f2fs学习笔记 - 1. f2fs概述
1. 前言本文主要通过回答几个问题来概要了解f2fs,这几个问题包括:f2fs是什么?为何引入f2fs?f2fs如何工作?f2fs如何做到随机写入顺序化?f2fs如何解决雪崩问题?2. f2fs是什么?F2FS (Flash Friendly File System) 是专门针对SSD、eMMC、UFS等闪存设备设计的文件系统。基于LFS,同时解决了LFS的一些问题。由三星工程师Jaegeuk K
1. 前言
本文主要从总体的角度来了解f2fs,尝试回答下面的几个问题来靠近它,这几个问题包括:
- f2fs是什么?
- 为何引入f2fs?
- f2fs如何工作?
2. f2fs是什么?
F2FS (Flash Friendly File System) 是专门针对SSD、eMMC、UFS等闪存设备设计的文件系统。基于LFS,同时解决了LFS的一些问题。由三星工程师Jaegeuk Kim于2012年10月发布到Linux社区,并于2012年12月进入Linux 3.8 内核主线,初始 版本包含22个patch。初始版本kernel 3.8(2012年)的代码量为1万多行,22个提交,截止到kernel 5.8-rc2(2020年)的代码量为4万多行,2899个提交。
3. LFS特点

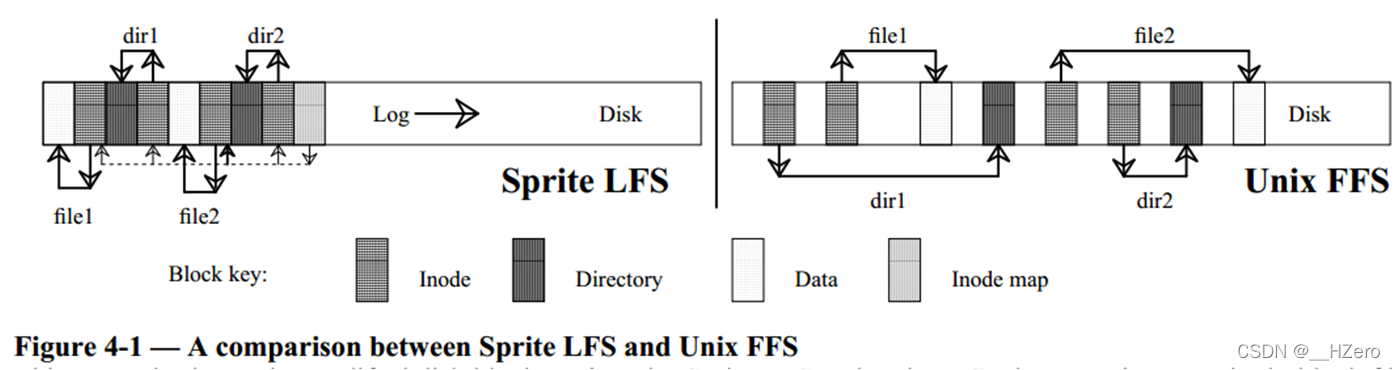
LFS最大的特点是以日志的形式将对文件的修改顺序写入磁盘,化随机写入为顺序写入,如上创建文件file1,file2,创建目录dir1,dir2,对于FFS会有10次的随机写入,而对于LFS将以日志的方式一次从内存中写入, 同时也要写入inode map,inode map记录了每个inode所在的block地址,索引为inode号,inode map所在的block地址被记录在F2FS的CP区域。
Flash memory的特点
(1)Out-place 更新 (非in-place更新)
(2)随机写入会增加GC垃圾回收开销
(3)顺序写入速率高于随机写入速率
LFS的特点
(1)Out-place更新
(2)大量的采用顺序写入
因此LFS对Flash memory是友好的文件系统 ,而f2fs基于LFS,因此也是对flash友好的文件系统
LFS的不足:
(1)针对HDD进行优化的文件系统布局
(2)仍然存在Wandering Tree(雪崩)问题
(3)没有进行冷热数据分离
(4)磁盘高利用率的情况下垃圾回收成本高
4. f2fs解决了哪些问题?
