Centos8安装 Hadoop3 详细操作(含图文)
Centos中Hadoop安装详细过程(含图文)一、创建hadoop用户二、安装SSH、配置SSH无密码登录三、安装jdk环境四、安装 Hadoop 3五、配置hadoop环境变量六、配置Hadoop伪分布式配置对 Hadoop 的几个配置文件进行配置3. 修改配置文件 core-site.xml修改配置文件 hdfs-site.xml:vim hadoop-env.sh配置成你自己的jdk安装路
Centos中Hadoop安装详细过程(含图文)
Hadoop介绍:
Hadoop的核心由3个部分组成:
-
HDFS: Hadoop Distributed File System,分布式文件系统,hdfs还可以再细分为NameNode、SecondaryNameNode、DataNode。
-
YARN: Yet Another Resource Negotiator,资源管理调度系统
-
Mapreduce:分布式运算框架
下面介绍安装 Hadoop
虚拟机: VMware
环境: Linux 系统 centos8
hadoop: hadoop-3.3.0
一、创建hadoop用户
VM上安装centos7的主机,设置初始内存为2G,硬盘为50G,安装成功后新建用户hadoop,设置hadoop的密码并授予hadoop用户sudo权限(不过后面主要还是用root操作)
如果你安装 CentOS 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
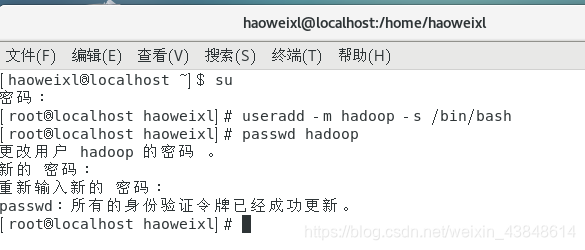
首先点击左上角的 “应用程序” -> “系统工具” -> “终端”,首先在终端中输入 su ,按回车,输入 root 密码以 root 用户登录,接着执行命令创建新用户
su # 上述提到的以 root 用户登录
useradd -m hadoop -s /bin/bash # 创建新用户hadoop,并使用 /bin/bash 作为shell。
passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:
visudo
如下图,找到 root ALL=(ALL) ALL 这行(应该在第98行,可以先按一下键盘上的 ESC 键,然后输入 :98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行 ),然后按i,进入插入模式,在这行下面增加一行内容:
hadoop ALL=(ALL) ALL
如下图所示:

添加上一行内容后,先按一下键盘上的 ESC 键,然后输入 :wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
最后注销当前用户(点击屏幕右上角的用户名,选择退出->注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。(如果已经是 hadoop 用户,且在终端中使用 su 登录了 root 用户,那么需要执行 exit 退出 root 用户状态)
二、安装SSH、配置SSH无密码登录
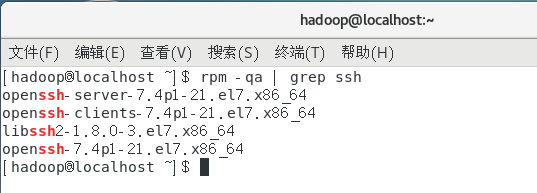
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),一般情况下,CentOS 默认已安装了 SSH client、SSH server,打开终端执行如下命令进行检验:
rpm -qa | grep ssh
如果返回的结果如下图所示,包含了 SSH client 跟 SSH server,则不需要再安装。
若需要安装,则可以通过 yum 进行安装(安装过程中会让你输入 [y/N],输入 y 即可):
sudo yum install openssh-clients
sudo yum install openssh-server
接着执行如下命令测试一下 SSH 是否可用:
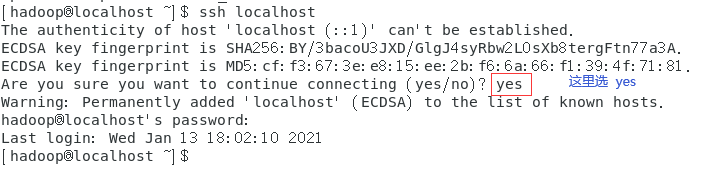
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
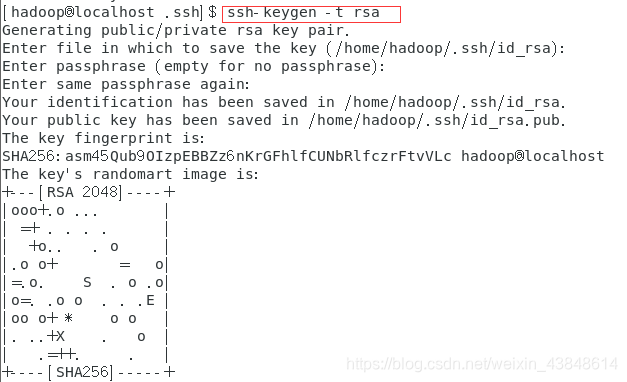
首先输入 exit 退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限


