Hadoop详细集群搭建
Hadoop详细安装环境:在虚拟机上,或者租一个服务器(用学生证可以认证白嫖喔,阿里云服务器等)
Hadoop详细安装
环境:在虚拟机上,或者租一个服务器(用学生证可以认证白嫖喔,阿里云服务器等)
本机使用工具:VMware® Workstation 16 Pro、MobaXterm_Personal_10.5
1.Linux搭建集群(三台服务器)
需注意:个人电脑内存4G的只能搭建一台、8G或16G及以上的可以搭建两台及两台以上
1.1新建虚拟机
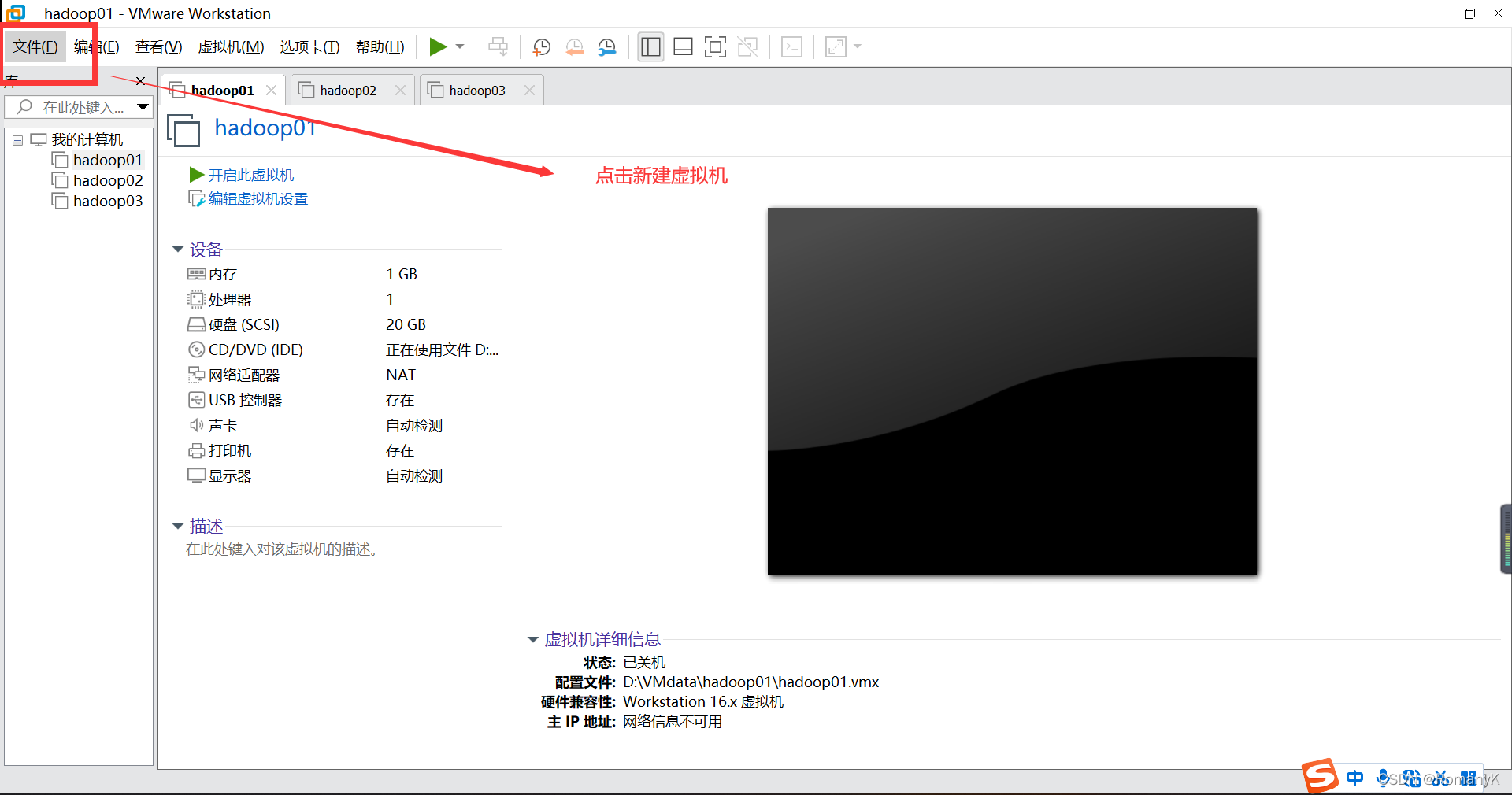
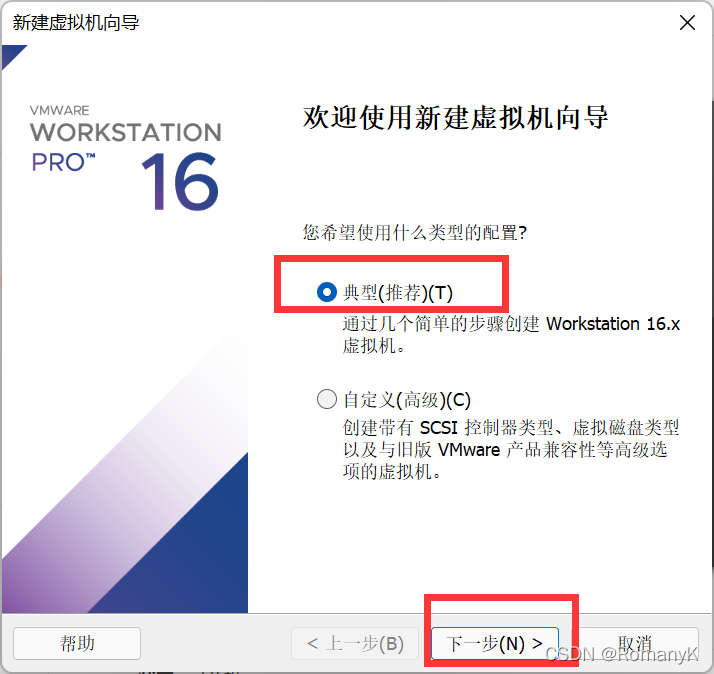
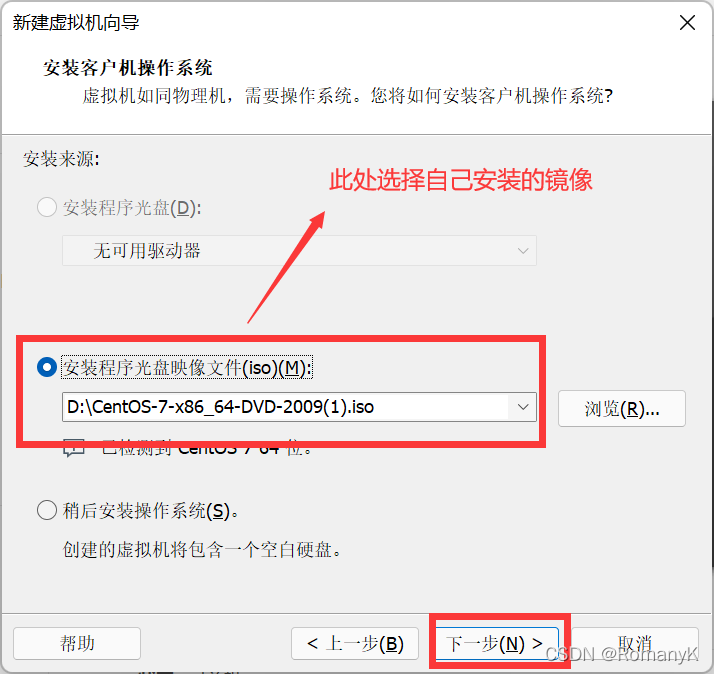
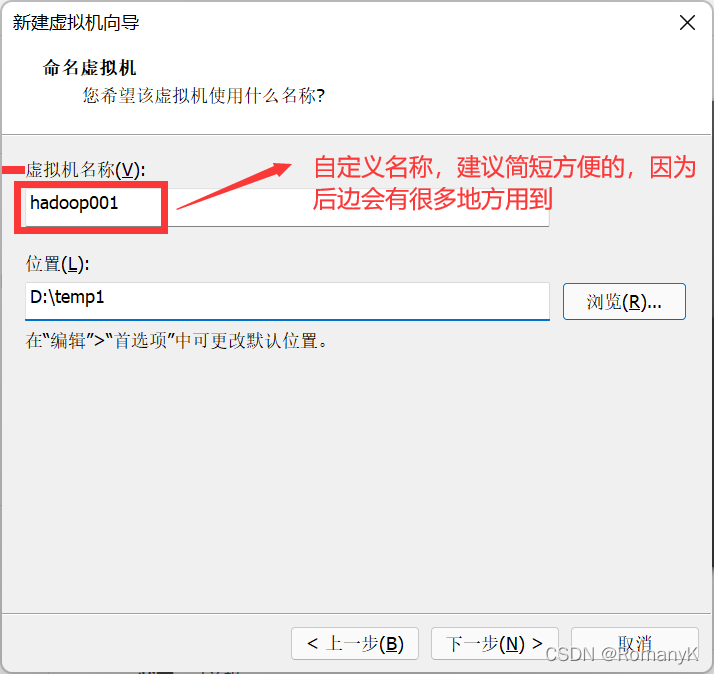
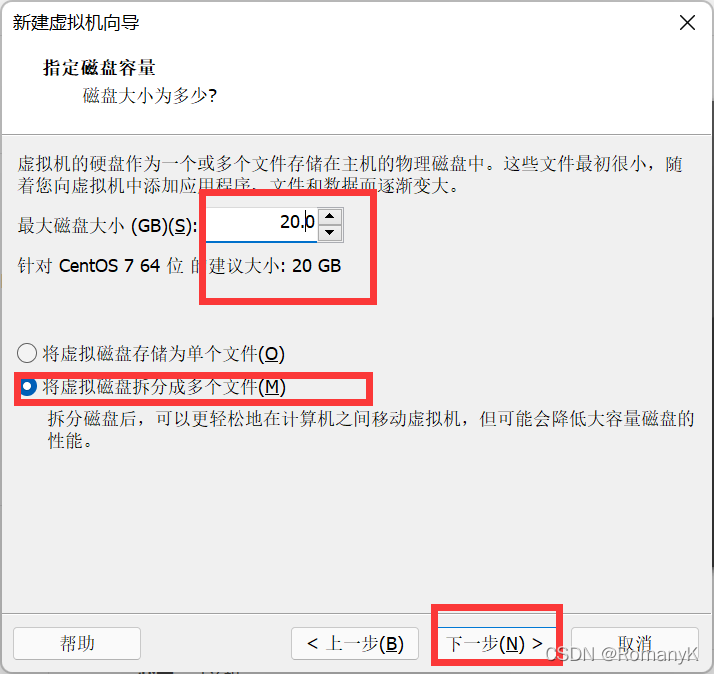
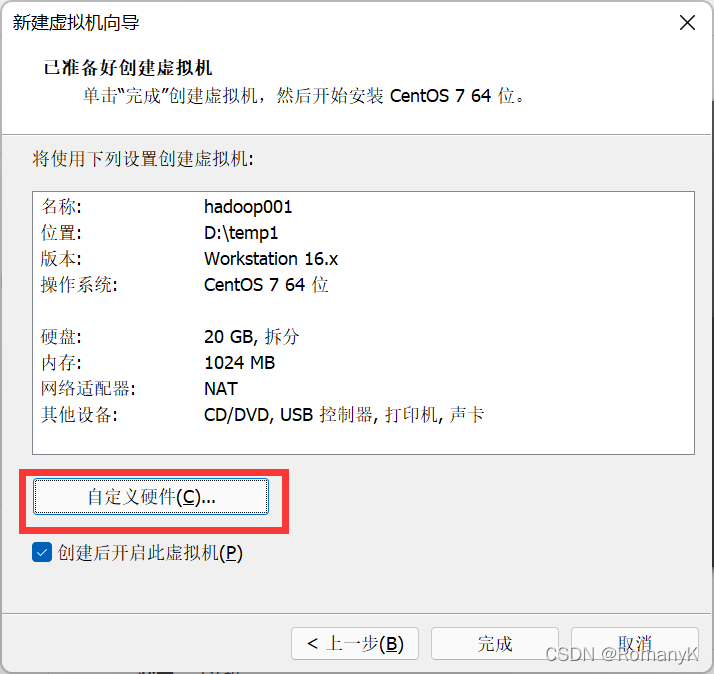
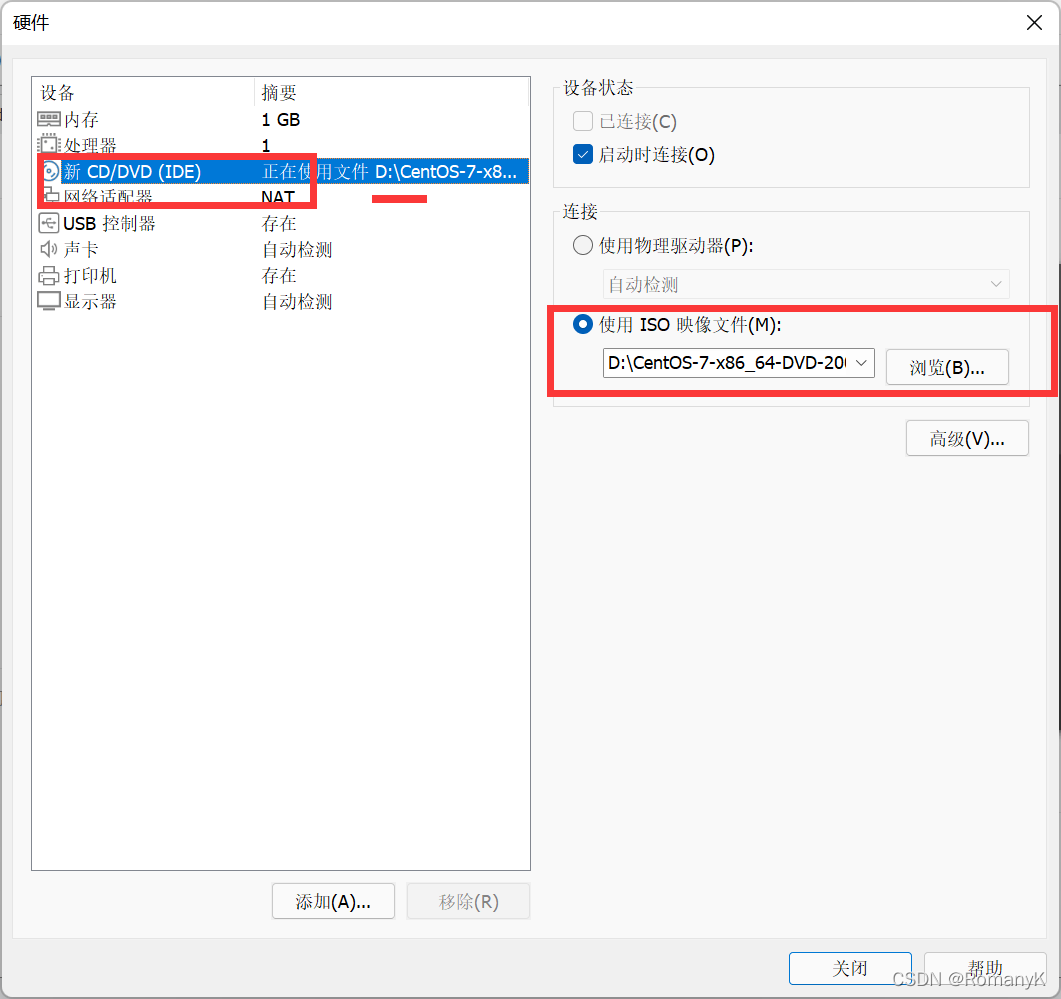
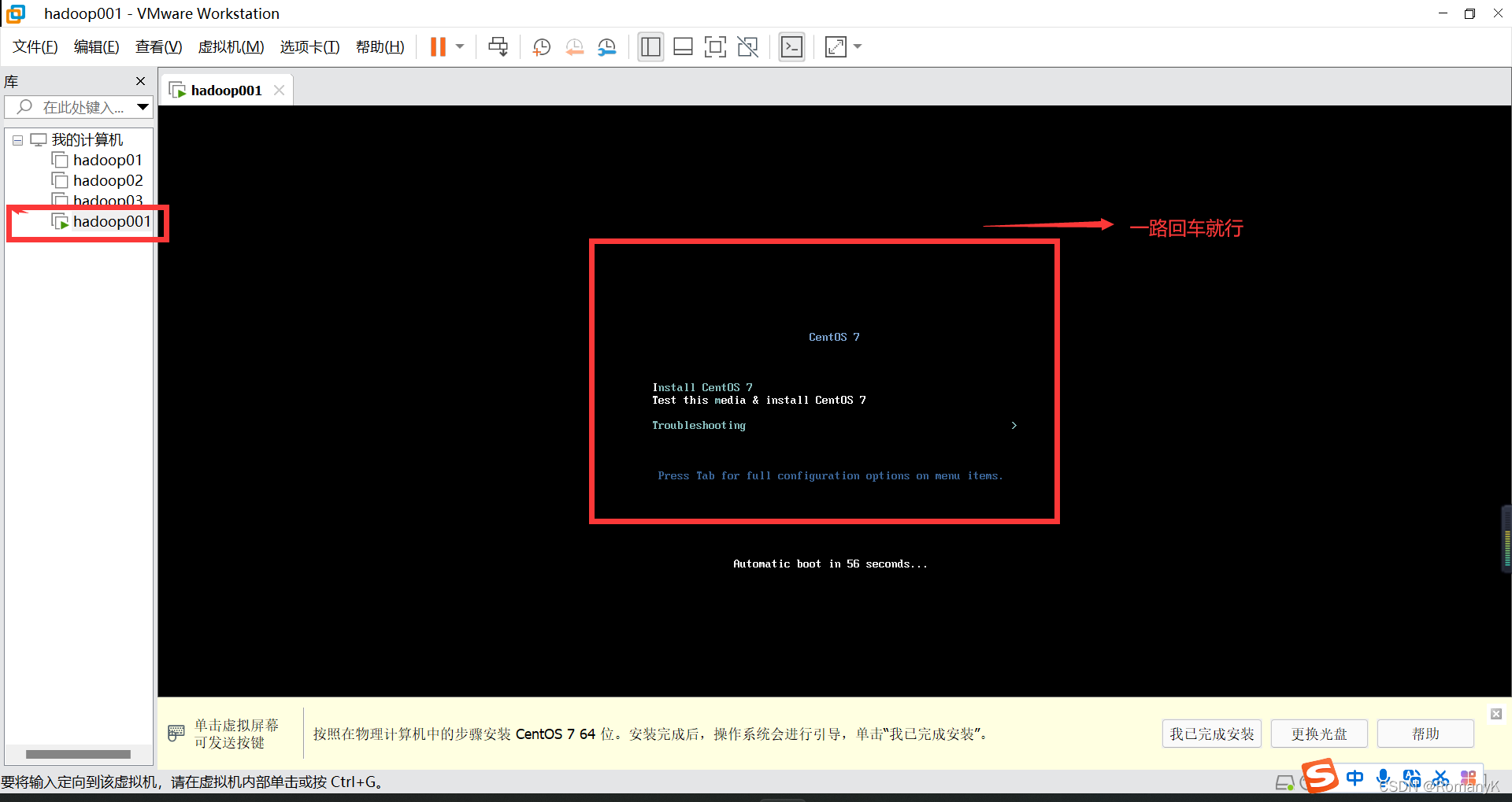
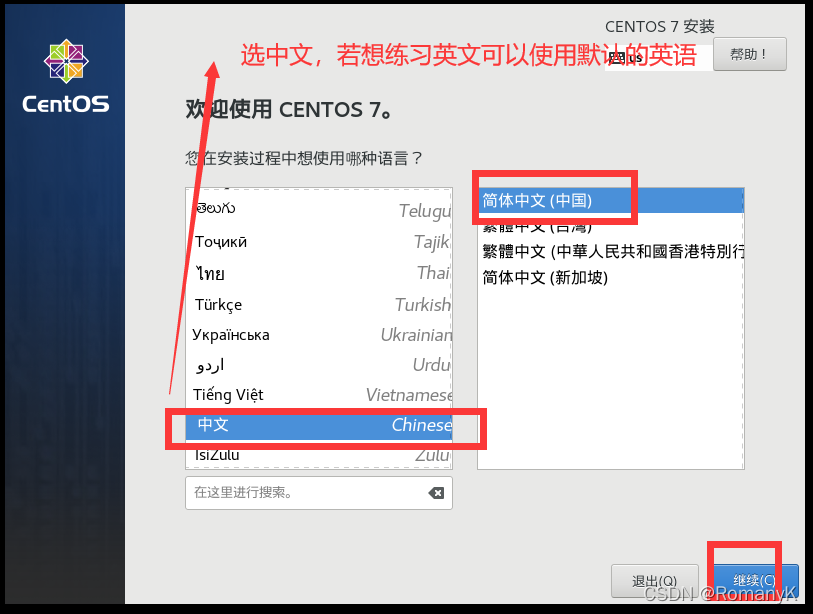
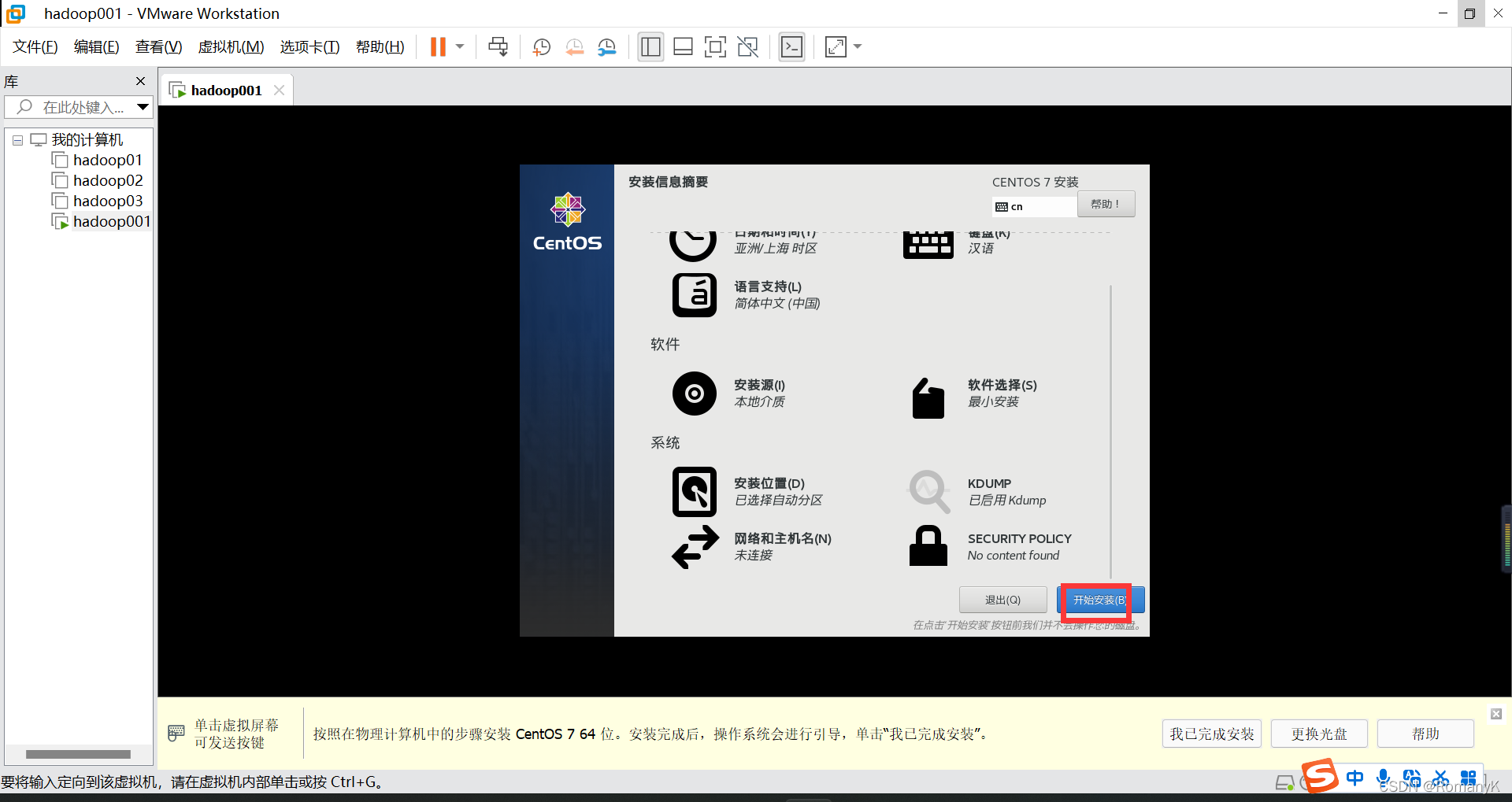
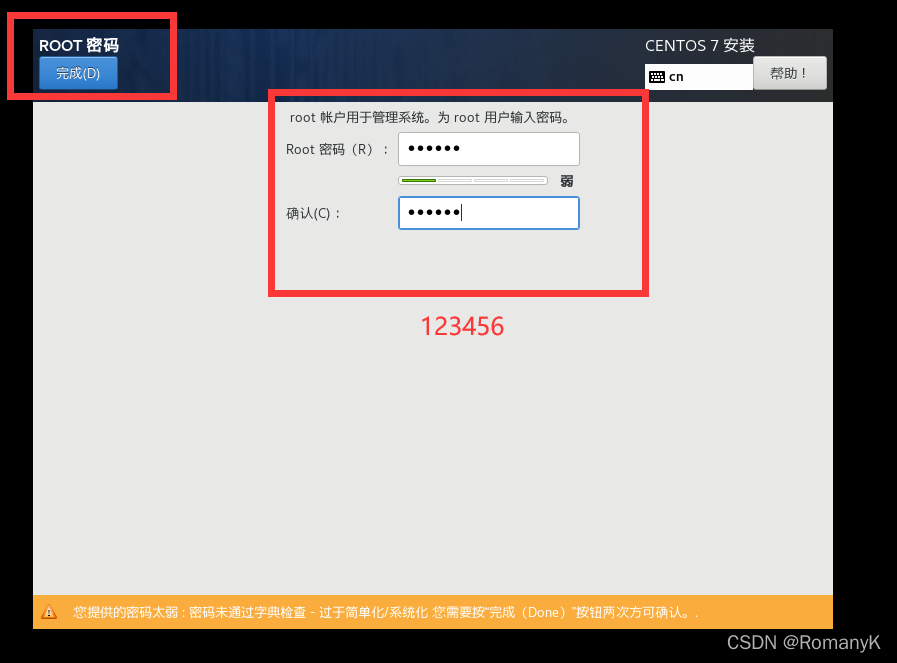
