linux内存管理
内存管理一、相关概念● 虚拟内存:内存管理的一种技术,它使得应用程序认为它拥有连续的可用内存(一个连续完整的地址空间);● 物理内存:相对于虚拟内存而言,指通过物理内存条而获得的内存空间;● 页表:一个进程的虚拟地址到物理地址的一个映射;● 页框:物理内存管理的基本单位,每个内存分区由大量的页框组成;内核以 struct page来描述页框;页框由很多属性,如页框的状态、用途、是否被分配等;● 内
内存管理
一、相关概念
● 虚拟内存:内存管理的一种技术,它使得应用程序认为它拥有连续的可用内存(一个连续完整的地址空间);
● 物理内存:相对于虚拟内存而言,指通过物理内存条而获得的内存空间;
● 页表:一个进程的虚拟地址到物理地址的一个映射;
● 页框:物理内存管理的基本单位,每个内存分区由大量的页框组成;内核以 struct page
来描述页框;页框由很多属性,如页框的状态、用途、是否被分配等;
● 内存节点:主要依据 CPU 访问代价的不同而划分,分为不同的分区;内核以 struct zone
来描述内存分区;通常一个节点分为 DMA、Normal 和 High Memory 内存区;
● DMA 内存区域:直接内存访问分区,通常为物理内存的起始 16M;主要是供一些外设使用,外设和内存直接访问数据访问,而无需系统 CPU 参与;不能 cache;
● 高端内存:在 32 位系统中 896M 以后的内存区;
● TLB:一般指转译后备缓冲区或者转译后备缓冲器,也被翻译为页表缓存、转址旁路缓存;
● PCB:Process Control Block,进程控制块,是进程实体的一部分;
● 内存共享:把两个虚拟地址空间通过页表映射到同一物理地址空间。这只需通过设置不 同索引的页表项的内容一致即可;
二、页表管理
1、页表概述
CPU 并不是直接访问物理内存地址,而是通过虚拟地址空间间接访问物理内存地址。而虚拟地址空间是操作系统为每一个执行中进程分配的逻辑地址,32 位 机上其范围从 0 ~ 4G。内核将虚拟地址和物理内存之间建立映射关系, 从而让 CPU 间接访问物理内存地址。通常将虚拟地址空间以512Byte ~ 8K作为一个单位,称为页,并从 0 开始依次对每一个页编号,这个大小通常被称为页面;将物理地址按照同样大小作为一个单位,称为框或块,也从 0 开始依次对每一个框编号。
内核维护此表,表中记录了每一对页和页框的映射关系,故此表称为页表:
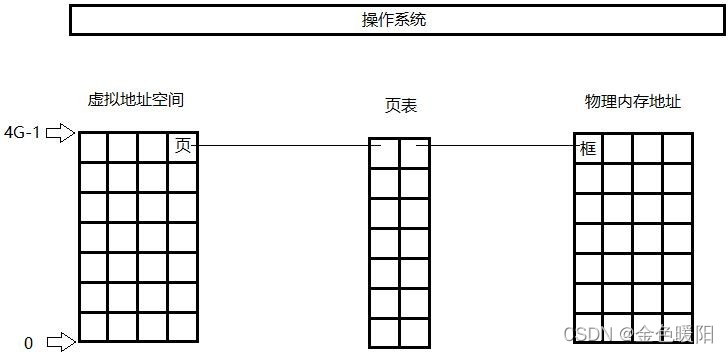
当 CPU 要访问一个虚拟地址空间对应的物理内存地址时,先将具体的虚拟地址 A/页面大小 4K,结果的商作为页表号,结果的余作为页内地址偏移:
例如: CPU 访问的虚拟地址:A
页面大小:L
页表号:(A/L)
页内偏移:(A%L)
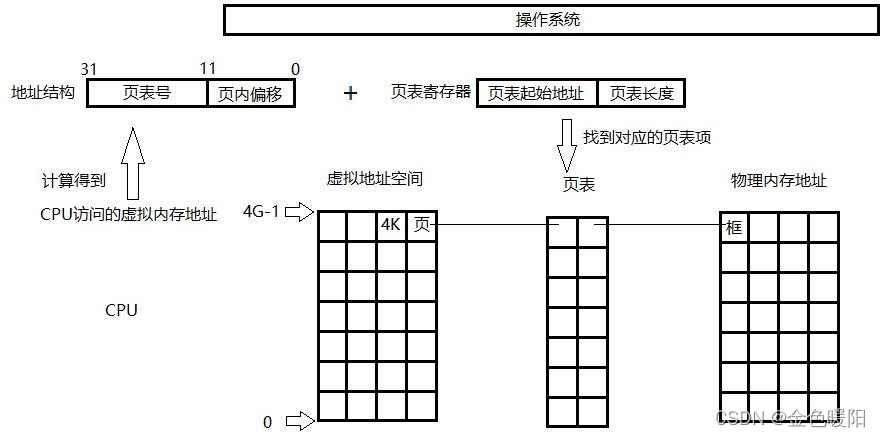
CPU 中有一个页表寄存器,里面存放着当前进程页表的起始地址和页表长度。将上述计算的页表号和页表长度进行对比,确认在页表范围内,然后将页表号和页表项长度相乘,得到目标页相对于页表基地址的偏移量,最后加上页表基地址偏移量就可以访问到相对应的框了,CPU 拿到框的起始地址之后,再把页内偏移地址加上,访问到最终的目标地址。如图:
注意,每个进程都有页表,页表起始地址和页表长度的信息在进程不被 CPU 执行的时候,存放在其 PCB(进程控制块)内。
按照上述的过程,可以发现,CPU 对内存的一次访问动作需要访问两次物理内存才能达到目的,第一次,拿到框的起始地址,第二次,访问最终物理地址,CPU 的效率变成了 50%。为了提高 CPU 对内存的访问效率,在 CPU 第一次访问内存之前,加了一个快速缓冲区寄存器,它里面存放了近期访问过的页表项。当 CPU 发起一次访问时,先到 TLB(页表缓存)中查询是否存在对应的页表项,如果有就直接返回了,整个过程只需要访问一次内存。如图:
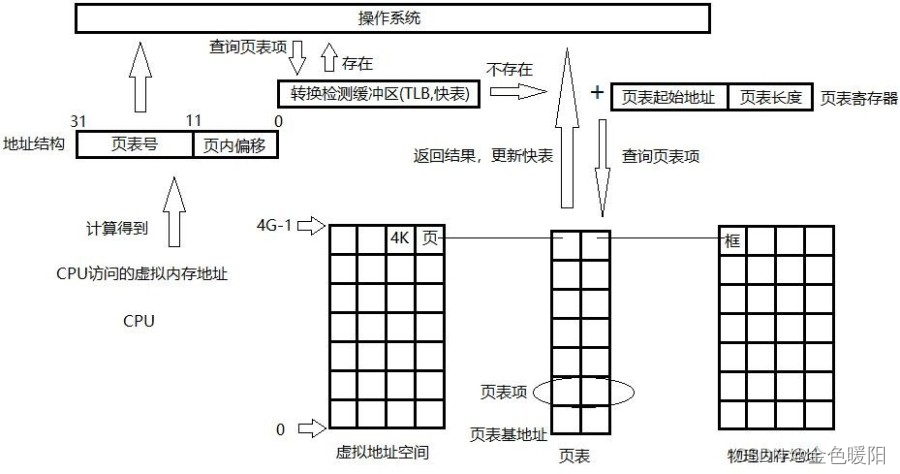
这种方式极大的提高了 CPU 对内存的访问效率。将近 90%。
然而这样的方式还是存在弊端:物理内存需要拿出至少 1M 的连续的内存空间来存放页表。可以通过多级页表的方式,将页表分为多个部分,分别存放,这样就不要求连续的整段内存,只需要多个连续的小段内存即可。 把连续的页表拆分成多个页表称之为一级页表,再创建一张页表,这张页表记录每一张一级页表的起始地址并按照顺序为其填写页表号。 通过这样的方式,CPU 从基地址寄存器中拿到了一级页表的地址,从地址结构中取出一级页表的页表号,找到二级页表的起始物理地址;然后结合地址结构中的中间 10 位(二级页表上的页表号),可以找到对应的框的起始地址,最后结合页内偏移量,就可以计算出最终目标的物理地址。如图:
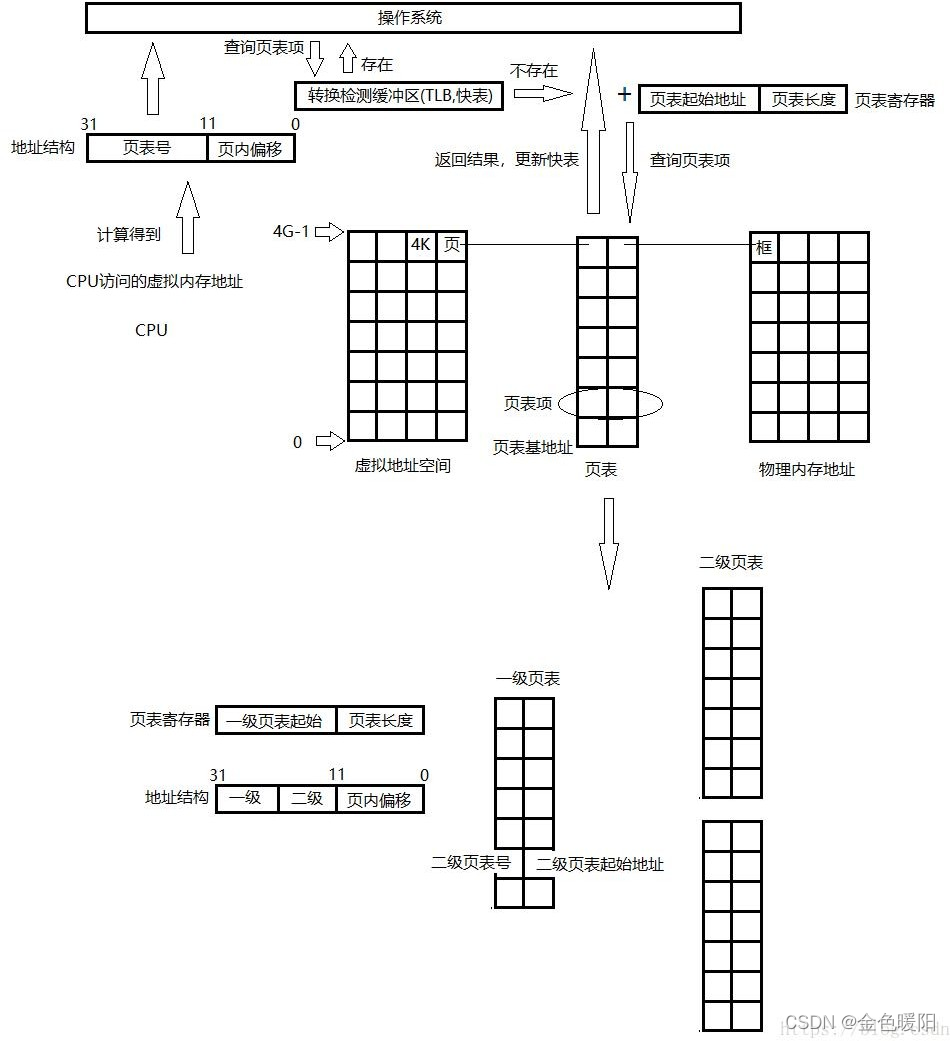
2、64 位系统
○ 64 位系统没有全部用完所有的地址空间,物理上只使用了 48 位,虚拟地址暂时使用 39 位;
○ 64 位系统,内核态和用户态的虚拟地址是相互分离的,由 2 个页表寄存器控制, 所以地址空间会重复;
○ 每页空间大小定为 4K Byte,即 12 位地址;
○ 采用 3 级页表,9 | 9 | 9 | 12 ;