~的含义
在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表“/home/hadoop/”。
此外,命令中的 # 后面的文字是注释。
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。

三、安装jdk环境
因为 Hadoop 是以 java 开发的,所以必须先安装 java 环境
linux系统版本的java环境安装,参考下面博客链接:
https://blog.csdn.net/weixin_43848614/article/details/108971979
四、安装 Hadoop 3
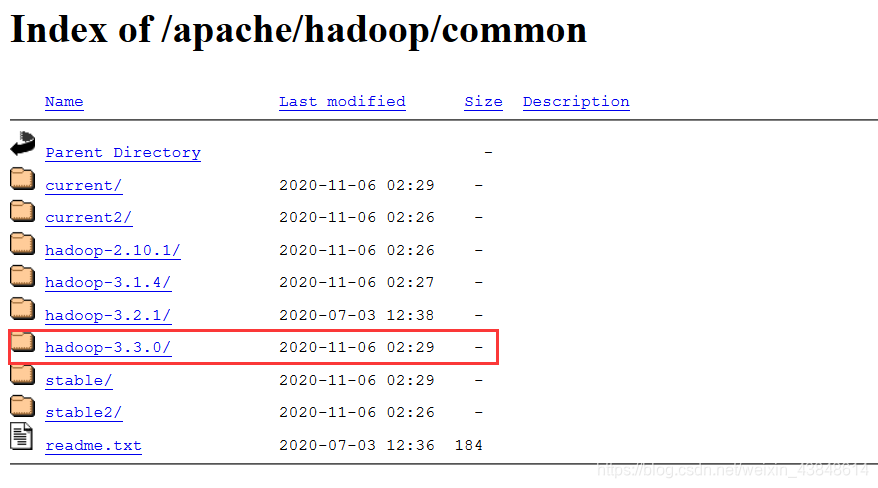
Hadoop 3 可以通过下面两个链接下载:
https://mirrors.cnnic.cn/apache/hadoop/common/
http://mirror.bit.edu.cn/apache/hadoop/common/
本教程选择的是 3.3.0 版本,下载时会有多个版本
hadoop-3.x.y.tar.gz 这是编译好的文件
hadoop-3.x.y.src.tar.gz 包含 的是 Hadoop 源代码,需要进行编译才可使用。

将下载好的安装包解压:
tar -zxvf hadoop-3.3.0.tar.gz
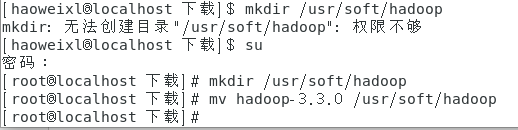
在 usr 中创建合适的文件夹存放解压后的文件,注意新建的文件夹需要后期配置环境路径使用。(本教程按本人所习惯的存放在 soft 文件夹中)
新建文件夹命令:(mkdir后面一定要加空格)
mkdir /usr/soft/hadoop
将解压后的文件移动到相应文件夹
mv jdk1.8.0_271 /usr/soft/hadoop

