pytest接口自动化框架搭建
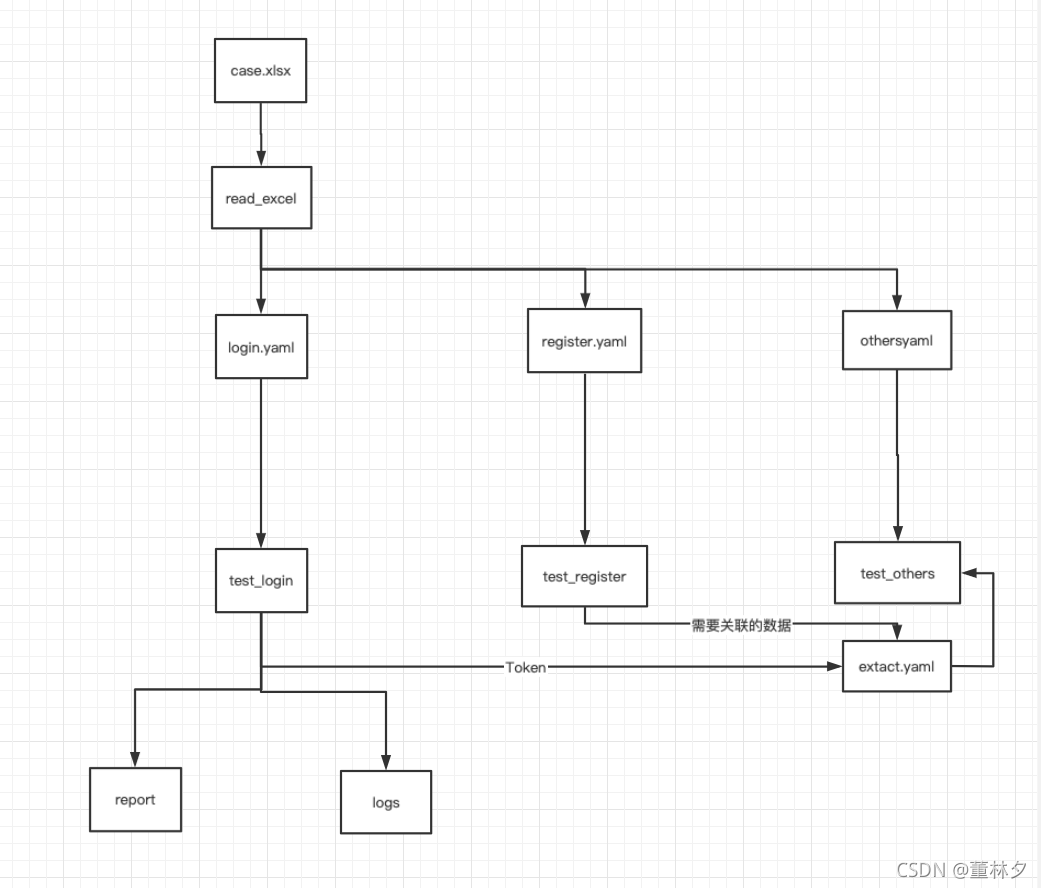
目标:最终完成一个用jenkins集成或用django,达到一个自由灵活可复用的接口自动化测试框架一、设计思路-整体框架:接口自动化测试之框架搭建步骤——思路整理1.先搭建框架主干config:存放配置文件,如ini文件,可以用来保存配置各个环境的地址output:用来存放测试报告、日志等common:公共的方法,如,封装yaml操作相关的方法、excel相关操作方法等testcase:运行用例的
目标:最终完成一个用jenkins集成或用django,达到一个自由灵活可复用的接口自动化测试框架
github地址(可直接clone到本地):git clone https://github.com/529851983/dongshuai.git
一、设计思路-整体框架:
接口自动化测试之框架搭建步骤——思路整理
1.先搭建框架主干
config:存放配置文件,如ini文件,可以用来保存配置各个环境的地址
output:用来存放测试报告、日志等
common:公共的方法,如,封装yaml操作相关的方法、excel相关操作方法等
testcase:运行用例的脚本
data:存放测试用例excel表、和转化为yaml格式的测试用例
2.选用合适的单元测试框架(这个用pytest做吧),··················
3.补充完善各个模块
4.写测试用例,用实际的接口进行测试
二、具体框架搭建
1.公共方法—common
1.1.yaml_util.py
- 封装操作yaml的方法,包括读、写、清空等操作
知识点:
- yaml反序列化:ymal.load()
- yaml序列化:yaml.dump()
- 生成后的yaml中文乱码解决:allow_unicode=True
- 生成后的yaml顺序不是原来的解决:sort_keys=False
@exception
def read_yaml(yaml_file):
"""读取yaml"""
with open(yaml_file, 'r', encoding='utf-8') as f:
value = yaml.load(f, Loader=yaml.FullLoader)
print(value)
return value
@exception
def write_yaml(data, yaml_file):
"""写yaml"""
with open(yaml_file, 'w') as f:
yaml.dump(data=data, stream=f, allow_unicode=True, sort_keys=False, default_flow_style=False)
@exception
def truncate_yaml(yaml_file):
"""清空yaml"""
with open(yaml_file, 'w') as f:
f.truncate()
@exception
def handler():
"""根据读取excel数据,生成yaml的测试用例数据"""
file = "%s/data/case_excel/接口测试框架实践用例.xlsx" % base_dir
value = ExcelUtil(file).read_excel()
sheet_names = ExcelUtil(file).wb.sheetnames
n = 0
for sheet in sheet_names:
data = value[n]
file = '%s/data/case_yaml/%s.yaml' % (base_dir, sheet)
write_yaml(data=data, yaml_file=file)
n += 1
1.2.excel_util.py
- 封装操作excel的方法,主要作用2个:
- 1、用于数据处理,读取excel中用例后返回规定的字典,便于生成yaml
- 2、将运行结果数据存入excel中对应列
from openpyxl import Workbook,load_workbook
from common.exception_utils import exception_utils
@exception_utils
class ExcelUtil(object):
def __init__(self, excel_path):
self.wb = load_workbook(excel_path)
self.template = """{"id":0,"url":"","case_name":"","header":"","method":"","body":"",
"expect":"","actual":"","valiadate":""},""" # 这个是写入用例的模板
@exception_utils
def read_excel(self):
"""读取excel,处理数据,并返回一个格式处理后的字典"""
value = []
for sheetname in self.wb.sheetnames:
ws = self.wb[sheetname]
cases_num = len(list(ws.values)) - 1 # 一个sheet中用例的数量
case_list = list(ws.values)
case_list.pop(0) # 去掉表头
cases_template = self.template * cases_num
cases_template_list = eval("[" + cases_template[:-1] + "]") # 与用例相同长度的模板
for i in range(len(case_list)): # i:第i个用例
# 每个用例中字段是9个,因此这样写
cases_template_list[i]['id'] = case_list[i][0]
cases_template_list[i]['url'] = case_list[i][1]
cases_template_list[i]['case_name'] = case_list[i][2]
cases_template_list[i]['header'] = case_list[i][3]
cases_template_list[i]['method'] = case_list[i][4]
cases_template_list[i]['body'] = case_list[i][5]
cases_template_list[i]['expect'] = case_list[i][6]
cases_template_list[i]['actual'] = case_list[i][7]
cases_template_list[i]['valiadate'] = case_list[i][8]
value.append({"cases": cases_template_list})
return value
@exception_utils
def write_excel(self):
"""运行结果写入excel"""
l_reponse, l_ispass = read_txt_handel()
print(l_reponse.__len__())
print(l_ispass.__len__())
i = 0
j = 0
for sheetname in self.wb.sheetnames:
ws = self.wb[sheetname]
# 实际结果列
for row in ws.iter_rows(min_row=2, max_row=ws.max_row, max_col=8, min_col=8):
for cell in row:
cell.value = l_reponse[i]
