Python网络爬虫及自动化——核酸查询并截图
用split()函数将每行分割出姓名与身份证,利用send_keys()对input元素赋值,再调用元素click()进行提交,最后用driver.save_screenshot(dir+"\\"+name+".png")对页面进行截图,保存为姓名.png。也可以通过XPATH来定位页面元素,比如图中input,这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。若无相应
背景:
因为要收集班级学生的核酸证明截图,写此程序,自动完成查询和截图。文中网址已做处理,该网址无验证码,否则需要加入验证码识别。
一、selenium库
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。
因为要截取页面,所以不使用requests库,而使用selenium库的webdriver驱动模块,通过webdriver.Edge()函数调用msedgedriver.exe,使用edge浏览器访问网页。
头文件需引入如下代码
from selenium import webdriver #导入驱动模块
from selenium.webdriver.common.by import By二、元素定位代码
新版本的格式由 driver.find_element_by_方法名(”value”)变为 driver.find_element(By.方法名, “value”),html元素如下:
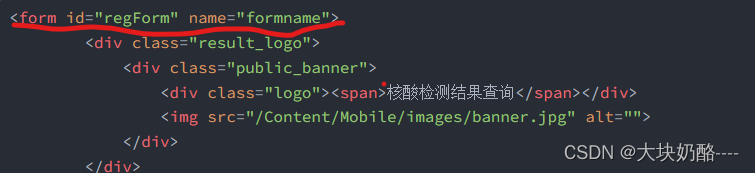
<form id="regForm" name="formname">
<div class="result_logo">
<div class="public_banner">
<div class="logo"><span>核酸检测结果查询</span></div>
<img src="/Content/Mobile/images/banner.jpg" alt="">
</div>
</div>
<div class="public_form" style="padding:.8rem .9rem 0;">
<div class="form_submit">
<ul>
<li class="text_li clearfix">
<div class="title"><b>姓名</b></div>
<div class="form">
<input type="text" id="txtName" placeholder="请输入姓名" maxlength="25">
<span id="eName" class="ps_red" style="display:none"></span>
</div>
</li>
<li class="text_li clearfix">
<div class="title"><b>证件号码</b></div>
<div class="form">
<input type="text" id="txtCardNo" placeholder="请输入证件号码">
<span id="eCardNo" class="ps_red" style="display:none"></span>
</div>
</li>
</ul>
</div>
</div>
</form>
元素定位可通过id,name,tag获取页面元素
driver.find_element(By.ID,"regForm")#通过ID获取元素
driver.find_element(By.NAME,"formname")#通过NAME获取元素
driver.find_element(By.TAG_NAME,"form")#通过NAME获取元素也可以通过XPATH来定位页面元素,比如图中input,这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。
优点:基本上是万能的