采用falsh友好的文件系统布局
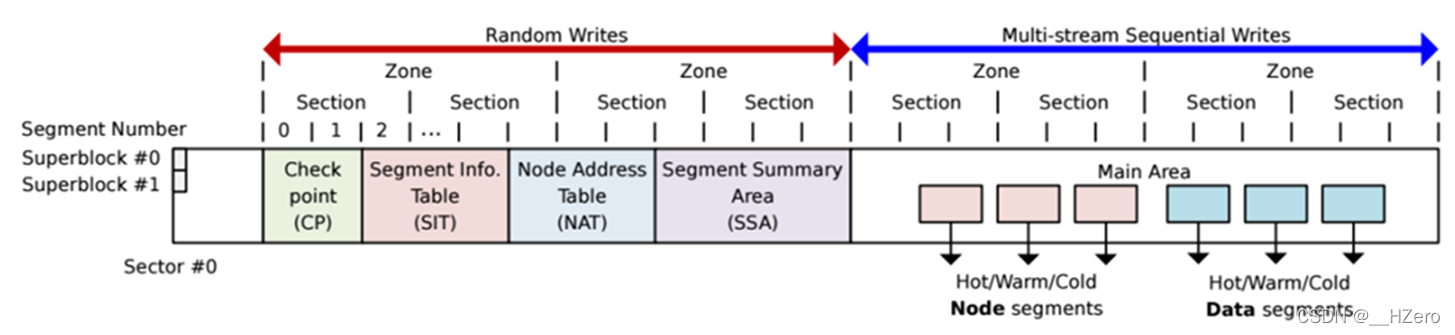

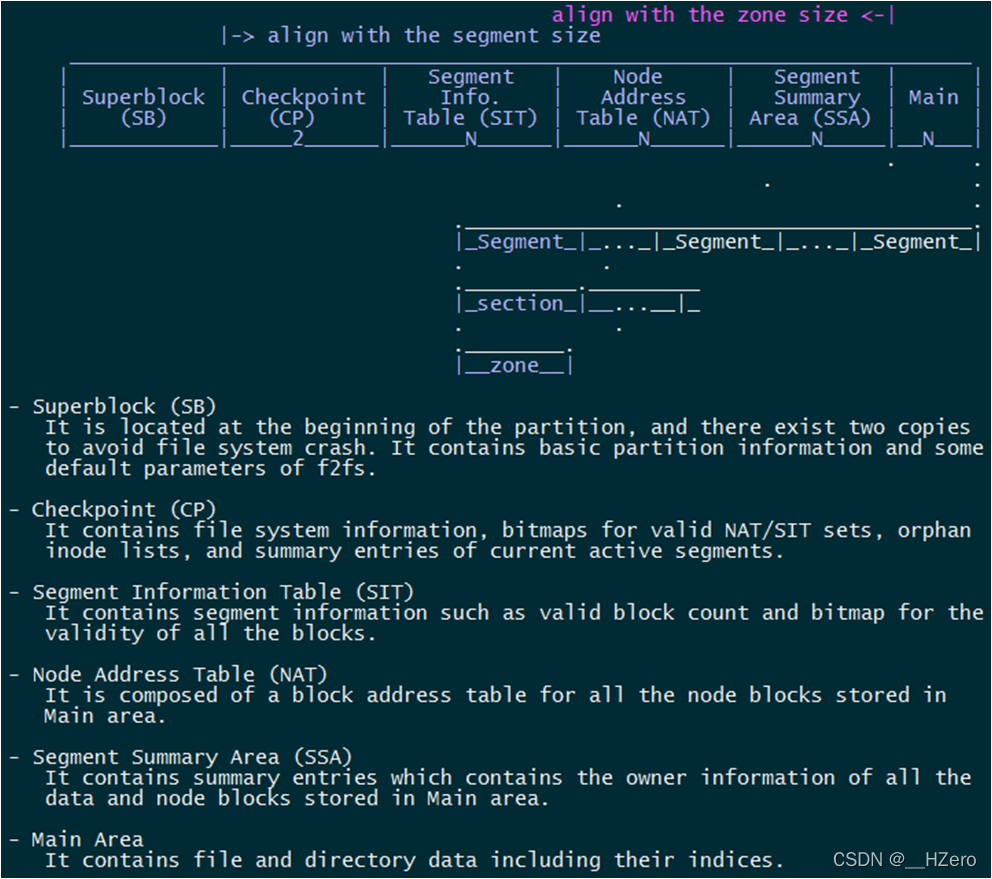
解决了Wandering Tree(雪崩)问题
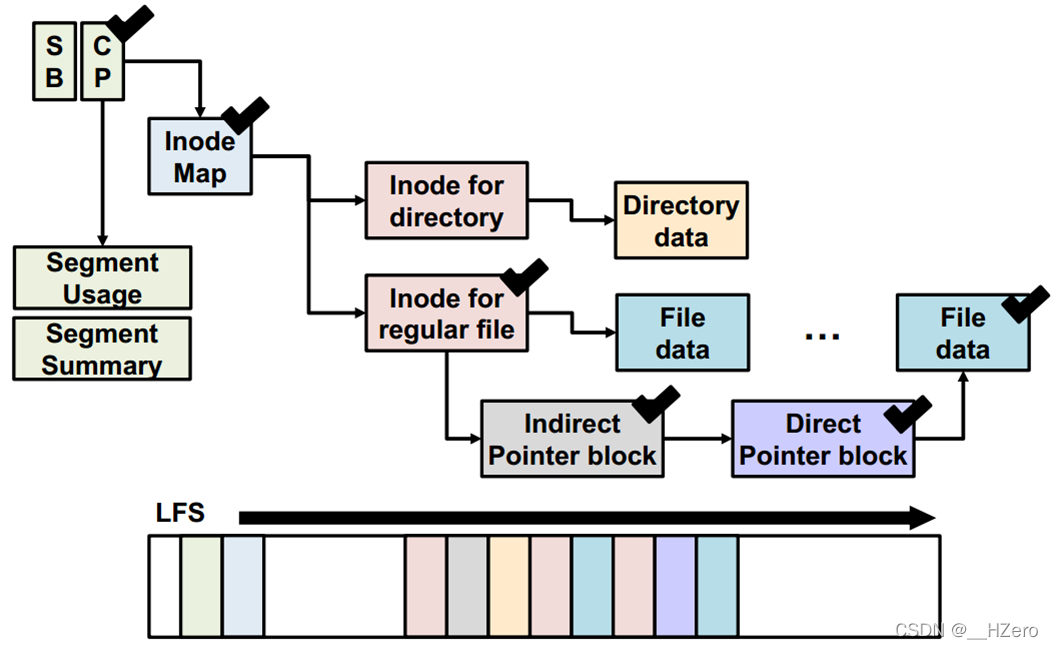
传统的LFS索引结构,由于异地更新在修改文件数据时会引发直接或间接node以及inode和inode map的一系列修改,称为wandering tree问题
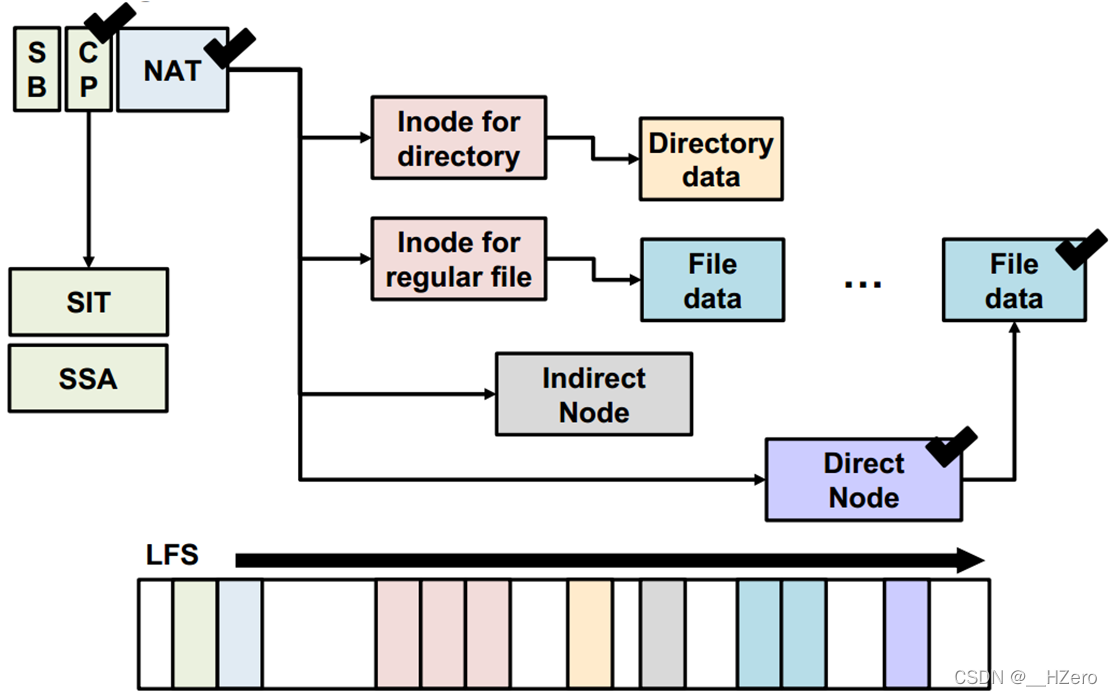
F2FS索引结构,通过引入NAT,保存所有node的信息,间接node不再指向直接node,而是指向NAT区,解决了wandering tree问题
使用Multi-head log,同时将冷热数据分离
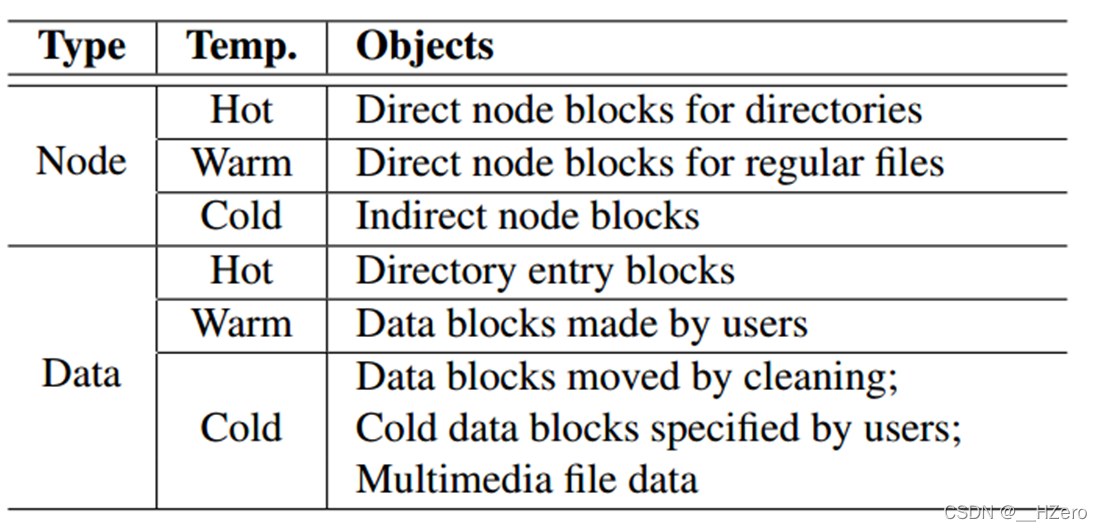
main area分为node block和data block
将node block和data block进行冷热分离
