操作系统MIT6.S081:Lab2->System calls
本系列文章为MIT6.S081的学习笔记,包含了参考手册、课程、实验三部分的内容,前面的系列文章链接如下操作系统MIT6.S081:[xv6参考手册第1章]->操作系统接口操作系统MIT6.S081:P1->Introduction and examples操作系统MIT6.S081:Lab1->Unix utilities操作系统MIT6.S081:[xv6参考手册第2章]->操作系统组织结构操
本系列文章为MIT6.S081的学习笔记,包含了参考手册、课程、实验三部分的内容,前面的系列文章链接如下
操作系统MIT6.S081:[xv6参考手册第1章]->操作系统接口
操作系统MIT6.S081:P1->Introduction and examples
操作系统MIT6.S081:Lab1->Unix utilities
操作系统MIT6.S081:[xv6参考手册第2章]->操作系统组织结构
操作系统MIT6.S081:P2->OS organization and system calls
前言
在上一个实验中,你利用系统调用编写了一些实用的程序。在本实验中,你将向xv6添加一些新的系统调用,这将帮助你了解系统调用的工作原理,并让你了解xv6内核的内部结构。你将在以后的实验中添加更多的系统调用。在开始编程之前,请阅读xv6参考手册的第2章、第4章的4.3和4.4节以及相关的源文件:
- 系统调用的用户域代码在
user/user.h和user/usys.pl中。 - 内核域代码在
kernel/syscall.h、kernel/syscall.c中。 - 与进程相关的代码在
kernel/proc.h、kernel/proc.c中。
开始实验之前,请切换到syscall分支:
一、System call tracing
1.1 实验描述
实验目的
----在本实验中,你将添加一个名为
trace的系统调用。在以后调试代码时,该系统调用可能对你有帮助。
----trace接受一个整型参数mask,指定要跟踪的系统调用。例如,为了跟踪fork系统调用,程序调用trace(1 << SYS_fork)。其中,SYS_fork是kernel/syscall.h中fork的系统调用号。
----如果向mask传递了一个系统调用的编号,则必须修改xv6的内核,使得每个系统调用即将返回时打印出一行内容。该行内容应包含进程id、系统调用的名称和返回值,你不需要打印系统调用参数。
----trace系统调用应该对调用它的进程以及由它派生的任何子进程开启跟踪,但不应影响其他进程。
测试案例
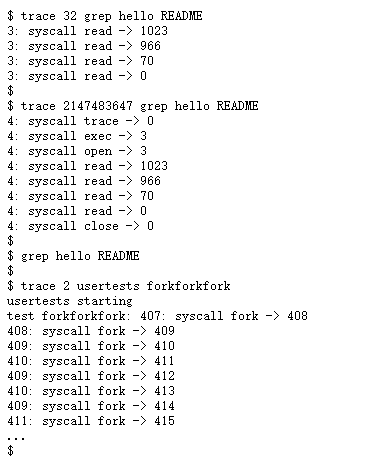
我们提供了一个用户域的
trace程序(user/trace.c)。当你完成整个实验后,您应该会看到如下输出:
实验提示
①在Makefile中将
$U/_trace添加到UPROGS
②运行make qemu,你会看到编译器无法编译user/trace.c,因为系统调用的用户空间桩代码还不存在:
----将系统调用的声明添加到user/user.h,将桩代码添加到user/usys.pl,将系统调用号添加到kernel/syscall.h。
----Makefile调用perl脚本user/usys.pl,它生产user/usys.S,即实际的系统调用桩代码,它使用RISC-Vecall指令切换到内核。
----修复编译问题后,运行trace 32 grep hello README。它会失败,因为你还没有在内核中实现系统调用。
③在proc结构体中添加一个新成员mask(参见kernel/proc.h)。初始时mask为0,表示不跟踪任何系统调用。而trace()系统调用可通过修改当前进程的mask来实现对系统调用的跟踪。
④在kernel/sysproc.c中添加一个sys_trace()函数。从用户空间获取系统调用参数的函数定义在kernel/syscall.c中,你可以在kernel/sysproc.c中看到它们的使用示例。
⑤修改fork()(参见kernel/proc.c)以实现将将父进程的mask复制给子进程。
⑥修改kernel/syscall.c中的syscall()函数以打印跟踪每个系统调用的输出结果。你需要添加一个按系统调用号索引系统调用名称的数组。
1.2 实验思路
参照实验提示的步骤一步一步来完成实验:
1、 根据实验提示①,首先将$U/_trace添加到Makefile中的UPROGS里
UPROGS=\
...
