Linux服务器卡顿如何排查
一、背景在一次测试中发现服务器非常卡顿,刚开始任务是网络问题导致,可是别人的服务却可以正常运行,于是进行了一些列排查。二、排查步骤2.1 查看内存使用情况## -g表示单位是G,-m 表示单位是mfree -g2.2 查看磁盘使用情况df -h查看磁盘的 已用 情况是否过高。2.3 查看磁盘IO使用情况## 1 表示没1s刷新一下iostat -x 1## 查看磁盘列表lsblk查看磁盘的io情况
一、背景
在一次测试中发现服务器非常卡顿,刚开始任务是网络问题导致,可是别人的服务却可以正常运行,于是进行了一些列排查。
二、排查步骤
2.1 查看内存使用情况
## -g表示单位是G,-m 表示单位是m,要使用-m,因为-g会向下取整,不准确
free -m


2.2 查看磁盘使用情况
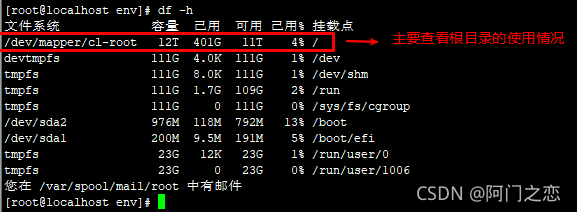
df -h
查看磁盘的 已用 情况是否过高。
2.3 查看磁盘IO使用情况
## 1 表示没1s刷新一下
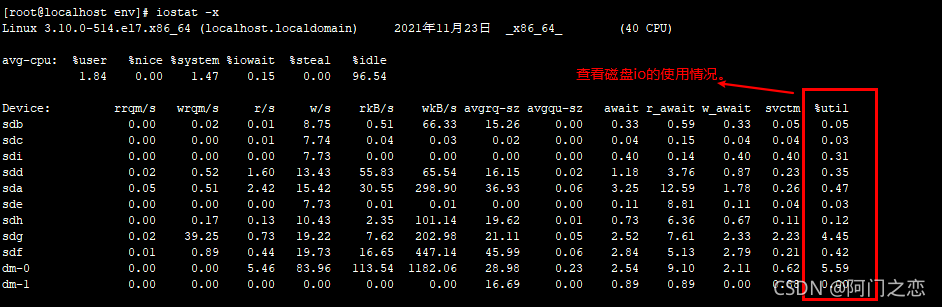
iostat -x 1
## 查看磁盘列表
lsblk
查看磁盘的io情况是否使用过高。
2.4 top 查看cpu使用情况,类似于Windows的任务管理器
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明:
d:指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p:★通过指定监控进程ID来仅仅监控某个进程的状态。
q:该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S:指定累计模式。
s:使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i:使top不显示任何闲置或者僵死进程。
c:★显示整个命令行而不只是显示命令名。

## 显示整个命令行而不只是显示命令名。
top -c
##
## 显示进程号为xxx的信息
top -p XXXX
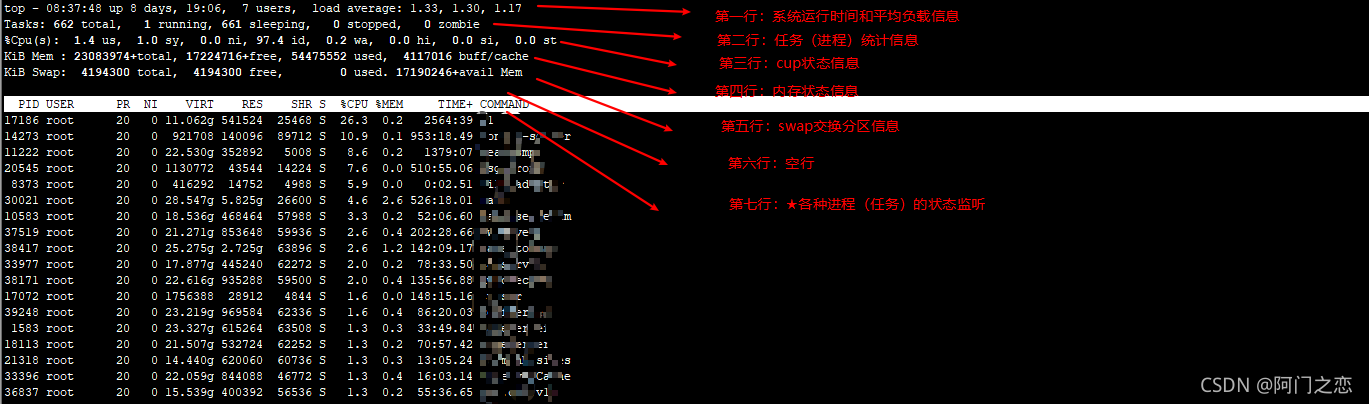
2.4.1 第一行:系统运行时间和平均负载
top - 08:43:13 up 8 days, 19:11, 7 users, load average: 1.55, 1.41, 1.25
系统时间:08:43:13
运行时间:up 8 days,这这段时间里没有关机或重启过。
当前登录用户: 7 user
★负载均衡(uptime) load average: 0.00, 0.00, 0.00
average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。
如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
★Load Average:数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。它的值应该小于CPU个数X核数X0.7
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
Load Average会有3个状态平均值,分别是1分钟、5分钟和15分钟平均Load。
如果1分钟平均出现大于CPU个数X核数的情况,还不需要担心;
