

最好用的十六进制编辑器010 Editor
https://blog.csdn.net/qq_38482805/article/details/89309120
新版010Edit注册机&去除网络验证:https://bbs.pediy.com/thread-249724.htm
010Editor脚本语法入门:https://www.jianshu.com/p/ba60ebd8f916
宇宙最强 010 Editor 模板开发教程(附带示例):https://bbs.pediy.com/thread-257797.htm
简介
010editor是一款十六进制编辑器,和winhex相比支持更灵活的脚本语法,可以对文件、内存、磁盘进行操作
软件简介:
010 Editor 是一款专业的文本编辑器和十六进制编辑器,旨在快速轻松地编辑计算机上任何文件的内容。该软件可以编辑文本文件,包括 Unicode 文件、批处理文件、C/C++、XML 等,而在编辑二进制文件中,010 Editor 有很大的优势。二进制文件是一种计算机可读但人类不可读的文件(如果在文本编辑器中打开,二进制文件将显示为乱码)。十六进制编辑器是一个程序,它允许您查看和编辑二进制文件的单个字节,以及包括 010 Editor 的高级十六进制编辑器还允许您编辑硬盘驱动器、软盘驱动器、内存密钥、闪存驱动器、CD-ROM、进程等中的字节。这里仅列出使用 010 Editor 的一些优点:
* 查看并编辑在你硬盘驱动器上(文件大小无限制)的任何二进制文件和文本文件,包括 Unicode 文件、C/C++、XML、PHP,等。
* 独特的二进制模板技术允许你了解任何二进制文件格式。
* 查找并修复硬盘驱动器、软驱、内存密钥、闪存驱动器、CD-ROM、进程等的问题。
* 用强大的工具包括查找、替换、在多文件中查找、在多文件中替换、二进制比较、校验和/散列算法、直方图等,来分析和编辑文本和二进制数据。
* 强大的脚本引擎允许多任务的自动化(语言非常类似于 C)。
* 轻松下载并安装其他使用 010 Editor 储存库共享的二进制模板和脚本。
* 以不同的格式导入和导出二进制数据。
内置在 010 Editor 中的十六进制编辑器可以立即加载任意大小的文件,并且对所有编辑操作都可以无限制地撤消和重做。编辑器甚至可以立即在文件之间复制或粘贴大量的数据块。010 Editor 的可移植版本也可用于 Windows 从 USB 键运行 010 Editor。试用了 010 Editor 后,我们相信你会同意 010 Editor 是今天最强大的十六进制编辑器!
官网地址是:http://www.sweetscape.com
模板文件地址是:http://www.sweetscape.com/010editor/repository/templates/
可以看到很多支持的模板。可以在官网上手动下载模板,也可以在 010editor 编辑器中下载模板。
打开 010editor 点击菜单 Templates -> Template Repository,会出现各种文件格式的模板,如下图

比如选择 EXE 文件的模板来分析 PE 文件,然后打开一个 PE 文件,效果如图:


文件模板
(*.bt) 用于识别文件类型 http://www.sweetscape.com/010editor/repository/templates/
- 支持cab gzip rar zip cda midi mp3 ogg wav avi flv mp4 rm pdf iso vhd lnk dmp dex androidmanifest class
- Drive.bt 解析mbr fat16 fat43 hfs ntfs等
- elf.bt 解析Linux elf格式的文件
- exe.bt 解析windows pe x86/x64 格式文件(dll sys exe ...)