五、配置hadoop环境变量
- 安装完成之后要进行环境配置,这里需要编辑编辑/etc/profile文件
编辑命令:
vim /etc/profile
在执行完上方命令之后点击i键位让文件可以修改,进行文件编写

2. 在文件末尾添加如下配置:
export HADOOP_HOME=/usr/soft/hadoop/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$PATH
编写完成以后,我们要保存退出,那么我们就要使用底部模式,这时候使用ESC键退出插入模式回到命令模式。
(1)按一下Esc
(2)输入一个冒号: 输入冒号需要是使用 “shirt” +" : "
(3)输入:wq 就会自动关闭文件并保存文件。

注意: 这里可能会由于设置全局变量导致 后边运行datanode出错
- 文件生效
对于/etc/profile编写完成之后是不够的,还需要最后一个步骤,就是让刚刚我们修改的文件变成有效起来,所以我们再输入一个命令,让修改生效。
生效命令:
source /etc/profile
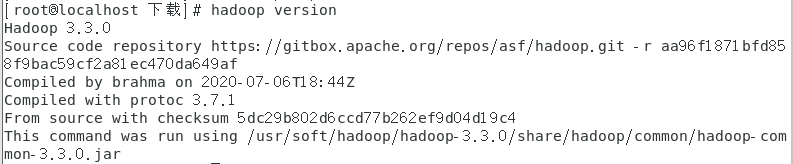
- 验证是否安装成功
最后我们来进行一下测试,看看我们的环境变量是否配置成功
测试命令:
hadoop version
六、Hadoop伪分布式配置
Hadoop 环境变量设置
在设置 Hadoop 伪分布式配置前,我们还需要设置 HADOOP 环境变量,执行如下命令在 ~/.bashrc 中设置:
vim ~/.bashrc
在文件最后面增加如下内容:
# Hadoop Environment Variables
export HADOOP_HOME=/usr/soft/hadoop/
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin

保存后,不要忘记执行如下命令使配置生效:
source ~/.bashrc

这些变量在启动 Hadoop 进程时需要用到,不设置的话可能会报错(这些变量也可以通过修改 ./etc/hadoop/hadoop-env.sh 实现)。
Hadoop 配置文件的修改
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
- 打开hadoop配置文件:
cd /usr/soft/hadoop/hadoop-3.3.0/etc/hadoop/
- 查看文件信息:
ll
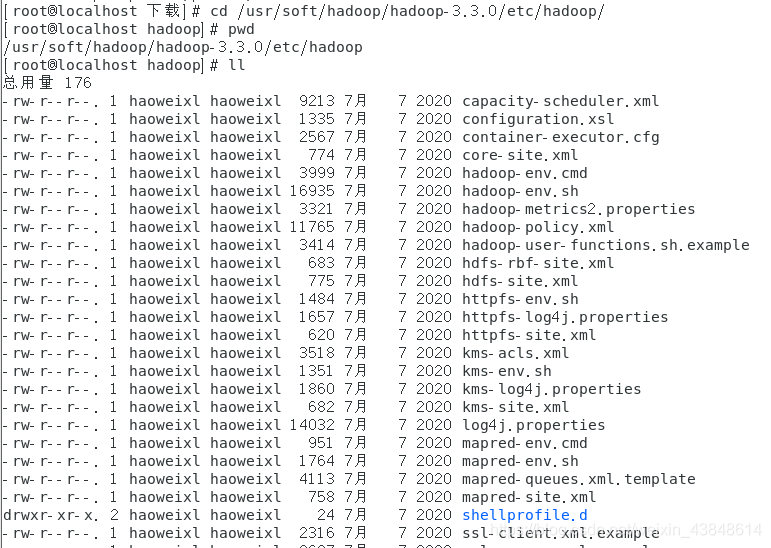
其中最好修改其中的五个配置文件
(1)修改配置文件 core-site.xml
如上图查看配置文件可知, core-site.xml 文件读写权限较低,修改配置文件之前需要修改文件权限
为了方便不细分权限,设置为允许所有操作
cd /usr/soft/hadoop/hadoop-3.3.0/etc/hadoop/
chmod 777 core-site.xml
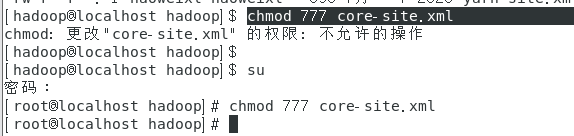
Vim模式修改配置文件
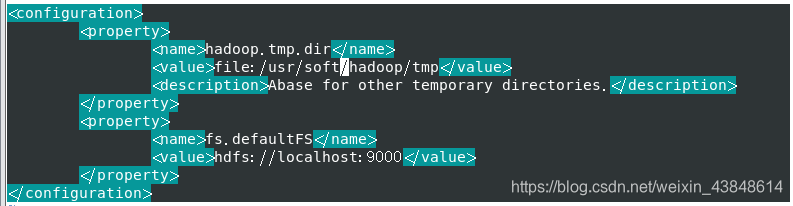
vim core-site.xml