如果5分钟的平均也是这样,那就要警惕了;
15分钟的平均也是这样,就要分析哪里出现问题,防范未然。
当系统负载继续大于0.7时,你必须开始调查问题,并防止情况恶化。
当系统负载继续大于1.0时,你必须找到解决方案,并降低该值。
当系统负载达到5.0时,表明系统存在严重问题,并且长时间没有响应,或几乎崩溃。你不应该让系统达到此值。
2.4.2 第二行:任务(进程)统计信息
Tasks: 661 total, 1 running, 660 sleeping, 0 stopped, 0 zombie
总进程:661 total, 运行:1 running, 休眠:660 sleeping, 停止: 0 stopped, 僵尸进程: 0 zombie
2.4.3 第三行:cpu状态信息
这里显示不同模式下所占cpu时间百分比,这些不同的cpu时间表示:
%Cpu(s): 1.9 us, 1.2 sy, 0.0 ni, 96.6 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
1.9 us【user space】— 用户空间占用CPU的百分比。
1.2 sy【sysctl】— 内核空间占用CPU的百分比。
0.0 ni【niced】— 改变过优先级的进程占用CPU的百分比
96.6 id【idolt】— 空闲CPU百分比
0.2 wa【wait】— IO等待占用CPU的百分比
0.0 hi【Hardware IRQ】— 硬中断占用CPU的百分比
0.0 st【Software Interrupts】— 软中断占用CPU的百分比
Linux 操作系统和驱动程序运行在内核空间,应用程序运行在用户空间。
2.4.4 第四行:内存状态
1003020k total【物理内存】, 234464k used【使用中的内存】, 777824k free【空闲内存】, 24084k buffers【缓存的内存量】
2.4.5 第五行:swap交换分区
2031612k total【交换区总量】, 536k used【使用的交换区总量】, 2031076k free【空闲交换区总量】, 505864k cached【缓冲的交换区总量】
备注:
可用内存近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,
第四行中空闲内存总量(free)是内核还未纳入其管控范围的数量。
纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心
2.4.6 空行
2.4.7 各进程(任务)的状态监控
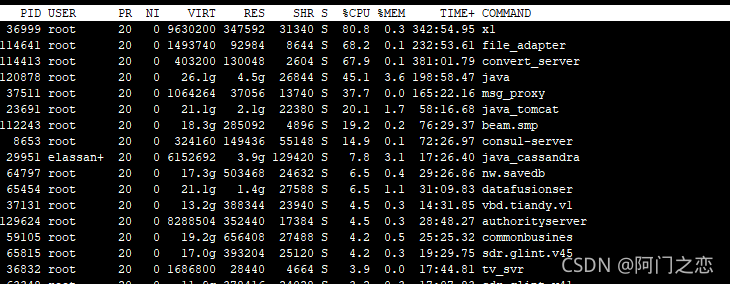
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S —进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — `上次更新到现在的CPU时间占用百分比`
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
详解
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来
DATA
1、数据占用的内存。如果top没有显示,按f键可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