- macho.bt 解析mac os可执行文件
- registrayhive.bt 解析注册表(Hive)文件
- bson.bt 解析二进制json
脚本模板
常用的脚本库(*.1sc)用于操作数据http://www.sweetscape.com/010editor/repository/scripts/
- CountBlocks.1sc 查找指定数据块
- DecodeBase64.1sc 解码base64
- EncodeBase64.1sc 编码base64
- Entropy.1sc 计算熵
- JoinFIle.1sc SplitFile.1sc 分隔合并文件
- Js-unicode-escape.1sc Js-unicode-unescape.1sc URLDecoder.1sc js编码解码
- CopyAsAsm.1sc CopyAsBinary.1sc CopyAsCpp.1sc CopyAsPython.1sc 复制到剪贴板
- DumpStrings.1sc 查找所有ascii unicode字符串
010 Editor 模板开发教程(附带示例)
众所周知,010 Editor 是二进制分析中十分强力的工具,能够解析多种文件格式并以友好的界面呈现。其强大的内部引擎使得任何人都可以定制所需的解析脚本或解析模板。在 010 的官网上已经有仓库存放了大量的 脚本 和 模板 库供大伙使用。但问题一定是解决不完的,当遇到冷门文件而官方仓库没有模板咋办?办法只有一个:自己写。
本文将手把手教你如何写一个简单而不失优雅的模板。首先我会讲解下 010 模板开发的基本语法和规则,然后会提到常用的一些 Api,最后会以微软的.lib静态库为例演示实际操作过程。
基本语法
010 模板(010 Editor Templates)的基本语法和 C 语言类似,毫不夸张的说你要是会 C 的话,你已经学会了一半。剩下一半你就记住这句话:将整个文件的二进制数据当作输入,将其强制转换为一个结构体就行了。不过当你动手开始实践的时候,你会发现事情果然没有那么简单的,要将整个文件的数据转换成一个结构体,其内部需要更细粒度的结构体来支撑。
前面说了一堆废话,还是要讲讲基本语法的,毕竟这是一篇从入门到踩坑系列教程。
变量类型
C 语言中基本变量类型都是支持,包括 int、char、short、long、float 等,结构体 struct,枚举 enum,位域 bitfield 以及联合体 union 也是没问题的。C 中常用的关键字 define、const 和 unsigned 等也是可以用在 010 模板中的。除此之外,Windows 中定义的变量类型也是受支持的,诸如 WORD、DWORD、UINT32、UINT64、LONG。
表达式及语法
C 中的各种加减乘除,大于小于,与或非等表达式也是可以用在模板中的,具体的如下:
- 数值运算:+ - * / ~ ^ & | % ++ -- ?: << >> ()
- 逻辑运算:&& || !
- 比较操作:< ? <= >= == != !
- 赋值操作:= += -= *= /= &= ^= %= |= <<= >>=
C 语言本身的语法并不复杂,在 010 模板中你更不必了解某些生僻的语法,只需要知道 if...else、while、for、switch 以及数组和函数即可。C 语言强大而复杂的指针在 010 中完全用不着,是不是贼开心,可以不用顶着多级指针去操作数据了。
需要注意的是在 010 模板中不能使用二维数组以及 goto 语句。
特殊属性
在官网的文档中,给出了 010 模板中具有的特殊属性:
<format=hex|decimal|octal|binary,
fgcolor=<color>,
bgcolor=<color>,
comment="<string>"|<function_name>,
name="<string>"|<function_name>,
open=true|false|suppress,
hidden=true|false,
read=<function_name>,
write=<function_name>,
size=<number>|<function_name>>下面将简单介绍下这些属性