# print("resp:%s" % i, cell.value)
i += 1
# 是否通过列
for row in ws.iter_rows(min_row=2, max_row=ws.max_row, max_col=9, min_col=9):
for cell in row:
cell.value = l_ispass[j]
# print("ispass%s:" % j, cell.value)
j += 1
save_path = "%s/output/run_result_excel/运行结果_%s.xlsx" % (self.base_dir, time.strftime("%Y%m%d_%H:%M:%S"))
self.wb.save(save_path)
1.4、text_ util.py
- 封装读、写、清空txt文件的方法
- 封装处理用例运行结果数据,返回规定格式的数据的方法
from pathlib import Path
base_dir = Path(__file__).parent.parent
def read_txt(text_file):
"""读取txt文件"""
with open(text_file, 'r', encoding='utf-8') as f:
return f.read()
def write_txt(text_file, data):
"""写入txt文件"""
with open(text_file, 'a') as f:
f.write(data)
def truncate_txt(text_file):
"""清空txt文件"""
with open(text_file, 'w') as f:
f.truncate()
def read_txt_handel(text_file='%s/data/run_result.txt' % base_dir):
"""将保存运行结果的txt数据,处理成想要的格式"""
value = read_txt(text_file=text_file)
l_reponse = []
l_ispass = []
for i in value[0:-1].split("|"):
l_reponse.append(i.split('__')[0])
l_ispass.append(i.split('__')[1])
# print(l_reponse)
# print(l_ispass)
return l_reponse, l_ispass
if __name__ == '__main__':
read_txt_handel()
1.5、exception_util.py
封装处理异常的装饰器
import traceback
from functools import wraps
def exception_utils(func):
"""处理异常的装饰器"""
@wraps(func)
def wraped(*args, **kwargs):
try:
return func(*args, **kwargs)
except Exception as e:
print('出现异常,error is %s\n%s' % (e, traceback.extract_stack()))
return wraped
1.6、email_util.py
封装发送邮件的方法
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
from common.text_util import base_dir
def email_util(att=None, content=None, subject=None,):
"""发送邮件的工具方法"""
username = '52985****@qq.com'
password = 'segkbtnjeimd****'