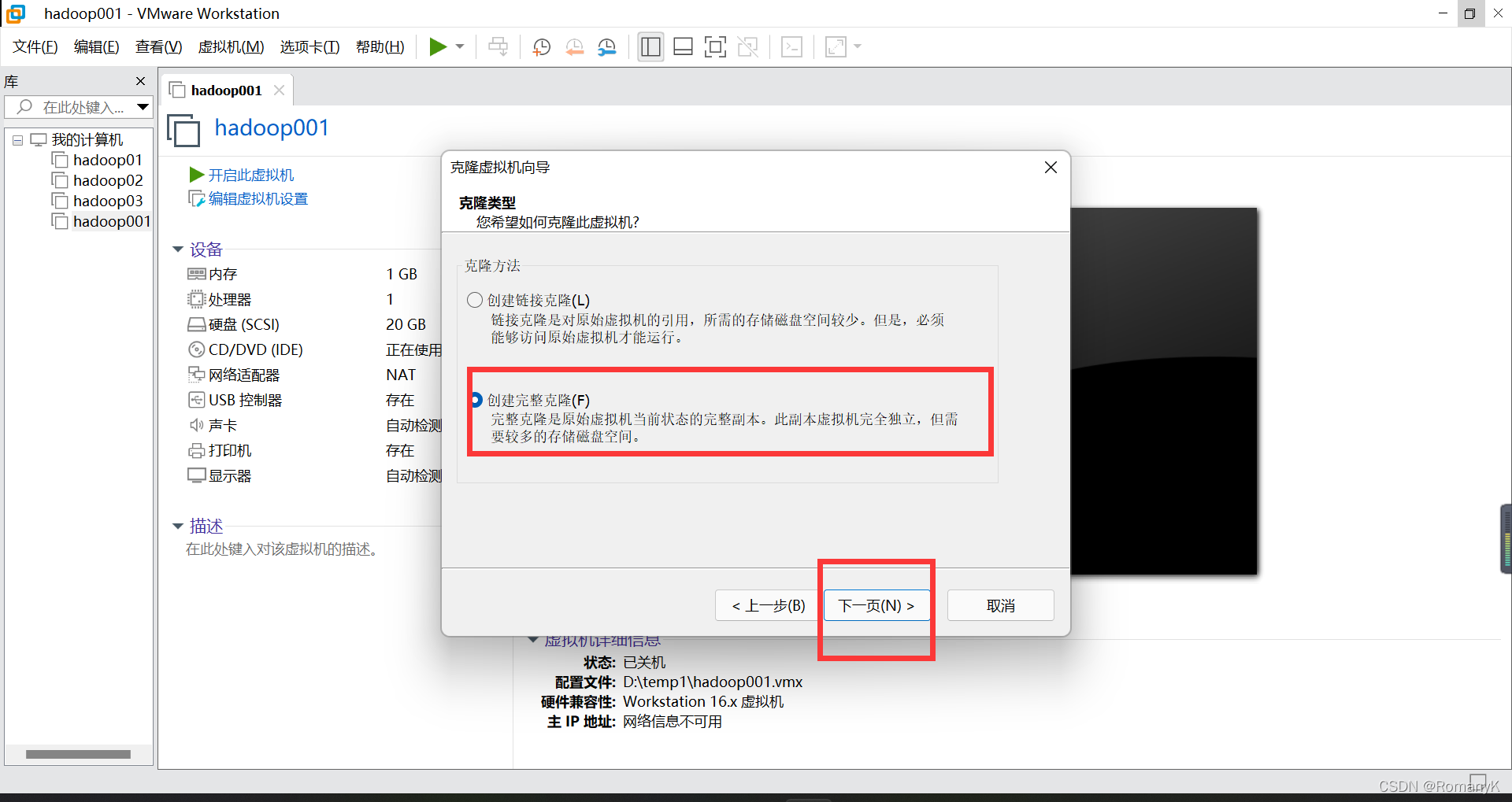
1.2克隆两台虚拟机
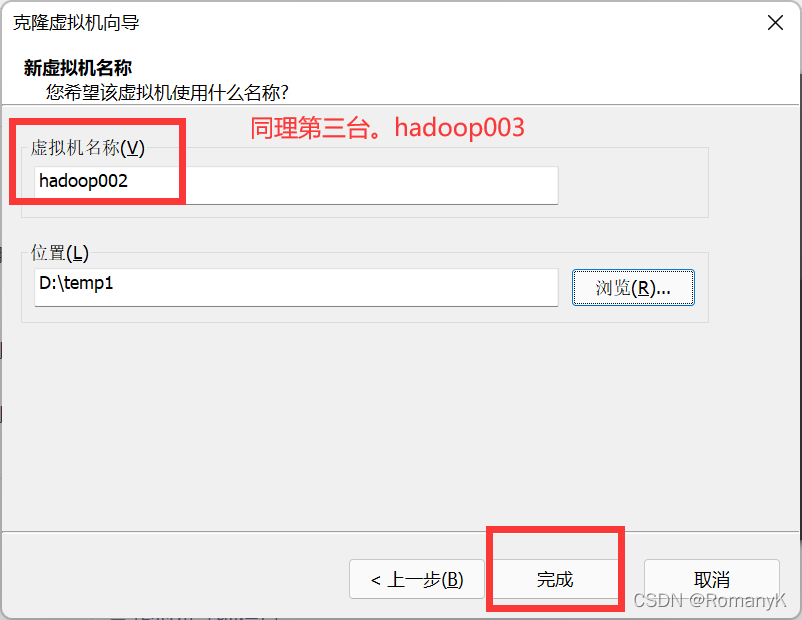
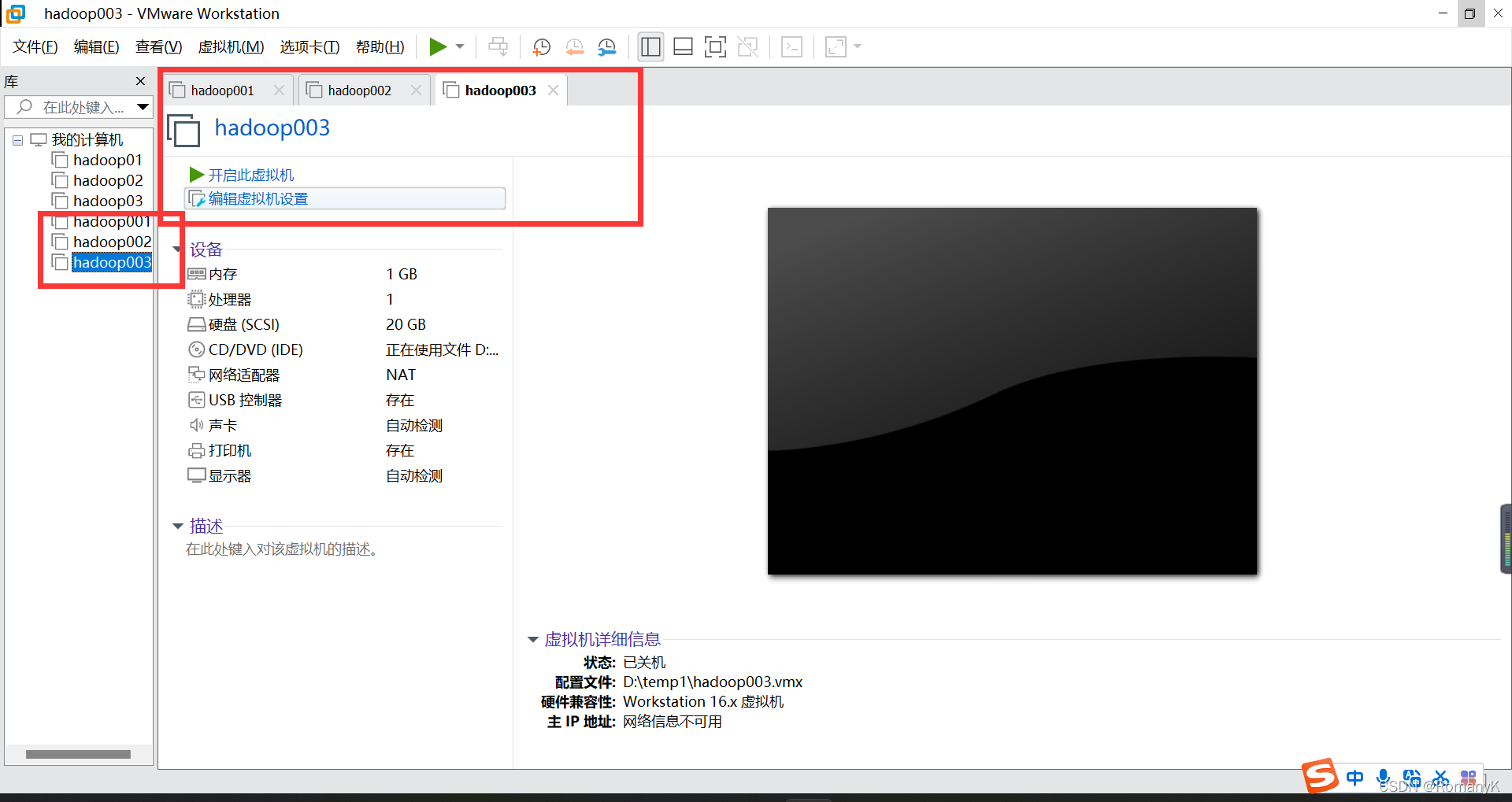
1.3网卡配置
1.3.1第一台hadoop001 (192.168.20.111)
先只启动hadoop001
vi /etc/sysconfig/network-scripts/ifcfg-ens33
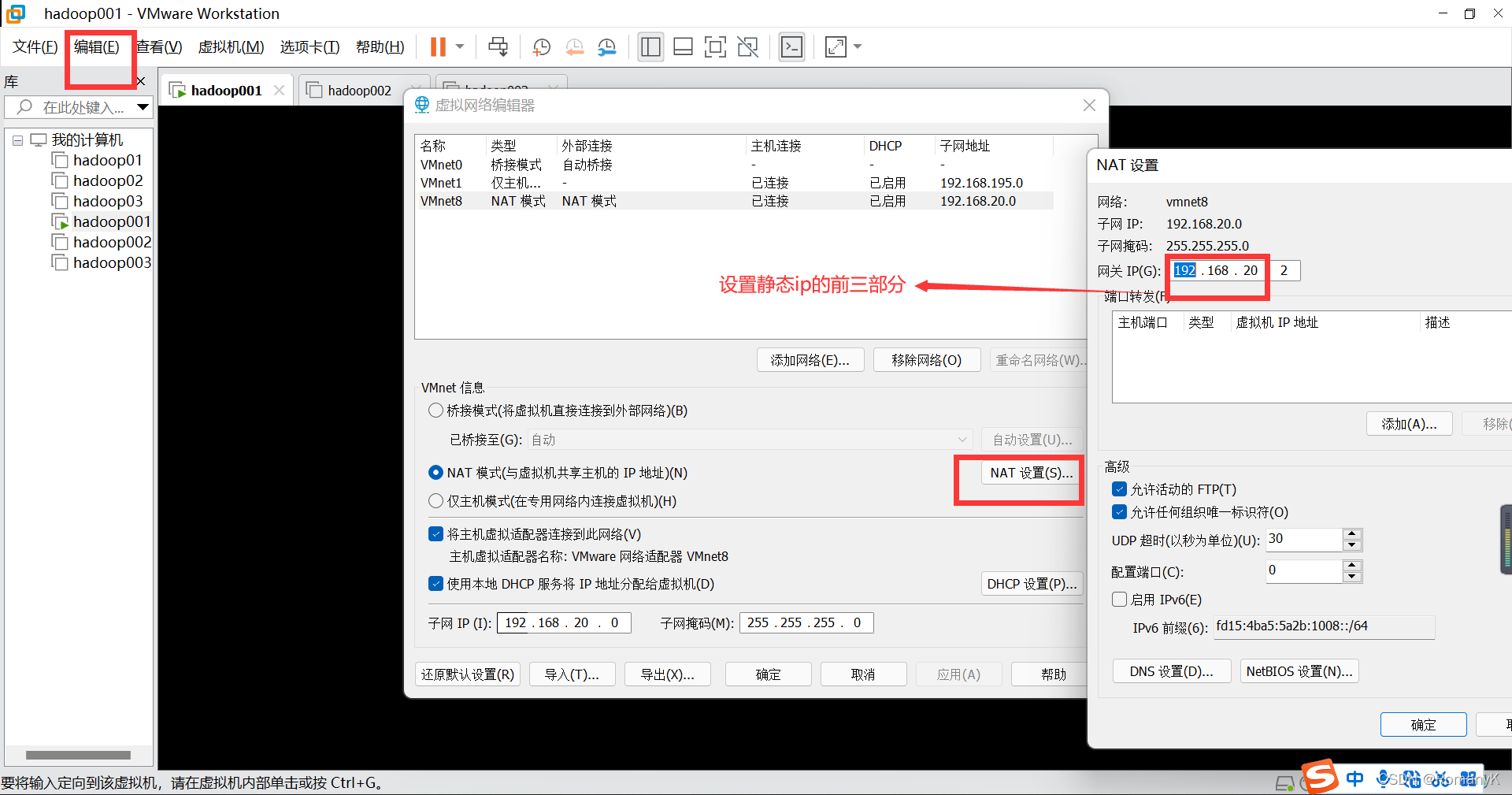

按Esc后输入":wq",保存退出
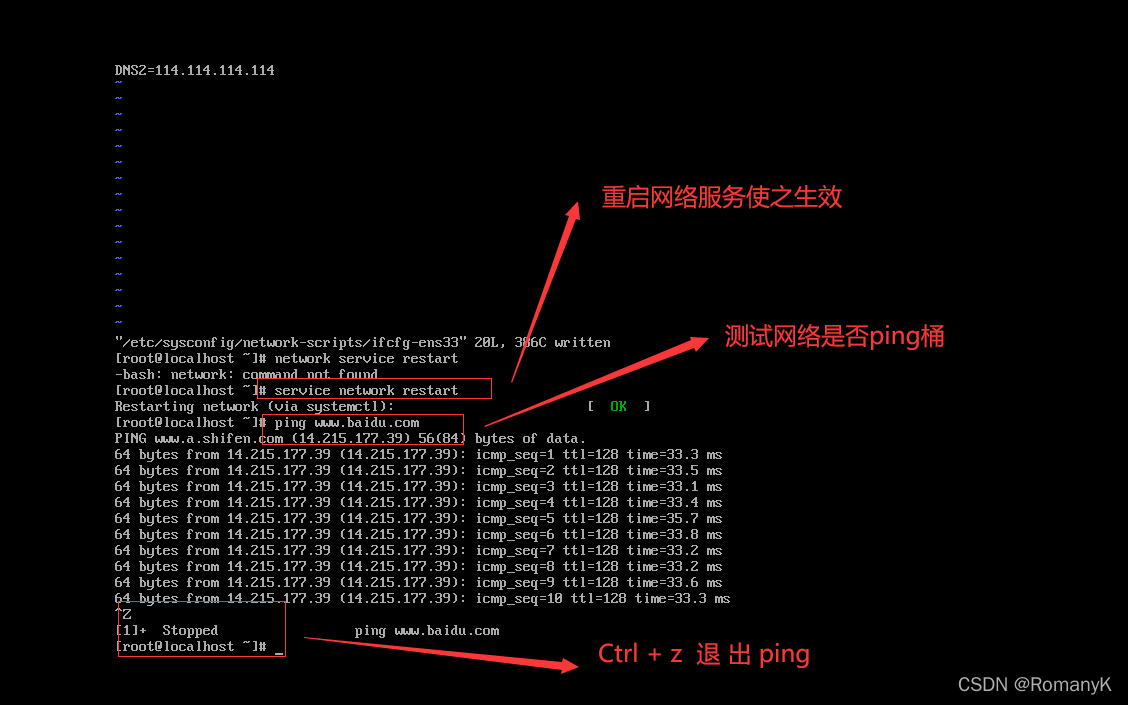
接下来配置另外两台的网卡,记住一定要关闭第一台的!!!,然后再开始相同步骤配置第二台的,然后关闭第二台后再继续配第三台!!!否则没配好静态IP之前会IP地址会变动
1.3.2第二台hadoop002 (192.168.20.112)
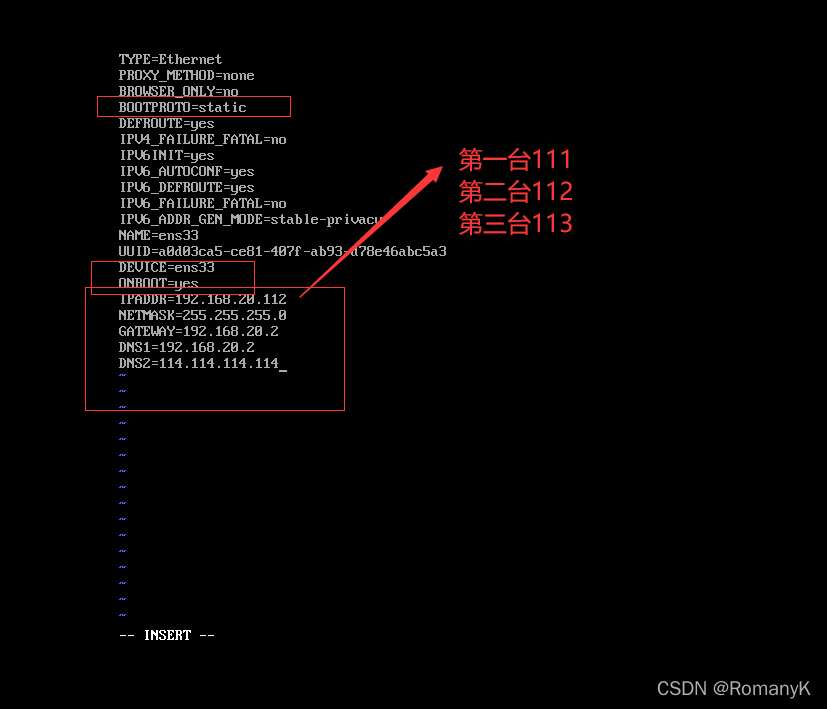
1.3.3第三台hadoop003(192.168.20.113)
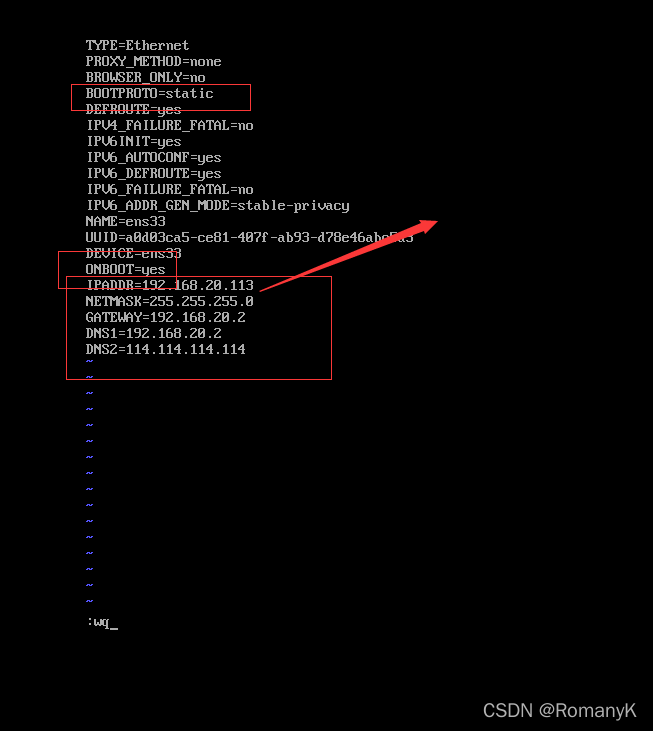
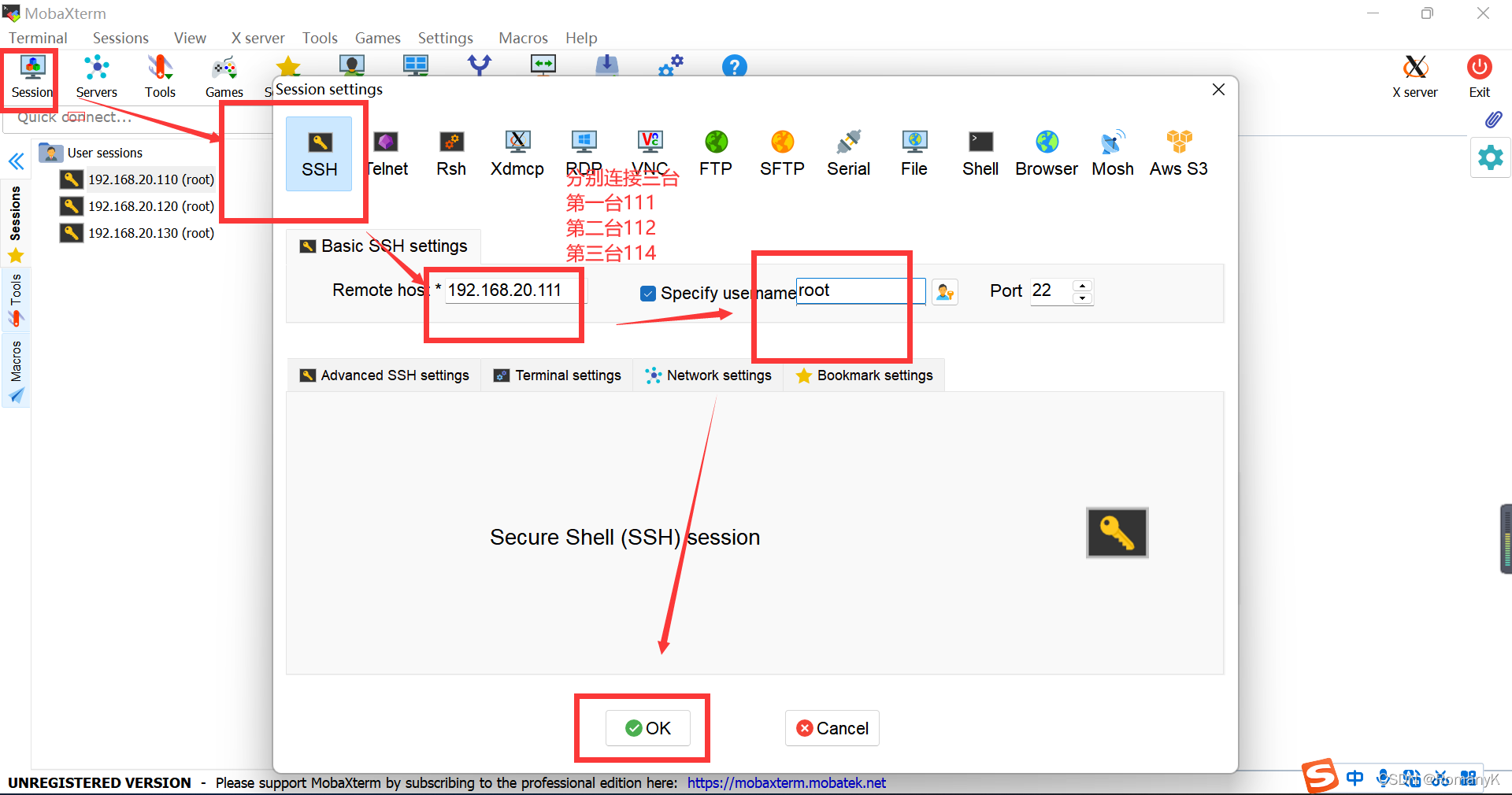
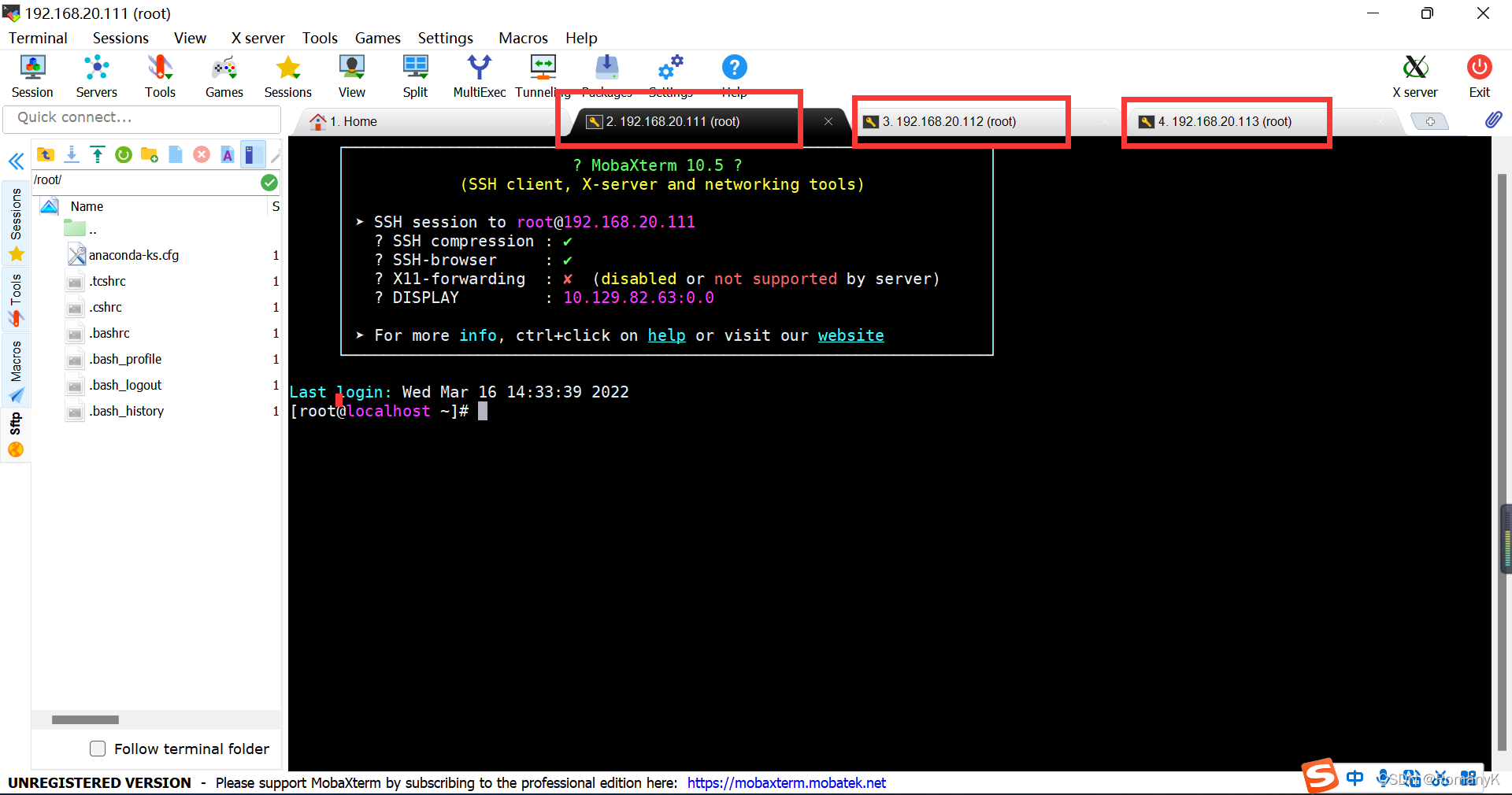
1.4将三台虚拟机连接到MobaXtem