- format: 以某种进制格式显示,默认为十进制,显示在 Vlaue 栏
- fgcolor: 设置字体色
- bgcolor: 设置背景色
- comment: 添加注释,显示在 Comment 栏
- name: 替换显示的字符,默认为结构体中的变量名,显示在 Name 栏
- open: 设置树形图是否展开,默认不展开
- hidden: 设置是否隐藏,默认为不隐藏
- read: 读回调,返回字符串并显示在 Vlaue 栏
- write: 写回调,将读回调返回的字符写入结构体某个字段中
- size: 按需执行,可节约系统内存
把这些特殊属性归个类,不常用的属性有 open、write 和 size,某些比较特殊情况下会用到的属性 name 和 hidden,花里胡哨时才会用到 fgcolor 和 bgcolor,快速开发模板你只需要记住 read、format 和 comment。
上边提到特殊情况我展开说明下,name 属性我没怎么用到过,感觉是给强迫症用的,hidden 这个属性在某些情况下有奇效,比如定义的局部变量可能显示在结果中,这时候就可以利用<hidden=true>来隐藏冗余的输出。
下面我放两张图,帮助大伙更好的理解以上这几个特殊的属性,图 1 中的 1 处是 name 属性显示的字符,如果不指定 name 属性默认就是结构体中的变量名。2 处是 format 属性,默认是十进制,这里指定为 16 进制。3 处是背景颜色和字体颜色缩影,这里没设置颜色所以显示为空。4 处就是 comment 属性显示的位置。
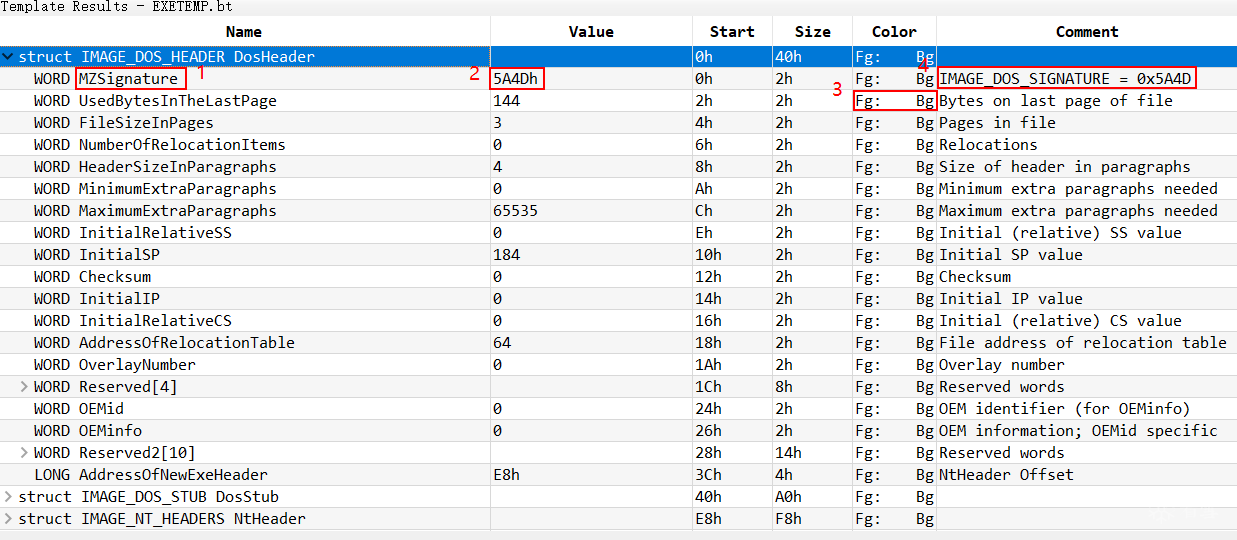
背景颜色 bgcolor 和字体颜色 fgcolor 明眼人一看就明白了。
API接口
010 模板的 Api 比较多,我将一些使用频率比较高的 Api 罗列出来,如果你想要完整的 Api 列表,请看官网的函数接口。不过个人认为下面的 Api 已经足够使用了,除非你要写非常复杂的解析模板:
- void BigEndian()
- void LittleEndian()
- char ReadByte(int64 pos=FTell())
- uchar ReadUByte(int64 pos=FTell())
- short ReadShort(int64 pos=FTell())
- ushort ReadUShort(int64 pos=FTell())
- int ReadInt(int64 pos=FTell())
- uint ReadUInt(int64 pos=FTell())
- int64 ReadInt64(int64 pos=FTell())
- uint64 ReadUInt64(int64 pos=FTell())
- void ReadBytes(uchar buffer[], int64 pos, int n)
- char[] ReadString(int64 pos, int maxLen=-1)
- int ReadStringLength(int64 pos, int maxLen=-1)
- wstring ReadWString(int64 pos, int maxLen=-1)
- int ReadWStringLength(int64 pos, int maxLen=-1)
- void WriteByte(int64 pos, char value)
- int FSeek(int64 pos)
- int FSkip(int64 offset)
- int64 FTell()
- int FEof()
- void Strcpy(char dest[], const char src[])
- void Strcat(char dest[], const char src[])
- int Strchr(const char s[], char c)
- int Strcmp(const char s1[], const char s2[])
- int Printf(const char format[] [, argument, ... ])
- int SScanf(char str[], char format[], ...)