2.4.8 top内部命令如下:
1 – ★数字1 按数字“1”可监控每个逻辑CPU的状况
f/F – ★添加或删除top中的显示字段
K – ★终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
u – ★搜索某一用户得进程
n – ★设置在进程列表所显示进程的数量
s – ★改变画面更新周期,单位时秒
P – ★排序【%cpu】以 CPU 占用率大小的顺序排列进程列表
c – ★切换显示命令名称和完整命令行。
o或者O:改变显示项目的顺序
l – 关闭或开启第一部分第一行 切换显示平均负载和启动时间信息。
t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示切换显示进程和CPU状态信息。
m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示切换显示内存信息。
N – 排序【PID】以PID的大小的顺序排列表示进程列表
M – 排序【内存占用率】以大小的顺序排列进程列表
T – 排序【根据时间/累计时间进行】
i:忽略闲置和僵死进程。这是一个开关式命令。
S:切换到累计模式。
h – 显示帮助
q – 退出 top
W:将当前设置写入~/.toprc文件中。
b – 打开/关闭运行线程【R状态】的加亮效果
x – 打开/关闭运行线程【R状态】排序列的加亮效果
”shift + >”或”shift + < :★可以向右或左改变排序列
2.4.9 其他与cup相关的命令
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
# 查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
# 查看详细内存信息
cat /proc/meminfo
# 监控java线程数:
ps -eLf | grep java | wc -l
# 监控网络客户连接数:
netstat -n | grep tcp | grep 侦听端口 | wc -l
2.4.10 vmstat 命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写
用法:
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
vmstat -n 2 3
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
实战:
# 一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数表示采样的间隔时间;第二个参数表示采样多少次。重点看2个值procs 和 cpu
vmstat -n 2 5
结果:
[root@localhost ~]# vmstat -n 2 5
procs -----------memory---------- —swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
6 0 0 15037980 11448 1145436 0 0 261 654 38 214 12 5 78 5 0
1 0 0 15038684 11528 1144752 0 0 0 434 42829 102051 6 6 87 2 0