$U/_trace\
2、 根据实验提示②,实现桩代码。
----首先将trace的声明添加到user.h中去。由于用户态的trace代码已经写好了,我们可以看到trace接收一个int类型的整数,返回值和0做比较,所以返回值应该也是一个int类型的整数。
#include "kernel/param.h"
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
int i;
char *nargv[MAXARG];
if(argc < 3 || (argv[1][0] < '0' || argv[1][0] > '9')){
fprintf(2, "Usage: %s mask command\n", argv[0]);
exit(1);
}
if (trace(atoi(argv[1])) < 0) {
fprintf(2, "%s: trace failed\n", argv[0]);
exit(1);
}
for(i = 2; i < argc && i < MAXARG; i++){
nargv[i-2] = argv[i];
}
exec(nargv[0], nargv);
exit(0);
}
于是把trace的声明加入到user.h中
// system calls
...
int trace(int);
----Makefile会调用perl脚本(user/usys.pl),生成一个user/usys.S。所以接下来在user/usys.pl中添加一行生成实际桩代码(user/usys.S)的脚本:entry("trace");
entry("trace");
3、 根据实验提示②,在kernel/syscall.h中添加trace系统调用序号的宏定义SYS_trac。
//System call numbers
...
#define SYS_trace 22
4、 根据实验提示③,去kernel/proc.h中修改proc结构体(记录当前进程信息)。给proc结构体添加一个成员变量mask,表示当前进程需要跟踪的系统调用。
struct proc
{
...
int mask;
}
5、 在根据实验提示④的提示去阅读syscall.c和sysproc.c的代码之前,我们先看一下桩代码(user/usys.S)的内容。这个文件就像一个switch语句一样,当你使用一个系统调用的时候(比如fork),操作系统会查询user/usys.S中对应的标签来执行相应的代码。在这些代码中,将SYS_fork这个名称放入a7,然后使用ecall,请求提升硬件权限。此时,进入内核,内核会执行syscall()。
...
.global fork
fork:
li a7, SYS_fork
ecall
ret
...
6、 根据实验提示④去syscall.c中查看syscall的具体实现,如下所示:
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
if((1 << num) & p->mask) {
printf("%d: syscall %s -> %d\n", p->pid, syscall_names[num], p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
其中,num = p->trapframe->a7;从寄存器a7中读取系统调用号。接下来p->trapframe->a0 = syscalls[num]();通过调用syscalls[num]();函数把返回值保存在了a0寄存器中。syscalls[num]()函数调用了系统调用命令,所以我们把新增的trace系统调用添加到函数指针数组*syscalls[]上,并给内核态的系统调用trace加上声明。
...
extern uint64 sys_trace(void);
static uint64 (*syscalls[])(void) = {
...
[SYS_trace] sys_trace,
};
7、 根据实验提示④,再去看看kernel/sysproc.c,我们这里给出了其中一个函数的示例,正是lab1中sleep系统调用代码。
uint64
sys_sleep(void)
{
int n;
uint ticks0;
if(argint(0, &n) < 0)
return -1;
acquire(&tickslock);
ticks0 = ticks;
while(ticks - ticks0 < n){
if(myproc()->killed){
release(&tickslock);
return -1;
}
sleep(&ticks, &tickslock);
}
release(&tickslock);
return 0;
}
类似的,我们在这里也给出sys_trace函数的具体实现。trace系统调用只是给mask设置相应的值。
uint64
sys_trace(void)
{
int mask;
// 取 a0 寄存器中的值返回给 mask
if(argint(0, &mask) < 0)
return -1;
// 把 mask 传给现有进程的 mask
myproc()->mask = mask;
return 0;
}
8、 根据实验提示⑤,在kernel/proc.c中fork函数调用时,添加子进程复制父进程的mask的代码。
int
fork(void)
{
...
np->mask = p->mask;
...
