sed 的基本使用【详图】
sed 的基本使用【图解】1.sed介绍sed 在处理文本时是逐行读取文件内容,读到匹配的行就根据指令做操作,不匹配就跳过。sed 的使用方法,调用 sed 命令的语法有两种:在命令行指定 sed 指令对文本进行处理:sed+选项'指令'文件先将 sed 指令保存到文件中,将该文件作为参数进行调用,sed+选项 -f 包含sed指令的文件 文件sed的常用选项:选项含义-e它告诉sed将下一个参
·
sed 的基本使用【图解】
1.sed介绍
sed 在处理文本时是逐行读取文件内容,读到匹配的行就根据指令做操作,不匹配就跳过。
-
sed 的使用方法,调用 sed 命令的语法有两种:
-
在命令行指定 sed 指令对文本进行处理:
sed+选项'指令'文件 -
先将 sed 指令保存到文件中,将该文件作为参数进行调用,
sed+选项 -f 包含sed指令的文件 文件
sed的常用选项:
选项 含义 -e 它告诉sed将下一个参数解释为一个sed指令,只有当命令行上给出多个sed指令时才需要使用-e选项 -f 后跟保存了sed指令的文件 -i 直接对内容进行修改,不加-i时默认只是预览,不会对文件做实际修改 -n 取消默认输出,sed默认会输出所有文本内容,使用-n参数后只显示处理过的行 sed中的编辑命令:
命令 含义 a-追加 向匹配行后面插入内容 i-插入 向匹配行前插入内容 c-更改 更改匹配行的内容 d-删除 删除匹配的内容 s-替换 替换掉匹配的内容 p-打印 打印出匹配的内容,通常与-n选项和用 = 用来打印被匹配的行的行号 n 读取下一行,遇到n时会自动跳入下一行 r,w 读和写编辑命令,r用于将内容读入文件,w用于将匹配内容写入到文件 -
2.使用示例
2.1 追加 --> a
sed 'lahello' test.txt #向第一行后面添加hello,1表示行号
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n5vt7880-1647424261311)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111161104343.png)]](https://img-blog.csdnimg.cn/95f47982a5b84002a9924c79723bdb32.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_19,color_FFFFFF,t_70,g_se,x_16)
上图中,1代表了行号,a是选择追加,但因为没有使用 -i ,所以最后只是预览模式,并没有保存
使用参数 -i如下已保存
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oWqvWRaF-1647424261312)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111161746894.png)]](https://img-blog.csdnimg.cn/4b79e8b56bb84784bc20096c636ba5f4.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_18,color_FFFFFF,t_70,g_se,x_16)
- 批量添加
sed '/22/achina' test.txt
#向内容11后面添加china,如果文件中有多行包括22,则每一行后面都会添加
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xvcIy1Ez-1647424261312)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111163535849.png)]](https://img-blog.csdnimg.cn/097e5d2e82c049d9a858aad8314e0ca1.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_18,color_FFFFFF,t_70,g_se,x_16)
- $表示在最后一行添加
sed '$a富强' test.txt #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XXcFjkK1-1647424261313)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111163753634.png)]](https://img-blog.csdnimg.cn/f536246e69c443508b6ff2ef4103ef6f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_18,color_FFFFFF,t_70,g_se,x_16)
- 在第三行之前插入good
sed '3igood' test.txt # 在第三行之前插入good
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5DYcs0Kx-1647424261314)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111164910955.png)]](https://img-blog.csdnimg.cn/ec9bde24696a4bd0b13505e5dbfd36cb.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
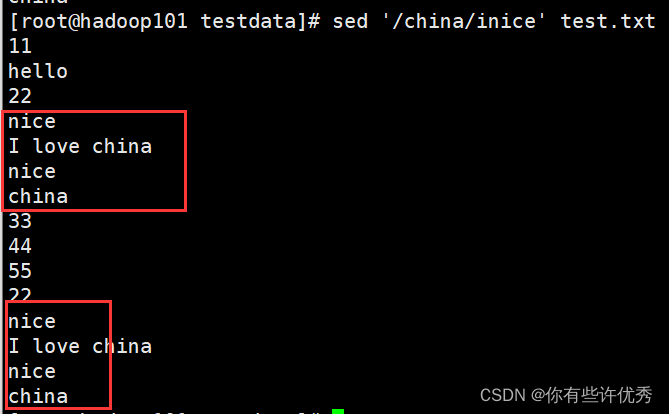
- 在包含china之前的行插入数据,如果含多个,则都会插入
sed '/china/inice' test.txt # 在包含china之前的行插入数据,如果含多个,则都会插入
2.2 更改 --> c
sed '7cedg' test.txt # 将第7行的替换为edg
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BG9Sp7YE-1647424261316)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111171214382.png)]](https://img-blog.csdnimg.cn/10a91c7ad7384f4cba3515936dd3d1a3.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_15,color_FFFFFF,t_70,g_se,x_16)
- 批量替换
sed '/22/cgoto' test.txt #将包含22的全部替换为goto
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vuqjKYKo-1647424261316)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111171542257.png)]](https://img-blog.csdnimg.cn/9d59b535e1354b459b880fc3e0693168.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_18,color_FFFFFF,t_70,g_se,x_16)
2.3 删除 --> d
