异常值检测常用算法及案例
异常值检测常用方法对历史数据进行异常值检测,对突发情况或者异常情况进行识别,避免因为异常值导致预测性能降低,并对其进行调整便于后续预测。一、3-sigma原则异常值检测3-Sigma原则又称为拉依达准则,该准则定义如下:假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。如果数据服从正态分布,异常值被定义为一组测定值中
异常值检测常用方法
对历史数据进行异常值检测,对突发情况或者异常情况进行识别,避免因为异常值导致预测性能降低,并对其进行调整便于后续预测。
一、3-sigma原则异常值检测
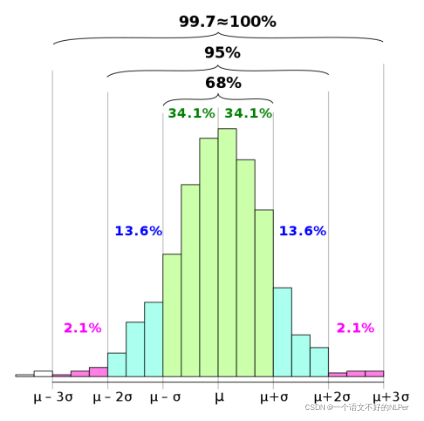
3-Sigma原则又称为拉依达准则,该准则定义如下:假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。如果数据服从正态分布,异常值被定义为一组测定值中与平均值的偏差超过3倍的值 → p(|x - μ| > 3σ) ≤ 0.003。
样例如下:
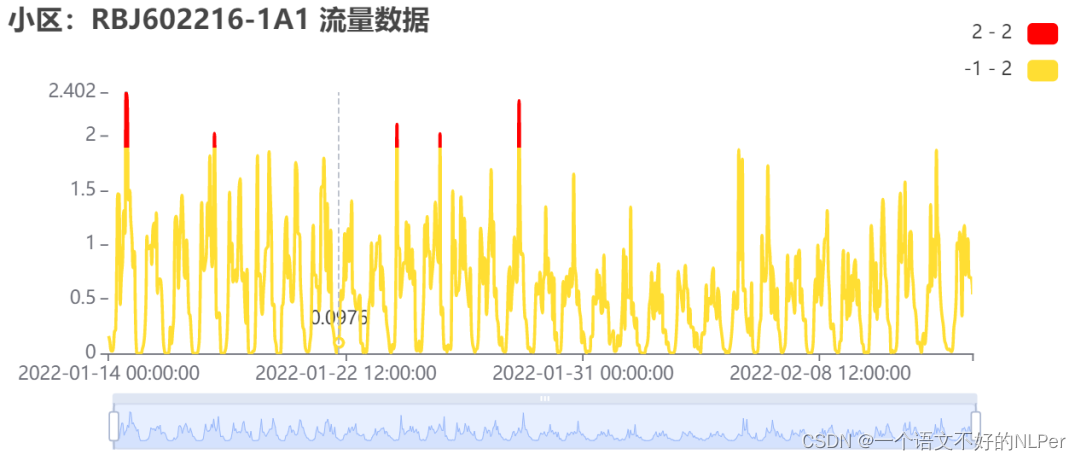
对于波动较为规律性的部分数据,异常值往往即最大值、最小值,对这种情况只需取规则上限进行修匀。
对于长期为0,偶尔存在较高业务量的情形,3-sigma原则能够较好地识别较极端的部分,对于较小的部分会进行保留,不会将所有非0值剔除,比较符合实际场景。
核心函数:
sample_data中仅需要包含一个字段:总流量
每行代表一个时间点,将会对总流量这一列进行异常值检测,并得到一个标签。
def three_sigma(sample_data):
"""
3-sigma法则异常值判定
"""
data_mean = np.array(sample_data['总流量'].tolist()).mean() # 计算均值
data_std = np.array(sample_data['总流量'].tolist()).std() # 计算标准差
data_max = data_mean + 3 * data_std
data_min = data_mean - 3 * data_std
sample_data['three_sigma'] = 0
sample_data.loc[(sample_data['总流量'] > data_max) | (sample_data['总流量'] < data_min), 'three_sigma'] = 1
length = len(sample_data[sample_data['three_sigma']==1]) # 3-sigma方法的异常值数量
if length!=0:
print('3-sigma方法的异常值数量:{}'.format(length))
return sample_data
二、箱线法异常值检测
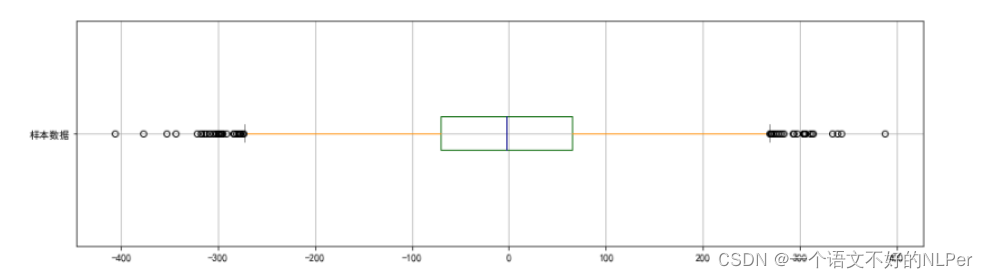