}
9、 根据实验提示⑥,修改syscall函数打印跟踪每个系统调用的输出结果。
----到目前为止,我们只是设置了进程的mask,其他什么也没干。因此,在进行每一个系统调用时,我们需要检查该进程的mask。如果指示需要跟踪该系统调用,就输出信息。
----我们知道,用户在申请执行系统调用(执行ecall指令)前,把可能的参数依次放在a0~a5寄存器中,把系统调用号放在a7寄存器中。
----执行ecall后trap进内核,开始执行kernel/syscall.c中的syscall(void)函数中的代码。它从a7中获取系统调用号,接着去syscalls函数指针数组中索引对应的系统调用函数指针。若可以索引到,就执行这个系统调用函数,否则就打印我们之前看到的未知的系统调用错误提示信息。
----执行后,系统调用的返回值存储在a0寄存器中。
----由于需要打印函数调用的名称,而proc结构体里的name是整个进程的名字,所以我们不能用p->name,而要自己定义一个数组。由于系统调用号从1开始,所以我们将数组中的第0个元素置为空。
static char *syscall_names[] = {
"", "fork", "exit", "wait", "pipe",
"read", "kill", "exec", "fstat", "chdir",
"dup", "getpid", "sbrk", "sleep", "uptime",
"open", "write", "mknod", "unlink", "link",
"mkdir", "close", "trace", "sysinfo",};
----于是我们将进程的mask和1<<系统调用编号按位判断的,如果相等就打印:①进程序号(通过p->pid获取)、②函数名称(从我们定义的函数名数组syscall_names[num]中获取)、③系统调用的返回值(p->trapframe->a0)
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
//Start 从a7读取系统调用的编号,将1<<num与进程的mask比较,相等则打印
if((1 << num) & p->mask) {
printf("%d: syscall %s -> %d\n", p->pid, syscall_names[num], p->trapframe->a0);
}
//End
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
1.3 实验结果
测试
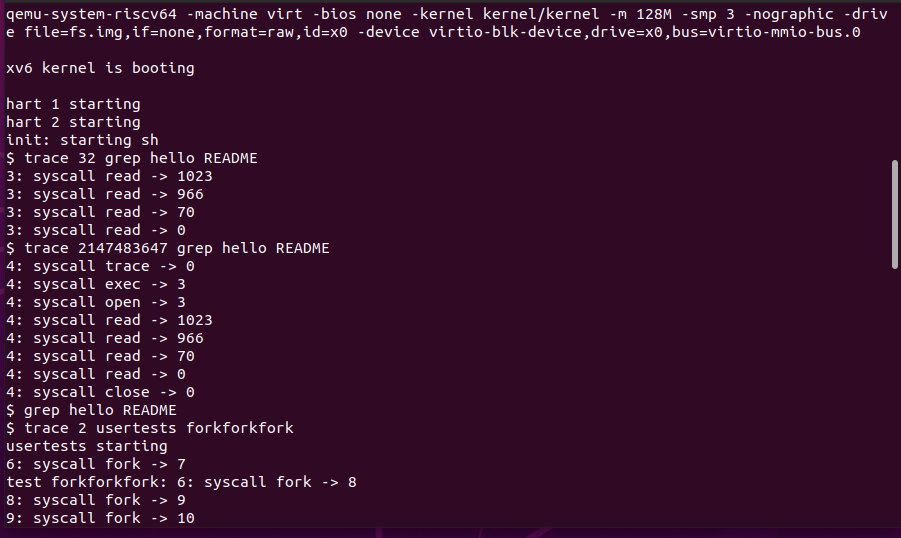
①首先启动xv6
②输入测试命令:
----trace 32 grep hello README
----trace 2147483647 grep hello README
----grep hello README
----trace 2 usertests forkforkfork
结果如下:
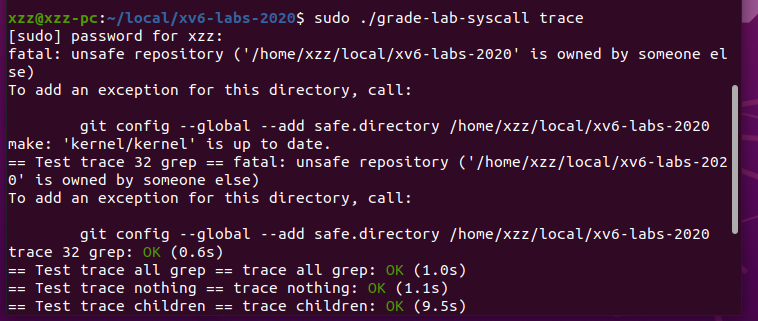
执行./grade-lab-syscall trace,结果如下:
二、Sysinfo
2.1 实验描述
实验目的
在这个实验中,你将添加一个
sysinfo系统调用,用来收集当前系统的相关信息。该系统调用接收1个参数:指向struct sysinfo的指针(参见kernel/sysinfo.h)。内核应填写struct sysinfo的相关字段:freemem字段应设置为空闲内存的字节数,nproc字段应设置为state不是UNUSED的进程数。我们提供了一个测试程序sysinfotest,如果它打印“sysinfotest:OK”,你就通过了这个任务。
实验提示
①将
$U/_sysinfotest添加到Makefile中的UPROGS。
②运行make qemu,user/sysinfotest.c将无法编译。需要根据上个实验的操作,添加sysinfo系统调用的相关信息。要在user/user.h中声明sysinfo()的原型,你需要预先声明struct sysinfo的存在:
----struct sysinfo;
----int sysinfo(结构 sysinfo *);
修复编译问题后,运行sysinfotest。它会失败,因为你还没有在内核中实现系统调用。
③sysinfo需要将struct sysinfo复制回用户空间。有关如何使用copyout()执行此操作的示例,请参见sys_fstat()(kernel/sysfile.c)和filestat()(kernel/file.c)。