sed '7d' test.txt #删除第7行的数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zu5Posvy-1647424261317)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111174129583.png)]](https://img-blog.csdnimg.cn/ffdab407306a4b5fafedeed8cf06c228.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_20,color_FFFFFF,t_70,g_se,x_16)
- 隔行删除
sed '1~2d' test.txt #从第一行开始删除,每隔两行删掉一个,删掉奇数行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pR6yi1E5-1647424261317)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111175711612.png)]](https://img-blog.csdnimg.cn/c6d6d7667a164651abda81c84fd03c20.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_15,color_FFFFFF,t_70,g_se,x_16)
- 范围删除
sed '1,2d' test.txt #删掉1-2行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d4M1RZ5Y-1647424261318)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111175839810.png)]](https://img-blog.csdnimg.cn/f3d86c5964884a2e9d8bc3d339802c69.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_15,color_FFFFFF,t_70,g_se,x_16)
- 删除 除了1-2行之外的行
sed '1,2!d' test.txt #除了1-2行之外的行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fpXHh8ky-1647424261318)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111180034866.png)]](https://img-blog.csdnimg.cn/7973cd9dd8694ae395f53a6c0c1a2c09.png)
- 删除最后一行
sed '$d' test.txt #删除最后一行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PTWj2EjE-1647424261319)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111180149073.png)]](https://img-blog.csdnimg.cn/7aff7d8611b945989bf813f8fa515366.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_14,color_FFFFFF,t_70,g_se,x_16)
- 删除 除了包含china之外的行
sed '/china/!d' test.txt #删除 除了包含china之外的行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8iDSEdrm-1647424261319)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211111180325158.png)]](https://img-blog.csdnimg.cn/04e51b54ea434d9d97902ae9bc2440ee.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_17,color_FFFFFF,t_70,g_se,x_16)
- 删除最后一行
sed '$d' test.txt #删除最后一行
- 删除匹配55的行以及下一行
sed '/55/,+1d' test.txt #删除匹配55的行以及下一行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qUmD06Ku-1647424261320)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115111309040.png)]](https://img-blog.csdnimg.cn/7c1191dfeef34bdc8d46612afb86df24.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EMIdW5UN-1647424261320)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115111512337.png)]](https://img-blog.csdnimg.cn/55c6722a374348dd8bfbac44fe795b0f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
注:匹配了 ‘I love china’ 那行,后面的 'china '已经被删除
- 删除从匹配到china的行到最后一行
sed '/china/,$d' test.txt #删除从匹配到china的行到最后一行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PHQyhijw-1647424261321)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115111807363.png)]](https://img-blog.csdnimg.cn/5b7976d465814df5800429333f21f67b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
- 删除空行
sed '/^$/d' test.txt #删除空行 (开始^到结束$中内容没有,因此匹配的是空行)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FEvhpcES-1647424261322)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115112253727.png)]](https://img-blog.csdnimg.cn/1c0874bc31b946c9bcbe39e0a76cb814.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_14,color_FFFFFF,t_70,g_se,x_16)
- 删除不匹配的行
sed '/china\|^$/!d' test.txt
#删除不匹配 china 或者 空行 的行
#/china\|^$/表示匹配china或者空行,!取反
