Linux下c语言多线程编程
创建线程函数pthread_create()和等待线程函数pthread_join()的用法。注意:在创建线程pthread_create()之前,要先定义线程标识符:pthread_t 自定义线程名;例子1:创建线程以及等待线程执行完毕。#include <stdio.h>#include <stdlib.h>#include <pthread.h>//线程要
创建线程函数pthread_create()和等待线程函数pthread_join()的用法。
注意:在创建线程pthread_create()之前,要先定义线程标识符:
pthread_t 自定义线程名;
例子1:创建线程以及等待线程执行完毕。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
//线程要运行的函数,除了函数名myfunc,其他全都是固定的。
void* myfunc()
{
printf("Hello World!\n");
return NULL;
}
int main()
{
pthread_t th;//在创建线程之前要先定义线程标识符th,相当于int a这样
pthread_create(&th,NULL,myfunc,NULL);
/*第一个参数是要创建的线程的地址
第二个参数是要创建的这个线程的属性,一般为NULL
第三个参数是这条线程要运行的函数名
第四个参数三这条线程要运行的函数的参数*/
pthread_join(th,NULL);
/*线程等待函数,等待子线程都结束之后,整个程序才能结束
第一个参数是子线程标识符,第二个参数是用户定义的指针用来存储线程结束时的返回值*/
return 0;
}
//编译运行多线程的程序,要在gcc命令尾部加上-lpthread
//gcc example1.c -lpthread -o example1
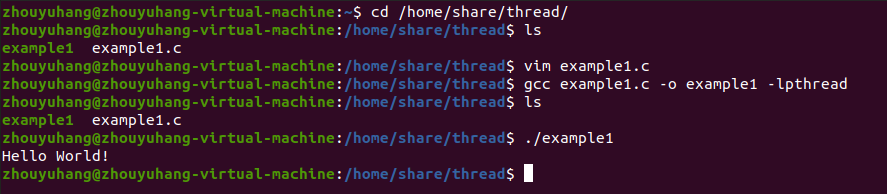
例子二:创建两条线程以及等待两条线程执行完毕
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* myfunc()
{
int i;
for(i=1;i<50;i++)
{
printf("%d\n",i);
}
return NULL;
}
int main()
{
pthread_t th1;
pthread_t th2;
pthread_create(&th1,NULL,myfunc,NULL);
pthread_create(&th2,NULL,myfunc,NULL);
pthread_join(th1,NULL);
pthread_join(th2,NULL);
return 0;
}
运行我们可以看到,线程1两条线程的执行方式是怎么样的,
线程1数到46就被挂起了,轮到线程二执行,cpu给线程二一个时间片,线程二在这个时间片内执行只数到20就被挂起了。然后cpu立即切换去执行线程1,线程1继续执行数到49执行完毕立即结束。CPU就立刻去执行剩下的线程二,直到执行结束。
两条线程是同时在随机交叉着运行的。
单核CPU就是这样子随机分配时间片给线程一直交换着执行,这叫并发执行。
如果运行的时候发现它是一条线程运行完了才换另一条,那可能就是cpu给他分配是时间片太多了而已让他直接就执行完毕了,线程运行确实是交换着执行的。
例子3
我们想看看哪些数字是第一条线程打印出来的,哪些数字是第二条线程打印出来的。
可以通过传递参数的方法来查看。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* myfunc(void* args)
{
int i;
//由于“th1”是字符串,所以这里我们要做个强制转换,把void*强制转换为char*
char* name = (char*) args;
for(i=1;i<50;i++)
{
printf("%s:%d\n",name,i);
}
return NULL;
}
int main()
{
pthread_t th1;
pthread_t th2;
pthread_create(&th1,NULL,myfunc,"th1");//pthread_create的第四个参数是要执行的函数的参数哦!~
//这里的“th1”就是void* args
pthread_create(&th2,NULL,myfunc,"th2");
pthread_join(th1,NULL);
pthread_join(th2,NULL);
return 0;
}
运行之后可以看到哪些数字是th1打印的,哪些数字是th2打印的。
例子4
定义一个大小为5000的数组,随机生成5000个数,我们想创建两条线程,让这两条线程去计算这5000个数字的和,第一条线程计算前2500个数的和,第二条线程让它算后2500个数字的和。怎么做?