有效减少GC cost
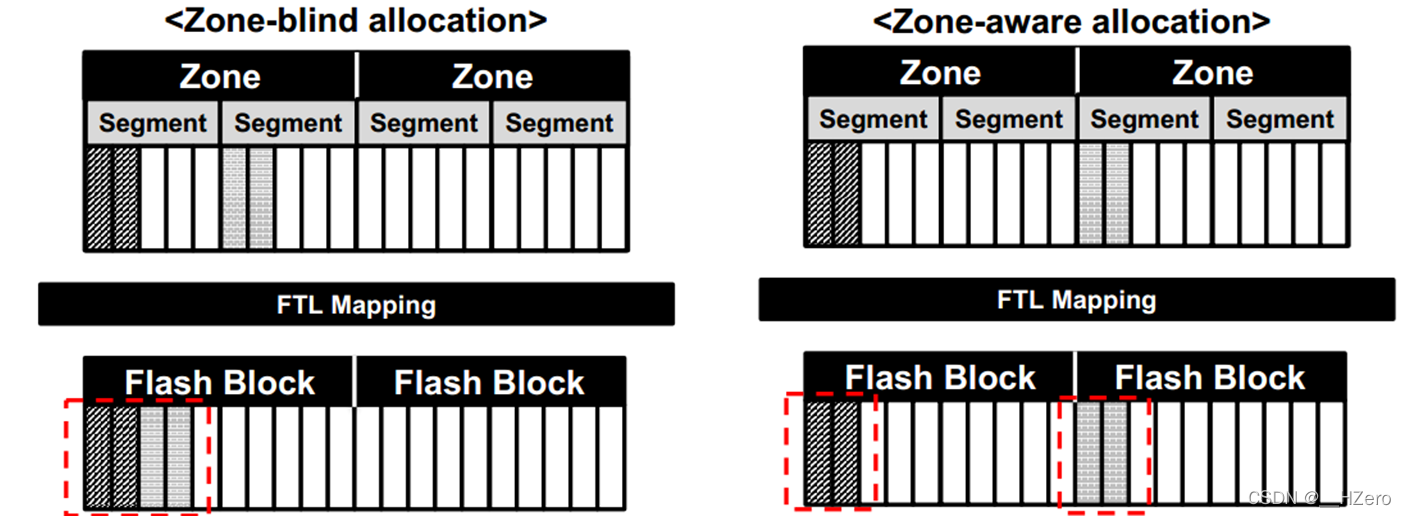
node block与data block分离, 冷热数据分离,将不同数据存放到不同的zone中,有利于FTL进行GC垃圾回收,如上图,假设zone对应flash中的一个block,则zone-aware allocation可以做到冷热数据分配到不同的zone,也就分配到不同的flash block中
采用自适应的log方式
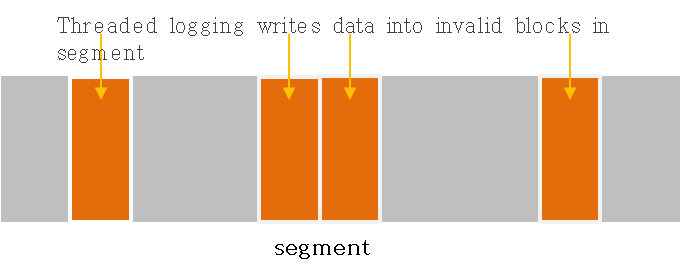
- Normal logging
追加式logging,只会向clean segment写入
如果没有空闲空间,需要执行GC操作
GC操作会带来随机读和顺序写开销 - Thread logging
向dirty的segment写入
不需要GC操作
会引起随机写入 - Normal logging与thread logging的切换
当空闲空间低于阀值(e.g.k=5% )将采用thread logging,否则采用normal logging
5. f2fs是如何工作的?