添加如下配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/soft/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
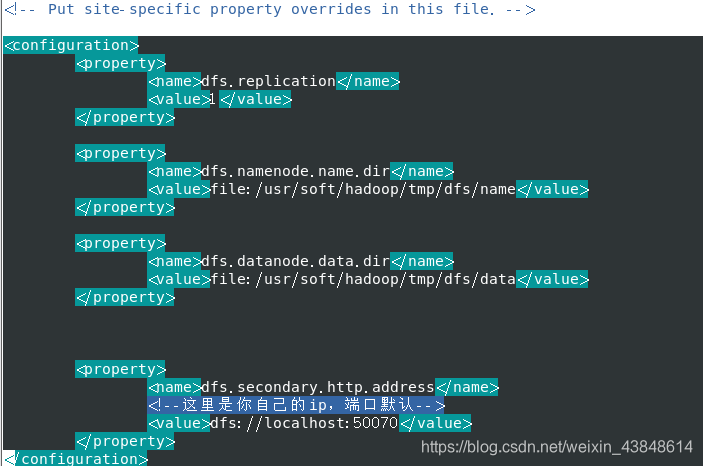
(2)修改配置文件 hdfs-site.xml:
同样先修改文件权限:
chmod 777 hdfs-site.xml
vim模式修改配置文件
vim hdfs-site.xml
添加如下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/soft/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/soft/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<!--这里是你自己的ip,端口默认-->
<value>dfs://localhost:50070</value>
</property>
</configuration>
(3)修改配置文件 hadoop-env.sh
vim hadoop-env.sh 配置成你自己的jdk安装路径
export JAVA_HOME=/usr/soft/java/jdk1.8.0_271