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int arr[5000];
int s1=0;
int s2=0;
void* myfunc1(void* args)
{
int i;
for(i=0;i<2500;i++)
{
s1 = s1 + arr[i];
}
return NULL;
}
void* myfunc2(void* args)
{
int i;
for(i=2500;i<5000;i++)
{
s2 = s2 + arr[i];
}
return NULL;
}
int main()
{
//初始化数组
int i;
for(i=0;i<5000;i++)
{
arr[i] = rand() % 50;
}
/* for(i=0;i<5000;i++)
{
printf("a[%d]=%d\n",i,arr[i]);
}*/
pthread_t th1;
pthread_t th2;
pthread_create(&th1,NULL,myfunc1,NULL);
pthread_create(&th2,NULL,myfunc2,NULL);
pthread_join(th1,NULL);
pthread_join(th2,NULL);
printf("s1=%d\n",s1);
printf("s2=%d\n",s2);
printf("s1+s2=%d\n",s1+s2);
return 0;
}

例子5
上一个例子的代码重复率太高,我们对其优化,加入了结构体,也只用了同一个函数。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int arr[5000];
int s = 0;
typedef struct {
int first;
int last;
}MY_ARGS;
void* myfunc(void* args)
{
int i;
MY_ARGS* my_args = (MY_ARGS*)args;
int first = my_args->first;
int last = my_args->last;
for(i=first;i<last;i++)
{
s = s + arr[i];
}
printf("s = %d\n",s);
s=0;
return NULL;
}
int main()
{
//初始化数组
int i;
for(i=0;i<5000;i++)
{
arr[i] = rand() % 50;
}
/* for(i=0;i<5000;i++)
{
printf("a[%d]=%d\n",i,arr[i]);
}*/
pthread_t th1;
pthread_t th2;
//设置两个结构体变量作为参数
MY_ARGS args1 = {0,2500};
MY_ARGS args2 = {2500,5000};
pthread_create(&th1,NULL,myfunc,&args1);
pthread_create(&th2,NULL,myfunc,&args2);
pthread_join(th1,NULL);
pthread_join(th2,NULL);
return 0;
}
例子6
来看看如果把s加在全局变量,让s++循环10000次后会发生什么?
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
int s = 0;
void* myfunc(void* args)
{
int i = 0;
for(i=0;i<1000000;i++)
{
s++;
}
return NULL;
}
int main()
{
pthread_t th1;
pthread_t th2;
pthread_create(&th1,NULL,myfunc,NULL);
pthread_create(&th2,NULL,myfunc,NULL);
pthread_join(th1,NULL);
pthread_join(th2,NULL);
printf("s = %d\n",s);
return 0;
}

我们发现每次执行后的s都不一样,按理说s应该是200000才对呀,为什么会这样呢?
因为在第一条线程读s并s++的时候,第二条线程也会来读,可能在第一条线程进行加之前读也可能在加之后读,所以我们会丢失一些s++,所以每次运行出来的结果都不一样。
这种情况叫做race condition,当出现race contion的时候,就很有可能会出现错误的结果。
那么要如何解决race condition呢?
最常用的方法就是加锁。
有一种锁叫mutex。
我们看看mutex要怎么用?
pthread_mutex_t lock;
这种pthread_mutex_t的数据类型叫锁