- int SPrintf(char buffer[], const char format[] [, argument, ... ])
这些 Api 大部分都能猜出来是干嘛的,比如 ReadByte 是指定位置读取一个字节,WriteByte 是指定位置写入一个字节,Strcmp 是字符串比较,Printf 打印字符,SScanf 将字符数组 buffer 格式化为多种数据格式,SPrintf 将各种数据格式化后置于字符数组 buffer。
特别需要注意的是以下几个函数,对于解析偏移后的动态数据它们是不可或缺的:
- FEof 判断当前读取位置是否在文件末尾
- FTell 返回文件的当前读取位置
- FSeek 将当前读取位置设置为指定地址
- FSkip 将当前读取位置向前移动多个字节
如果你想要操控 010 模板内部指针的位置,你就得牢记模板在解析文件时内部指针的移动方式:
- 每次在模板中定义变量时,读取位置都会向前移动该变量使用的字节数
- ReadByte 等函数既可以读取数据也不会影响读取位置
模板开发过程演示
下面我就以微软的静态库.lib文件为例,给大伙演示一个 010 模板从无到有的完整过程。你想想如果你要解析某个文件,第一步会干嘛呢?当然是了解该文件的构成,所以第一步就是搜集相关的资料。
搜集资料
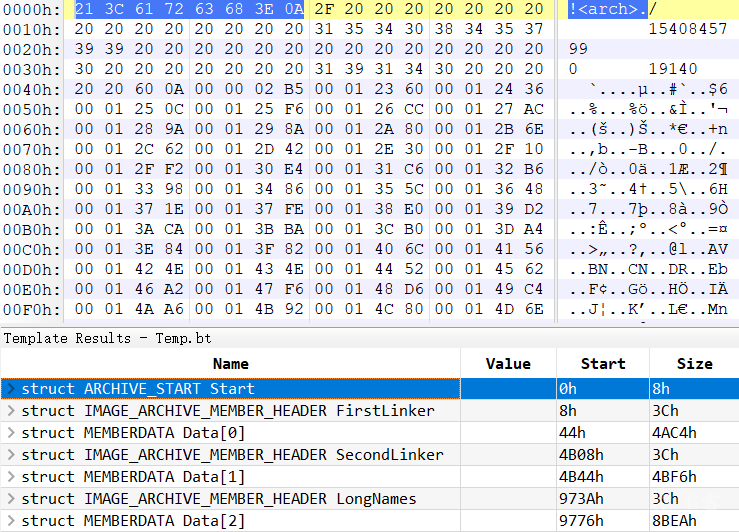
在看雪论坛上找到一篇LIB文件解析的文章,将其消化理解后我画了一张结构图来帮助大伙理解,如图:

要是没接触过 Lib 文件,是很难参悟上图的,所以我将上图简要的阐述下,可能会利于大伙理解:
- 开头 8 字节固定为
!<arch>. - 随后为 60 字节的第一链接成员以及 Size 字节的数据
- 然后是第二链接成员及其数据
- 紧接着又是长名称成员及其数据
- 最后是每一个 Obj 成员及其数据
注意,Size 的具体值在其对应的成员结构体中指定。顺便再科普以下,Lib 文件其实是以特定格式打包多个 Obj 文件后的产物
定义结构
有了之前准备的那些资料,就可以为 010 模板定义核心的结构了,核心的结构如下所示:
#define IMAGE_ARCHIVE_START_SIZE 8
#define IMAGE_ARCHIVE_START "!<arch>\n"
#define IMAGE_ARCHIVE_LINKER_MEMBER "/ "
#define IMAGE_ARCHIVE_LONGNAMES_MEMBER "// "
typedef struct _ARCHIVE_START
{
char StartStr[IMAGE_ARCHIVE_START_SIZE];
}ARCHIVE_START;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER {
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER;
typedef struct _MEMBERDATA(ULONG Size)
{
UCHAR Data[Size];
}MEMBERDATA;一定要注意,IMAGE_ARCHIVE_MEMBER_HEADER 的 最后一个字段 EndHeader 必须是以 `\n 结尾,如果不是则必须将当前指针向后移动直到符合上述条件,否则后续的数据解析会连环出错。为了方便只需判断最后一个字节的 ascii 码是不是 10 即可,如果不是当前指针加 1 即可。
简单解析模板
俗话说饭要一口一口的吃,事要一点一点的做。所以先把 Obj 成员之外的简单结构解析了,这部分的代码如下:
#define IMAGE_ARCHIVE_START_SIZE 8
#define IMAGE_ARCHIVE_START "!<arch>\n"
#define IMAGE_ARCHIVE_LINKER_MEMBER "/ "
#define IMAGE_ARCHIVE_LONGNAMES_MEMBER "// "
typedef struct _ARCHIVE_START
{
char StartStr[IMAGE_ARCHIVE_START_SIZE];
}ARCHIVE_START;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER {
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER;
typedef struct _MEMBERDATA(ULONG Size)
{