8 0 0 15081436 12936 1148448 0 0 2418 484 43447 106708 10 6 79 5 0
2 0 0 15272932 4884 967476 0 0 6947 1114 42706 103687 8 8 77 7 0
3 0 0 15224792 5124 1011796 0 0 22520 286 42382 100842 6 7 84 3 0
字段说明:
★procs (进程):
r: 运行和等待CPU时间片的进程数 ,原则上要不要超过cup 核数的2被。否则就是系统压力过大。
b:等待资源的进程数:比如等待磁盘I/O、网络I/O 等 ,这个数字如果大于cpu核树代表卡了。
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。【interrupt】
cs: 每秒上下文切换数。 【count/second】
★CPU(以百分比表示):
us: 用户进程执行时间(user time), us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 系统进程执行时间(system time),sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间,wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id: 空闲时间百分比,正常情况要大于40,相当于空闲40%以上。
st:来自于一个虚拟机偷取的CPU时间的百分比
服务器监控有用处的度量主要有:
r(运行队列)
bi(页导入)
us(用户CPU)
sy(系统CPU)
id(空闲)
如果 r 经常大于cup核树的2倍 ,us+sy>80(已占用的高于80%),表示cpu的负荷很重。
如果bi,bo 长期不等于0,表示内存不足
2.4.11 Linux下查看CPU核心数的命令:
cat /proc/cpuinfo|grep processor|wc -l
2.4.12 LInux下查看所有cpu核信息
# 2 表示没2s刷新一下
mpstat -P ALL 2
mpstat 与 vmstat的区别,vmstat看整体,mpstat 看个体
结果:
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 9.87 0.00 6.04 2.26 0.00 0.13 0.00 0.00 0.00 81.70
Average: 0 10.97 0.00 6.23 1.59 0.00 0.12 0.00 0.00 0.00 81.08
Average: 1 10.67 0.00 6.06 2.25 0.00 0.06 0.00 0.00 0.00 80.95
Average: 2 10.71 0.00 5.87 2.38 0.00 0.12 0.00 0.00 0.00 80.92
Average: 3 10.01 0.00 5.90 2.07 0.00 0.06 0.00 0.00 0.00 81.96
Average: 4 9.54 0.00 5.95 2.00 0.00 0.08 0.00 0.00 0.00 82.43
Average: 5 9.07 0.00 5.93 2.31 0.00 0.10 0.00 0.00 0.00 82.59
Average: 6 8.83 0.00 6.14 2.71 0.00 0.06 0.00 0.00 0.00 82.26