3、32 位系统
○ 32 位系统所有的地址空间全部使用完,物理上使用了 32 位,虚拟地址也使用 32位;
○ 32 位系统,由于硬件的原因内核态和用户态的虚拟地址是统一编址的,2 个页表寄存器存储相同的页表地址,地址空间不能重复;
○ 每页空间大小定为 4K Byte,即 12 位地址;
○ 采用 2 级页表: 12 | 8 | 12 (32 - 12 = 20, 20 - 12 = 8);
○ 高端内存:由于在 32 位系统中,内核态只能访问 1G 的虚拟空间,而且对应关系是在物理内存的基础上将最高位置“1”的方式,所以如果内核想访问其他物理地址时,就临时借用高端内存的 128M 空间来建立映射到想访问的那段物理内存(即填充内核 PTE 页面表),用完后归还。如此其它程序也可借用这段地址空间访问其他物理内存,实现了使用有限的地址空间访问所有物理内存。
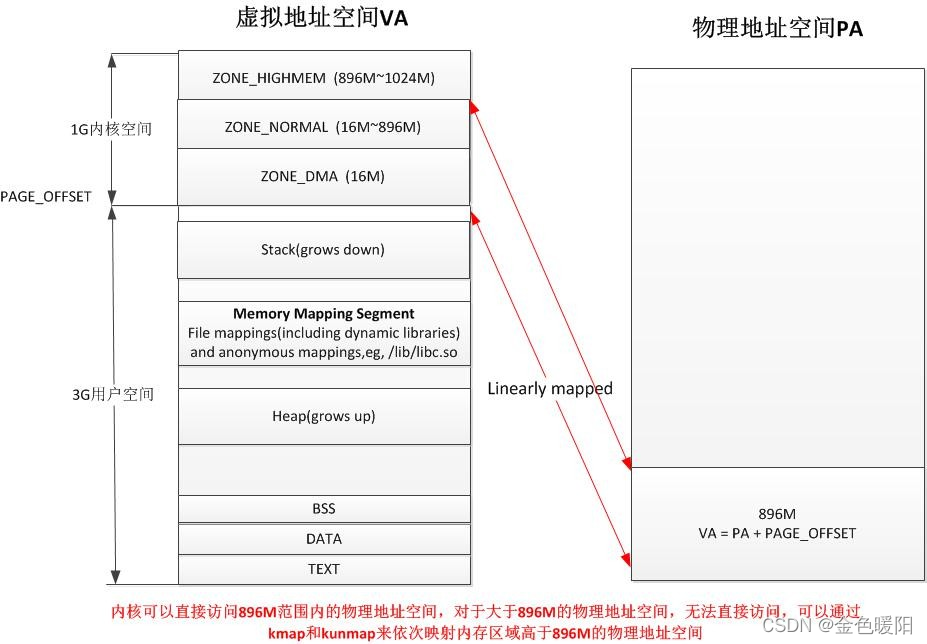
三、内存布局
1、Linux 内存布局
Linux 支持多种硬件体系结构,因此采用通用方法来描述内存,以方便对内存进行管理。为此,Linux 有了内存节点、分区、页框的概念:
○ 内存节点:主要依据 CPU 访问代价的不同而划分,分为不同的分区。内核以 struct
zone 来描述内存分区。通常一个节点分为 DMA、Normal 和 High Memory 内存区;
○ DMA 内存区:直接内存访问分区,通常为物理内存的起始16M。供外设使用,外设和内存直接访问数据而无需CPU参与;
○ Normal 内存区:从 16M 到 896M 内存区;
○ HighMemory 内存区:896M 以后的内存区;
四、内存分配管理
1、页级内存的分配与释放管理
页级内存管理能有效地完成以页大小为最小单位(粒度)的内存分配和回收工作,这样可以很好地与分页机制配合,提供有效分页管理。
-
页级内存管理概述
在动态分配内存时,存在很多限制,效率很低。在操作系统原理中,为了有效地分配内存,首先需要了解和跟踪空闲内存和分布情况,一般可采用位图(bit map)和双向链表两种方式跟踪内存使用情况:
● 位图方式:每个页对应位图区域的一个 bit,如果此位为 0,表示空闲,如果为 1,表示被占用。采用位图方式很省空间,但查找 n 个长度为 0 的位串的开销比较大;
● 双向链表方式:采用链表的方式记录内存使用情况,在查询或修改操作方面灵活性和效 率较高; -
双向链表内存管理
本文重点介绍双向链表方式。
假设整个物理内存的空闲空间以页为单位被一个双向链表管理起来,每个表项管理一个物理页。这需要设计某种算法来查找空闲页和回收空闲页。