receiver = '1853451****@163.com' # 接收邮箱
content = content
if att is None: # 不带附件的
message = MIMEText(content)
message['subject'] = subject
message['from'] = username
message['to'] = receiver
else: # 带附件发送
message = MIMEMultipart()
txt = MIMEText(content, _charset='utf-8', _subtype="html")
part = MIMEApplication(open('%s/%s' % (base_dir, att), 'rb').read())
part.add_header('Content-Disposition', 'attachment', filename=att.split('\\')[-1])
message['subject'] = subject
message['from'] = username
message['to'] = receiver
message.attach(txt)
message.attach(part)
# 登录smtp服务器
smtpserver = 'smtp.qq.com'
smtp = smtplib.SMTP()
smtp.connect(smtpserver)
smtp.login(username, password)
smtp.sendmail(username, receiver, message.as_string())
smtp.quit()
if __name__ == '__main__':
email_util(content="<i>测试发送邮件</i>", subject="测试发送邮件-主题", att='output/run_result_excel/吃素.jpg')
1.7、log_util.py
封装日志处理的方法(日志这个懒得写了,直接网上copy过来改改用)
import logging
import logging.handlers
import os
import time
from common.text_util import base_dir
class LogUtil(object):
def __init__(self):
self.logger = logging.getLogger("")
# 创建文件目录
logs_dir = "%s/output/logs" % base_dir
if os.path.exists(logs_dir) and os.path.isdir(logs_dir):
pass
else:
os.mkdir(logs_dir)
# 修改log保存位置
timestamp = time.strftime("%Y%m%d", time.localtime())
logfilename = '%sOkayProject.txt' % timestamp
logfilepath = os.path.join(logs_dir, logfilename)
rotatingFileHandler = logging.handlers.RotatingFileHandler(filename=logfilepath,
maxBytes=1024 * 1024 * 50,
backupCount=5)
# 设置输出格式
formatter = logging.Formatter('[%(asctime)s] [%(levelname)s] %(message)s', '%Y-%m-%d %H:%M:%S')
rotatingFileHandler.setFormatter(formatter)