Average: 7 9.14 0.00 6.25 2.77 0.00 0.43 0.00 0.00 0.00 81.41

2.4.13 pidstat 详解
2.4.13.1 监控CPU (-u)
Linux下查看 每个进程使用cpu的分量分解信息
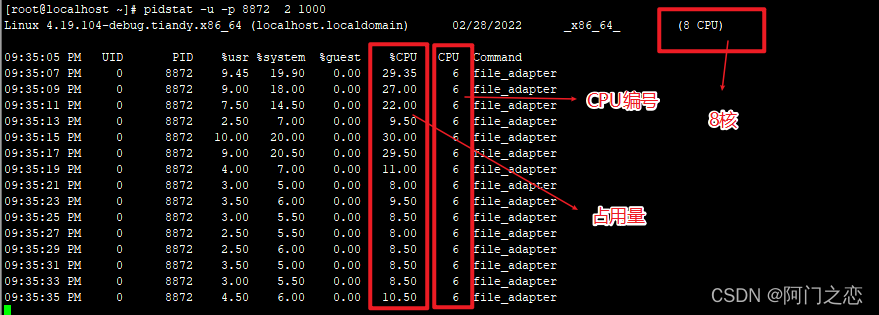
## 每隔2s输出进程id为8872的cpu信息,总共输出1000次。
pidstat -u -p 8872 2 1000
2.4.13.2 监控内存 (-r)
## 查看进程号位8872的进程的内存使用情况,没2s刷新一次,共1000次
pidstat -r -p 8872 2 1000
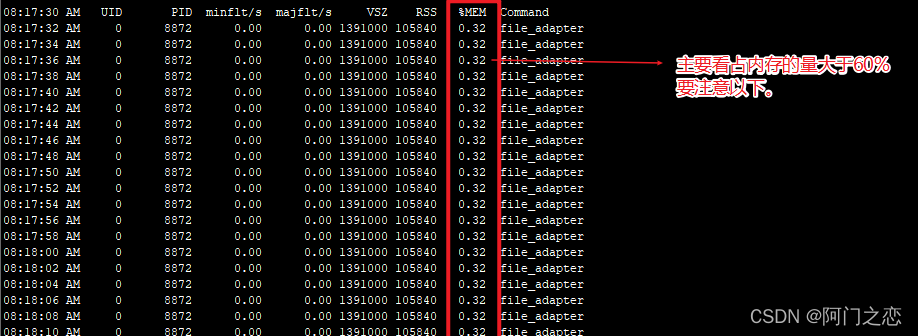
minflt/s: 每秒次缺页错误次数(minor page
faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数。
majflt/s: 每秒主缺页错误次数(major page
faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page
fault,一般在内存使用紧张时产生。
VSZ: 该进程使用的虚拟内存(以kB为单位)。
RSS: 该进程使用的物理内存(以kB为单位)。
%MEM: 该进程使用内存的百分比。
Command: 拉起进程对应的命令。
2.4.13.3 监控磁盘IO (-d)
## 查看进程号位8872的进程的磁盘io(不是网络io)使用情况,没2s刷新一次,共1000次
pidstat -d -p 8872 2 1000

kB_rd/s: 每秒进程从磁盘读取的数据量(以kB为单位)
kB_wr/s: 每秒进程向磁盘写的数据量(以kB为单位)
Command: 拉起进程对应的命令
2.5 查看网络情况 iftop
简单查看网络
ifstat -p
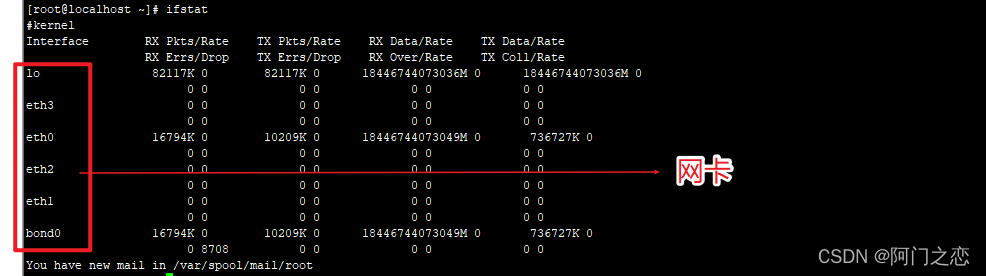
RX Pkts/Rate 数据包接收流量
RX Errs/Drop 数据包接收丢包
TX Pkts/Rate 数据包发送流量
TX Errs/Drop 数据包发送丢包
RX Data/Rate 数据接收流量
TX Coll/Rate 数据发送流量
2.5.1 安装iftop
官方网站:http://www.ex-parrot.com/~pdw/iftop/
下载与安装:
## 第一步:找个合适的位置下载
wget http://www.ex-parrot.com/pdw/iftop/download/iftop-0.17.tar.gz
## 第二步:解压
tar zxvf iftop-0.17.tar.gz
## 第三步:打开路径
cd iftop-0.17
## 第四步:运行配置
./configure
## 第五步:安装
make && make install
2.5.2 监听效果
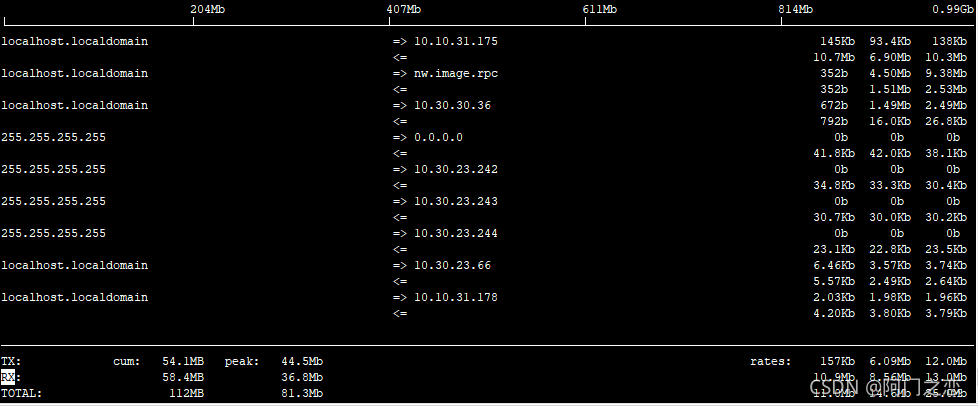
iftop
2.5.3 iftop参数说明
1》iftop 界面相关说明
界面上面显示的是类似刻度尺的刻度范围,为显示流量图形的长条作标尺用的。
中间的<= =>这两个左右箭头,表示的是流量的方向。
TX:发送流量
RX:接收流量
TOTAL:总流量
Cumm:运行iftop到目前时间的总流量
peak:流量峰值