f2fs文件读取(/File)
- Setp 1首先通过superblock获取root inode号(==nid,假设为3),通过NAT获取root inode所在的node block地址
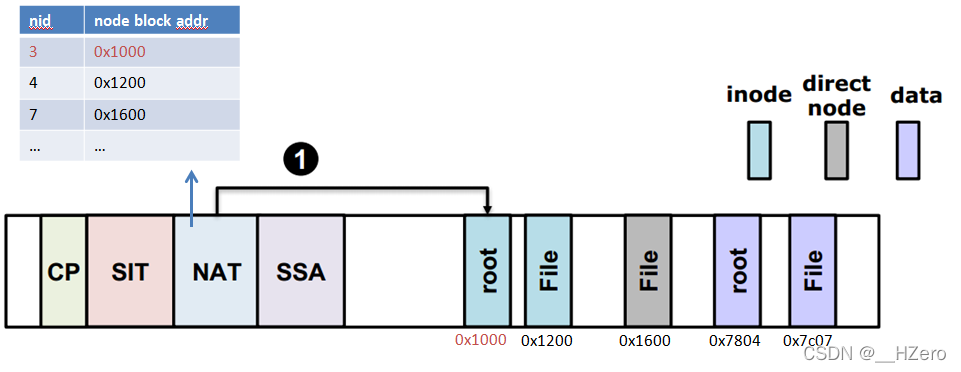
- Setp 2 通过root inode找到root目录的data block地址
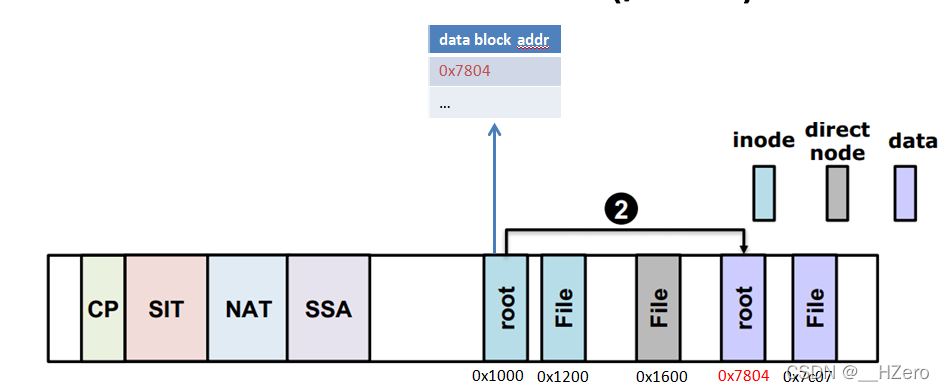
- Setp 3 通过文件名File遍历每一个entry,找到File对应的inode号,通过inode号(==nid)查NAT
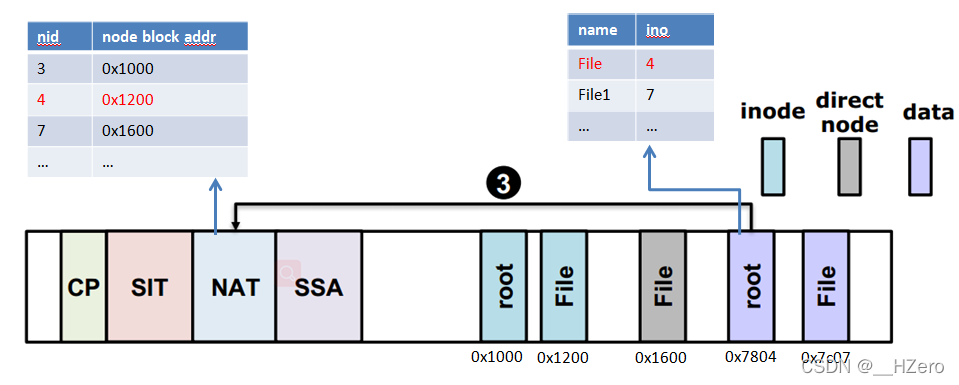
- Setp 4 通过NAT找到File的inode所在的node block地址,它存储了File的direct node的nid(假设为7)
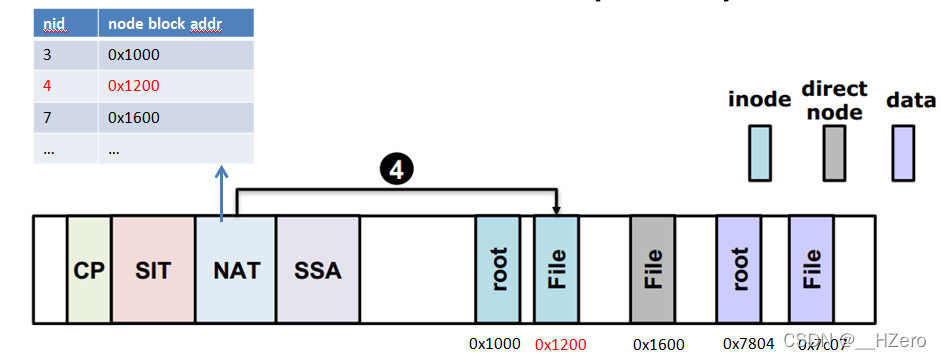
- Setp 5 通过file的inode找到direct node的nid(假设为7),通过查找NAT,找到direct node的node block地址