# 控制台句柄
console = logging.StreamHandler()
console.setLevel(logging.NOTSET)
console.setFormatter(formatter)
# 添加内容到日志句柄中
self.logger.addHandler(rotatingFileHandler)
self.logger.addHandler(console)
self.logger.setLevel(logging.INFO)
def info(self, message):
self.logger.info(message)
def debug(self, message):
self.logger.debug(message)
def warning(self, message):
self.logger.warning(message)
def error(self, message):
self.logger.error(message)
调用日志方法:
# 添加日志
log_text = "name:%s,url:%s,reponse:%s" % (name, url, rep)
LogUtil().info(log_text)
1.8、request_util.py
- 封装运行用例时,发送请求的方法
- 将运行结果写入.txt文件(也可以直接写redis中)
import json
import requests
from common.text_util import *
def request_utl(method, url, headers, payloads, params=None, expect=None, run_result_txt=None):
if method == 'get':
res = requests.get(url=url, headers=headers, params=params)
assertion = expect in res.text # 断言依据
if assertion:
assert assertion
# 将运行结果写入txt文件保存
write_txt(text_file=run_result_txt, data=res.text+"__pass|") # 用"__"符号间隔
else:
assert assertion
write_txt(text_file=run_result_txt, data=res.text+"__fail|")
elif method == 'post':
res = requests.post(url=url, headers=headers, data=payloads)
assertion = expect in res.text # 断言依据
print("断言是:", assertion)
if assertion:
write_txt(text_file=run_result_txt, data=res.text+"__pass|")
else:
write_txt(text_file=run_result_txt, data=res.text+"__fail|")
assert assertion
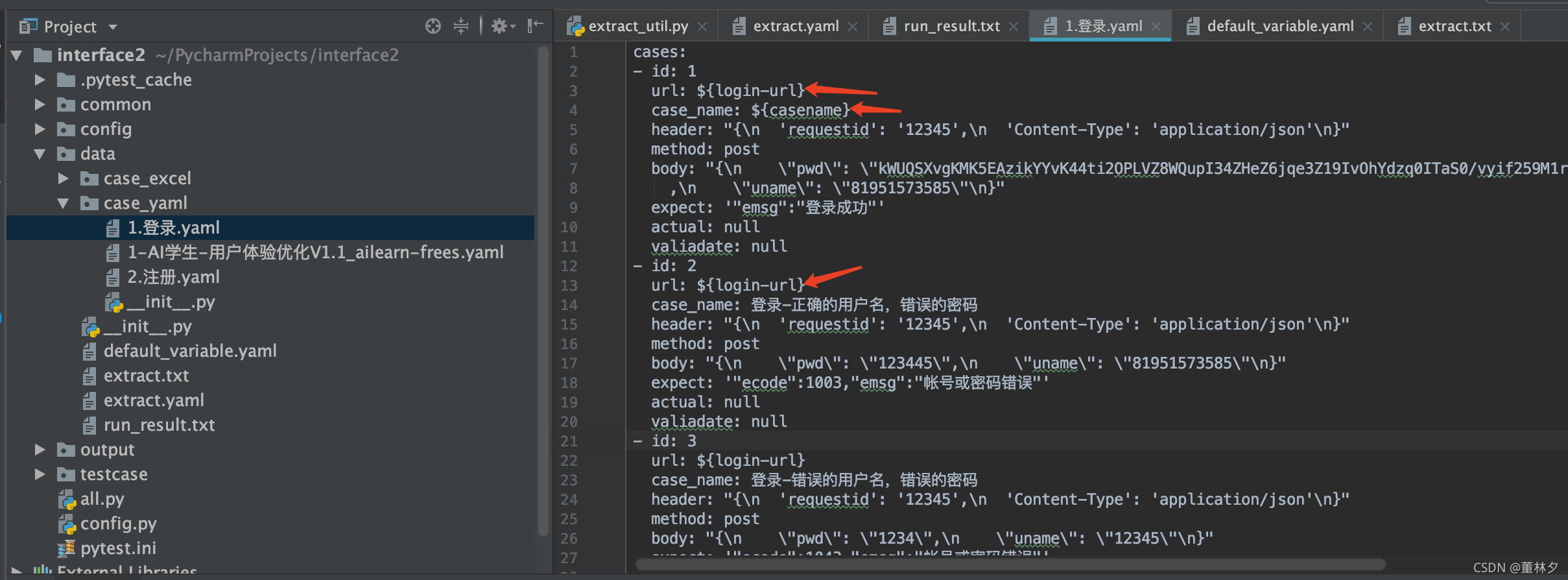
1.9、extract_util.py,实现数据驱动—yaml热处理
- 将变量保存到extract.yaml中
- 在用例yaml中用${}引用的变量
- 用例运行时,调封装好的方法,先进行变量替换,进行热处理
知识点:
- re库:待补充re.findall()、re.sub
import re
from common.exception_utils import exception_utils
from common.text_util import *
from common.yaml_util import *
