Python自动化办公—DOCX库(一)
今天学习了docx库,记录一下笔记,总结一下自己的理解,方便以后查阅。首先要了解docx文档的基本结构。python-docx将整个文章看作是一个Document对象。其基本结构如下:每个Document包含多个代表“段落”的Paragraph对象,存放在document.paragraphs中。每个Paragraph都有多个代表“行内元素”的Run对象,代表内容的text对象,和代表表格的tab
今天学习了docx库,记录一下笔记,总结一下自己的理解,方便以后查阅。
- 首先要了解docx文档的基本结构。
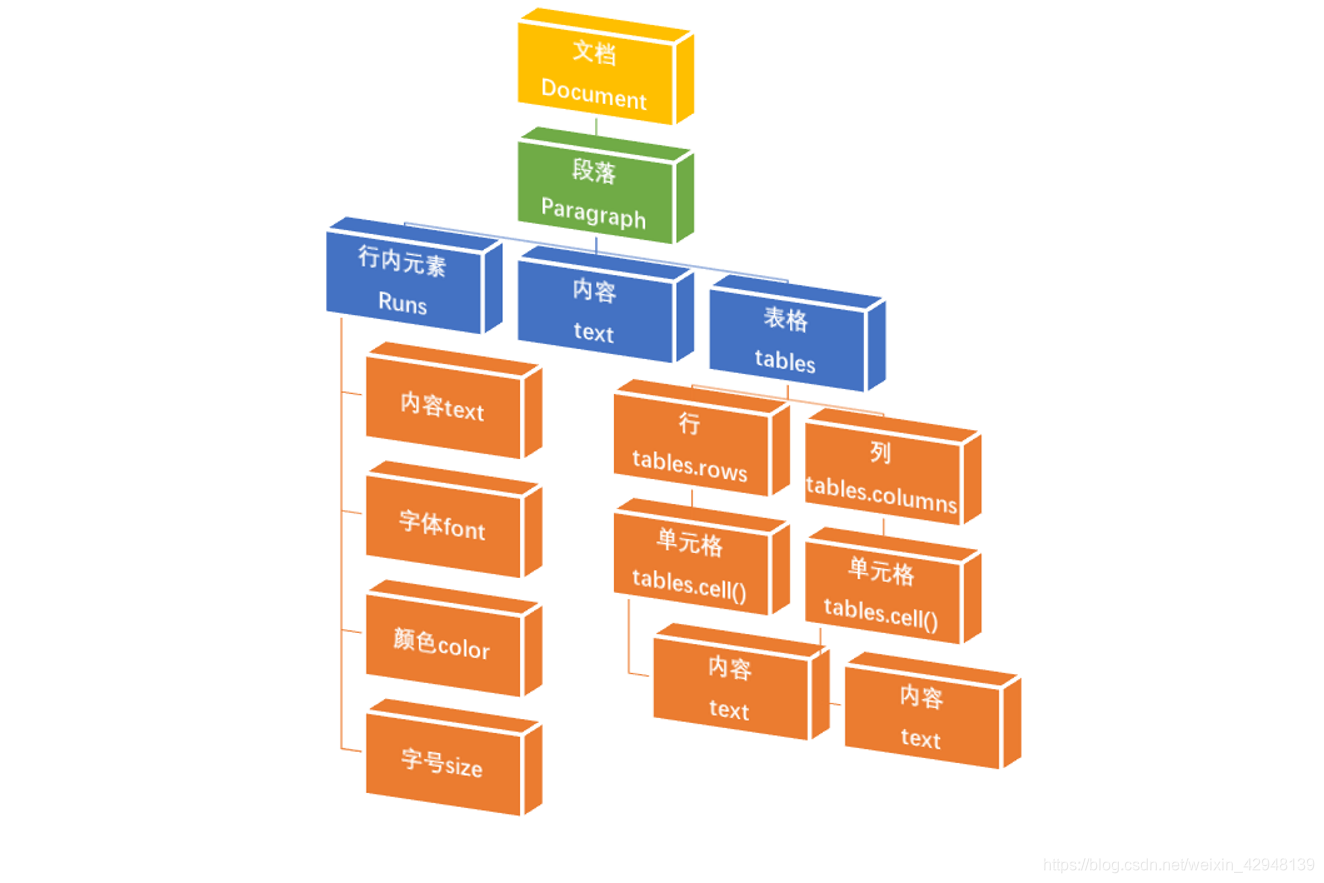
python-docx将整个文章看作是一个Document对象。其基本结构如下:
每个Document包含多个代表“段落”的Paragraph对象,存放在document.paragraphs中。每个Paragraph都有多个代表“行内元素”的Run对象,代表内容的text对象,和代表表格的tables对象。 - 读取docx文件中的表格数据
读取word所有内容
from docx import Document
file=Document('F:\工作\自动化办公\时间序列分析论文要求.docx')
for para in file.paragraphs:
print(para.text)
读取一级标题(读取二级标题时把Heading 1改为Heading 2,以此类推)
from docx import Document
file=Document('F:\工作\自动化办公\时间序列分析论文要求.docx')
for para in file.paragraphs:
if para.style.name == 'Heading 1':
print(para.text)
读取所有标题
import re
for para in file.paragraphs:
if re.match('^Heading \d+$',para.style.name):
print(para.text)
读取正文
from docx import Document
file = Document('F:\work\自动化办公\时间序列分析论文要求.docx')
for para in file.paragraphs:
if para.style.name=='Normal':
print(para.text)
读取标题名称:
from docx.enum.style import WD_STYLE_TYPE
from docx import Document
file = Document('F:\work\自动化办公\时间序列分析论文要求.docx')
title=file.styles
for i in title:
if i.type == WD_STYLE_TYPE.PARAGRAPH:
print(i.name)
- 写入Word文字
添加标题
from docx import Document
file = Document()
file.add_heading(text="时间序列分析论文要求",level=1)
file.save('F:\work\自动化办公\时间序列分析论文要求2.docx')
添加正文file.add_paragraph(text='', style=None)
style是段落样式参数,默认为None
添加分页符file.add_page_break()
添加文字块 块一般在段落下一层,因此需要先添加段落‘
a=file.add_paragraph('')#添加的文本是这一段的第一块
a.add_run(text=None, style=None) #这一段的第二块,添加的字体是普通字体
a.add_run(text=None, style=None).bold=True#这一段的第三块,添加的字体是加粗
a.add_run(text=None, style=None).italic=True#这一段的第四块,添加的字体是斜体
段落的定位:para=file.paragraphs[i]
指定段落处添加段落:原第二个段落变成第三个段落
para= file.paragraphs[1] # 获取第二个段落
para.insert_paragraph_before( text=None, style=None) # 在第二个段落处插入
插入图片add_picture(image_path_or_stream, width=None, height=None)
from docx.shared import Cm