1.4.1记住刚刚的三台虚拟机的网关(IP)
hadoop001 ------------192.168.20.111
hadoop002 ------------192.168.20.112
hadoop003 ------------192.168.20.113
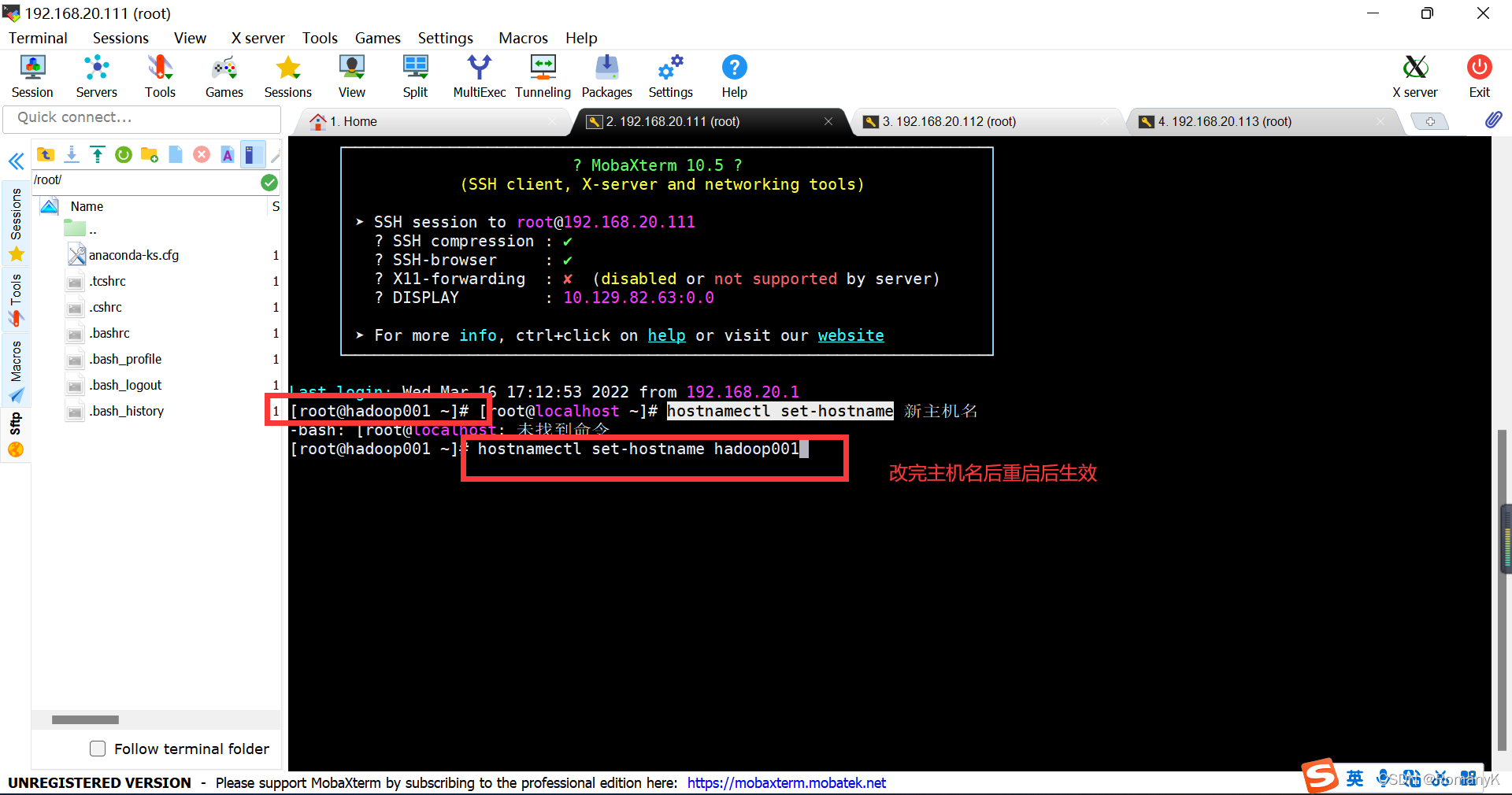
1.4.2接下来改主机名便于操作:
[root@localhost ~]# hostnamectl set-hostname 新主机名
第二台第三台同理
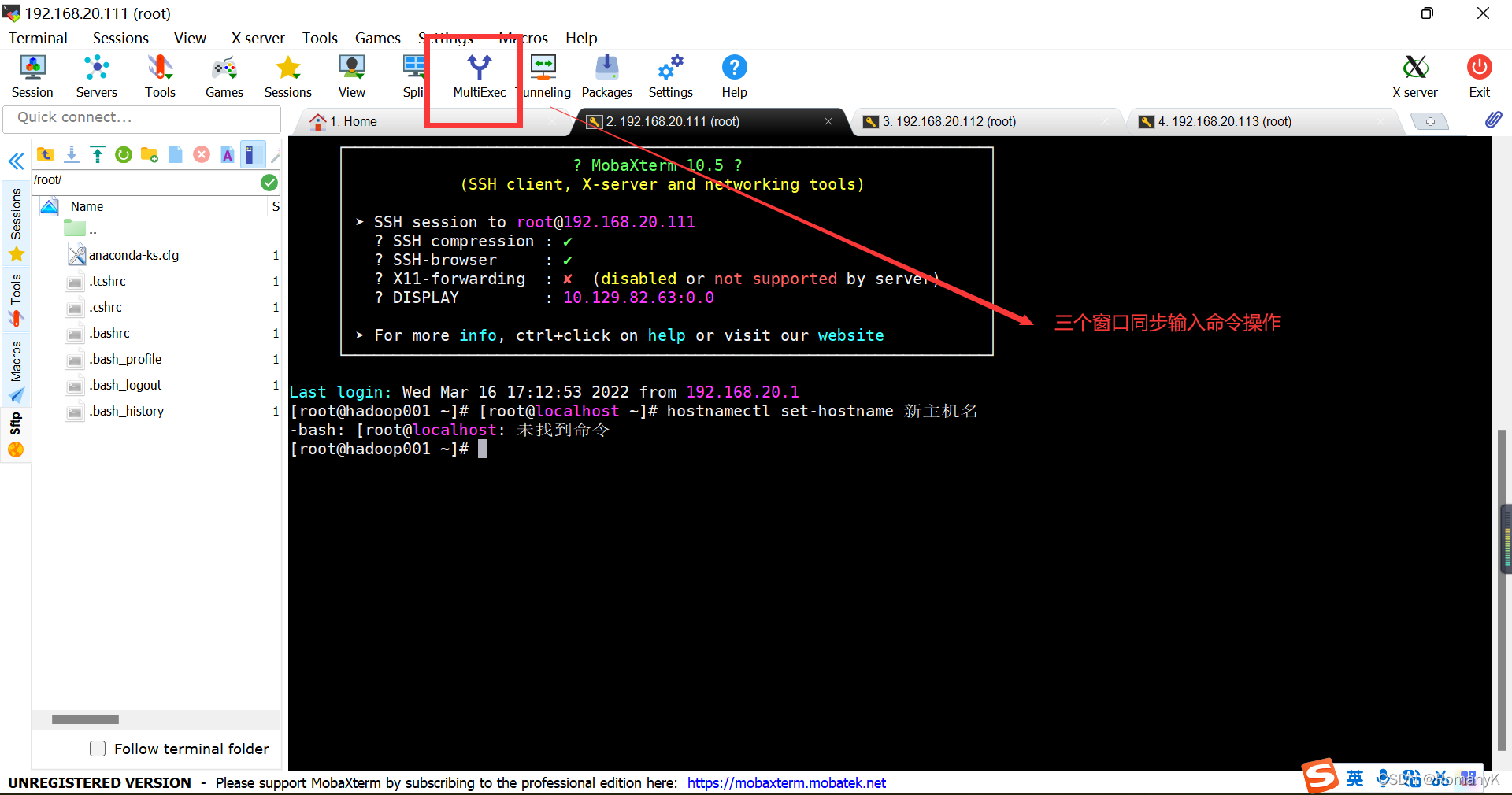
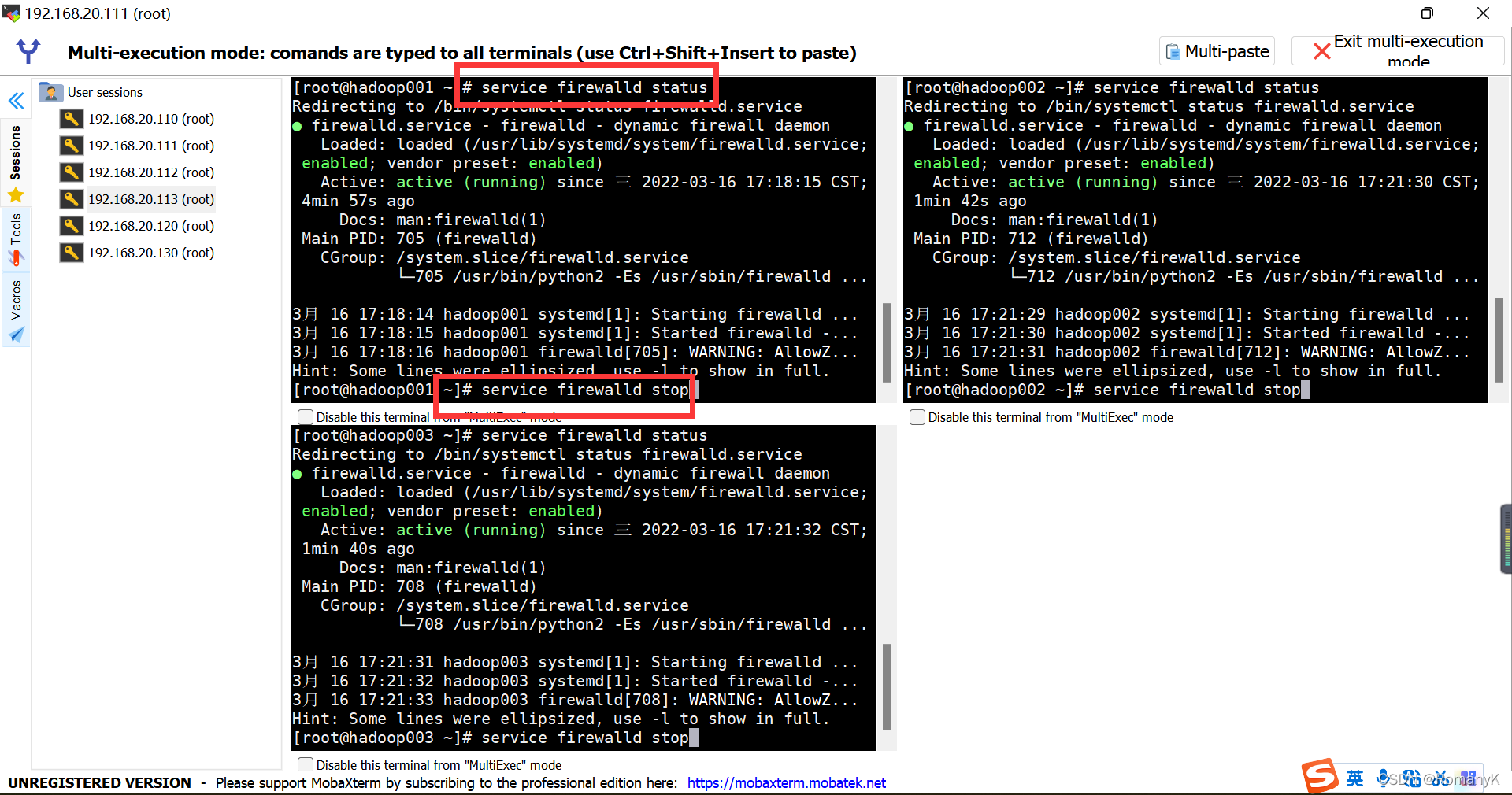
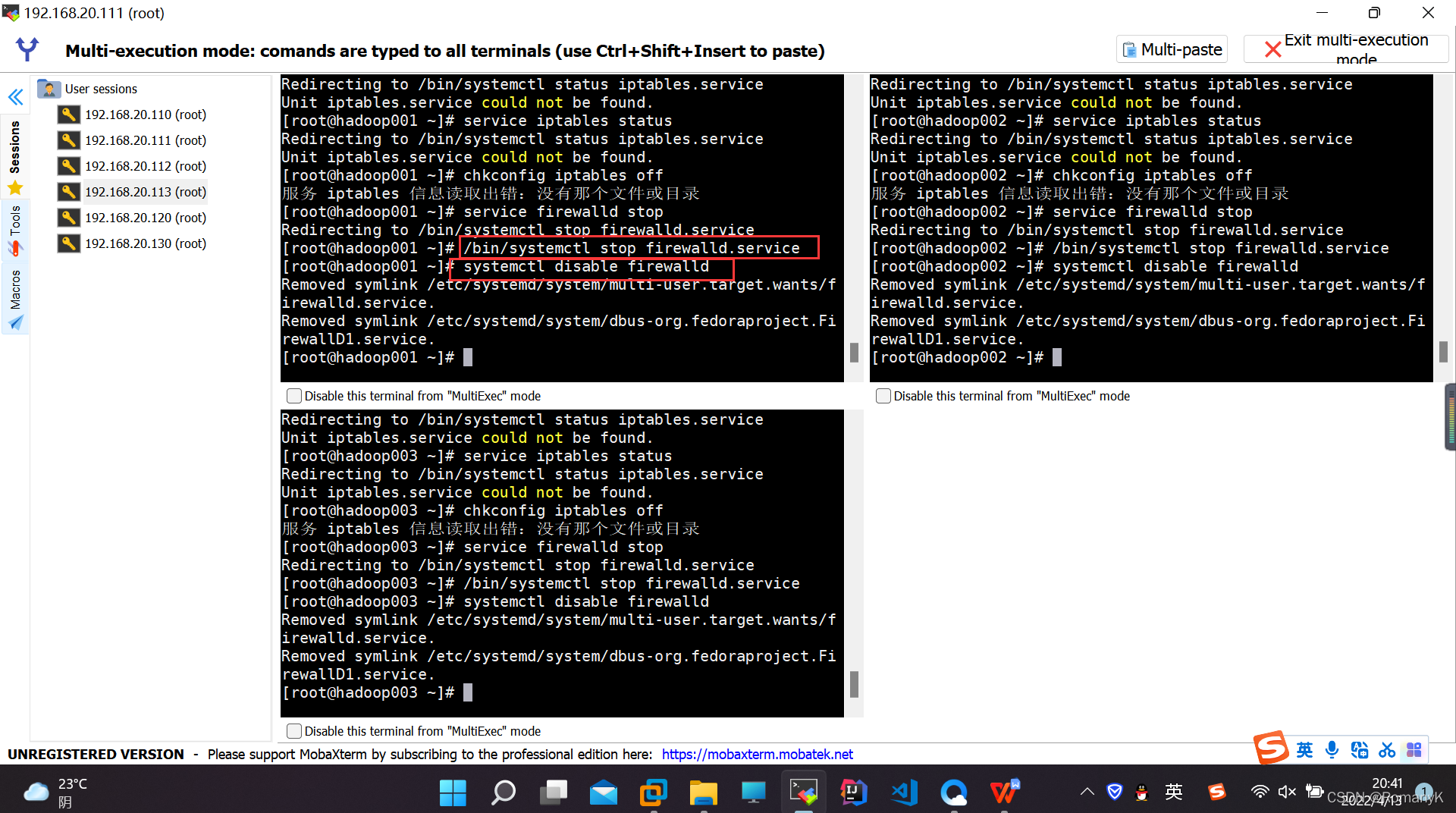
1.4.3关闭防火墙
1.5部署Hadoop
环境准备:
上传HADOOP安装包
规划安装目录 /usr/local/hadoop-2.7.3
解压安装包
修改配置文件 /usr/local/hadoop-2.7.3/etc/hadoop/
最简化配置如下:
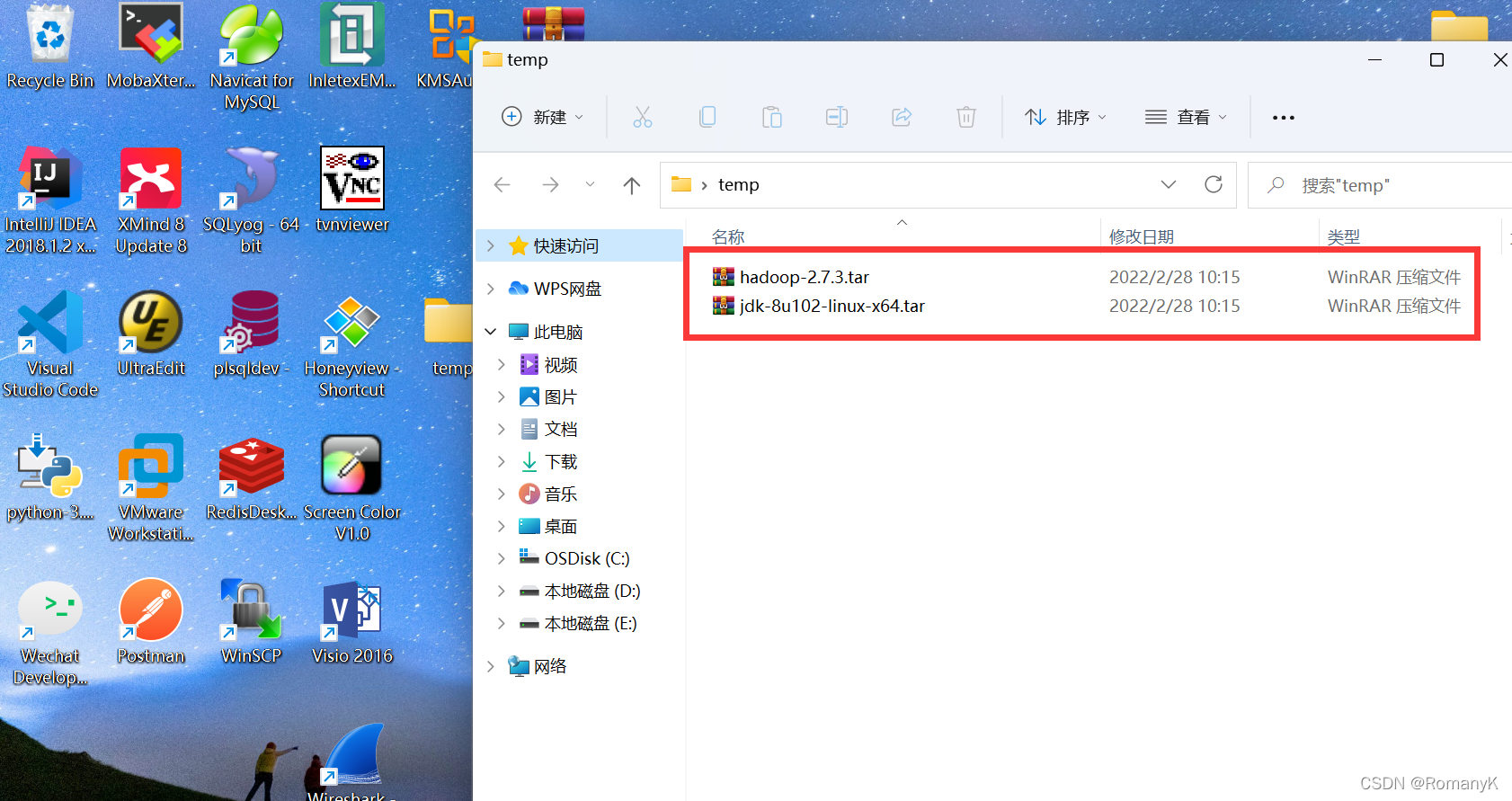
1.5.1上传HADOOP安装包
若需安装包可去我主页另一个破解软件专栏里有白嫖资源
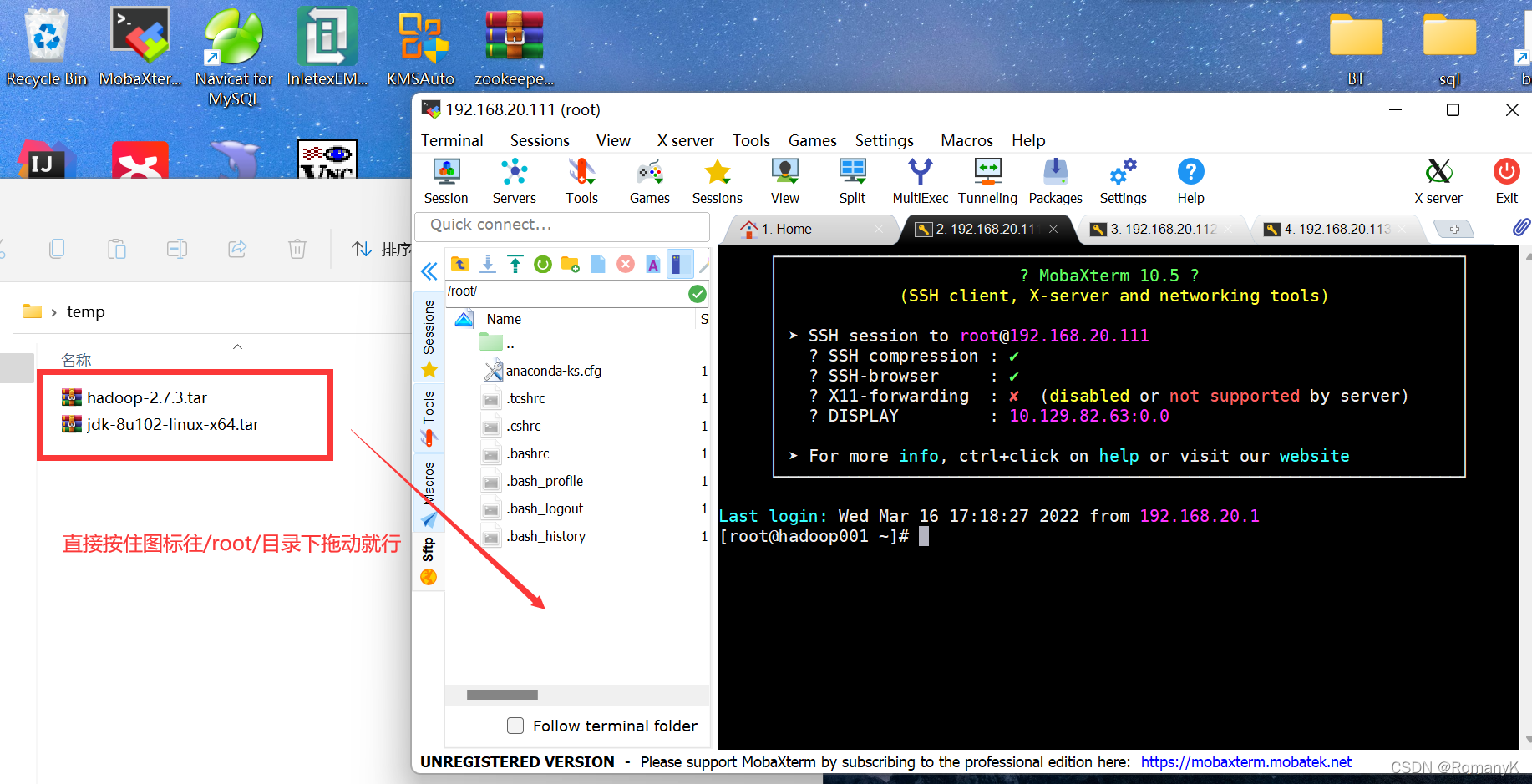
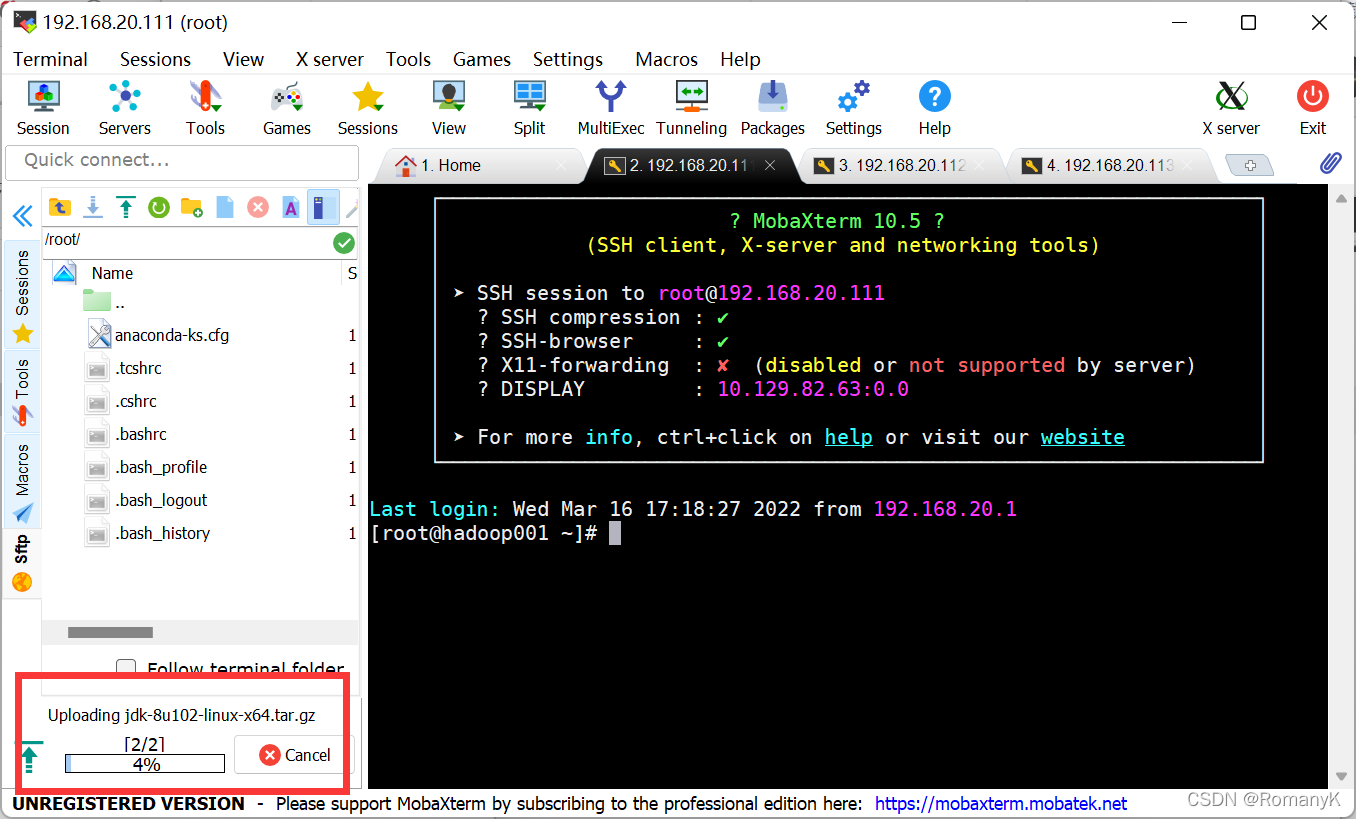
1.5.2安装JDK