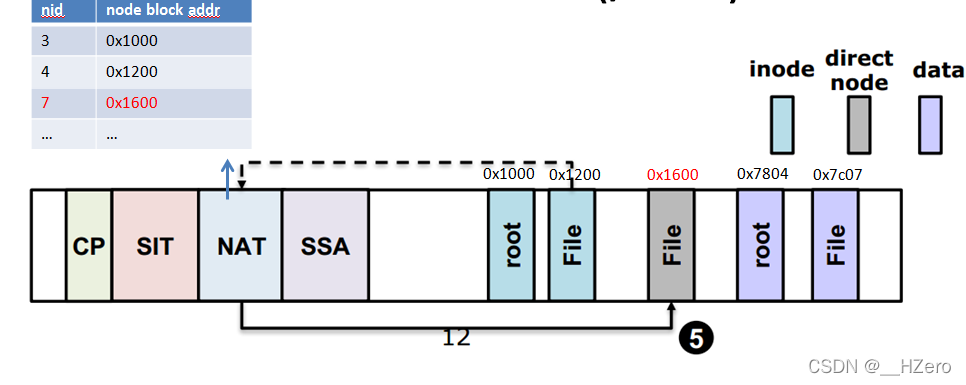
- Setp 6 File的direct node中保存着File的data block的地址,根据这些data block地址就可以读取到File的数据
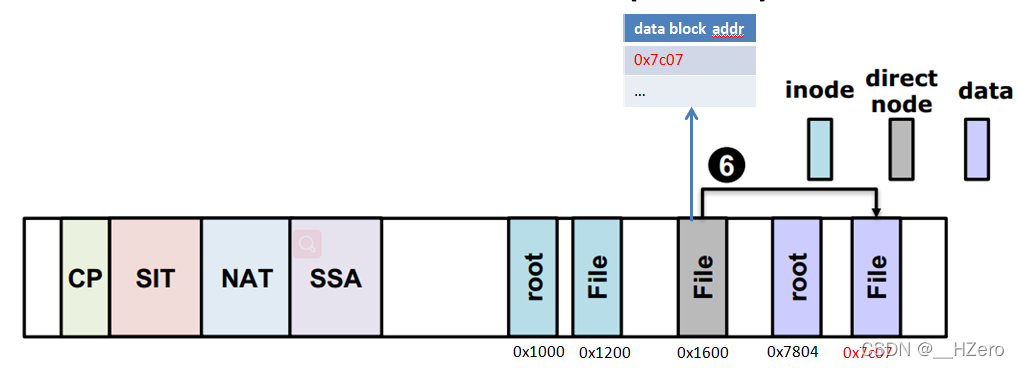
F2FS GC垃圾回收
-
GC回收分为foreground gc和background gc
当没有足够空闲的segment(一般是小于reserved segments)时将启动foreground gc
当系统没有进行IO操作时,将启动background gc thread,回收的时间间隔会根据invalid blocks的多少进行调整
foreground gc采用greedy算法,只考虑dirty invalid blocks数目; background gc采用cost-benefit算法,还考虑了segment的修改时间 -
Cost-benefit算法