@exception_utils
def extract_util(case_file, extract_yamlfile="%s/data/data_driven_yaml/extract.yaml" % base_dir,
default_yamlfile="%s/data/data_driven_yaml/default_variable.yaml" % base_dir):
"""
数据关联的公共方法
思路:
1.运行用例前,检查用例yaml中是否有${}
2.有,则检查${}中的变量是否存在于extract.yaml中
3.有,则替换;无,则不变,或设置默认值
4.内存中覆盖yaml中读取的值
5.再进行数据驱动
返回——>替换${变量}后的数据
"""
# 运行用例
text_file = '%s/data/extract_replace.txt' % base_dir
# 运行前先清空extract.txt
# truncate_txt(text_file)
# 1.返回全部匹配到的结果,且去重
value_cases = str(read_yaml(case_file))
extract_txt(text_file='%s/data/extract_replace.txt' % base_dir, data=value_cases) # 一.写入txt
p = r'\$\{(.*?)\}'
match_list = list(set(re.findall(p, value_cases)))
# 2.提取字段的key列表(关联变量 和 用户默认变量,将他们合并)
global value_extract_keys, value_extract
if read_yaml(extract_yamlfile):
value_extract = read_yaml(extract_yamlfile)
print(value_extract)
vlaue_default_variable = read_yaml(default_yamlfile)
value_extract.update(vlaue_default_variable)
value_extract_keys = list(value_extract.keys())
print(value_extract_keys)
# print(value_extract)
else:
print("extract.yaml文件中没有储存的变量")
if read_yaml(default_yamlfile):
vlaue_default_variable = read_yaml(default_yamlfile)
value_extract_keys = list(vlaue_default_variable.keys())
print(value_extract_keys)
"""这里有点不太会,只会用比较笨的办法,每次结果存入txt文件,然后再每次读取txt文件"""
# 3.动态替换${}
for m in match_list:
if m in value_extract_keys:
p1 = r'\${%s}' % m
replace = re.sub(p1, value_extract[m], read_txt(text_file)) # 替换${}中内容
extract_txt(text_file=text_file, data=replace) # 三.每次覆盖动态写入
else:
print("关联数据中,没有该key:%s" % m)
return eval(read_txt(text_file))['cases']
def save_variable(key, value):
"""保存变量到extract.yaml文件,需要模块运行前先进行清空"""