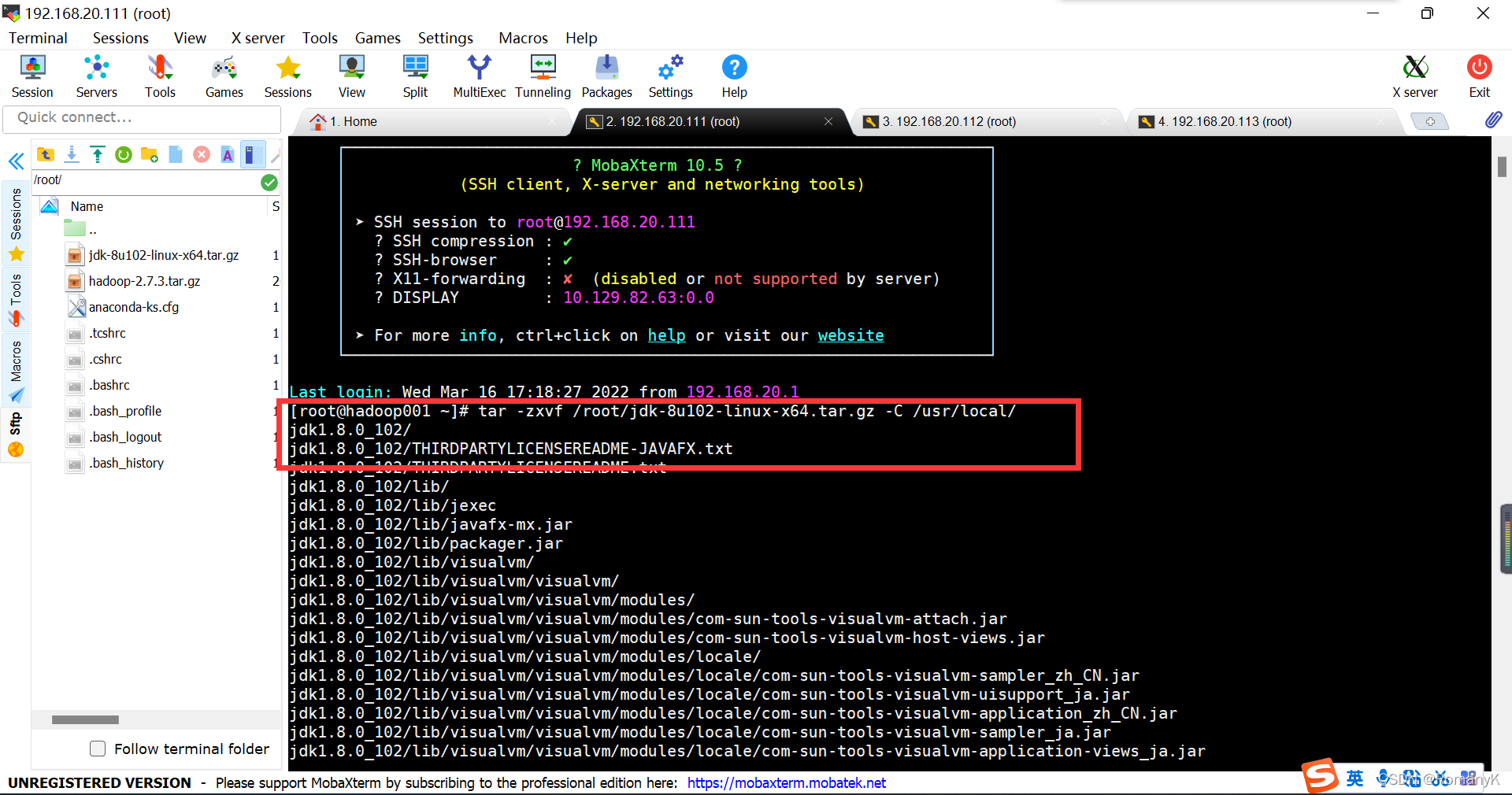
tar -zxvf /root/jdk-8u102-linux-x64.tar.gz -C /usr/local/
注意这里的“-C”C是大写的
1.5.3配置JDK环境变量
vi /etc/profile
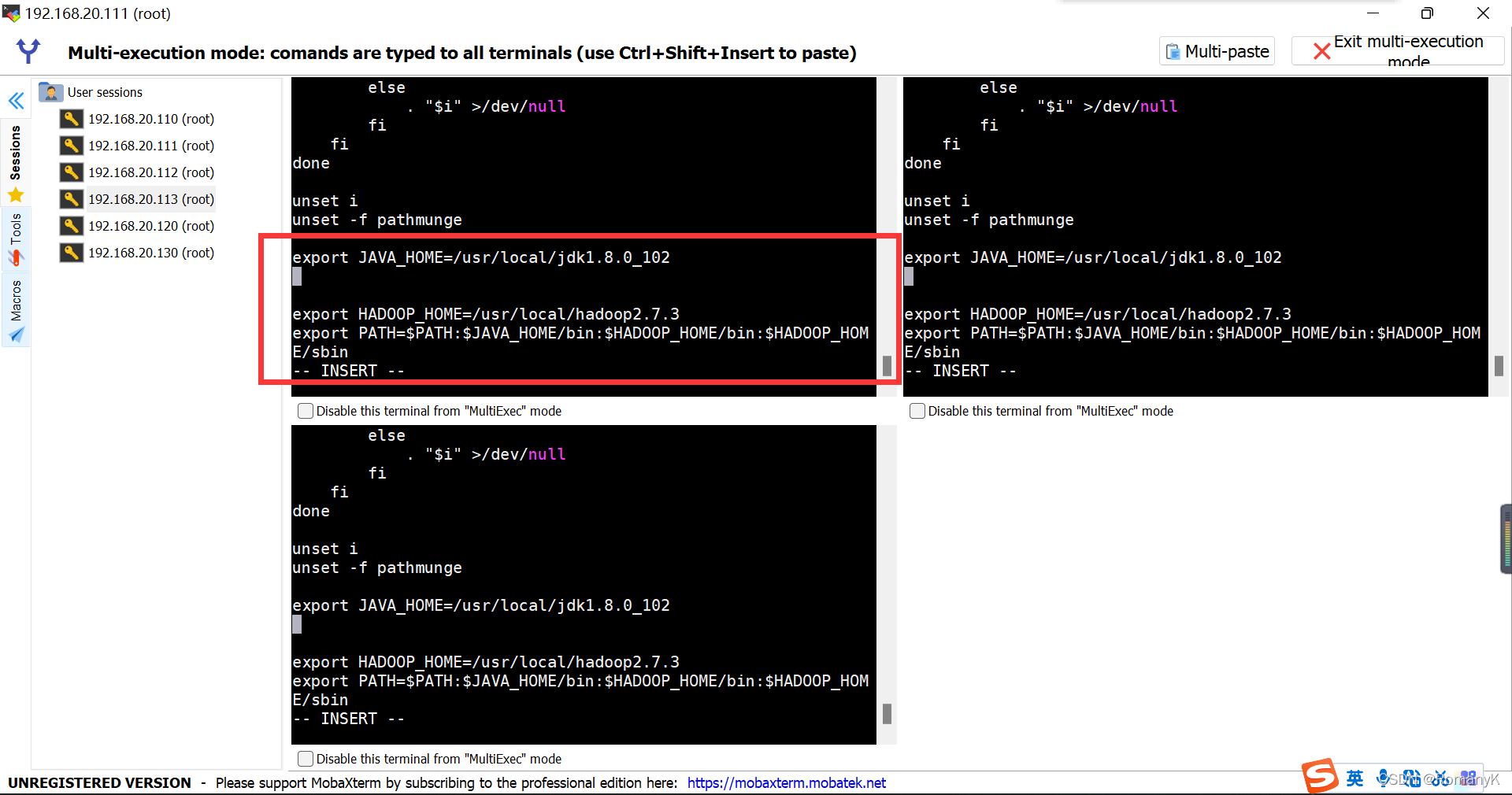
source /etc/profile
1.5.4配置Hadoop环境变量
vi /etc/profile
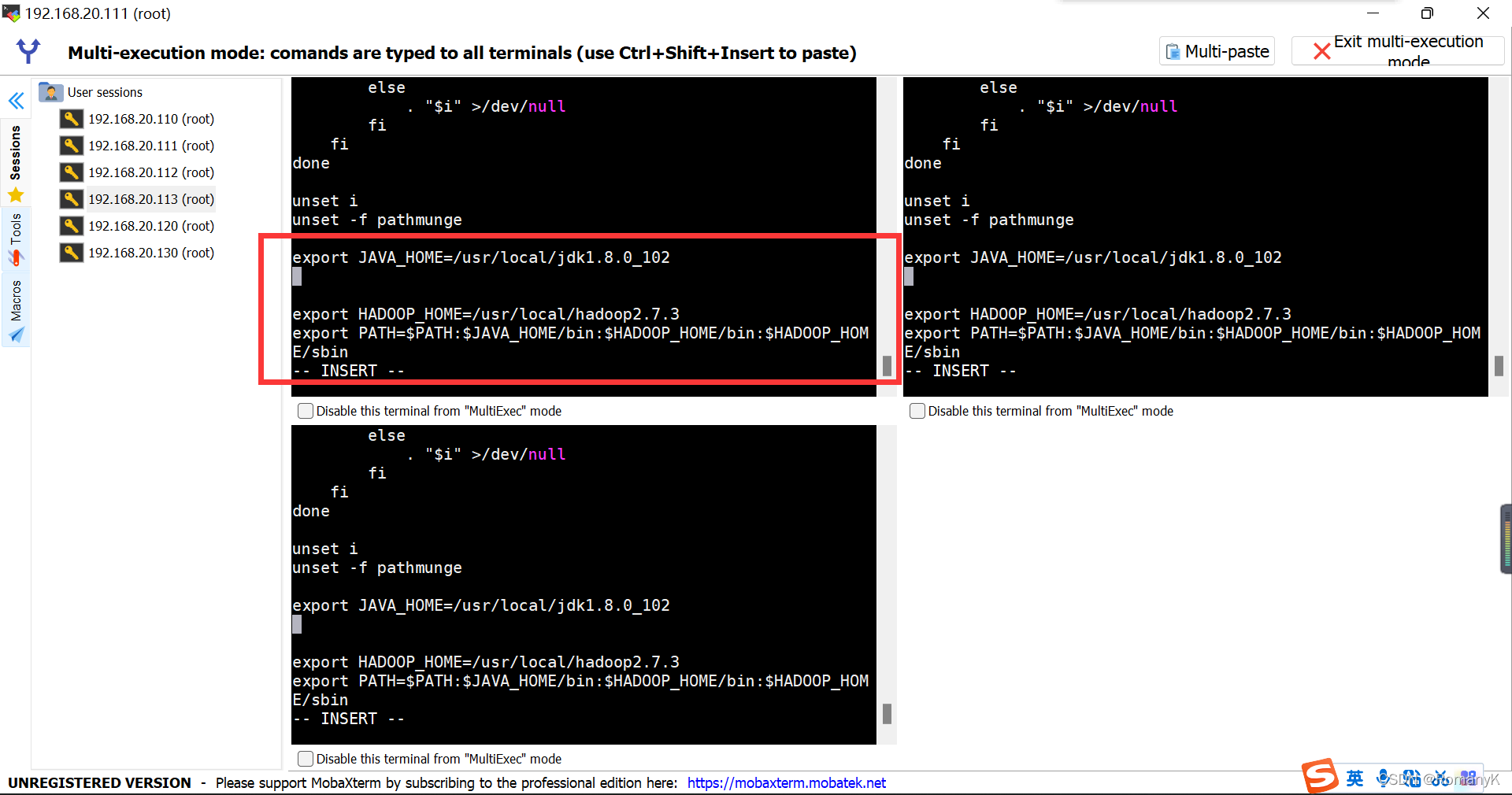
source /etc/profile
1.5.5安装Hadoop
tar -zxvf /root/hadoop-2.7.3.tar.gz -C /usr/local/
修改配置文件(进入Hadoop的目录)
cd /usr/local/hadoop-2.7.3/etc/hadoop/
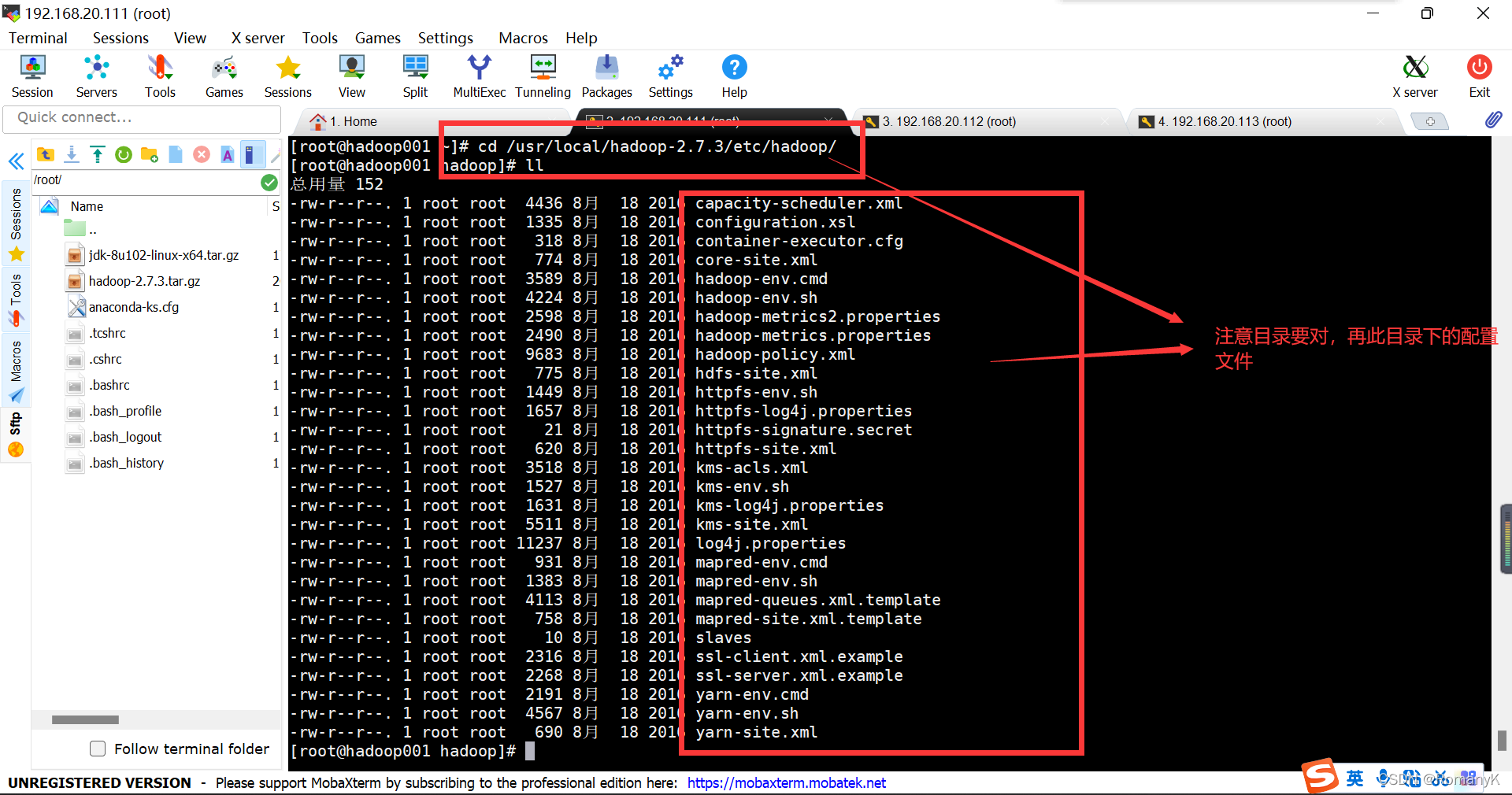
1.5.6修改配置文件 /usr/local/hadoop-2.7.3/etc/hadoop/
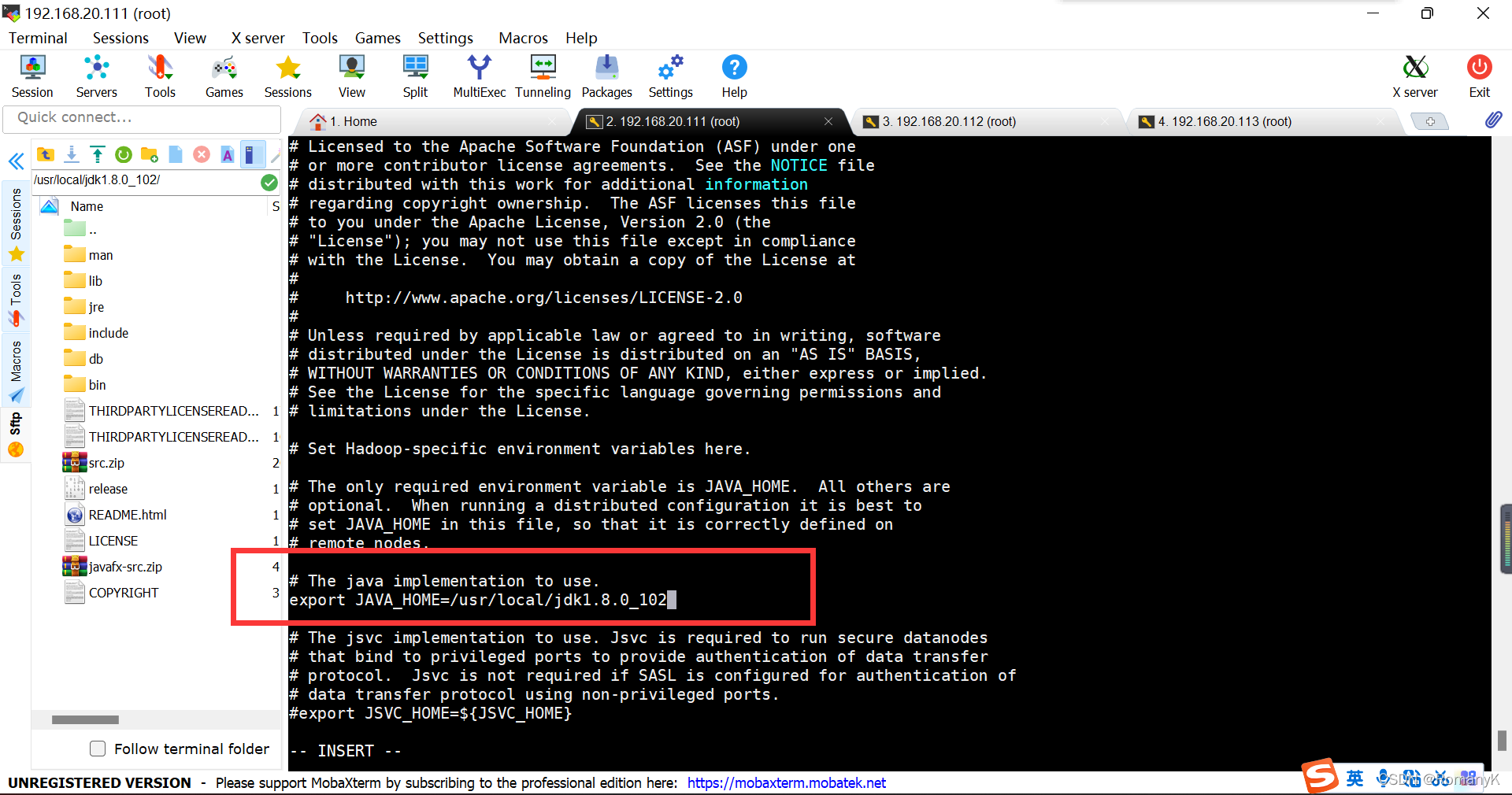
1.5.6.1==vi hadoop-env.sh
vi hadoop-env.sh
The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8.0_102
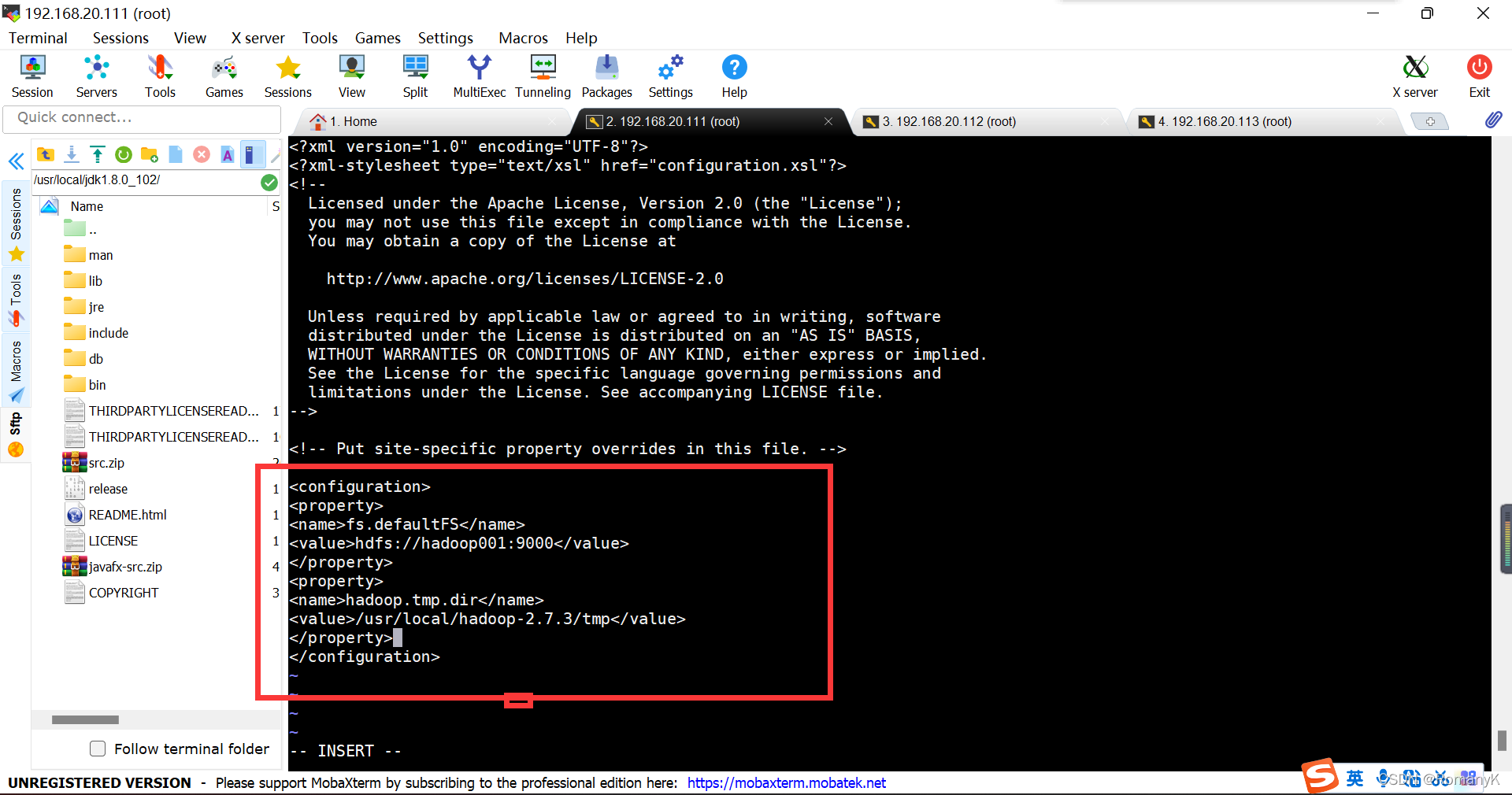