rates:分别表示过去 2s 10s 40s 的平均流量
2》★iftop 命令的相关参数
最佳实战命令1: 显示ip,端口,最大刻度20M:
iftop -nPm 20M

最佳实战命令2: 显示特定网段的进出流量,并将流量刻度尺设置为最大100M:
iftop -F 106.11.79.0/24 -m 100M
最佳实战命令3: 不以实时监控界面的方式运行,监听eth0网卡,每隔5s后打印一次流量信息,打印两次输出:
iftop -i eth0 -n -t -s 5 -L 2
-i ★设定监测的网卡,如:# iftop -i eth1
-n ★使host信息默认直接都显示IP,如:# iftop -n
-P ★显示端口;
-m ★设置界面最上边的刻度的最大值,刻度分五个大段显示【指定为带有“K”、“M”或“G”后缀的数字。】,例:# iftop -m 100
-F ★显示特定网段的进出流量,如# iftop -F 10.10.1.0/24或# iftop -F 10.10.1.0/255.255.255.0
-B 以bytes为单位显示流量(默认是bits),如:# iftop -B
-h(display this message),帮助,显示参数信息
-p 以混杂模式运行,因此不直接通过指定接口的通信量也被计算在内
-b 使流量图形条默认就显示;
-f 滤波器代码,使用筛选代码选择要计数的数据包。只对IP数据包进行计数,因此指定的代码计算为(筛选代码)和IP;
-l 显示和统计发送到链路本地IPv6地址或来自链路本地IPv6地址的数据报。默认情况下,不显示该地址类别。
-G net6/mask6指定用于流量分析的IPv6网络。mask6的值可以作为前缀长度或数字地址字符串给出,用于更复杂的位掩码。
-c 配置文件指定备用配置文件。如果未指定,iftop将使用~/.IFTOPC(如果存在)。有关配置文件的说明
-t 文本输出模式
3》进入iftop画面后的一些操作命令(注意大小写)
按h ★切换是否显示帮助;
按P ★切换暂停/继续显示;
按n ★切换显示本机的IP或主机名;
按B ★切换计算2秒或10秒或40秒内的平均流量;
按T ★切换是否显示每个连接的总流量;
按l ★L打开屏幕过滤功能,输入要过滤的字符,比如ip,按回车后,屏幕就只显示这个IP相关的流量信息;
按s切换是否显示本机的host信息;
按d切换是否显示远端目标主机的host信息;
按t ★切换显示格式为2行/1行/只显示发送流量/只显示接收流量;
按N ★切换显示端口号或端口服务名称;
按S切换是否显示本机的端口信息;
按D切换是否显示远端目标主机的端口信息;
按p切换是否显示端口信息;
按b切换是否显示平均流量图形条;
按L切换显示画面上边的刻度;刻度不同,流量图形条会有变化;
按j或按k ★可以向上或向下滚动屏幕显示的连接记录;
按1或2或3可以根据右侧显示的三列流量数据进行排序;
按<根据左边的本机名或IP排序;
按>根据远端目标主机的主机名或IP排序;
按o切换是否固定只显示当前的连接;
按f可以编辑过滤代码,这是翻译过来的说法,我还没用过这个!
按!可以使用shell命令,这个没用过!没搞明白啥命令在这好用呢!
按q退出监控。
2.6 linux 性能监控 sar命令
https://blog.csdn.net/liyongbing1122/article/details/89517282
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)