cost_benefit = (1 - u) / 2u * age
u: 表示valid block在该section中的比例
1-u: 表示对这个section进行gc后的收益
2u: 表示对这个section的GC的开销,读取Valid block(1个u)然后写入到到新的segment(再1个u)
age: 表示上一次修改距离现在的时间差
NOTE:cost_benefit值越大表示越值得回收
F2FS checkpoint
Checkpoint执行的操作:
- 将page cache中的dirty node和dentry block flush到磁盘;
- Suspend冻结文件系统操作,如create,unlink,mkdir等
- 文件系统元数据NAT, SIT, SSA写入磁盘各自区域;
- 写checkpont pack部分,主要包括:
Header和footer checkpoint page;
NAT bitmap和SIT bitmap
NAT journal和SIT journal
Active segments的summary blocks
Orphan blocks
F2FS recovery
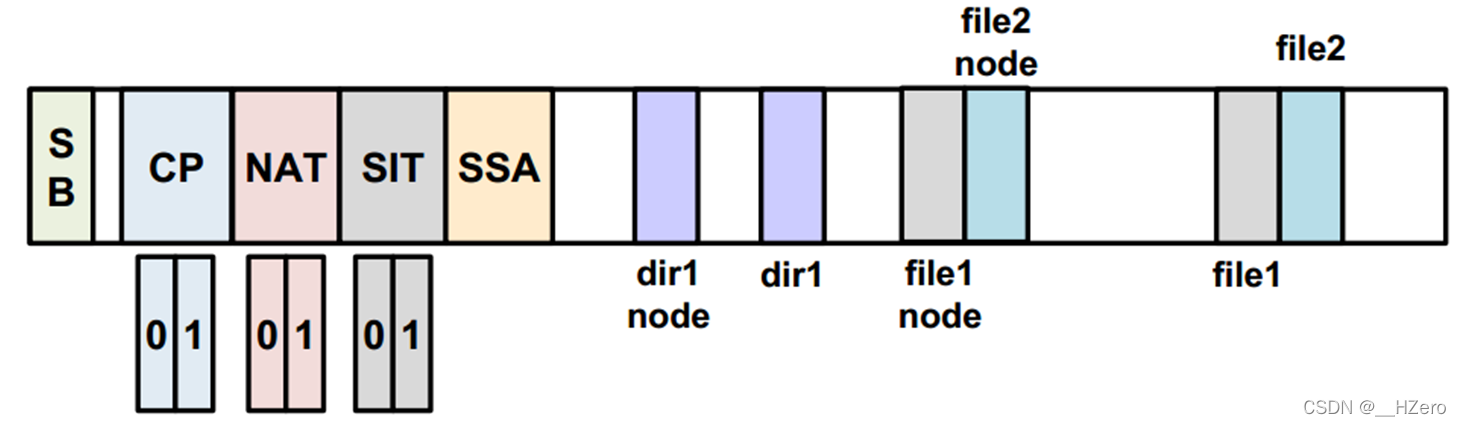
step 1 创建dir1, file1, file2
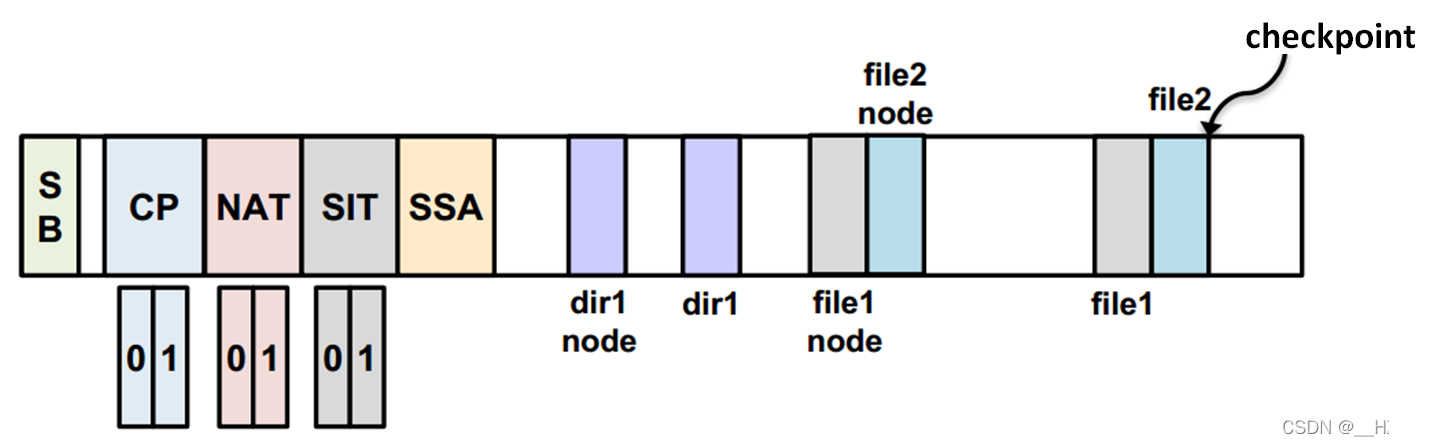
step 2 触发checkpoint,此时数据与元数据保持一致性状态
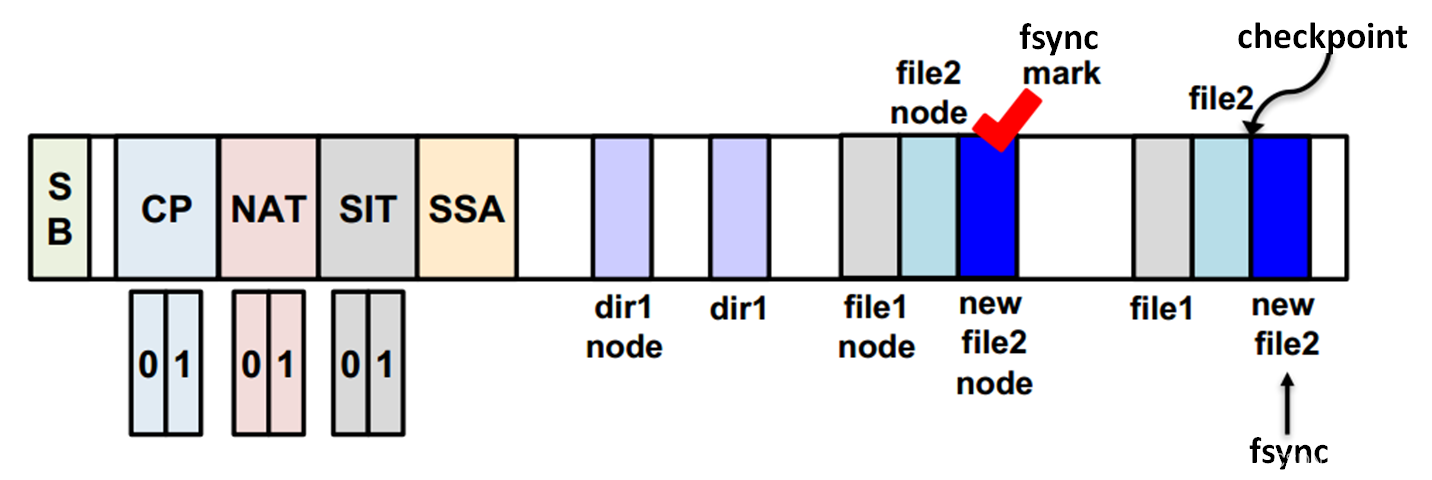
step 3 更新file2, 并将记录file2更新数据块号的new file2 node作fsync mark标记
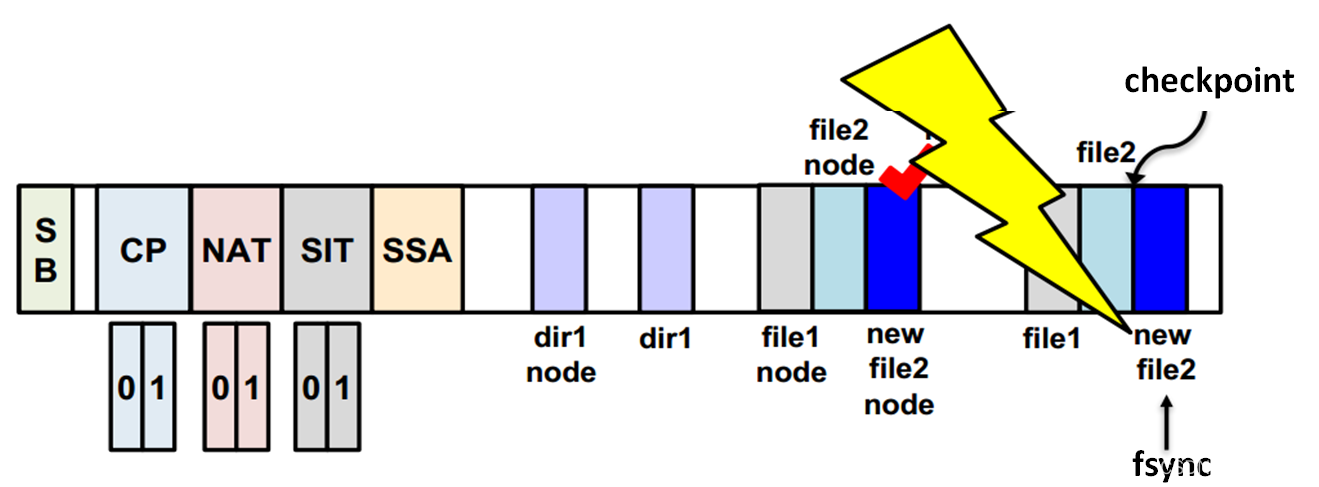
step 4 此时更新的new file2后并没有执行checkpoint,发生了断电,数据和元数据不一致
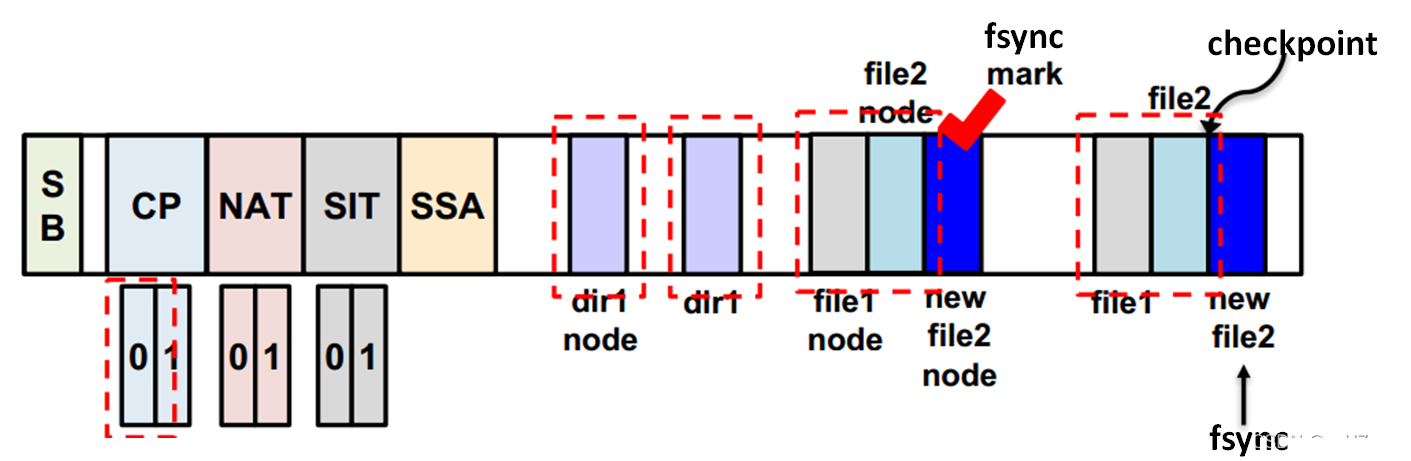
step 5 执行修复,首先通过roll-back,找到最新的稳定的checkpoint pack版本
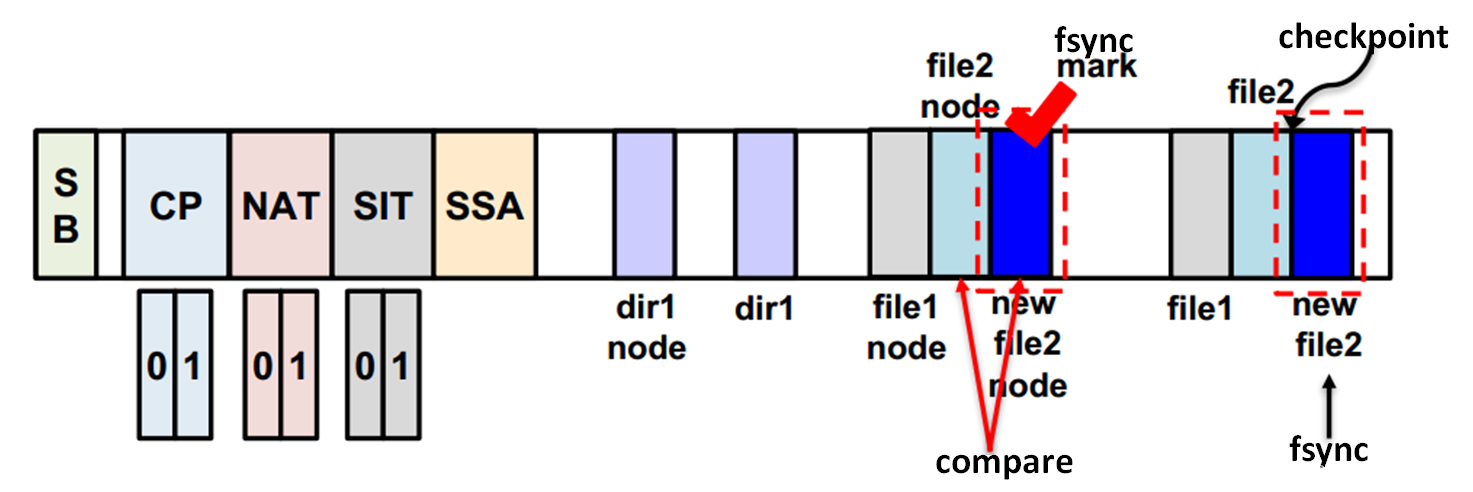