1.5.6.2==vi core-site.xml
//##Namenode在哪里 ,临时文件存储在哪里
fs.defaultFS
hdfs://hadoop001:9000
hadoop.tmp.dir
/usr/local/hadoop-2.7.3/tmp
1.5.6.3==vi hdfs-site.xml
dfs.secondary.http.address dfs.namenode.name.dir /usr/local/hadoop-2.7.3/data/name dfs.datanode.data.dir /usr/local/hadoop-2.7.3/data/data dfs.replication 3 hadoop001:50090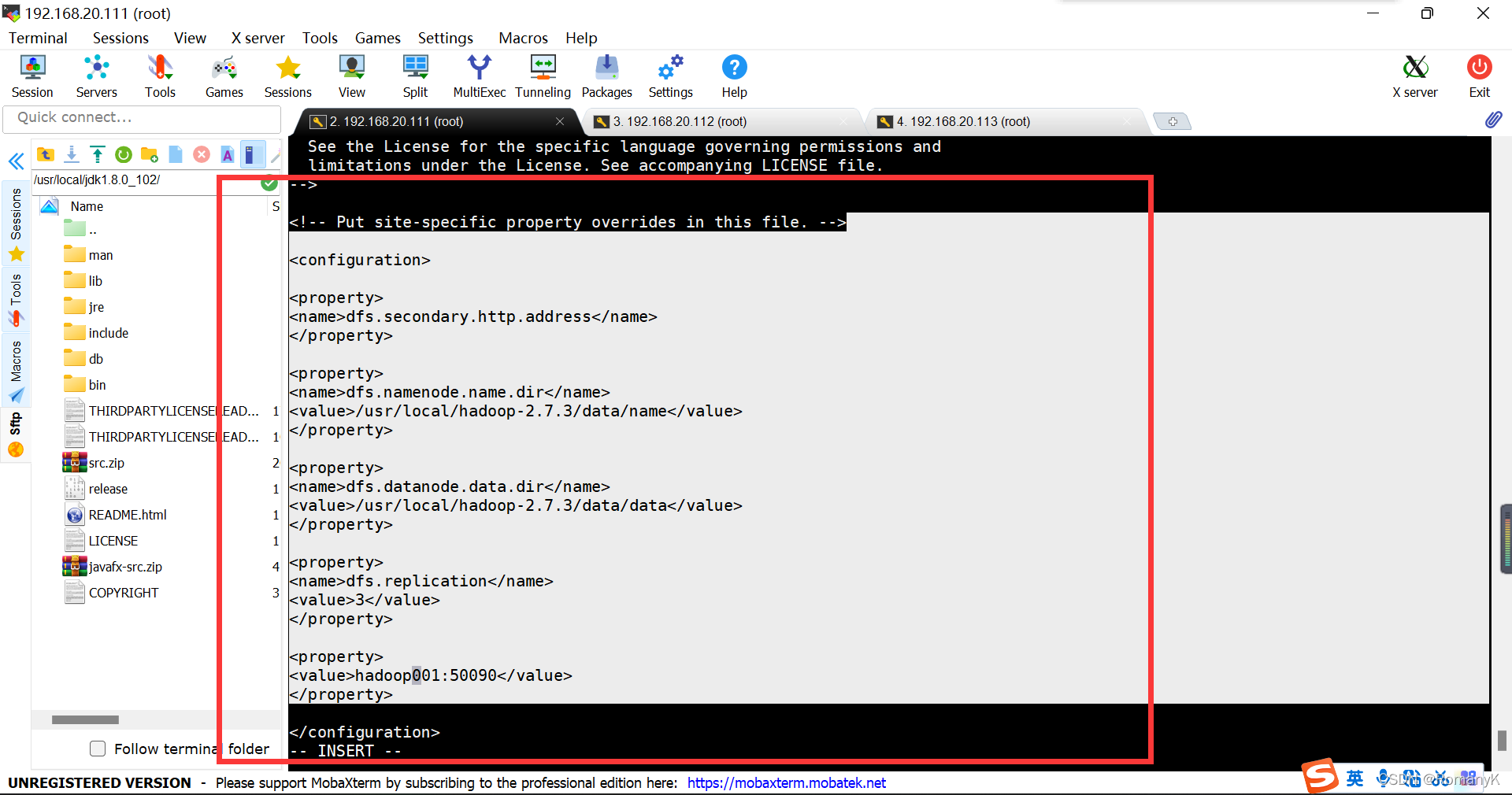
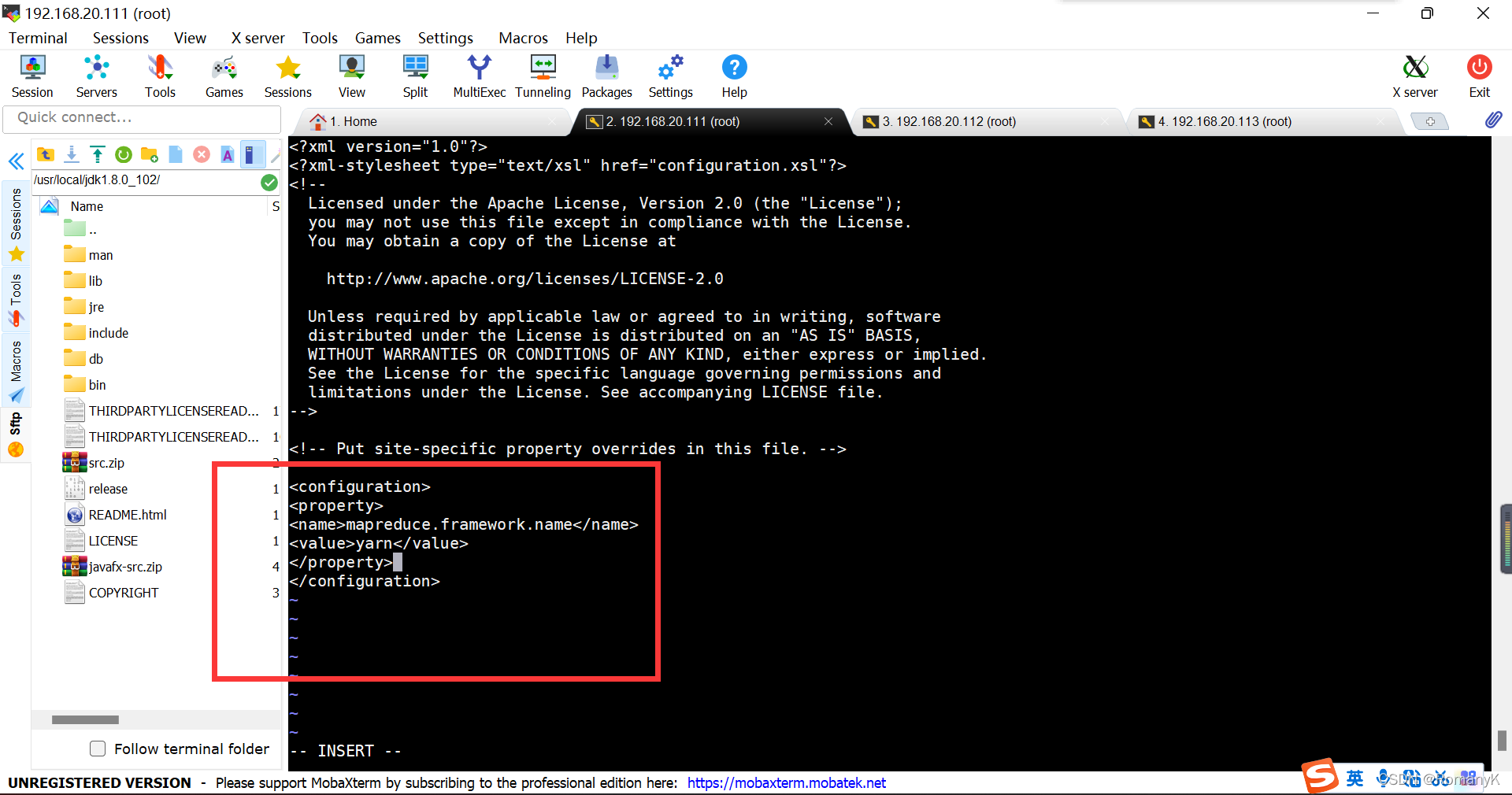
1.5.6.4==Mv mapred-site.xml.tmp* mapred-site.xml vi mapred-site.xml
mapreduce.framework.name yarn
1.5.6.5==vi yarn-site.xml
yarn.resourcemanager.hostname hadoop001 yarn.nodemanager.aux-services mapreduce_shuffle
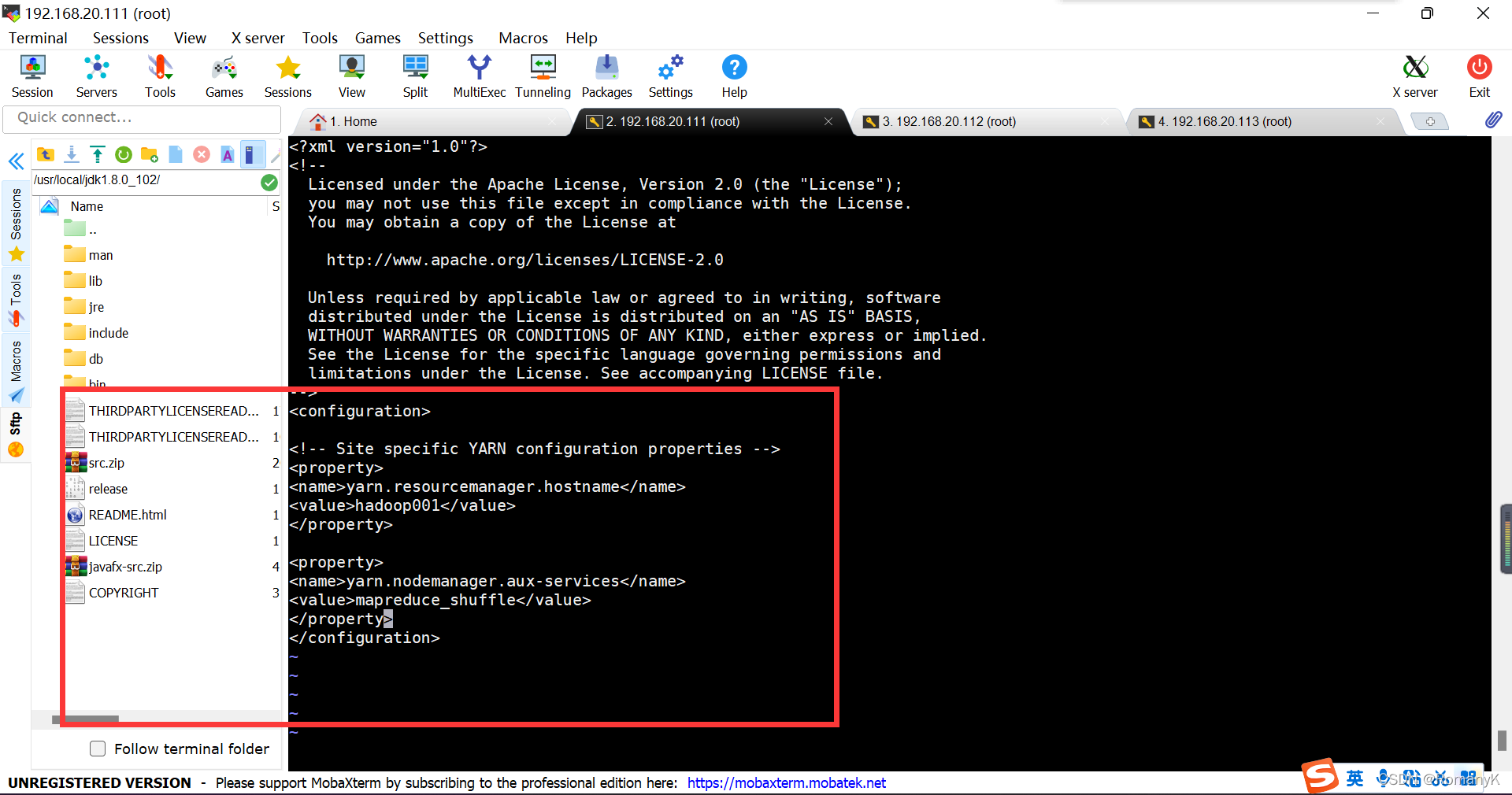