箱形图可以用来观察数据整体的分布情况,利用中位数,25/%分位数,75/%分位数,上边界,下边界等统计量来来描述数据的整体分布情况。通过计算这些统计量,生成一个箱体图,箱体包含了大部分的正常数据,而在箱体上边界和下边界之外的,就是异常数据。
检测样例如下:
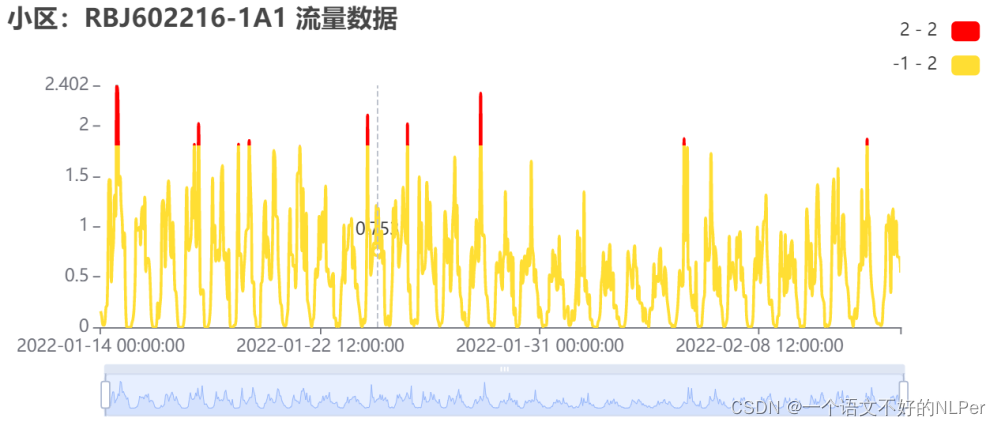
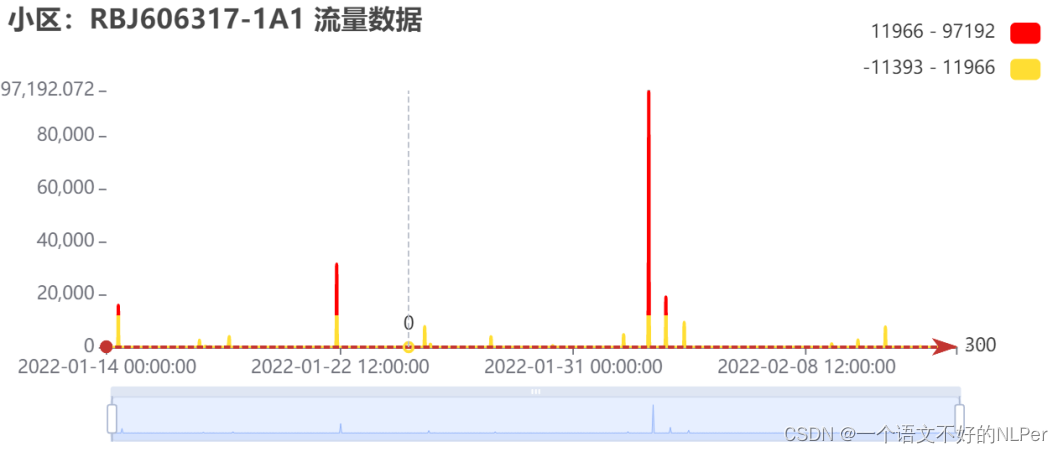
对于曲线波动较平稳且存在一定规律性的小区,检测效果与3-sigma相似,都集中在极值附近。

对于较极端情形,箱线法将所有值都判定为异常值,不符合常理。
核心代码:
def box_test(sample_data):
"""
箱线法
"""
Q1 = np.percentile(sample_data['总流量'], 25) # 计算1/4分位数
Q3 = np.percentile(sample_data['总流量'], 75) # 计算3/4分位数
IQR = Q3 - Q1
outlier_step = 1.5 * IQR
min_limit_box = Q1 - outlier_step
max_limit_box = Q3 + outlier_step
print('正常值范围是:'+str(min_limit_box)+'---'+str(max_limit_box))
sample_data['box_test'] = 0
sample_data.loc[(sample_data['总流量'] > max_limit_box) | (sample_data['总流量'] < min_limit_box), 'box_test'] = 1
length = len(sample_data[sample_data['three_sigma']==1]) # 3-sigma方法的异常值数量
if length!=0:
print('箱线法得到异常值数量:{}'.format(length))
return sample_data
三、adtk异常值检测
智能运维AIOps的数据基本上都是时间序列形式的,而异常检测告警是AIOps中重要组成部分,异常值检测在智能运维中应用十分广泛。
同时对于电力负荷、业务量预测而言也可以借鉴相应方法,提升数据质量。
adtk包主要包含:
- 简单有效的异常检测算法(detector)
- 异常特征加工(transformers)
- 处理流程控制(Pipe)
1. adtk数据要求
时间序列的数据主要包括时间和相应的指标(如cpu,内存,数量,电力负荷、业务量等)。
python中数据分析一般都是pandas的DataFrame,adtk要求输入数据的索引必须是DatetimeIndex。
pandas提供了时间序列的时间生成和处理方法。
- pd.to_datetime
也可以用处理脚本进行转换:
time_data = sample_data['总流量']
time_index = pd.to_datetime(sample_data['time'])
time_data.index = time_index
adtk提供是validate_series来验证时间序列数据的有效性,如是否按时间顺序
time_data = validate_series(time_data)
2. 异常特征加工(transformers)
adtk中transformers提供了许多时间序列特征加工的方法:
- 一般我们获取时间序列的特征,通常会按照时间窗口在滑动,采集时间窗口上的统计特征;
- 还有对于季节性趋势做分解,区分哪些是季节性的部分,哪些是趋势的部分
- 时间序列降维映射:对于细粒度的时间序列数据,数据量大,对于检测算法来说效率不高。降维方法能保留时间序列的主要趋势等特征同时,降低维数,提供时间效率。这个对于用CNN的方式来进行时间序列分类特别有效,adtk主要提供基于pca的降维和重构方法,主要应用于多维时间序列。
3. 异常检测算法(detector)
adtk提供的主要是无监督或者基于规则的时间序列检测算法,可以用于常规的异常检测。
-
ThresholdAD 人为定阈值
adtk.detector.ThresholdAD(low=None, high=None) 参数: low:下限,小于此值,视为异常 high:上限,大于此值,视为异常 原理:通过认为设定上下限来识别异常 总结:固定阈值算法from adtk.detector import ThresholdAD threshold_ad = ThresholdAD(high=30, low=15) anomalies = threshold_ad.detect(time_data)
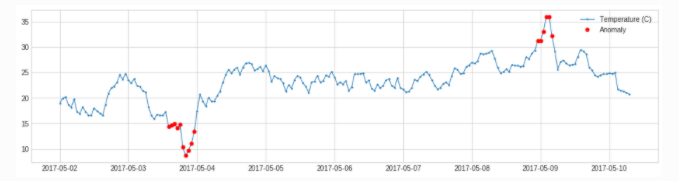
在现实数据集中,异常值往往是多个而非单个。为了将Grubbs’ Test扩展到k个异常值检测,
则需要在数据集中逐步删除与均值偏离最大的值(为最大值或最小值),同步更新对应的t分布临界值,检验原假设是否成立。
GESD是一种简单的统计方法,用于检测遵循近似正态分布的单变量数据集中的一个或多个异常值。
统计方法假设常规数据遵循某种统计模型(或分布),而不遵循模型(或分布)的数据则是异常值。
GeneralizedESDTestAD
adtk.detector.GeneralizedESDTestAD(alpha=0.05)
参数:
alpha:显著性水平 (Significance level),alpha越小,表示识别出的异常越有把握是真异常
原理:将样本点的值与样本的均值作差后除以样本标准差,取最大值,通过t分布计算阈值,对比阈值确定异常点
计算步骤简述:
设置显著水平alpha,通常取0.05
指定离群比例h,若h=5%,则表示50各样本中存在离群点数为2
计算数据集的均值mu与标准差sigma,将所有样本与均值作差,取绝对值,再除以标准差,找出最大值,得到esd_1