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GXMjVgAw-1647424261322)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115112517502.png)]](https://img-blog.csdnimg.cn/c6af0ca26008421da460884d8a89ed41.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_17,color_FFFFFF,t_70,g_se,x_16)
- 删除1~5行中,匹配内容china的行
sed '1,5{/china/d}' test.txt #删除1~5行中,匹配内容china的行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x4Z6bDW3-1647424261322)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115113125170.png)]](https://img-blog.csdnimg.cn/a8a25ce464d4428282ee226c33eda149.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_17,color_FFFFFF,t_70,g_se,x_16)
2.4 替换 --> s
- love替换成爱,默认只替换每行匹配到的第一个
sed 's/love/爱/' test.txt #将love替换成爱,默认只替换每行第一个love
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gUSbhkqQ-1647424261323)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115114059050.png)]](https://img-blog.csdnimg.cn/af1302415e6444f88153506419cdf4d6.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
# g可将所有love替换成爱
sed 's/love/爱/g' test.txt
#2可将每行第二个匹配到的love替换成爱
sed 's/love/爱/2' test.txt
g可将所有的匹配替换
sed -n 's/china/中国/gpw yi.txt' test.txt
#将每行中所有匹配的china替换成中国,并将替换后的行采用覆写的方式写入yi.txt文件中。
替换前:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jAuaMpob-1647424261323)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115115243392.png)]](https://img-blog.csdnimg.cn/181415beb5a64cc59fcc309c44361bdc.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
替换后:

- 匹配有‘#’号的行,替换匹配行中逗号后 的所有内容为空
sed '/#/s/,.*//g' test.txt # 匹配有‘#’号的行,替换匹配行中逗号后 的所有内容为空
# (,.*)表示逗号后的所在内容
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KTlqMGzp-1647424261324)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115142303297.png)]](https://img-blog.csdnimg.cn/556ebfbd9f2f4c1c9e9c9aeb18eea449.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
- 替换每行中的最后两个字符为空
sed 's/..$//g' test.txt
#替换每行中的最后两个字符为空
# 每个点代表一个字符,$表示匹配末尾 (..$)表示匹配最后两个字符
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ke2ZIqCP-1647424261324)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115142528096.png)]](https://img-blog.csdnimg.cn/28b73d8c19734dcdb0115c1bb8fc170c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_16,color_FFFFFF,t_70,g_se,x_16)
- 将文件中以’#'开头的行替换成空行
sed 's/^#.*//' test.txt
# 将文件中以'#'开头的行替换成空行
# ( ^#)表示匹配以#开头,(.*)代表所有内容
sed 's/^#.*//;/^$/d' test.txt
#先替换test.txt文件中所有注释的空行为空行,然后删除空行,替换和删除操作中间用分号隔开
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gr1nzmV4-1647424261325)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115144301110.png)]](https://img-blog.csdnimg.cn/f1331fc5ae28442fb99713b64ec1ea5a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_17,color_FFFFFF,t_70,g_se,x_16)
- 将每一行中行首的数字加上一个小括号
sed 's/^[0-9]/(&)/' yi.txt #将每一行中行首的数字加上一个小括号 (^[0-9])表示行首是数字,&符号代表匹配的内容
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bndSWQVI-1647424261325)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115153109117.png)]](https://img-blog.csdnimg.cn/0da61b0930fd41a2aa9b15400b786434.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_18,color_FFFFFF,t_70,g_se,x_16)
2.5 打印 --> p
sed -n '4p' test.txt #打印文件中的第4行内容
sed -n '2~2p' test.txt #从第二行开始,每隔两行打印一行,波浪号后面的2表示步长
sed -n '$p' test.txt #打印文件的最后一行
sed -n '1,3p' test.txt #打印1到3行
sed -n '3,$p' test.txt #打印从第3行到最后一行的内容
sed -n '/love/p' test.txt #逐行读取文件,打印匹配love的行
sed -n '/china/,3p' test.txt #逐行读取文件,打印从匹配china的行到第3行的内容
sed -n '1,/china/p' test.txt #打印第一行到匹配china的行