④要收集可用内存量,请在kernel/kalloc.c中添加一个函数。
⑤要收集进程数,请在kernel/proc.c中添加一个函数。
2.2 实验思路
根据上个实验的思路,先执行以下操作:
1、 修改Makefile
UPROGS=\
...
$U/_sysinfotest\
2、 在user/user.h中添加sysinfo结构体以及sysinfo函数的声明:
struct sysinfo;
int sysinfo(struct sysinfo*);
3、 在user/usys.pl中添加sysinfo的用户态接口
entry("sysinfo");
4、 将sysinfo系统调用序号定义在kernel/syscall.h中。
#define SYS_sysinfo 23
5、 在kernel/syscall.c中新增sys_sysinfo函数的定义、在函数指针数组中新增sys_info的函数指针、在函数名称数组中新增sys_sysinfo的函数调用名称
extern uint64 sys_sysinfo(void);
static uint64 (*syscalls[])(void) = {
...
[SYS_sysinfo] sys_sysinfo,
}
static char *syscall_names[] = {
"", "fork", "exit", "wait", "pipe",
"read", "kill", "exec", "fstat", "chdir",
"dup", "getpid", "sbrk", "sleep", "uptime",
"open", "write", "mknod", "unlink", "link",
"mkdir", "close", "trace", "sysinfo"
};
6、 要实现收集可用内存量,根据实验提示④,先去看看kernel/kalloc.c。
// Physical memory allocator, for user processes,
// kernel stacks, page-table pages,
// and pipe buffers. Allocates whole 4096-byte pages.
...
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
...
----kalloc.c是xv6的物理内存分配器。物理内存分页管理,每页4096字节。
----系统维护了一个kmem结构体,kfree使用前插法来不断地将内存的空闲页插入kmem中的freelist链表。
----具体来讲:kfree函数中把从end(内核后的第一个地址)到PHYSTOP(KERNBASE + 128*1024*1024)之间的物理空间以PGSIZE为单位全部初始化为1,然后每次初始化一个PGSIZE就把这个页挂在了kmem.freelist上,所以kmem.freelist永远指向最后一个可用页。
----那我们只要顺着这个链表往前走,直到NULL为止。然后统计数量,然后乘以每一个内存页的大小即可。
因此,在kernel/kalloc.c中添加free_mem函数统计空余内存量,整体代码如下:
// Return the number of bytes of free memory
uint64
free_mem(void)
{
struct run *r;
// counting the number of free page
uint64 num = 0;
// add lock
acquire(&kmem.lock);
// r points to freelist
r = kmem.freelist;
// while r not null
while (r)
{
// the num add one
num++;
// r points to the next
r = r->next;
}
// release lock
release(&kmem.lock);
// page multiplicated 4096-byte page
return num * PGSIZE;
}
7、要实现收集进程数,根据实验提示⑤先去看看kernel/proc.c。其中有一个结构体数组,每一个元素都是一个进程的相关信息。
struct proc proc[NPROC];
我们再去kernel/proc.h中看proc结构体的定义,可以看出枚举量state就保存了进程的状态。
...
enum procstate { UNUSED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
int mask;
};
...