常用的算法有:
● 首次适配(first fit)算法;
● 最佳适配(best fit)算法;
● 最差适配(worst fit)算法;
● 兄弟(buddy)算法; -
算法介绍
● 首次适配(first fit)算法的分配内存的设计思路是物理内存页管理器顺着双向链表进行搜索空闲内存区域,直到找到一个足够大的空闲区域,这是一种速度很快的算法,因为它尽可能少地搜索链表。如果空闲区域的大小和申请分配的大小正好一样,则把这个空 闲区域分配出去,成功返回;否则将该空闲区分为两部分,一部分区域与申请分配的大小相等,把它分配出去,剩下一部分区域形成新的空闲区。其释放内存的设计思路很简单,只需把这块区域重新放回双向链表中即可。
● 最佳适配(best fit)算法的设计思路是物理内存页管理器搜索整个双向链表(从开始到结束),找出能够满足申请分配的空间大小的最小空闲区域。找到这个区域后的处理及释放内存的处理与上面类似。最佳适配算法试图找出最接近实际需要的空闲区,名字上听起来很好,其实在查询速度上较慢,且较易产生多的内存碎片。
● 最差适配(worst fit)算法与最佳适配(best fit)算法的设计思路相反,物理内存页管理器搜索整个双向链表,找出能够满足申请分配的空间大小的最大空闲区域,使新的空闲区比较大从而可以继续使用。在实际效果上,查询速度上也较慢,产生内存碎片相对少些。
● buddy 算法的基本设计思想是:在 buddy 系统中,已占用内存空间和空闲内存空间大小均为 2 的 k 次幂(k 是正整数)。若申请 n 个页的内存空间,则实际可能分配的空
间大小为 2K 个页(2k-1<n<=2k)。若初始化时的空闲内存空间容量为 2m 个页,这空闲块的大小只可能是 20、21、…、2m 个页。
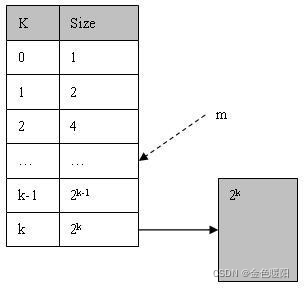
假定内存一开始是一个连续地址空间(大小为 2^k 个页)的大空闲块,且最小分配单位为 1 个页(4KB),则 buddy system 初始化时将生成一个长度为 k + 1 的可用空间表 List, 并将全部可用空间作为一个大小为 2^k 个页的空闲块 Bk 挂接在空闲块数组链表 List 的最后一个节点上, 如下图:
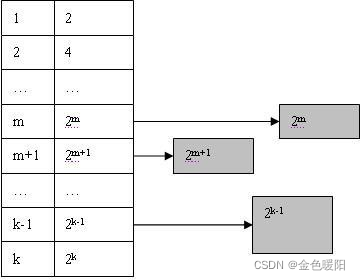
当其他子系统申请n 个字节的存储空间时, buddy system 分配的空闲块大小为 2^ m 个页,