(4)配置 mapred-site.xml
mapred-site.xml 指定MapReduce程序应该放在哪个资源调度集群上运行。若不指定为yarn,那么MapReduce程序就只会在本地运行而非在整个集群中运行。
同样先修改文件权限:
chmod 777 mapred-site.xml
vim模式修改配置文件
vim mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
</configuration>
(5)配置yarn-site.xml
同样先修改文件权限:
chmod 777 yarn-site.xml
vim模式修改配置文件
vim yarn-site.xml
添加如下配置:
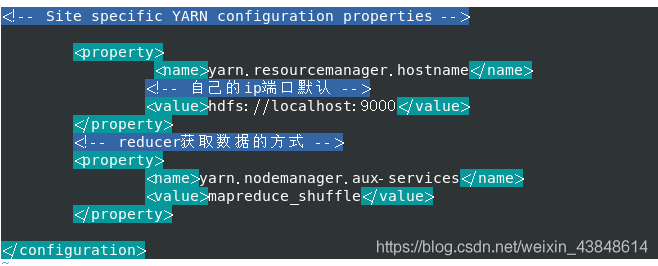
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 自己的ip端口默认 -->
<value>hdfs://localhost:9000</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
七、启动 Hadoop
cd /usr/soft/hadoop/hadoop-3.3.0/sbin/
初始化化hadoop文件格式,输入命令:
hadoop namenode -format
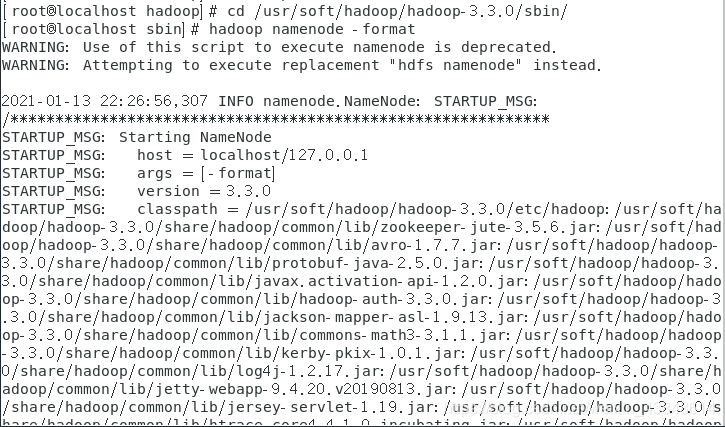

成功标志:

可以使用下面命令启动所有进程:
./start-all.sh
也可以使用“ start-dfs.sh ”开启 NaneNode 和 DataNode 守护进程:
start-dfs.sh
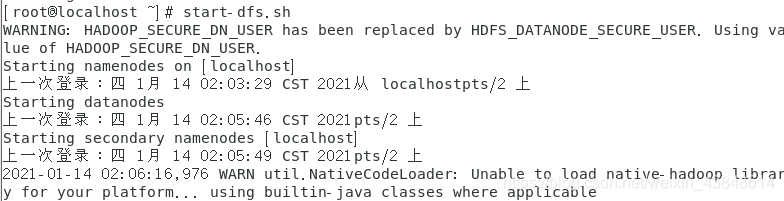
然后输入命令 ’ jps ’ 查看已成功启动的进程
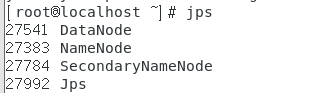
若成功启动则会列出如下进程: “NameNode”、”DataNode”和SecondaryNameNode(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
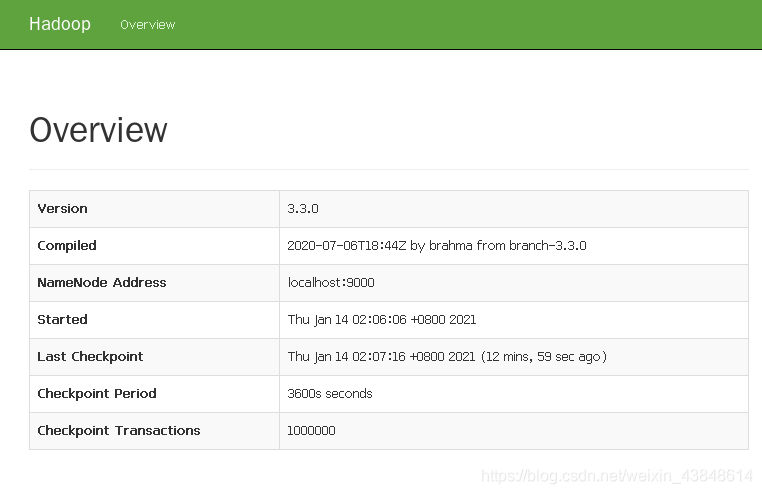
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
参考博客:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)