# 1.数据按格式追加写入extract_save.txt文件
file = '%s/data/extract_save.txt' % base_dir
extract_yamlfile = "%s/data/data_driven_yaml/extract.yaml" % base_dir
write_txt(file, '"%s":"%s",' % (key, value))
variable = eval("{%s}" % read_txt(file)[0:-1])
write_yaml(data=variable, yaml_file=extract_yamlfile)
用例yaml中引用变量如下:
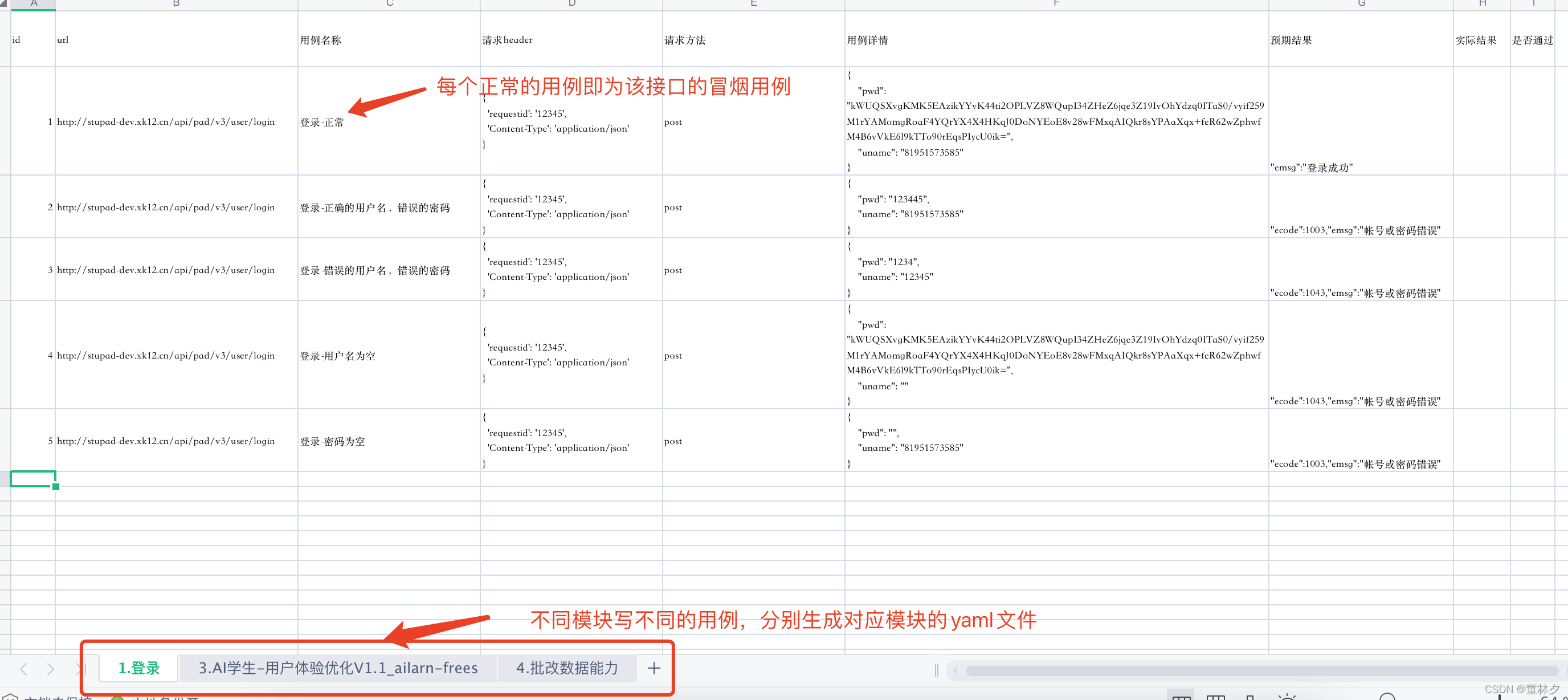
2.测试数据—data

excel编写接口测试用例:
3.输出文件—output
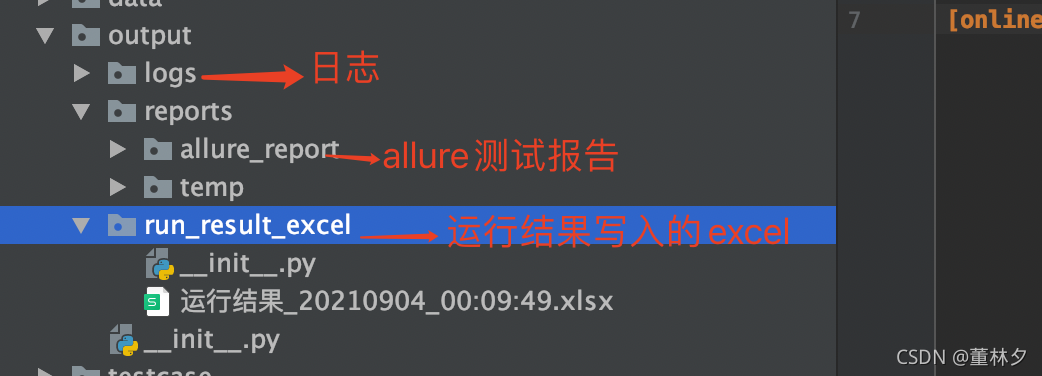
运行结果自动写入接口测试用例中:
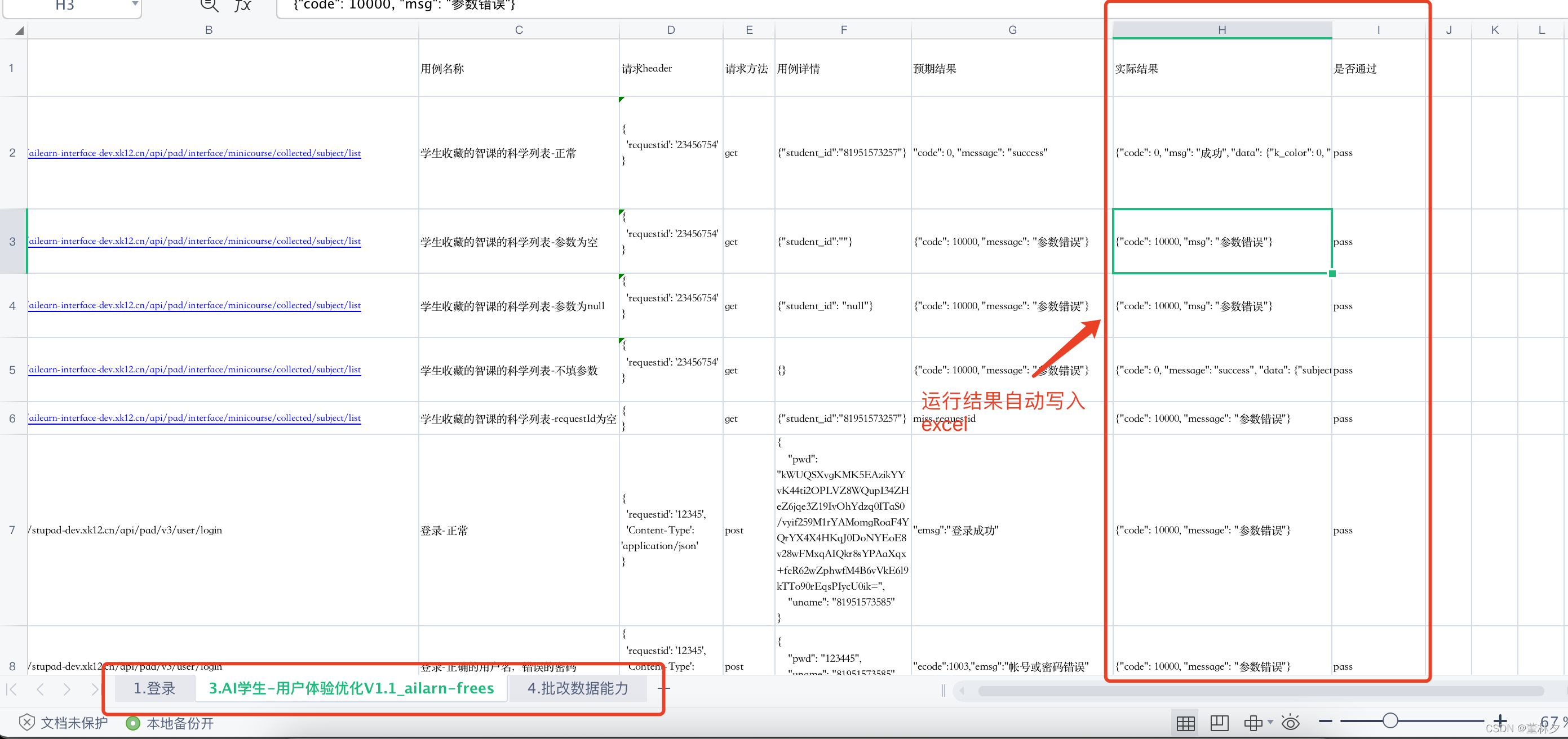
4.运行用例—testcase
拿登录举例:
- 用pytest.mark.parametrize()数据驱动 和 yaml结合生成测试用例
- 用封装好的请求方法,直接传参调用
import pytest
from common.request_util import request_utl
from common.text_util import *
from common.yaml_util import *
import json
# @pytest.mark.skip
@pytest.mark.parametrize('args', read_yaml('%s/data/case_yaml/1.登录.yaml' % base_dir)['cases'])
def test_login(args):
"""登录接口,获取token"""
#
url = args['url']
headers = eval(args['header'])
payloads = json.dumps(eval(args['body']))
params = eval(args['body'])
method = args["method"]
run_result_txt = '%s/data/run_result.txt' % base_dir # 运行结果保存到txt文件中
expect = args['expect'] # 断言依据
# 二、调封装的请求方法
request_utl(method, url, headers, payloads=payloads, params=params, expect=expect, run_result_txt=run_result_txt)
5.前后置—conftest.py结合pytest.fixture()
前置内容:
- 清空关联数据文件yaml文件
- 登录获取token,写入yaml文件
后置内容:
知识点:通过conftest.py和pytest.fixture()来实现用例的前后置
import pytest
from common.text_util import *
@pytest.fixture(scope="function")
def login():
print("用例运行前,先登录")
@pytest.fixture(scope='session', autouse=True)
def truncate():
"""运行用例前清空data下的相关文件"""
print("\n用例运行前操作:")
print("1.清空run_result.txt文件")
truncate_txt("%s/data/run_result.txt" % base_dir)
print("2.清空extract_save.txt文件")