所以我们可以直接遍历所有进程,获取其状态判断当前进程的状态是不是为UNUSED并统计数目就行了。我们在kernel/proc.c中新增函数nproc如下,通过该函数以获取可用进程数目:
// Return the number of processes whose state is not UNUSED
uint64
nproc(void)
{
struct proc *p;
// counting the number of processes
uint64 num = 0;
// traverse all processes
for (p = proc; p < &proc[NPROC]; p++)
{
// add lock
acquire(&p->lock);
// if the processes's state is not UNUSED
if (p->state != UNUSED)
{
// the num add one
num++;
}
// release lock
release(&p->lock);
}
return num;
}
8、 在kernel/defs.h中添加上述两个新增函数的声明:
// kalloc.c
...
uint64 free_mem(void);
// proc.c
...
uint64 nproc(void);
9、 开始写sys_sysinfo(),需要复制一个struct sysinfo返回用户空间。struct sysinfo的定义在kernel/sysinfo.h中。
struct sysinfo {
uint64 freemem; // amount of free memory (bytes)
uint64 nproc; // number of process
};
根据实验提示③,需要使用copyout()执行此操作,先参考sys_fstat()(kernel/sysfile.c)
uint64
sys_fstat(void)
{
struct file *f;
uint64 st; // user pointer to struct stat
if(argfd(0, 0, &f) < 0 || argaddr(1, &st) < 0)
return -1;
return filestat(f, st);
}
这里可以看到调用了filestat()函数,该函数在kernel/file.c中,如下:
// Get metadata about file f.
// addr is a user virtual address, pointing to a struct stat.
int
filestat(struct file *f, uint64 addr)
{
struct proc *p = myproc();
struct stat st;
if(f->type == FD_INODE || f->type == FD_DEVICE){
ilock(f->ip);
stati(f->ip, &st);
iunlock(f->ip);
if(copyout(p->pagetable, addr, (char *)&st, sizeof(st)) < 0)
return -1;
return 0;
}
return -1;
}
我们来查看一下 copyout() 函数的定义(kernel/vm.c)
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
copyout函数把内核地址src开始的len字节大小的数据逐字节地拷贝到用户进程pagetable的虚地址dstva处。所以sys_sysinfo函数实现里先用argaddr函数读进来我们要保存在用户态的数据sysinfo的指针地址,然后再把从内核里得到的sysinfo开始的内容以sizeof(info)大小的的数据复制到这个指针上。根据上面的例子,我们在kernel/sysproc.c文件中添加sys_sysinfo函数的具体实现如下:
// add header
#include "sysinfo.h"
uint64
sys_sysinfo(void)
{
// addr is a user virtual address, pointing to a struct sysinfo
uint64 addr;
struct sysinfo info;
struct proc *p = myproc();
if (argaddr(0, &addr) < 0)
return -1;
// get the number of bytes of free memory
info.freemem = free_mem();
// get the number of processes whose state is not UNUSED
info.nproc = nproc();
if (copyout(p->pagetable, addr, (char *)&info, sizeof(info)) < 0)
return -1;
return 0;
}
2.3 实验结果
测试结果
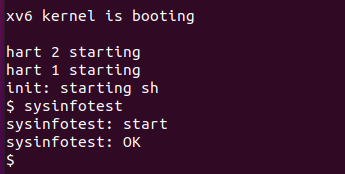
启动xv6
执行sysinfotest,结果如下:
执行./grade-lab-syscall sysinfo,结果如下:
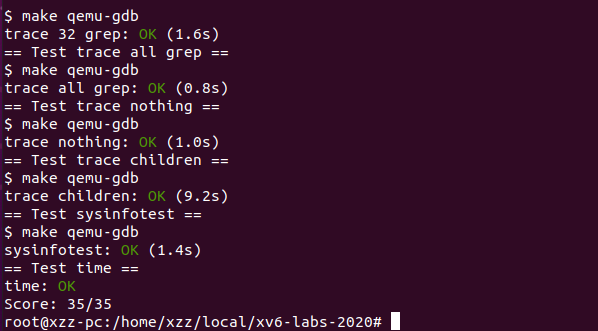
执行make grade,两个实验均正确。


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)