1.5.6.6==vi slaves
hadoop002
hadoop003
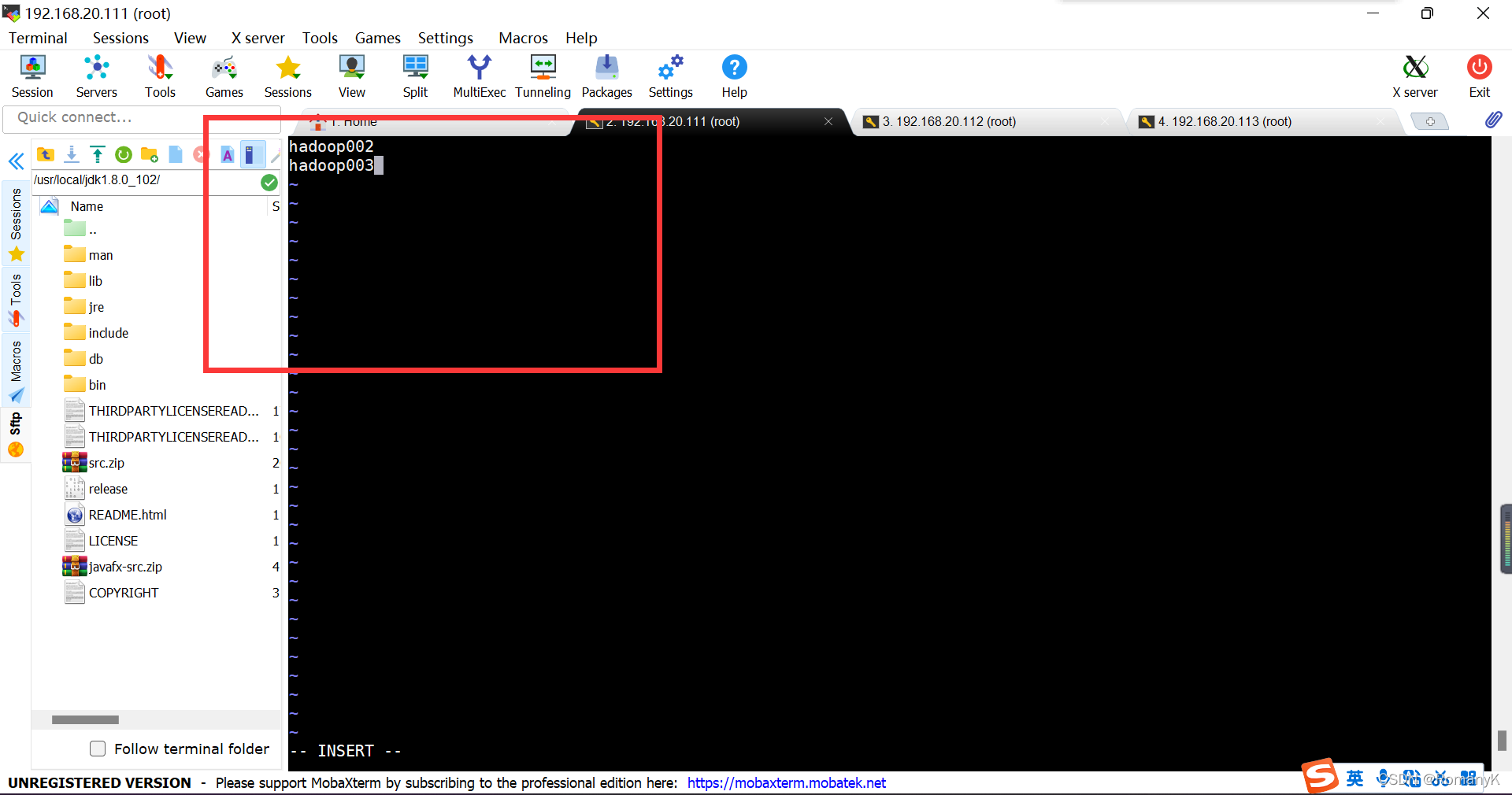
1.5.6.7总结
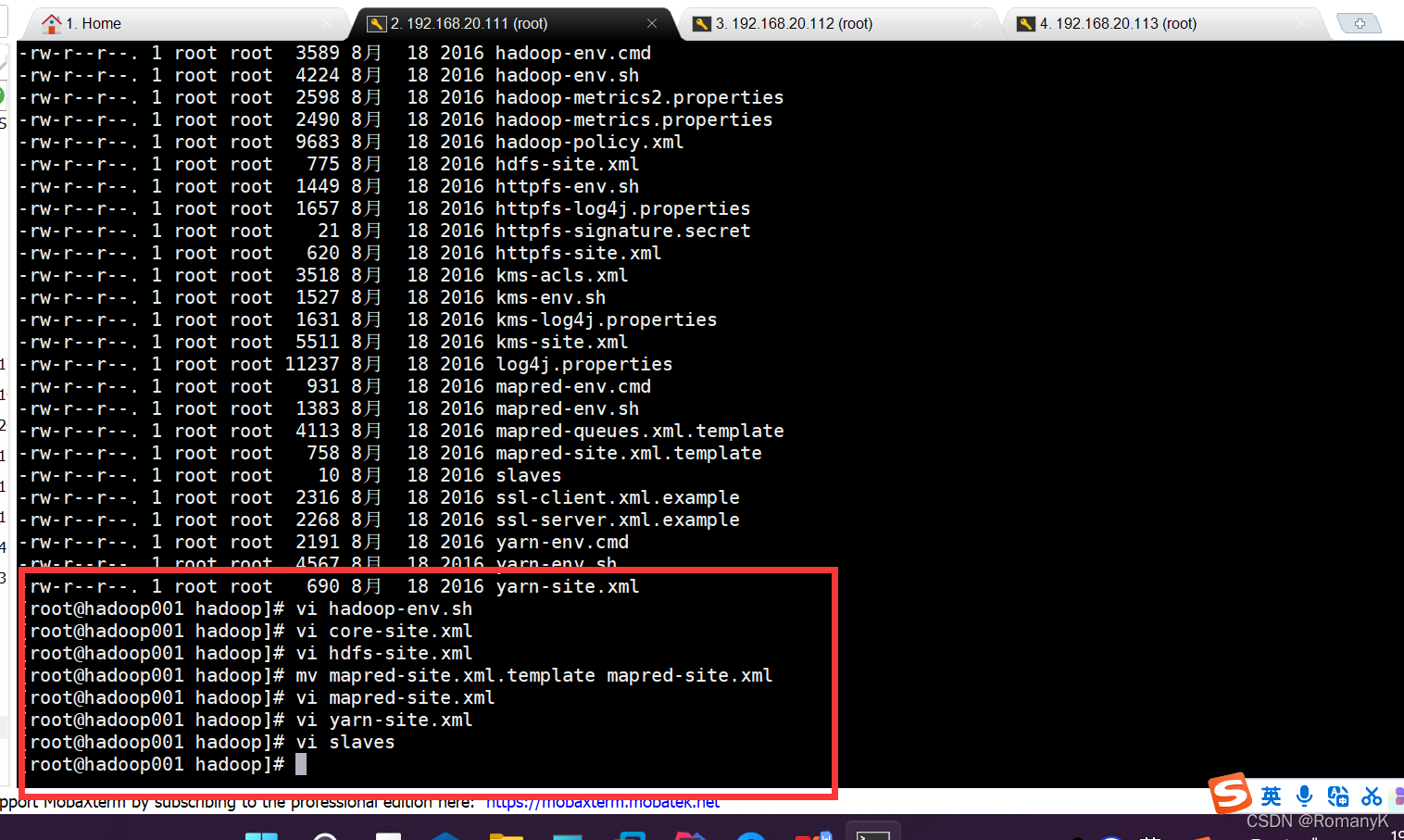
输入时注意别把也输入错误,注意格式
1.5.7修改host映射
需要使用主机名传递,需要修改host映射
vi /etc/hosts
192.168.20.111 hadoop001
192.168.20.112 hadoop002
192.168.20.113 hadoop003
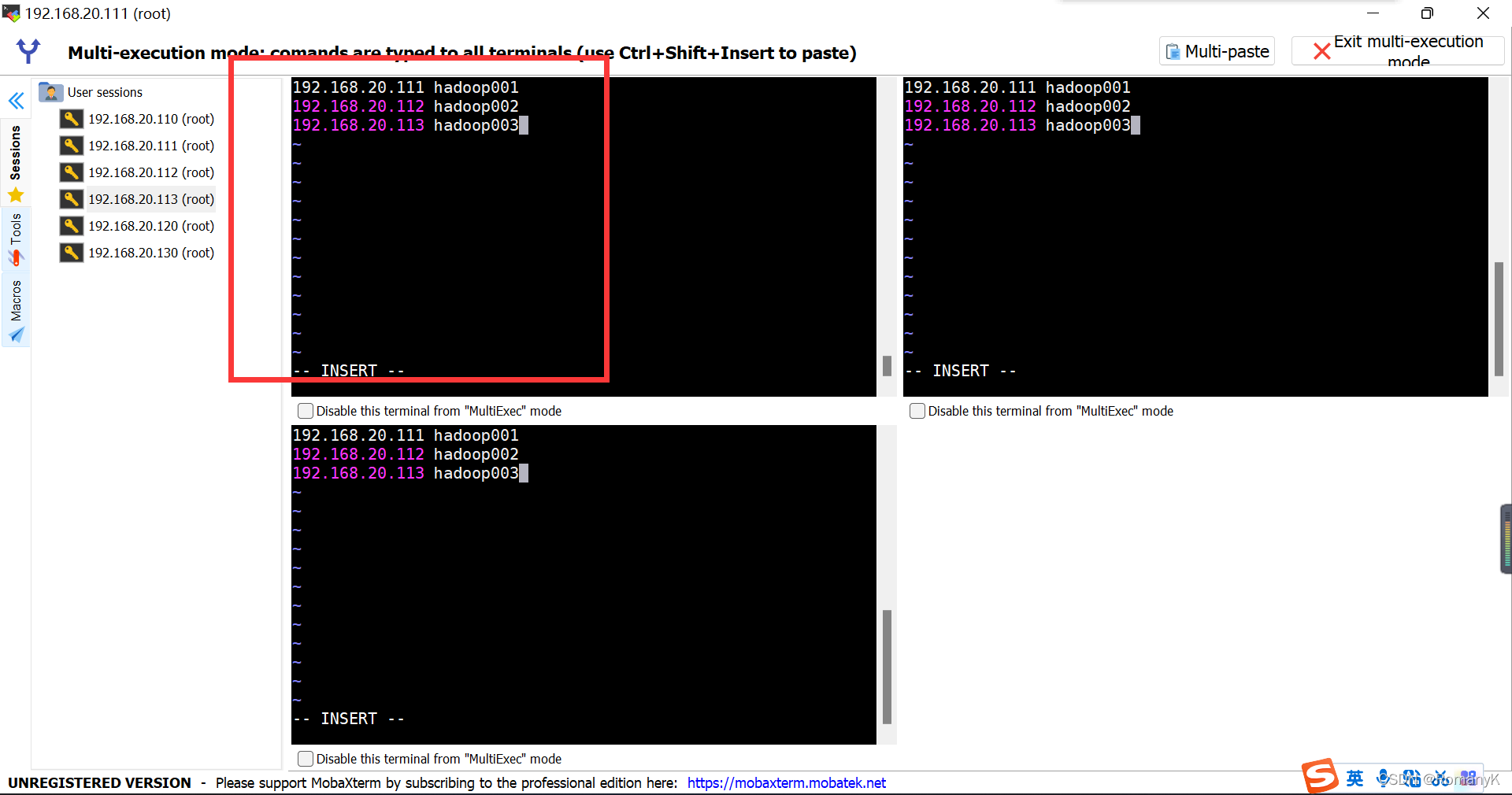
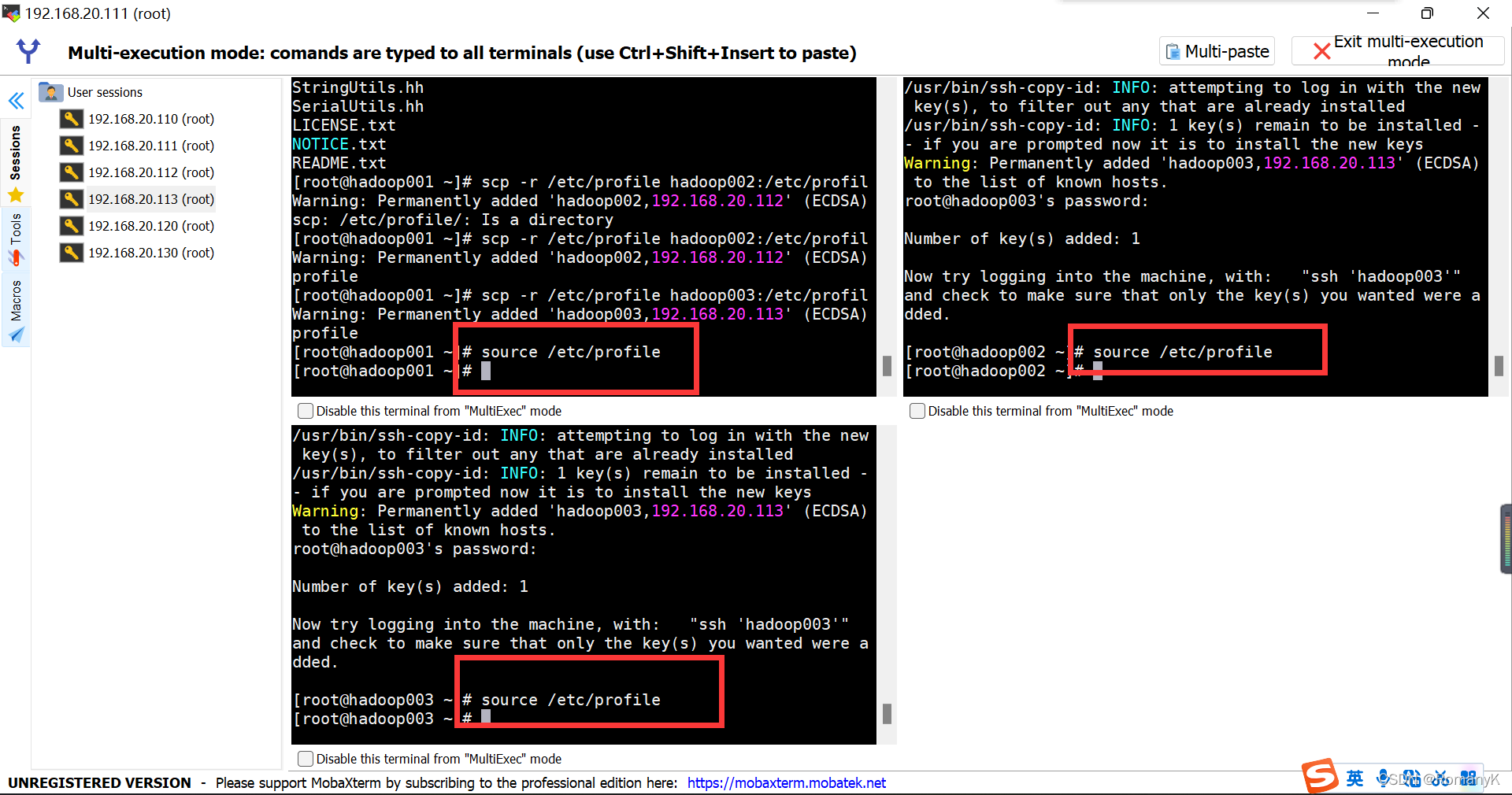
1.5.8 设置免密登录SSH
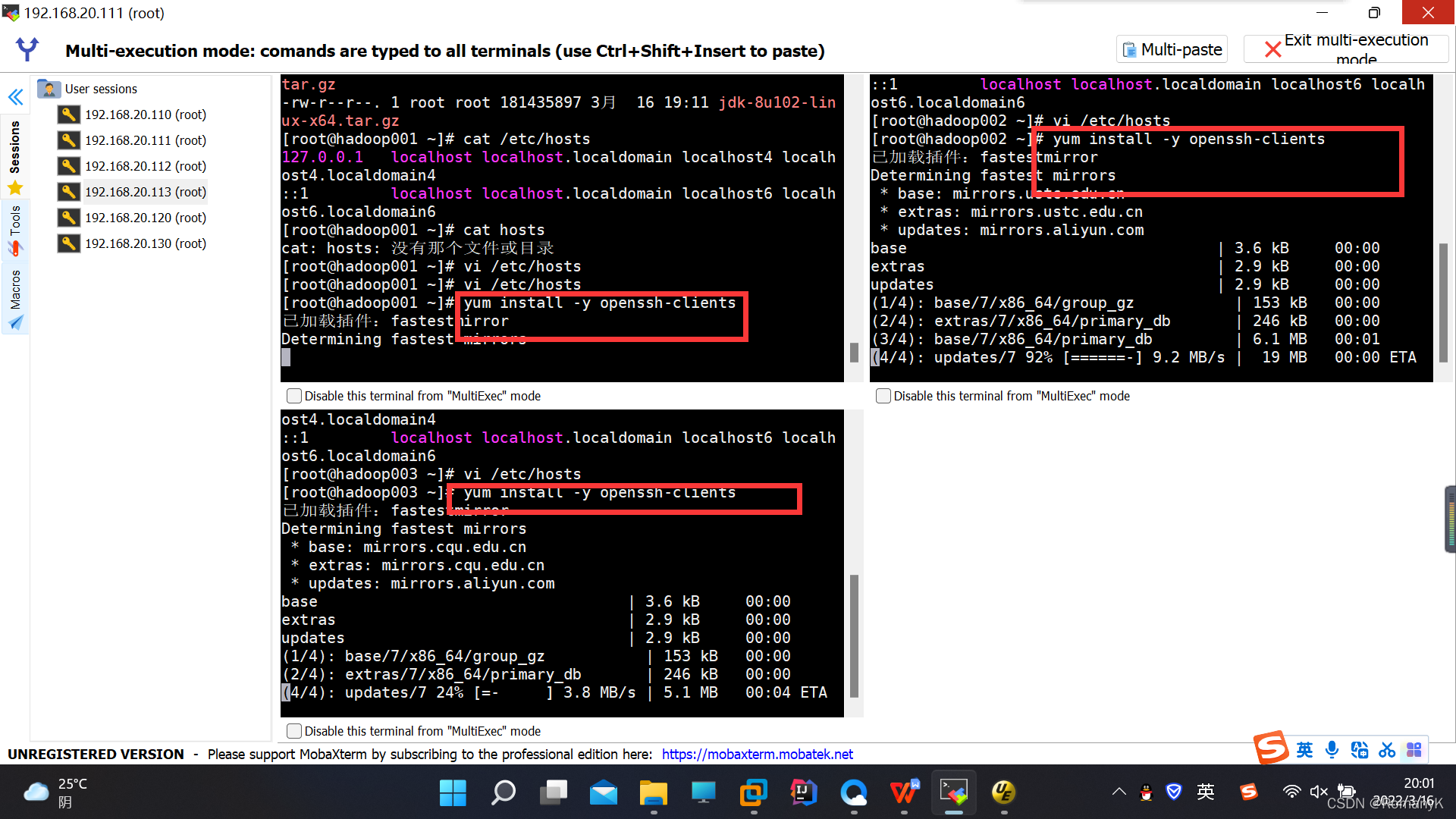
安装免密登录客户端:yum install -y openssh-clients
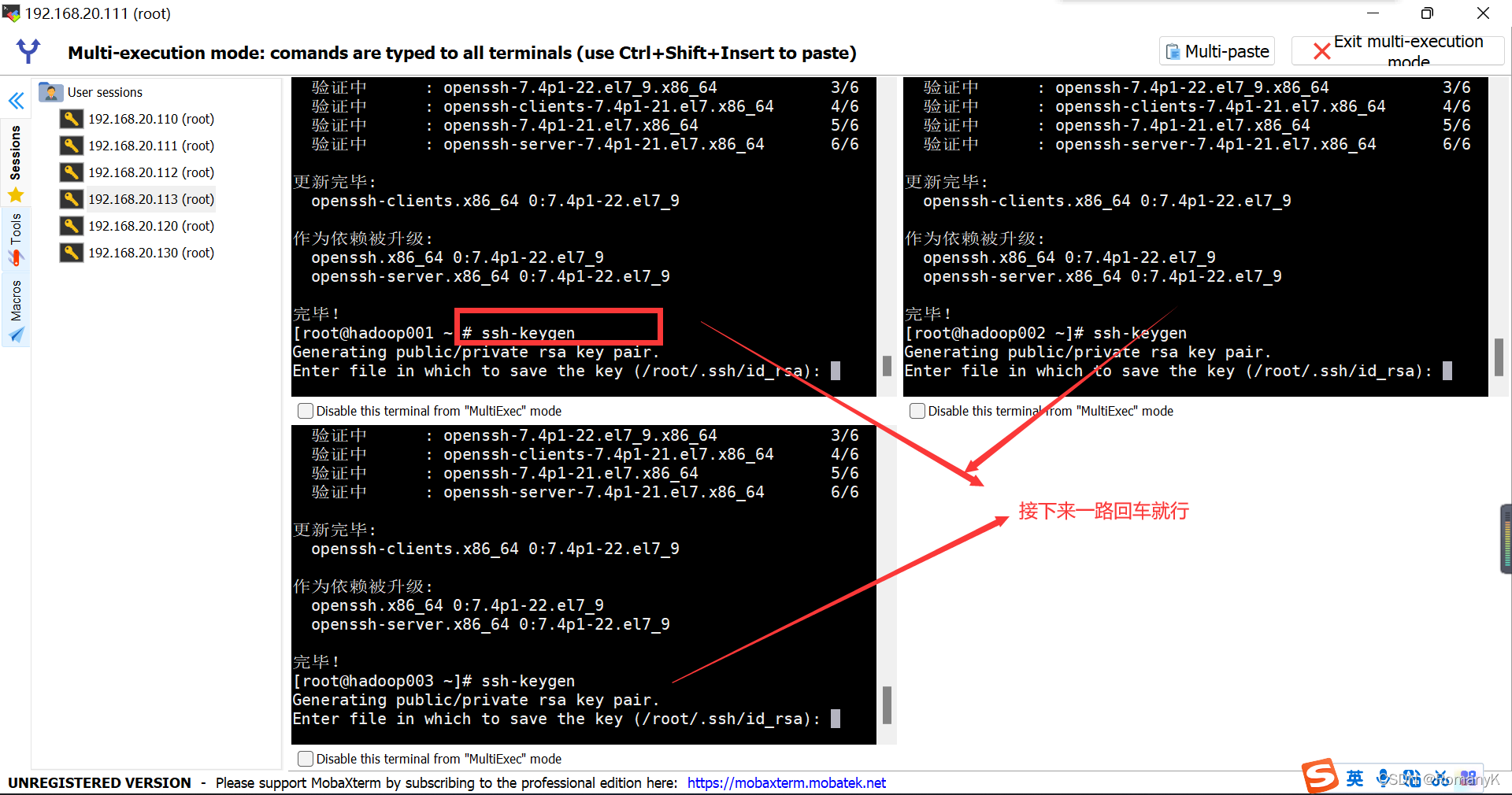
生成公钥跟私钥:ssh-keygen
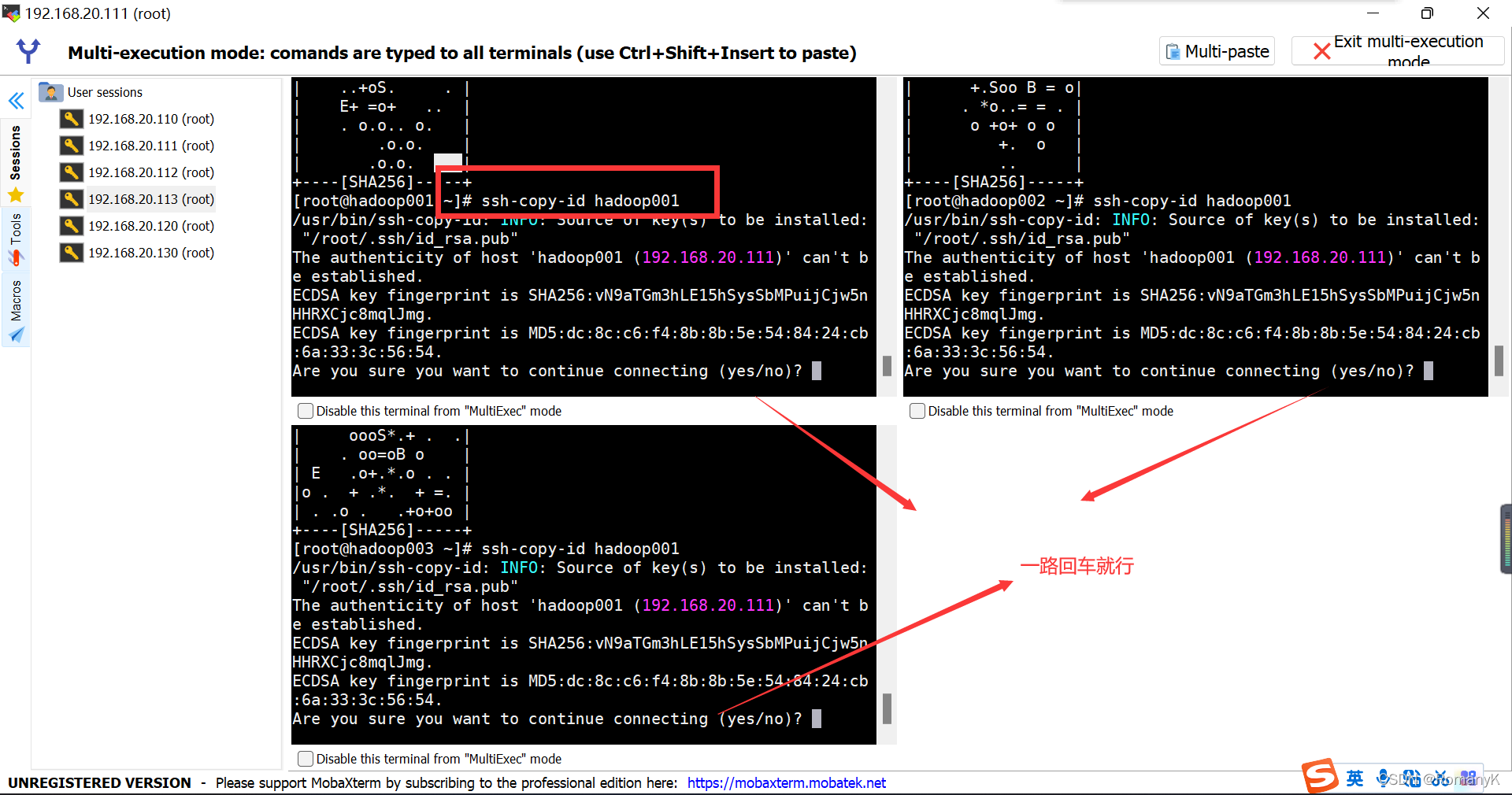
发送公钥跟私钥:ssh-copy-id spark01
注意:不紧要给别人发,也给自己发一份
如果配置免密时遇到问题可参考这篇文章:
https://blog.csdn.net/oba_gaga/article/details/80684059?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_paycolumn_v3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_paycolumn_v3&utm_relevant_index=2
1.5.9 分发
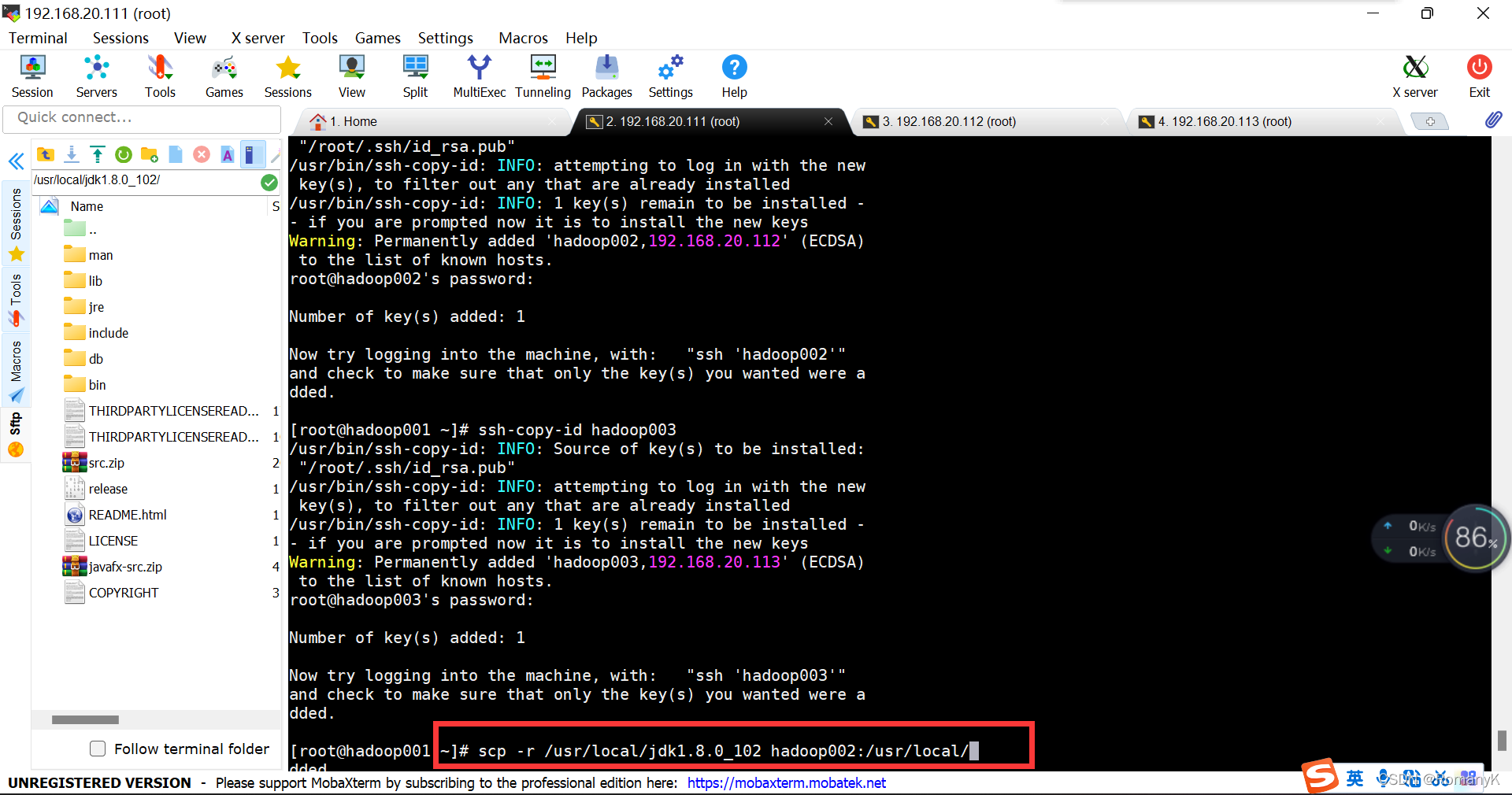
把第一台安装好的jdk和hadoop以及配置文件发送给另外两台==hosts文件、jdk安装后的文件夹、Hadoop安装后的文件夹、/etc/profile 文件
eg:scp -r /usr/local/jdk1.8.0_102 hadoop02:/usr/local/
scp -r /usr/local/jdk1.8.0_102 hadoop002:/usr/local/
scp -r /usr/local/jdk1.8.0_102 hadoop003:/usr/local/
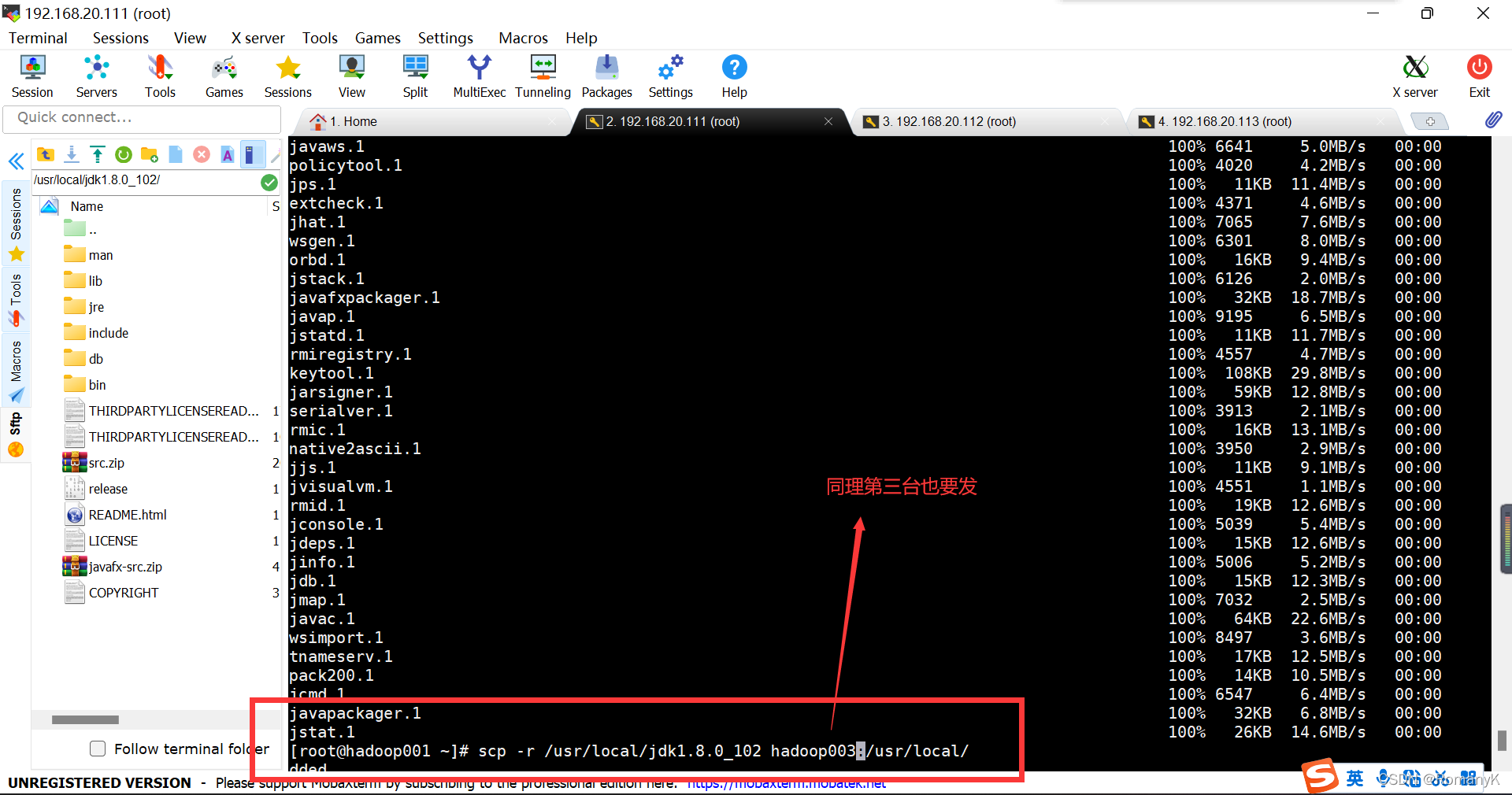
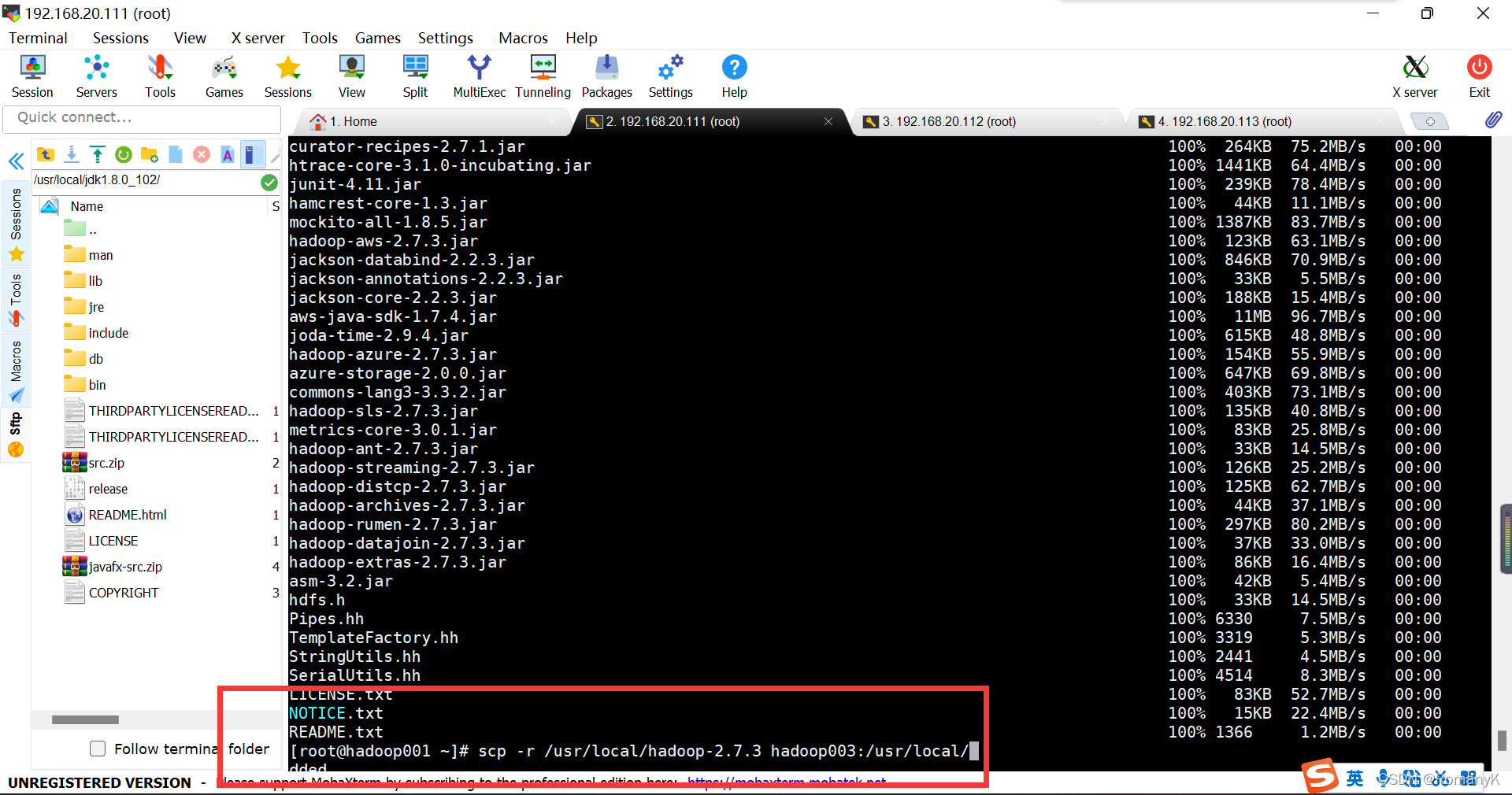
scp -r /usr/local/hadoop-2.7.3 hadoop002:/usr/local/
scp -r /usr/local/hadoop-2.7.3 hadoop003:/usr/local/
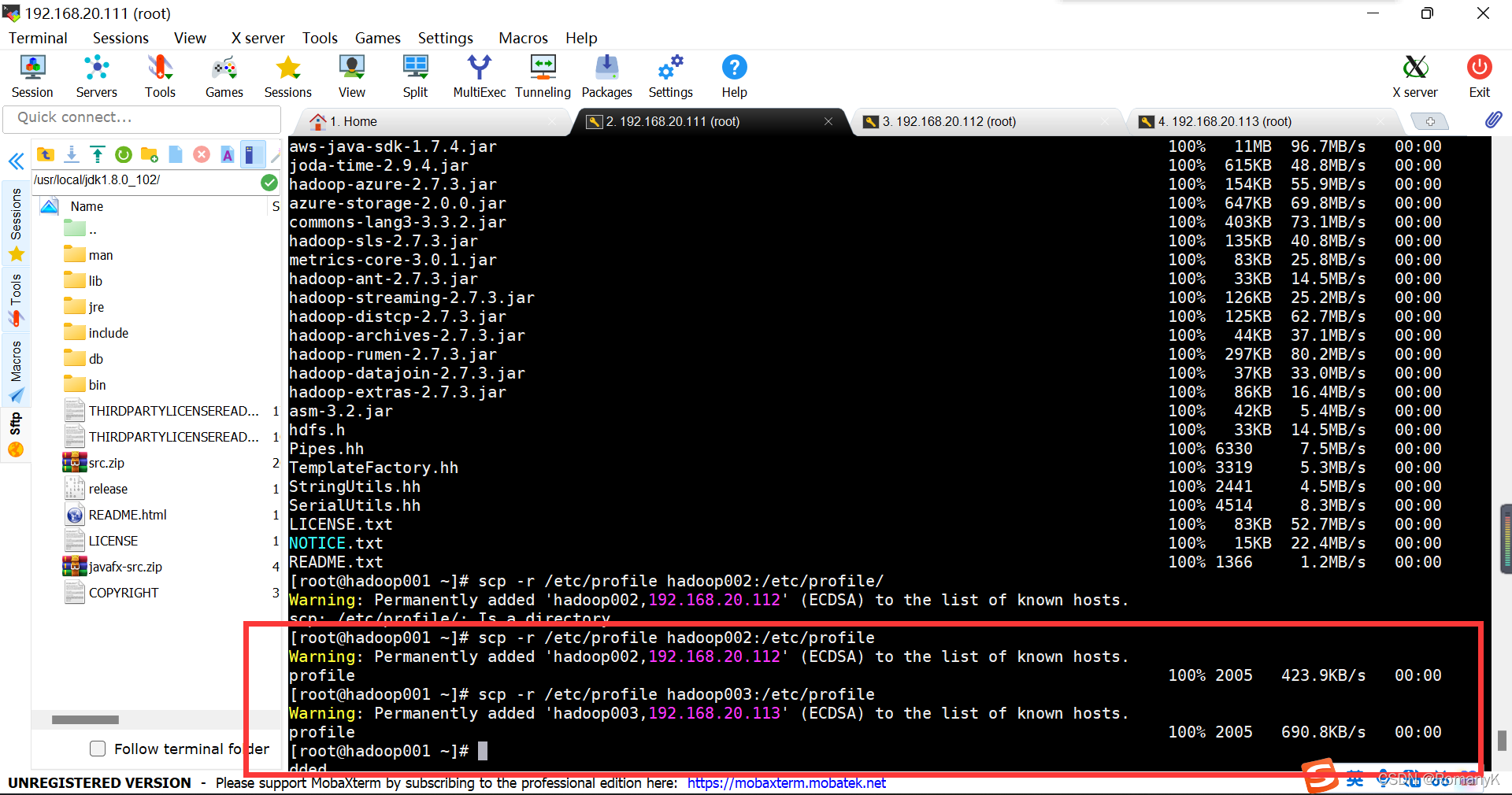
