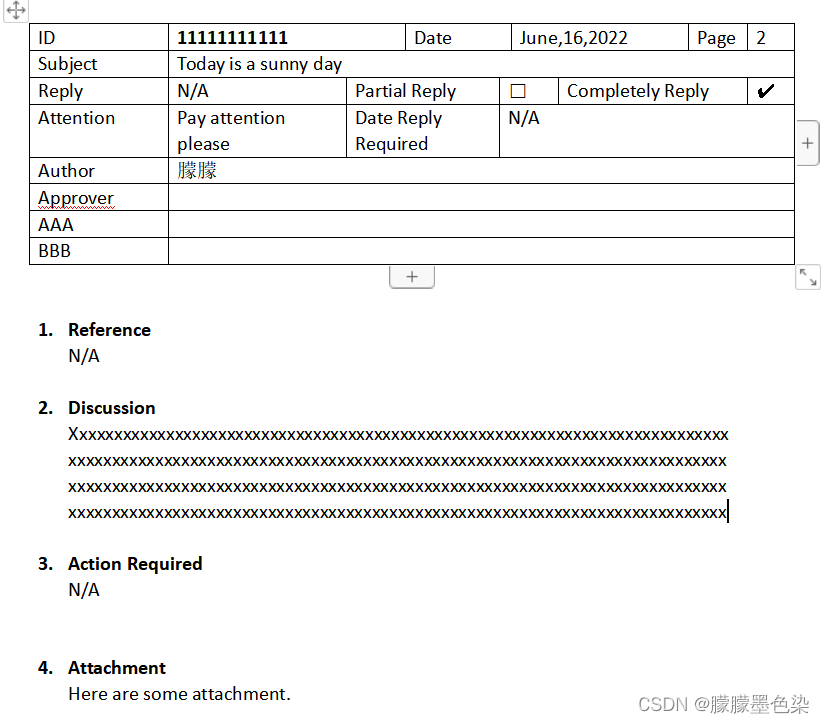
背景如上,开始设计程序。基本思路是:首先针对单个pdf文档进行提取,然后加入遍历文件夹操作。
这个pdf涉及表格和文字,所以分别提取内容存至列表col_values。然后输出col_values的值,使用自己需要的内容在列表中的位置(索引)将需要的col_values按顺序存放至列表doc_values。
file=pdfplumber.open(doc_path)
first_page = file.pages[1]
#提取表格
col_values = first_page.extract_table()
#提取字符串
text = first_page.extract_text()
str1 = (text.split('Reference')[2].split('\n \n2. Discussion')[0])
str2 = (text.split('3. Action Required')[1].split('\n \n \n4. Attachment')[0])
doc_values = [] # 获取需要的列值
doc_values.append(col_values[0][1])
doc_values.append(col_values[0][3])
doc_values.append(col_values[3][1])
doc_values.append(col_values[4][1])
doc_values.append(' ')
doc_values.append(str1)
doc_values.append(col_values[2][1])
doc_values.append(col_values[1][1])
doc_values.append(str2)至此完成对单个pdf文档的内容提取,将其设计为可被调用的函数write_pdf,主函数是遍历文件夹部分+写入excel部分。在将doc_values写入excel之前需要加入一个判断结构:判断当前文件是否已经被写入excel,同时注意写入excel时使用的是追加操作。
import pdfplumber
from openpyxl import load_workbook
import os
def write_pdf(doc_path):
file=pdfplumber.open(doc_path)
first_page = file.pages[1]
#提取表格
col_values = first_page.extract_table()
#提取字符串
text = first_page.extract_text()
str1 = (text.split('Reference')[2].split('\n \n2. Discussion')[0])
str2 = (text.split('3. Action Required')[1].split('\n \n \n4. Attachment')[0])
doc_values = [] # 获取需要的列值
doc_values.append(col_values[0][1])
doc_values.append(col_values[0][3])
doc_values.append(col_values[3][1])
doc_values.append(col_values[4][1])
doc_values.append(' ')
doc_values.append(str1)
doc_values.append(col_values[2][1])
doc_values.append(col_values[1][1])
doc_values.append(str2)
return doc_values
if __name__ == '__main__':
for filepath,dirnames,filenames in os.walk(r"D:\install\desktop\AM\SAV"):
for filename in filenames:
doc_path = os.path.join(filepath,filename)
doc_values = write_pdf(doc_path)
wb = load_workbook('D:\install\desktop\EAM\EAM\Tracker.xlsx')
ws2 = wb['SAV']
rows = ws2.max_row
print(rows)
columnA_data = []
for i in range(1, rows):
cell_value = ws2.cell(row=i+1, column=1).value
columnA_data.append(cell_value)
if doc_values[0] in columnA_data:
print("文件{}已被写入excel".format(doc_values[0]))
else:
ws2.append(doc_values)
wb.save('D:\install\desktop\EAM\EAM\Tracker.xlsx')
print('保存成功')

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)