在剩下的样本点中,重复步骤3,可以得到h个esd值
为每个esd值计算critical value: lambda_i (采用t分布计算)
统计每个esd是否大于lambda_i,大于的认为你是异常
from adtk.detector import GeneralizedESDTestAD
esd_ad = GeneralizedESDTestAD(alpha=0.3)
anomalies = esd_ad.fit_detect(time_data)

突变: Spike and Level Shift 异常的表现形式不是离群点,而是通过和临近点的比较,即突增或者突降。adtk提供adtk.detector.PersistAD 和 adtk.detector.LevelShiftAD检测方法
可以并排滑动两个时间窗口,并继续跟踪它们的平均值或中值之间的差异。这种随时间的差异是一个新的时间序列,由异常值检测器检查。每当左右窗口中的统计数据显着不同时,就表明在这个时间点附近发生了突变。时间窗口长度控制检测变化的时间尺度:对于尖峰,左侧窗口比右侧窗口长,以捕获近期的代表性信息;另一方面,对于电平转换,两个窗口都应该足够长以捕捉稳定状态。
PersistAD将每个时序值与其以前的值进行比较。在内部,它被实现为带有变压器DoubleRollingAggregate的管道网络。
adtk.detector.PersistAD(window=1, c=3.0, side='both', min_periods=None, agg='median')
参数:
window:参考窗长度,可为int, str
c:分位距倍数,用于确定上下限范围
side:检测范围,为’positive’时检测突增,为’negative’时检测突降,为’both’时突增突降都检测
min_periods:参考窗中最小个数,小于此个数将会报异常,默认为None,表示每个时间点都得有值
agg:参考窗中的统计量计算方式,因为当前值是与参考窗中产生的统计量作比较,所以得将参考窗中的数据计算成统计量,默认’median’,表示去参考窗的中位值
原理:
用滑动窗口遍历历史数据,将窗口后的一位数据与参考窗中的统计量做差,得到一个新的时间序列s1;
from adtk.detector import PersistAD
persist_ad = PersistAD(c=3.0, side='positive')
anomalies = persist_ad.fit_detect(s)
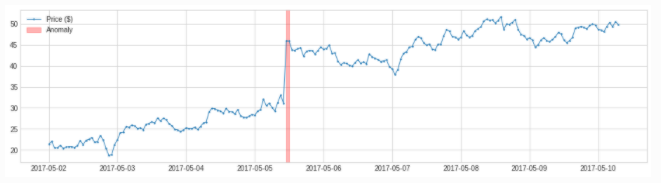
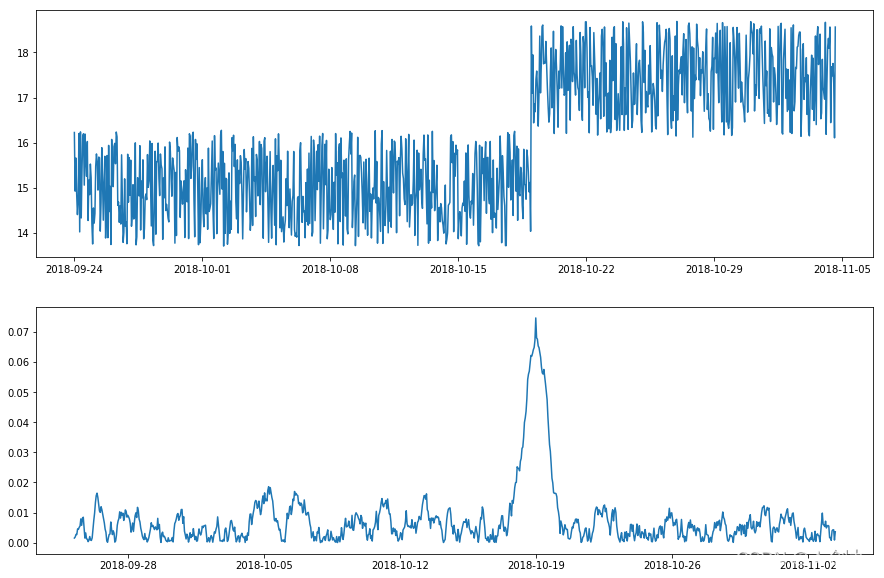
LevelShiftAD通过跟踪两个相邻滑动时间窗口的中位数值之间的差异来检测值水平的偏移。
它对瞬时峰值不敏感,如果经常发生嘈杂的异常值,它可能是一个不错的选择。在内部,它被实现为带有变压器DoubleRollingAggregate的管道网络。