scp -r /etc/profile hadoop002:/etc/profile
scp -r /etc/profile hadoop003:/etc/profile
2.启动集群
初始化HDFS(在hadoop001进行操作)(操作一次就ok)
在hadoop001号机子上执行
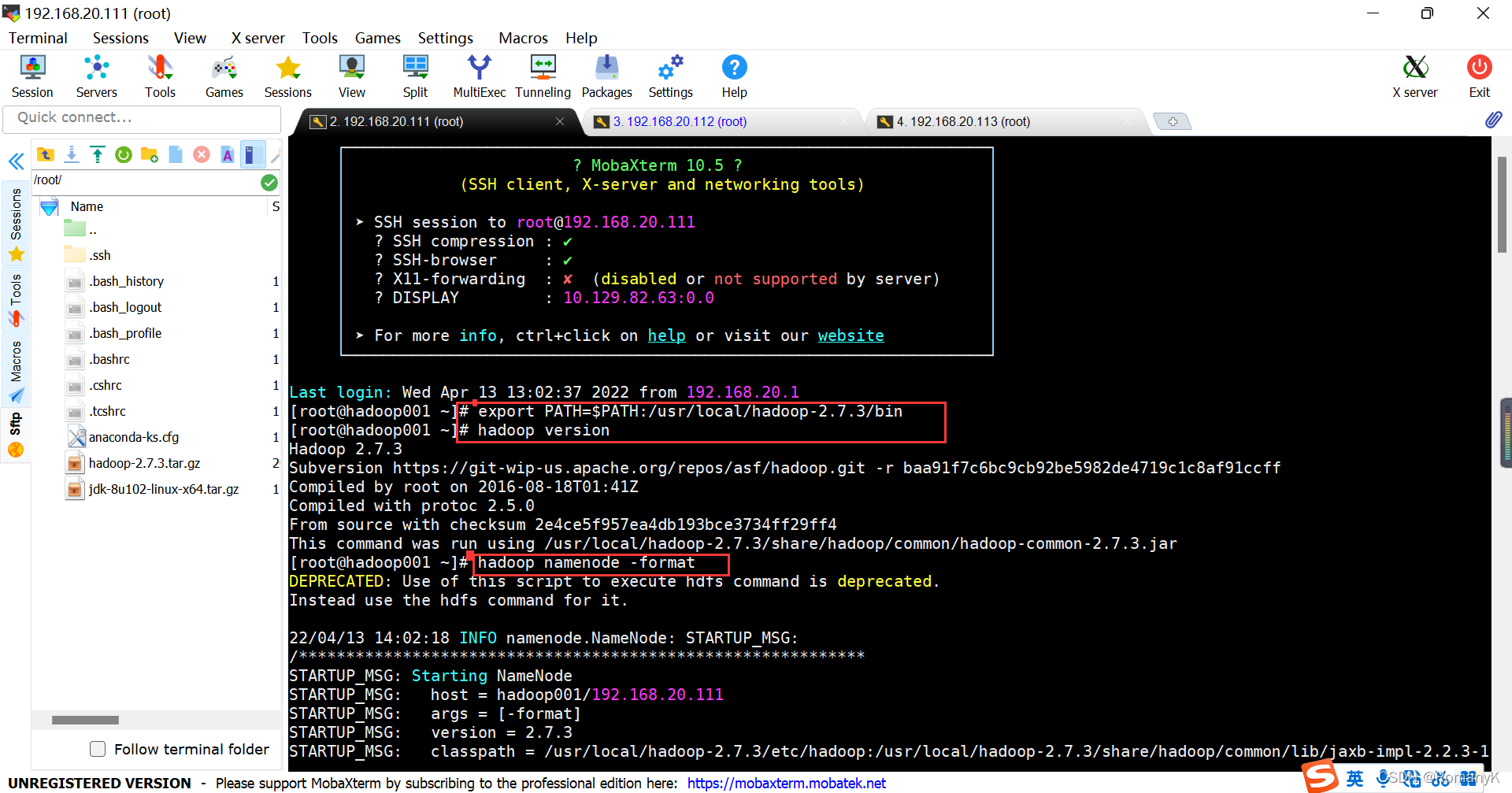
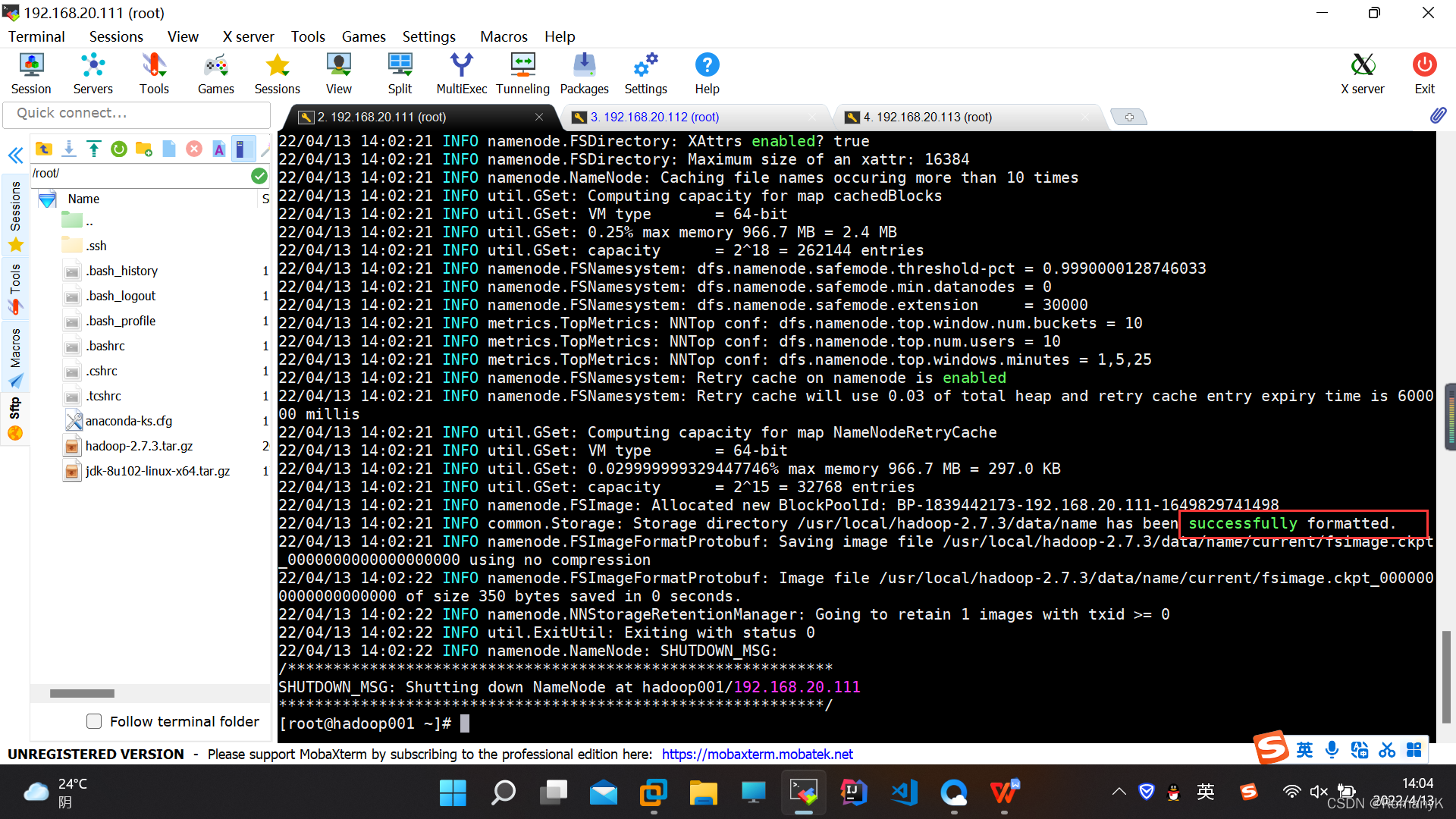
hadoop集群在搭建出来,第一次启动的时候,一定要进行初始化,并且只执行一次 hadoop namenode -format 只能在hadoop001操作一次
hadoop namenode -format
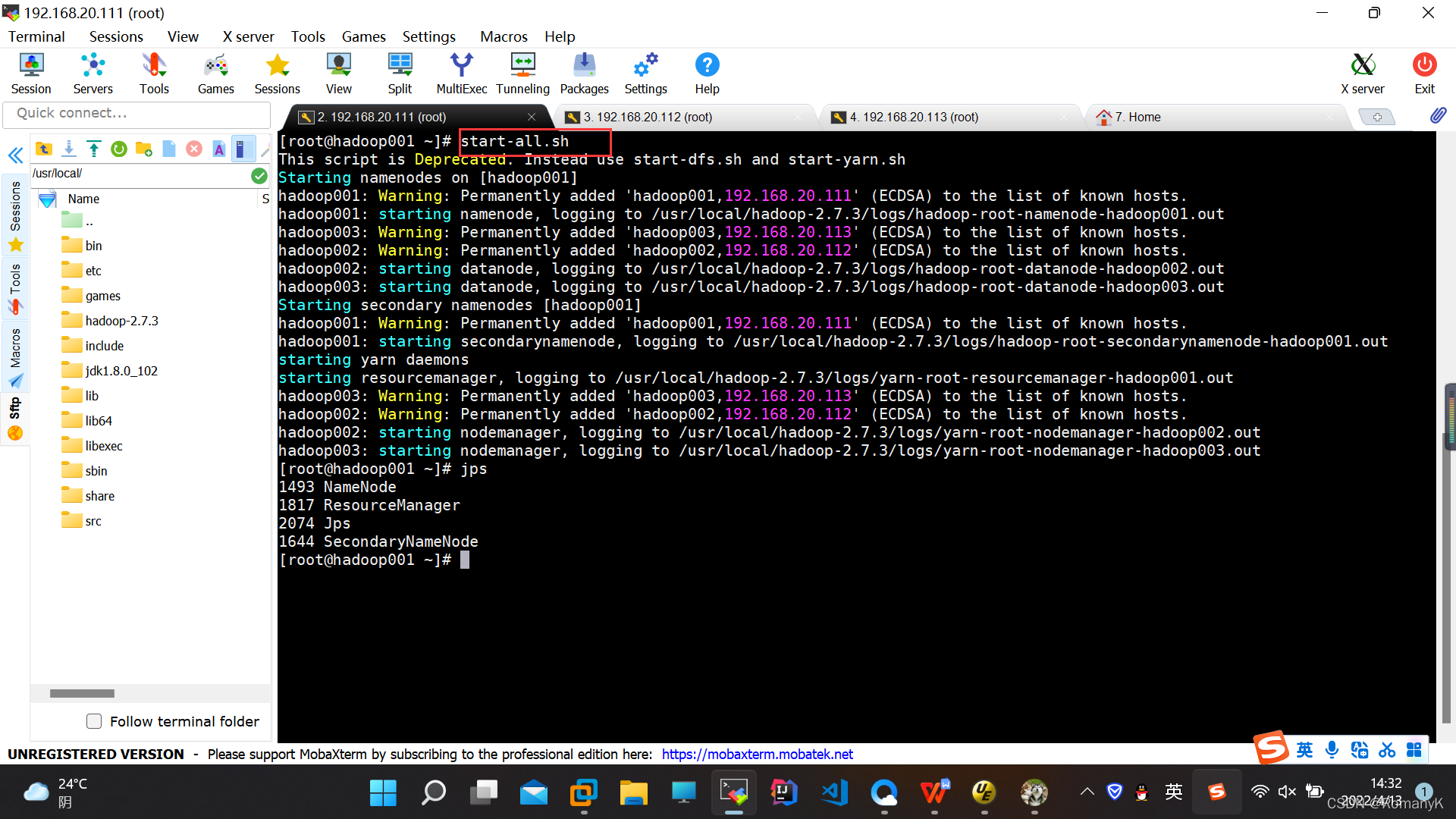
start-all.sh
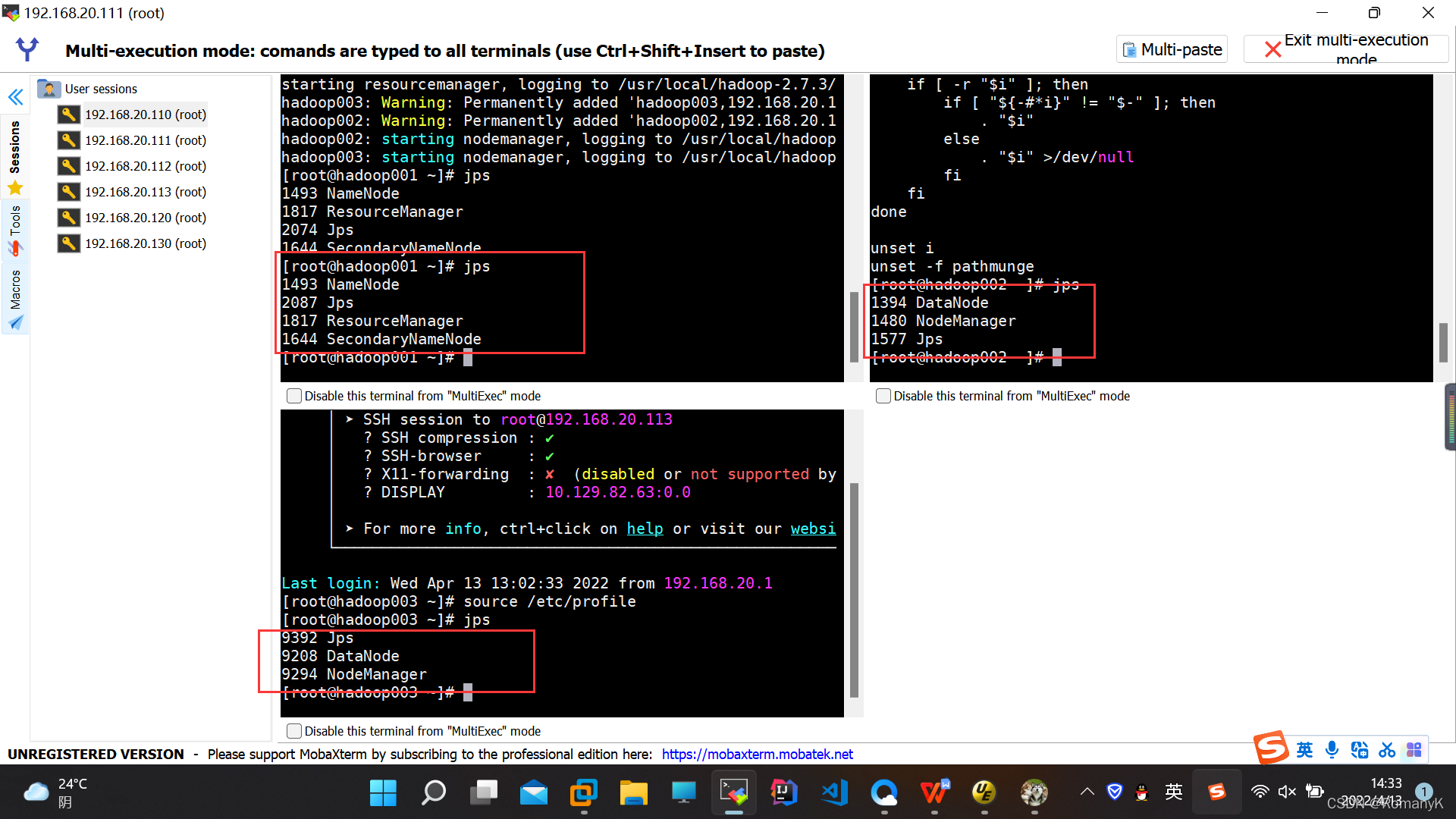
3.验证集群
3.1JPS:
3.2网页查看:
192.168.20.111:50070
192.168.20.111:8088
【IP:端口号(50070与8088)】
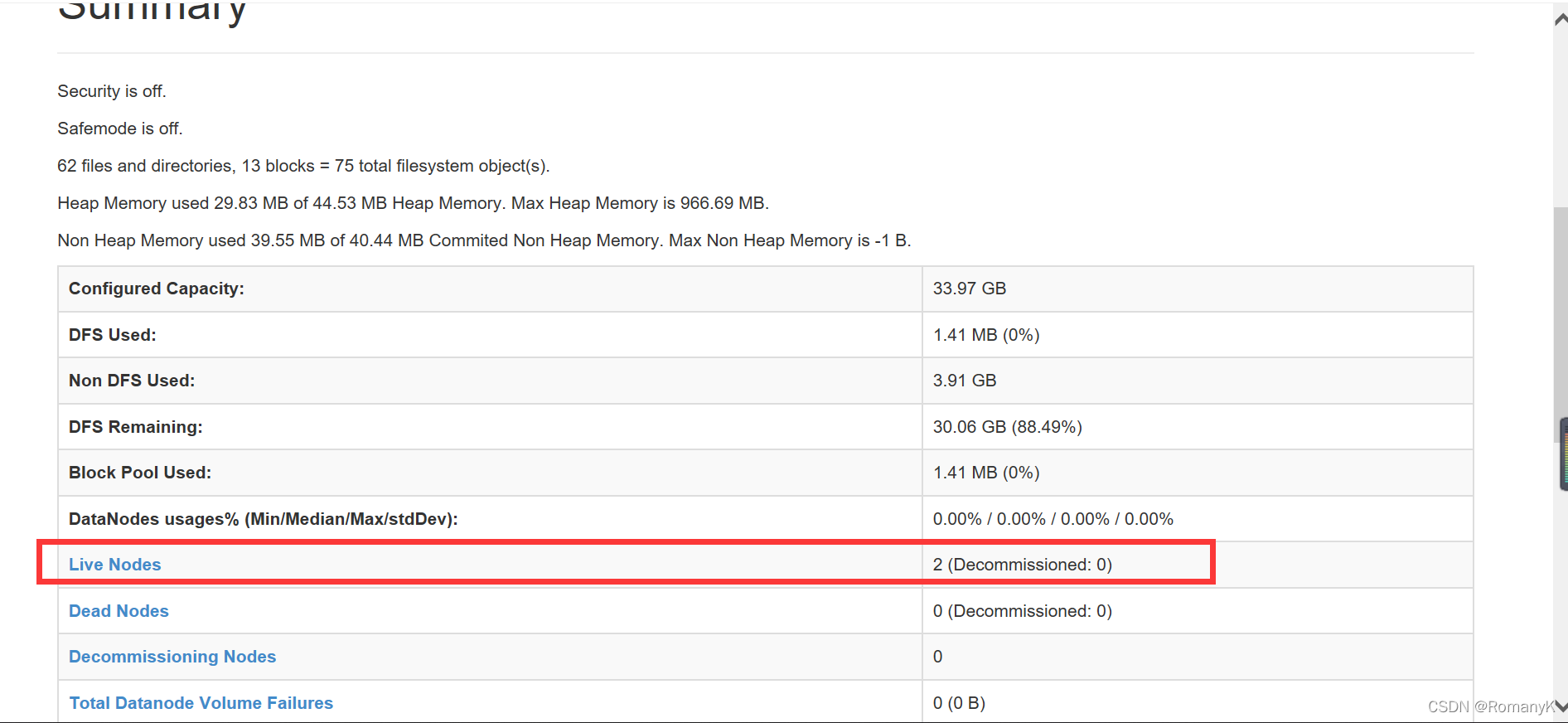
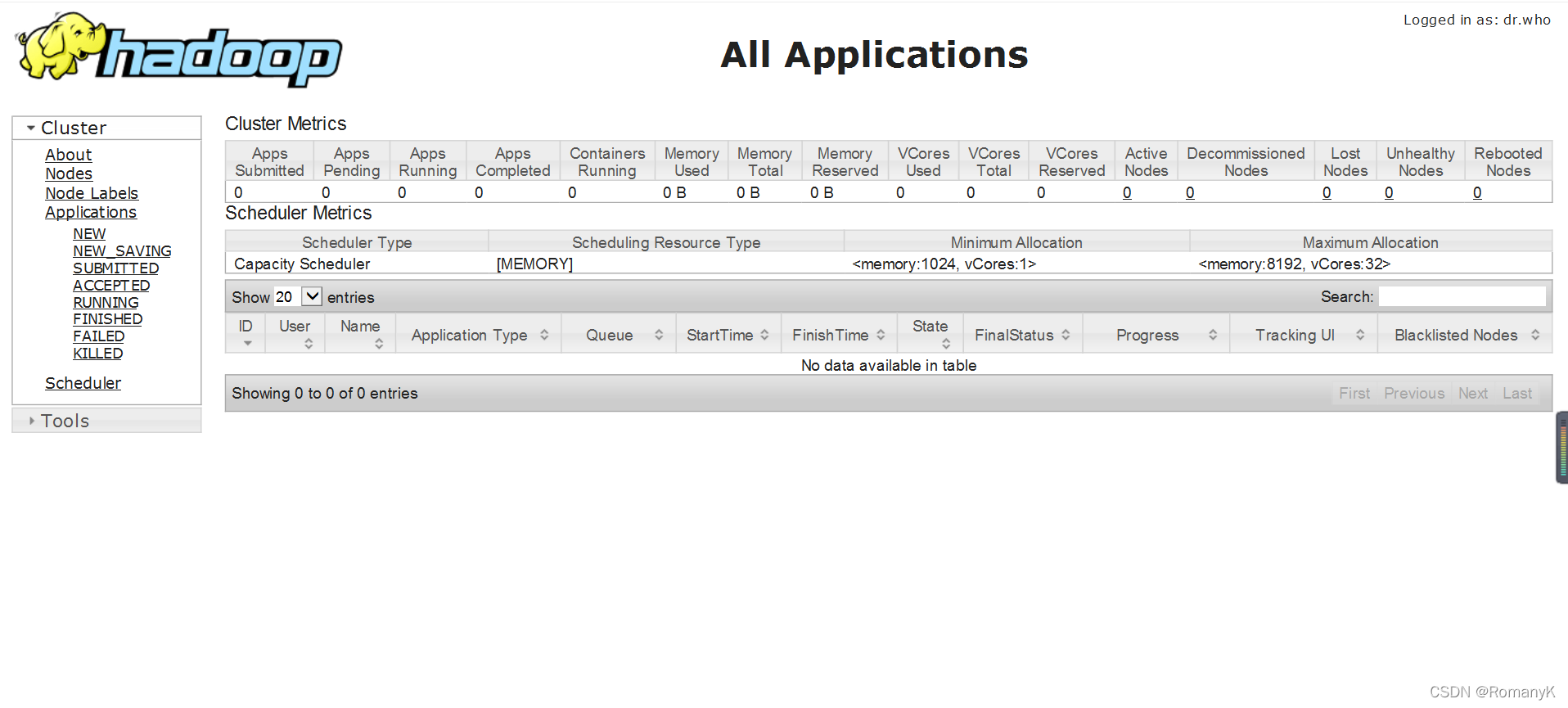
3.3 注意事项(关闭防火墙(永久关闭))!!!
3.4在安装过程有任何问题欢迎来私信我哦!!!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)