step 6 比较file2 node和new file2 node中所记录的data block块号是否相等,如果不相等将执行roll-forward恢复
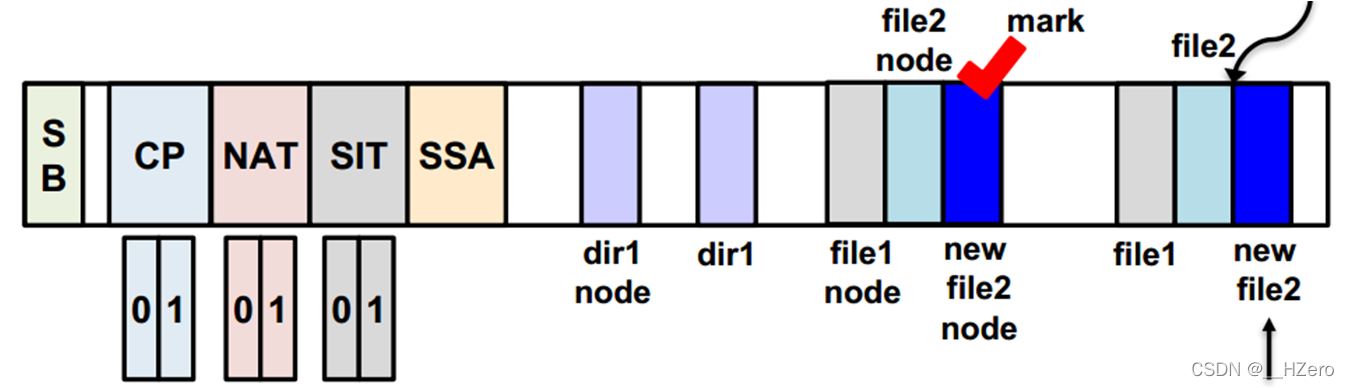
step 6 执行新的checkpoint
参考文档
Lee et. al, F2FS: A New File System for Flash Storage, FAST ’15
Linux/Document/filesystems/f2fs.txt
F2FS技术拆解
F2FS源码分析-1.3 [F2FS 元数据布局部分] Checkpoint结构
f2fs系列文章——sit/nat_version_bitmap
http://www.ssdfans.com/?p=5135 greedy和cost-and-benefit
https://github.com/jasonactions/f2fs-initial f2fs初始版本注释

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)