UCHAR Data[Size];
}MEMBERDATA;
//--------------------------------------
LittleEndian();
ARCHIVE_START Start;
IMAGE_ARCHIVE_MEMBER_HEADER FirstLinker;
if(ReadByte(FTell() + Atoi(FirstLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(FirstLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(FirstLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER SecondLinker;
if(ReadByte(FTell() + Atoi(SecondLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(SecondLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(SecondLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER LongNames;
if(ReadByte(FTell() + Atoi(LongNames.Size)) == 10)
{
MEMBERDATA Data(Atoi(LongNames.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(LongNames.Size));
}010 模板语法是脚本类型的,即它也是顺序执行。代码的前半部分是一堆类型定义,所以执行的第一行代码是 LittleEndian(),该函数指定为小端解析。后半部分代码是把文件数据依次对应到某个变量,在解析时文件指针会跟随每个结构体的大小移动,解析的效果如图:
完整解析模板
前面已经解析了 Lib 文件中比较简单的结构,剩下的是多个 Obj 成员和数据,这部分解析起来比较复杂。而且最复杂的地方是将其文件名找到并显示在 Value 栏或者 Comment 栏中。所以必须使用 read 和 comment 回调来实现该功能,完整的模板代码如下:
#define IMAGE_ARCHIVE_START_SIZE 8
#define IMAGE_ARCHIVE_START "!<arch>\n"
#define IMAGE_ARCHIVE_LINKER_MEMBER "/ "
#define IMAGE_ARCHIVE_LONGNAMES_MEMBER "// "
typedef struct _ARCHIVE_START
{
char StartStr[IMAGE_ARCHIVE_START_SIZE];
}ARCHIVE_START;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER {
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER;
typedef struct _MEMBERDATA(ULONG Size)
{
UCHAR Data[Size];
}MEMBERDATA;
typedef struct _IMAGE_ARCHIVE_MEMBER_HEADER_OBJ(int i) {
local int index <hidden=true>;
index = i;
BYTE Name[16];
BYTE Date[12];
BYTE UserID[6];
BYTE GroupID[6];
BYTE Mode[8];
BYTE Size[10];
BYTE EndHeader[2];
}IMAGE_ARCHIVE_MEMBER_HEADER_OBJ <comment=GetFullObjName,read=GetObjName>;
typedef struct _ALLOBJS
{
local int i <hidden=true>;
i = 0;
while(!FEof())
{
IMAGE_ARCHIVE_MEMBER_HEADER_OBJ ObjMember(i++);
if(FTell() + Atoi(ObjMember.Size) >= FileSize())
{
MEMBERDATA Data(Atoi(ObjMember.Size));
break;
}