truncate_txt("%s/data/extract_save.txt" % base_dir)
print("3.清空extract_replace.txt文件")
truncate_txt("%s/data/extract_replace.txt" % base_dir)
print("4.清空extract.ymal文件")
truncate_txt("%s/data/data_driven_yaml/extract.yaml" % base_dir)
yield
print("用例运行完毕,这是后置")
6.运行用例—all.py
import os
import time
from common.text_util import *
def main():
# 运行用例的主入口
truncate_txt("%s/data/run_result.txt" % base_dir)
tempdir_path = "output/reports/temp/%stemp" % time.strftime("%y%m%d-%H%M%S")
os.system("pytest --alluredir %s" % tempdir_path)
os.system("allure generate %s"
" -o output/reports/allure_report --clean" % tempdir_path)
if __name__ == '__main__':
main()
三、设计缺陷及解决方案
- 缺陷一:用例运行失败无返回数据时,这时保存的运行结果就不是全部的,因此结果写入excel文件时,报异常;解决方案:1.在用例后置中,加入逻辑判断,结果数和用例数是否一致,一致则写入;2.失败无结果的用例,给个默认值;
- 缺陷二:发送请求的和断言的方法,被封装在一起,这时不能提取返回参数到exrtact.yaml;解决方案:直接return一个res.text,然后添加逻辑判断,正常用例的时候,将返回中的token写入提取关联数据的yaml
- 缺陷三:灵活性,如何可以做到自由选择或添加模块运行,用例失败重跑,等各种运行用例相关的操作;解决:待定
- 缺陷四:测试报告默认是最新的,如何做到可以自由选择往期的测试报告进行查看;解决方案:用alluer 生成报告的命令,根据选择,动态进行生成报告;
- 缺陷五:日志是用logging呢,还是用pytest.ini中的日志配置进行收集日志
- 缺陷六:allure测试报告的定制化;解决方案:先得学习下allure报告相关的知识
- 缺陷七:如何冒烟测试(因为用例都写在了一起,不好拆开);解决方案:1.直接pytest.mark.smoke进行标记冒烟用例,然后生成一个smoke.yaml来保存;2.用例运行时,选择冒烟用例进行运行
- 缺陷八:关联数据后的,需要定义用例的运行顺序,如何定义;解决方案:直接在代码中手动添加pytest.order 来规定用例运行的先后顺序
- 缺陷九:签名的处理
四、结合jenkins实现持续集成
1.jenkins的安装
我是直接用docker拉取jenkins的镜像,进行在本地安装jenkins(docker安装就不写了)
拉取jenkins命令:docker pull jenkins/jenkins
启动镜像命令:docker run -d --name myjenkins -p 8080:8080 -p 50000:50000 -v /var/jenkins_node:/var/jenkins_home jenkins/jenkins
直接浏览器访问:127.0.0.1:8080
配置jenkins
参考:https://blog.csdn.net/qq_44663072/article/details/137927323

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)