定义一个锁后要对锁进行初始化
pthread_mutex_init(&lock,NULL);
锁初始化函数有两个参数,第一个参数就是我们定义的锁,第二个参数是互斥锁的属性,写NULL就可以了,代表默认的快速互斥锁。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
pthread_mutex_t lock;//定义一个互斥锁
int s = 0;
void* myfunc(void* args)
{
int i = 0;
pthread_mutex_lock(&lock);//这个函数表示,在这个地方上一个锁,就是摆一个锁在这个地方
for(i=0;i<100000;i++)
{
s++;
}
pthread_mutex_unlock(&lock);//把这个锁给解掉
return NULL;
}
int main()
{
pthread_t th1;
pthread_t th2;
pthread_mutex_init(&lock,NULL);//初始化这个锁,此时只是创建了这个锁而已,还没有加进去哦。
/*锁不是用来锁一个变量,它是用来锁住一段代码的。*/
pthread_create(&th1,NULL,myfunc,NULL);
pthread_create(&th2,NULL,myfunc,NULL);
pthread_join(th1,NULL);
pthread_join(th2,NULL);
printf("s = %d\n",s);
return 0;
}

解释一下上图的结果,加了锁之后得到的结果就是正确的了,第一次运行我是把锁加在for循环里头,可以看到运行的时间是.0.01ms是很慢的,而第二次运行也就是把锁加在for循环的外头,可以看到速度就快多了,所以加锁的位置很重要,最好不要加在循环里面,不然要一直循环开锁解锁就特别慢。
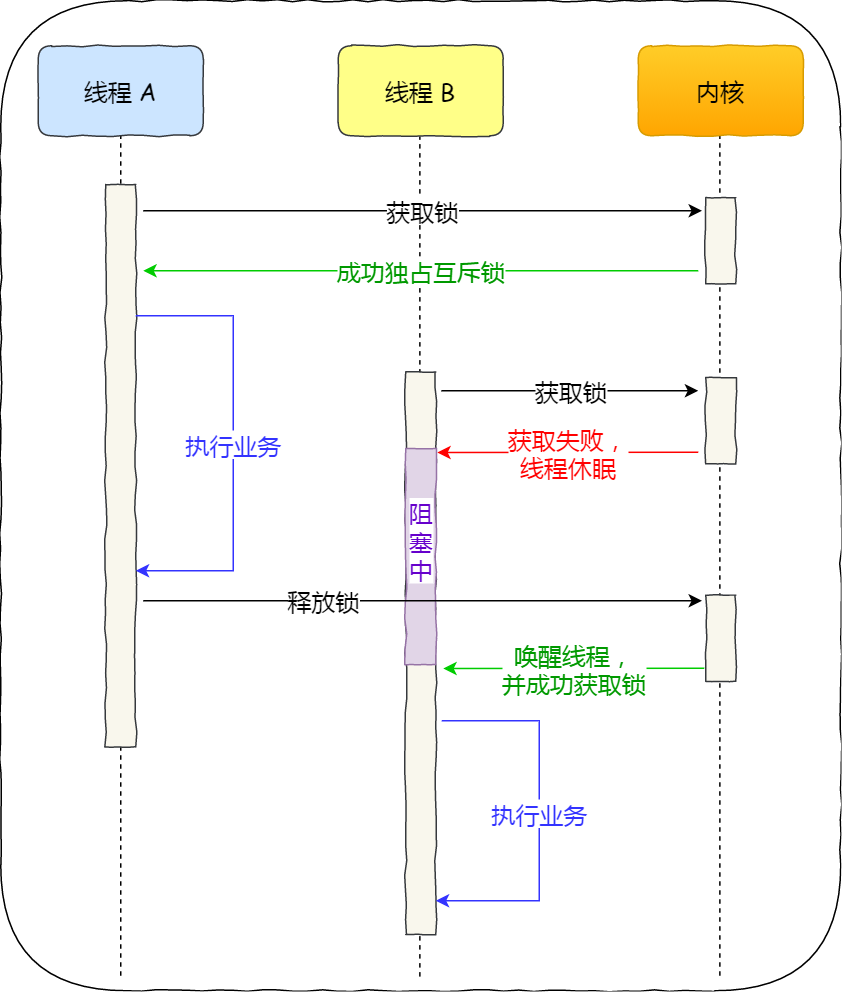
讲一下两条线程是遇到这个加锁的代码是怎么做的,
两条线程看谁先抢到这个锁,也是竞争在抢锁,如果是th1先抢到,那锁就是th1的了,拿到锁的线程就很自私,接下来锁里面的代码就是th1自己一个人的,th2就不能来读这段代码了,th2没抢到锁的话它自己是不会去自己加个锁的,th2只能靠边站了,等th1先走完了锁里的代码,然后解锁了,再轮th2,加锁可以保证两条线程不会去抢着读数据,导致结果出错。
加了锁,多线程就变成了两个单线程按顺序串行着走完,两个for循环是独立存在的。
互斥锁的作用:https://blog.csdn.net/galaxyxupt/article/details/81613181?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164868737616780261991331%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164868737616780261991331&biz_id=0&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_39736982/article/details/82348672?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164868779716781685333883%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164868779716781685333883&biz_id=0&spm=1018.2226.3001.4187
互斥锁可以 防止两条线程竞争共享数据资源而引起的与时间上有关的数据混乱。
每个线程在对共享资源操作前都尝试先加锁,成功加锁才能操作,操作结束解锁。
但通过“锁”就将资源的访问变成互斥操作,而后与时间有关的错误也不会再产生了。
在访问共享资源前加锁,访问结束后立即解锁。锁的“粒度”应越小越好。
https://blog.csdn.net/qq_34827674/article/details/108608566?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164868779716781685333883%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164868779716781685333883&biz_id=0&spm=1018.2226.3001.4187
多核的假共享的概念False sharing
为了避免假共享,最好分别把记录的结果当成局部变量。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)