if(ReadByte(FTell() + Atoi(ObjMember.Size)) == 10)
{
MEMBERDATA Data(Atoi(ObjMember.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(ObjMember.Size));
}
}
}ALLOBJS;
string GetFullObjName(IMAGE_ARCHIVE_MEMBER_HEADER_OBJ& MemberHeader)
{
local int j <hidden=true>;
j = 0;
local int NameOffset <hidden=true>;
NameOffset = LongNameBase;
while(j++ < MemberHeader.index)
{
NameOffset += Strlen(ReadString(NameOffset)) + 1;
}
return ReadString(NameOffset);
}
string GetObjName(IMAGE_ARCHIVE_MEMBER_HEADER_OBJ& MemberHeader)
{
local int j <hidden=true>;
j = 0;
local int k <hidden=true>;
k = 0;
local int NameOffset <hidden=true>;
NameOffset = LongNameBase;
local int start <hidden=true>;
start = 0;
while(j++ < MemberHeader.index)
{
NameOffset += Strlen(ReadString(NameOffset)) + 1;
}
for(start = NameOffset + Strlen(ReadString(NameOffset));start >= NameOffset;start--)
{
if(ReadByte(start) == '\\')
{
break;
}
}
return ReadString(start + 1);
}
//--------------------------------------
LittleEndian();
local int LongNameBase <hidden=true>;
ARCHIVE_START Start;
IMAGE_ARCHIVE_MEMBER_HEADER FirstLinker;
if(ReadByte(FTell() + Atoi(FirstLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(FirstLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(FirstLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER SecondLinker;
if(ReadByte(FTell() + Atoi(SecondLinker.Size)) == 10)
{
MEMBERDATA Data(Atoi(SecondLinker.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(SecondLinker.Size));
}
IMAGE_ARCHIVE_MEMBER_HEADER LongNames;
LongNameBase = FTell();
if(ReadByte(FTell() + Atoi(LongNames.Size)) == 10)
{
MEMBERDATA Data(Atoi(LongNames.Size) + 1);
}
else
{
MEMBERDATA Data(Atoi(LongNames.Size));
}
ALLOBJS Object;这里讲起来有点绕,所以我会挑一些我认为的重点来说,先给大伙看些最终的效果吧,示例文件是 VS 中的 libcmt.lib。
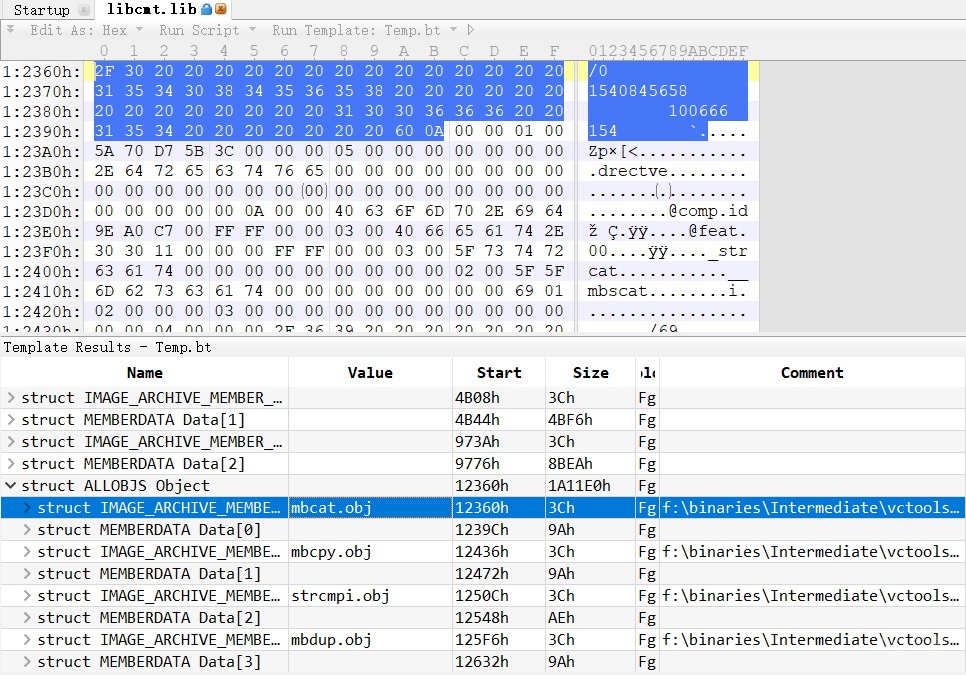
以下是我认为的代码中的重点:
- 必须判断成员结构的尾部是否为
\n - 必须记录长名称的基址 LongNameBase
- 回调函数可以访问结构体中的局部变量
- 解析时文件指针一定不能超过文件的大小
文章不易写,有错请理解,三克油。
参考链接:







 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)