m 满足条件:2^ (m-1) < n <= 2^ m;此时 buddy system 将在 list 中的 m 位置寻找可用的空闲块。初始化时 List 中这个位置为空, 于是 buddy system 就向上查找 m+1,…,直到达到 k 位置为止. 找到 k 位置后, 便得到可用空闲块 Bk, 此时 Bk 将分裂成两个大小为 2^(k-1)的空闲块 Bk-1a 和 Bk-1b, 并将其中一个插入到 List 中 k-1 位置, 同时对另外一个继续进行分裂. 如此以往直到得到两个大小为 2^m 个页的块为止,并把其中一个空闲块分配给需求方。此时的内存如下图所示:

如果buddy system 在运行一段时间之后, List 中某个位置t可能会出现多个块, 则将其他块依次链至可用块链表的末尾。当 buddy system要在t位置取可用块时, 直接从链表头取一个即可。
当一个存储块被释放时, buddy system 将把此内存块回收到空闲块链表 List 中。此时 buddy system 系统将根据此存储块的大小计算出其在List 中的位置, 然后插入到空闲块链表的末尾。在这一步完成后, 系统立即开始合并尝试操作,该操作是将地址相邻且大小相等的空闲块(简称 buddy,即”伙伴”空闲块)合并到一起, 形成一个更大的空闲块,并重新放到空闲块链表 List 的对应位置中, 并继续对更大的块进行合并, 直到无法合并为止。
2、支持任意大小内存分配
有效地完成比页更小单位(粒度)的内存分配和回收工作,以适应程序的需求。
-
任意大小内存分配概述
操作系统实际运行过程中,还有诸多小于一页的任意大小内存动态申请需求,则以页为最小单位就无法适应这类需求了。当然,我们可以直接把物理内存页管理器改为粒度 为1字节的物理内存管理器,但存在两个问题:
● 由于页目录表和页表的大小是 4KB,且一个页表项管理的内存空间大小也是 4KB,故需要扩展新的函数和结构匹配对页表的管理支持,导致代码复杂;
● 即使采用上述 4 种内存分配算法,在支持任意大小的内存分配请求上,依然存在效率不高,有外碎片和内碎片等问题。
所以,一个更加合理的办法是在物理内存页管理器的基础之上建立一个支持任意大小的内存 分配管理器,形成二级内存管理,满足高效支持任意大小的内存分配请求。这就对动态内存分配管理提出了新的挑战,即花尽量少的时间完成对内存的分配和回收,且保证能够产生的内外碎片尽量小,由此引入 slab 算法。 -
slab 算法概述
slab 算法的基本思路有两个:
○ 通过缓存实现“对象”重用,
○ 在一个连续页空间放同样类型的“对象”;