file.add_picture('路径', width = Cm(13), height = Cm(8))
#或在单元格中添加图片 #表中分单元格,单元格里再分段,再分块
run = file.tables[0].cell(0,0).paragraphs[0].add_run()
run.add_picture('路径', width = Cm(13), height = Cm(8))
设置图片对齐方式
在插入图片时,经常使用run.add_picture()方法,本质上仍然是在段落中添加,所以,改变段落对齐对齐方式,效果也作用到图片上,这个时候的图片是单独一个段落。
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 导入段落对齐包
pic = file.paragraphs[i]#图片的位置
pic.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 设置图片所在段落居中
在WD_PARAGRAPH_ALIGNMENT可以实现LEFT、RIGHT、CENTER、JUSTY和DISTRIBUTE等5种对齐方式
WD_PARAGRAPH_ALIGNMENT.LEFT # 左对齐
WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐
WD_PARAGRAPH_ALIGNMENT.RIGHT # 右对齐
WD_PARAGRAPH_ALIGNMENT.JUSTIFY # 两端对齐
WD_PARAGRAPH_ALIGNMENT.DISTRIBUTE # 分散对齐
图片删除
图像是通过run对象的add_picture()来添加的,而run对象是段落的一部分,所以通过删除段落可以删除图像。
pic = file.paragraphs[i]
pic.clear()
- 表格
添加表格file.add_table(rows = 多少行, cols = 多少列)
利用行,列双循环遍历到每个单元格
添加表格行和列
添加行:file.tables[i].add_row() # 表格最下方增加一行
添加列:file.tables[i].add_column(width) # 表格最右侧增加一列,一定要写列宽
删除表格中的行、列
在表格中虽然单元格可以从column中的cells中来遍历,但是单元格是按行存储的
删除表格中的行
aa=file.tables[i].rows[i]
aa._element.getparent().remove(aa._element) # 删除行
删除表格中的列
列的删除则不能像删除行那样使用对应的remove()函数,因为在_Column中没有定义_element,但可以采用单元格进行删除
删除表格中的行
删除列不能像删除行那样使用相应的_remove函数,因为在_Column中没有定义_element,因此删除列的使用可以删除相应的单元格来实现。
bb=file.tables[i].columns[i]
for run in bb.cells:
run._element.getparent().remove(run._element)
通过cell的remove()方法可以删除表格的列,但是由于表格中的cell是按行存储,每行存储的cell的数量并没有变化,所以当删除单元格后,后续的单元格会补上。
表格的删除file.tables[i]._element.getparent().remove(file.tables[i]._element)
设置单元格的值
表格中单元格的值有两种赋值方式,一种是直接为cell.text属性赋值来实现,另外一种是通过获取或者添加单元格中的段落,然后使用段落中的text属性赋值实现
from docx import Document
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 导入段落对齐方式
tab=file.add_table(i,j)
tab.cell(i,j).text=' '
para=tab.cell(i,j).paragraphs[i]
para.text=' '
para.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 设置段落居中
#第一种赋值方式,只能更改单元格的值,无法设置单元格中数据的样式,并且整个单元格只能是一个段落;
#而第二种赋值方式,使用了段落,在单元格赋值的基础上还能增加新的段落,并设置段落的样式和字体的样式
删除单元格数据可以使用赋值的方法,是单元格的数据为空即可。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)