缺点:因为要遍历所愿元素的路径,执行效率可能比较慢
定位的方法有两种:
“/” 绝对路径,从页面的根元素开始
“//” 相对路径,从页面上的任何节点开始匹配

使用绝对路径,注意:同级元素的下标从1开始,div[2]表示第二个div元素;get_attribute('outerHTML')获取元素的html内容
driver.find_element(By.XPATH,"//div/input")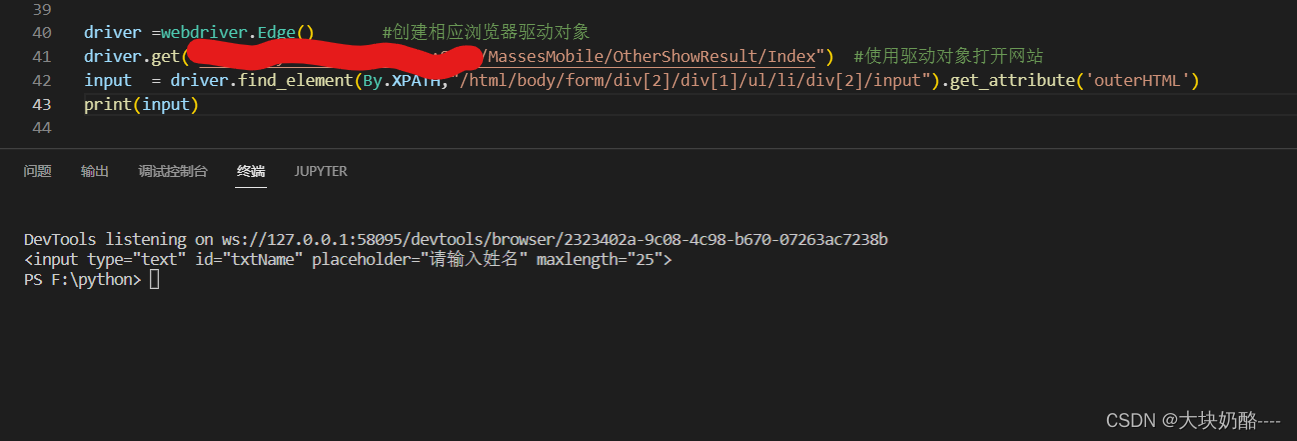
使用相对路径:
driver.find_element(By.XPATH,"//div//input[@id='txtName']").get_attribute('outerHTML')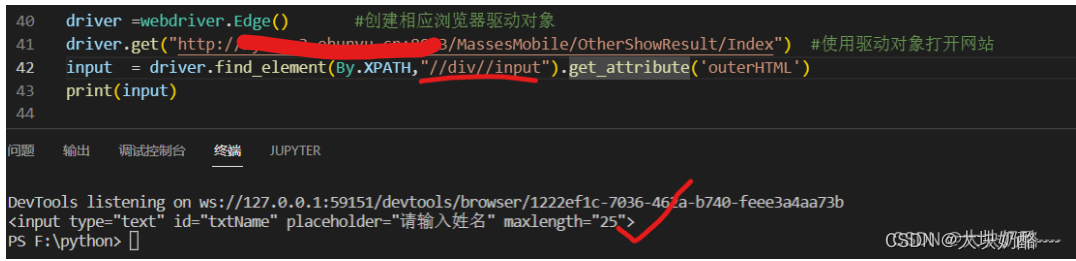
三、完整代码
从花名册.txt中读取姓名与身份证号,每行格式如下: 姓名\t身份号码
用split()函数将每行分割出姓名与身份证,利用send_keys()对input元素赋值,再调用元素click()进行提交,最后用driver.save_screenshot(dir+"\\"+name+".png")对页面进行截图,保存为姓名.png
#网络爬虫及自动化__提交页面截图
from asyncio.windows_events import NULL
from turtle import done
from unicodedata import name
from urllib import request
import requests
from selenium import webdriver #导入驱动模块
from selenium.webdriver.common.by import By
from selenium.common import exceptions
import os
def mdir(dir):
if( not os.path.exists(dir)):
os.makedirs(dir)
def get_result(student):
driver =webdriver.Edge() #创建相应浏览器驱动对象
driver.get("http://xxxxxxxxxxxxxx/OtherShowResult/Index") #使用驱动对象打开网站
driver.set_window_size(700,1024)
for stu in student:
stu.replace("\n","")
name = stu.split("\t")[0]
IDcode = stu.split("\t")[1]
driver.find_element(By.ID,"txtName").send_keys(name)
driver.find_element(By.ID,"txtCardNo").send_keys(IDcode)
driver.find_element(By.ID,"btnSearch").click() #点击
driver.save_screenshot(dir+"\\"+name+".png")
driver.find_element(By.TAG_NAME, "input").click()
input("ok")
dir = "核酸查询结果"
mdir(dir)
student = open("花名册.txt","r+").readlines()
get_result(student)
此源码使用Edge浏览器,需要下载msedgedriver.exe,并且放在Python安装目录或源码py文件的所在目录 。还可以使用Chrome、Firefox、IE等浏览器。
若无相应的浏览器驱动,Python报错,并提示相应的下载链接,下载后放在Python目录。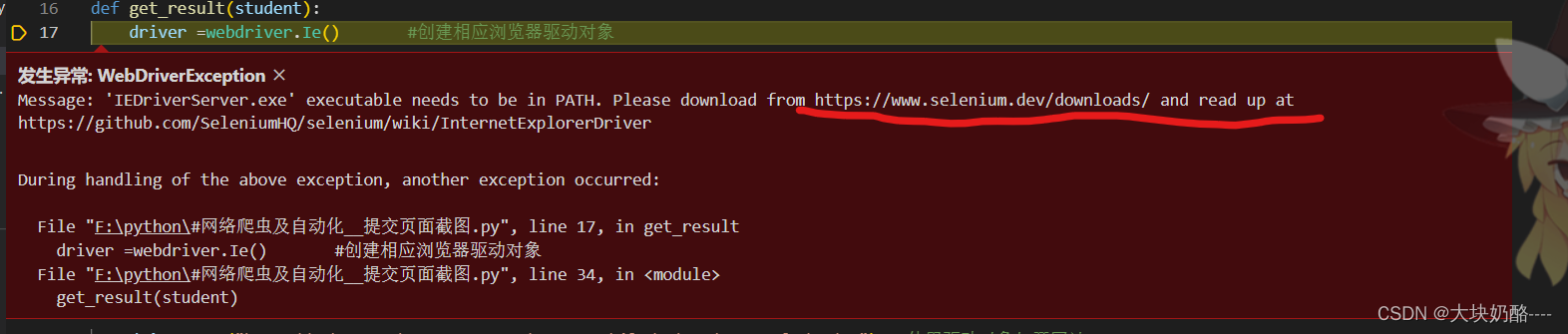

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)