Jeff Bonwick 在 SUN OS 内核中观察到内核在运行时会为有限的对象集(内核中各种常见的数据结构)分配大量内存,且对内核中这些数据结构进行初始化所需的时间超过了对其进行分配和释放所需的时间。因此他的结论是不应该将内存释放回一个全局的空闲内存池,而是将内存保持为针对特定目标而初始化的状态。例如,如果内存被分配给了一个变量,那么只需在为此变量首次分配内存时执行一次变量初始化函数即可,当该变量被回收并进一步被后续分配时就不需要执行这个初始化函数,因为从上次释放和调用析构之后,它已经处于所需的状态中了。在一个连续地址空间放同样类型的“对象”有助于快速查找和修改同样类型的
“对象”,提高分配的时间效率,并减少碎片。
- slab 算法的简化设计实现
数据结构描述
slab 算法采用了两层数据组织结构。在最高层是 slab_cache,这是一个不同大小 slab 缓存的链接列表数组。slab_cache 的每个数组元素都是一个管理和存储给定大小的空闲对象
(obj)的 slab 结构链表,这样每个 slab 设定一个要管理的给定大小的对象池,占用物理空间连续的 1 个或多个物理页。slab_cache 的每个数组元素管理两种 slab 列表:
● slabs_full:完全分配的 slab
● slabs_notfull:部分分配的 slab
注意 slabs_notfull 列表中的 slab 是可以进行回收(reaping),使得 slab 所使用的内存可被返回给操作系统供其他子系统使用。
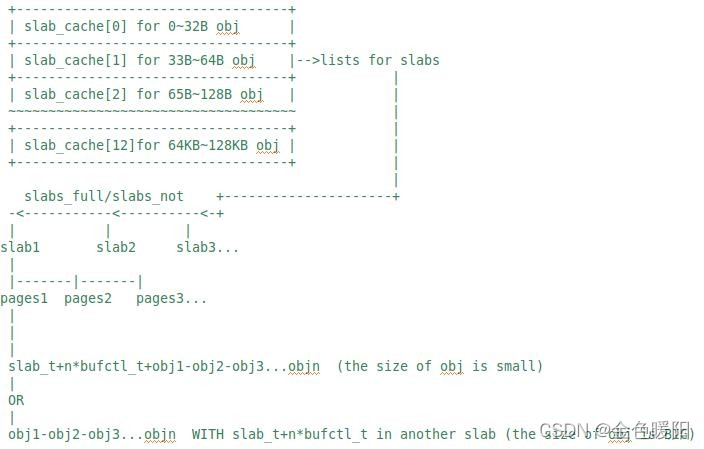
slab 列表中的每个 slab 都是一个连续的内存块(一个或多个连续页),它们被划分成一个个 obj。这些 obj 是中进行分配和释放的基本元素。由于对象是从 slab 中进行分配和释放的, 因此单个 slab 可以在 slab 链表之间进行移动。例如,当一个 slab 中的所有对象都被使用完时,就从 slabs_notfull 链表中移动到 slabs_full 链表中。当一个 slab 完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到 slabs_notfull 列表中。
分配与释放内存实现描述
现在来看一下能够创建新 slab 缓存、向缓存中增加内存、销毁缓存的接口以及 slab 中对对象进行分配和释放操作的 slab 相关操作过程和函数。
第一个步骤是通过执行 slab_init 函数初始化 slab_cache 缓存结构。然后其他 slab 缓存函数将使用该引用进行内存分配与释放等操作。常用的内存管理函数是 kmalloc 和kfree 函数。这两个函数的原型如下:
void *kmalloc( size_t size ); void kfree(void *objp );