LevelShiftAD
adtk.detector.LevelShiftAD(window, c=6.0, side='both', min_periods=None)
参数:
window:支持(10,5),表示使用两个相邻的滑动窗,左侧的窗中的中位值表示参考值,右侧窗中的中位值表示当前值
c:越大,对于波动大的数据,正常范围放大较大,对于波动较小的数据,正常范围放大较小,默认6.0
side:检测范围,为'positive'时检测突增,为'negative'时检测突降,为'both'时突增突降都检测
min_periods:参考窗中最小个数,小于此个数将会报异常,默认为None,表示每个时间点都得有值
原理:
该模型用于检测突变情况,相比于PersistAD,其抗抖动能力较强,不容易出现误报
from adtk.detector import LevelShiftAD
level_shift_ad = LevelShiftAD(c=6.0, side='both', window=5)
anomalies = level_shift_ad.fit_detect(time_data)
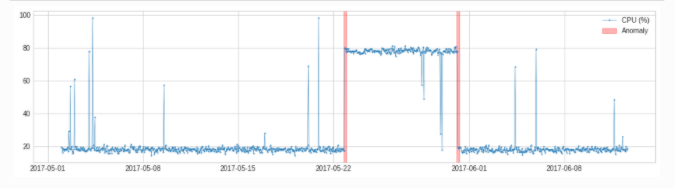
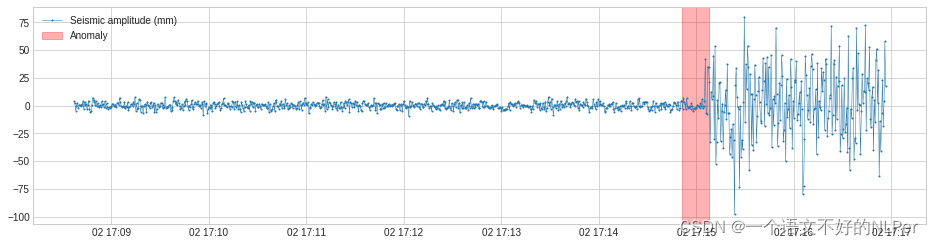
VolatilityShiftAD通过跟踪两个相邻滑动时间窗口下标准偏差之间的差异来检测波动率水平的变化。在内部,它被实现为带有变压器DoubleRollingAggregate的管道网络。
在下面的例子中,我们检测到地震振幅波动性的正向偏移,这表明地震的开始。
from adtk.detector import VolatilityShiftAD
volatility_shift_ad = VolatilityShiftAD(c=6.0, side='positive', window=30)
anomalies = volatility_shift_ad.fit_detect(time_data)
plot(time_data, anomaly=anomalies, anomaly_color='red');
四. 总结
时间序列异常检测的无监督算法工具包ADTK提供了简单的异常检测算法和时间序列特征加工函数。
- adtk要求输入数据为datetimeIndex,
validate_series来验证数据有效性,使得时间有序 - adtk单窗口和double窗口滑动,加工统计特征
- adtk分解时间序列的季节部分,获得时间序列的残差部分,可根据这个判断异常点
- adtk支持离群点、突变和季节性异常检测。通过
fit_detect获取异常点序列,也可以通过Pipeline联通多部异常检测算法

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)