sed -n '/\*/,$p' test.txt #打印从匹配*的行到最后一行的内容
sed -n '/\*/,+1p' test.txt #打印匹配*的行及其向后一行,如果有多行匹配too,则匹配的每一行都会向后多打印一行
sed -n '/china/,/\*/p' 1.txt #打印从匹配内容china到匹配内容*的行
2.6 行号 --> =
sed -n "$=" test.txt # 打印文件最后一行的行号
sed -n '/error/=' test.txt #打印匹配error的行的行号
- 打印匹配error的行的行号和内容(可用于查看日志中有error的行及其内容)
sed -n '/error/{=;p}' test.txt #打印匹配error的行的行号和内容(可用于查看日志中有error的行及其内容)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3fDatKl1-1647424261325)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115160546747.png)]](https://img-blog.csdnimg.cn/cc0043e044ff433d8929eb9b8aae6d18.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_19,color_FFFFFF,t_70,g_se,x_16)
2.7 读取 --> r
- 将文件2.txt中的内容,读入1.txt中,会在1.txt中的每一行后都读入2.txt的内容
sed 'r 2.txt' 1.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aolJiLTz-1647424261326)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115161838045.png)]](https://img-blog.csdnimg.cn/0c0726dfb47048888cf4cde69dad6baf.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g5pyJ5Lqb6K645LyY56eA,size_13,color_FFFFFF,t_70,g_se,x_16)
- 在1.txt第三行之后插入文件2.txt的内容
sed '3r 2.txt' 1.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AZPN1LPJ-1647424261326)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115162010985.png)]](https://img-blog.csdnimg.cn/ed535fb738c14e41a404ba20ea4887c7.png)
- 在匹配/的行之后插入文件2.txt的内容,如果1.txt中有多行匹配则在每一行之后都会插入
sed '/\//r 2.txt' 1.txt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fWfdELgl-1647424261327)(C:\Users\nice\AppData\Roaming\Typora\typora-user-images\image-20211115162759878.png)]](https://img-blog.csdnimg.cn/3ae7f99f69344b5295b77912e145f431.png)
sed '$r 2.txt' 1.txt #在1.txt的最后一行插入2.txt的内容
2.8 写入 --> w
sed -n 'w 2.txt' 1.txt
#将1.txt文件的内容写入2.txt文件,如果2.txt文件不存在则创建,如果2.txt存在则覆盖之前的内容
sed -n -e '1w 2.txt' -e '$w 2.txt' 1.txt #将1.txt的第1行和最后一行内容写入2.txt
sed -n -e '1w 2.txt' -e '$w 3.txt' 1.txt #将1.txt的第1行和最后一行分别写入2.txt和3.txt
sed -n '/abc\|123/w 2.txt' 1.txt #将1.txt中匹配abc或123的行的内容,写入到2.txt中
sed -n '/666/,$w 2.txt' 1.txt #将1.txt中从匹配666的行到最后一行的内容,写入到2.txt中
sed -n '/xyz/,+2w 2.txt' 1.txt #将1.txt中从匹配xyz的行及其后2行的内容,写入到2.txt中
2.9 sed在脚本中的使用
批量更改当前目录中的文件后缀名:
-
1
#!/bin/bash if [ $# -ne 2 ];then #判断用户的输入,如果参数个数不为2则打印脚本用法 echo "Usage:$0 + old-file new-file" exit fi for i in *$1* #对包含用户给定参数的文件进行遍历 do if [ -f $i ];then iname=`basename $i` #获取文件名 newname=`echo $iname | sed -e "s/$1/$2/g"` #对文件名进行替换并赋值给新的变量 mv $iname $newname #对文件进行重命名 fi done exit 666 -
2
#!/bin/bash read -p "input the old file:" old #提示用户输入要替换的文件后缀 read -p "input the new file:" new [ -z $old ] || [ -z $new ] && echo "error" && exit #判断用户是否有输入,如果没有输入怎打印error并退出 for file in `ls *.$old` do if [ -f $file ];then newfile=${file%$old} #对文件进行去尾 mv $file ${newfile}$new #文件重命名 fi done -
3
#!/bin/bash if [ $# -ne 2 ];then #判断位置变量的个数是是否为2 echo "Usage:$0 old-file new-file" exit fi for file in `ls` #在当前目录中遍历文件 do if [[ $file =~ $1$ ]];then #对用户给出的位置变量$1进行正则匹配,$1$表示匹配以变量$1的值为结尾的文件 echo $file #将匹配项输出到屏幕进行确认 new=${file%$1} #对文件进行去尾处理,去掉文件后缀保留文件名,并将文件名赋给变量new mv $file ${new}$2 #将匹配文件重命名为:文件名+新的后缀名 fi done -
2
echo "Usage:$0 old-file new-file" exit fi for file in `ls` #在当前目录中遍历文件 do if [[ $file =~ $1$ ]];then #对用户给出的位置变量$1进行正则匹配,$1$表示匹配以变量$1的值为结尾的文件 echo $file #将匹配项输出到屏幕进行确认 new=${file%$1} #对文件进行去尾处理,去掉文件后缀保留文件名,并将文件名赋给变量new mv $file ${new}$2 #将匹配文件重命名为:文件名+新的后缀名 fi done

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)