在分配任意大小的空闲块时,kmalloc 通过调用kmem_cache_alloc 函数来遍历对应size 的slab,来查找可以满足大小限制的缓存。如果 kmem_cache_alloc 函数发现 slab 中有空闲的 obj,则分配这个对象;如果没有空闲的 obj 了,则调用 kmem_cache_grow 函数分配包含 1 到多页组成的空闲 slab , 然后继续分配。 要使用 kfree 释放对象时, 通过进一步调用kmem_cache_free 把分配对象返回到 slab 中,并标记为空闲,建立空闲 obj 之间的链接关系。
五、虚拟内存管理
1、概述
有了页表的支持,我们可以使得不同用户态程序的内存空间之间无法访问,达到隔离和保护的作用。但页表若仅仅只支持此功能就太大材小用了,还可以通过页表实现更多的功能:
● 内存共享:把两个虚拟地址空间通过页表映射到同一物理地址空间;
● 提供超过物理内存大小的虚拟内存空间:其基本思想是在内存中放置最常用的一些数据,不常用的数据会被放到硬盘上,让用户态软件认为数据都在内存中;
● 按需分配内存:用户态软件在运行时要求操作系统提供很大的内存,操作系统“表面上” 表示满足用户需求,但在背后并没有实际分配对应的物理内存空间。等到用户态软件实际执行到对这些内存的访问时,产生访存异常。操作系统的异常中断处理例程再从系统管理的空闲空间中分配一页或几页物理内存给用户态软件,并让用户态软件重新执行产生访存异常的那条指令;
为了高效地完成上述三件事情,操作系统需要考虑应该把哪些不常用的内存换出到硬盘 上去,这就是内存的页替换算法,常见的有:
● LRU 算法;
● Clock 算法;
● 二次机会法等;
而在实现上,由于涉及异常处理和硬盘管理等,虚存管理在整个操作系统实现中的复杂度最大。
2、原理
以下三种内存管理技术给了程序员更大的内存“空间”,我们称为内存空间虚拟化:
● 通过内存地址虚拟化,可以使得软件在没有访问某虚拟内存地址时不分配具体的物理内 存,而只有在实际访问某虚拟内存地址时再动态地分配物理内存,建立虚拟内存到物理内存的页映射关系,这种技术属于 lazy load 技术,简称按需分页(demandpaging);
● 把不经常访问的数据所占的内存空间临时写到硬盘上,这样可以腾出更多的空闲内存空 间给经常访问的数据;当 CPU 访问到不经常访问的数据时,再把这些数据从硬盘读入到内存中,这种技术称为页换入换出(page swap in/out);
● 两个虚拟页的数据内容相同时,可只分配一个物理页框,这样如果对两个虚拟页的访问方式是只读方式,这这两个虚拟页可共享页框,节省内存空间;如果 CPU 对其中之一的虚拟页进行写操作,则这两个虚拟页的数据内容会不同,需要分配一个新的物理页框, 并将物理页框标记为可写,这样两个虚拟页面将映射到不同的物理页帧,确保整个内存空间的正确访问。这种技术称为写时复制(Copy On Write,简称 COW);
在实现上述三种技术时,需要解决的一个关键问题是,何时进行请求调页/页换入换出/ 写时复制处理?其实,在程序的执行过程中由于某种原因(页框不存在/写只读页等)而使CPU无法最终访问到相应的物理内存单元,即无法完成从虚拟地址到物理地址映射时,CPU产生一次缺页异常,从而需要进行相应的缺页异常服务例程。这个缺页异常处理的时机就是求调页/页换入换出/写时复制处理的执行时机,当相关处理完成后,缺页异常服务例程会 返回到产生异常的指令处重新执行,使得软件可以继续正常运行下去。
3、缺页异常处理
当启动分页机制以后,如果一条指令或数据的虚拟地址所对应的物理页框不在内存中或访问的类型有错误(比如写一个只读页或用户态程序访问内核态的数据等),就会发生缺页异常。
产生页面异常的原因主要有:
○ 目标页面不存在(页表项全为 0,即该线性地址与物理地址尚未建立映射或者已经撤销);
○ 相应的物理页面不在内存中(页表项非空,但 Present 标志位=0,比如在 swap 分区或磁盘文件上),这将在下面介绍换页机制实现时进一步讲解如何处理;
○ 访问权限不符合(此时页表项 P 标志=1,比如企图写只读页面);
当出现上面情况之一,那么就会产生页面page fault异常。产生缺页异常后,CPU硬件和软件都会做一些事情来应对此事。首先缺页异常也是一种异常,所以针对一般异常的硬件处理操作是必须要做的,即 CPU在当前内核栈保存当前被打断的程序现场; 其次开始执行中断服务例程。接下来,在 trap.c 的 trap 函数开始了中断服务例程的处理流程,大致调用关系为:
trap–> trap_dispatch–>pgfault_handler–>do_pgfault
下面需要具体分析一下 do_pgfault 函数,以 x86 处理器为例:
○ CPU 把引起缺页异常的虚拟地址装到寄存器 CR2 中,并给出了出错码(tf->tf_err), 指示引起缺页异常的存储器访问的类型;
○ 中断服务例程会调用缺页异常处理函数 do_pgfault 进行具体处理;
○ 缺页异常处理是实现按需分页、swap in/out 和写时复制的关键之处;
后面的小节将分别展开讲述。
do_pgfault 函数是完成缺页异常处理的主要函数,它根据从 CPU 的控制寄存器 CR2 中获取的缺页异常的虚拟地址以及根据 error code 的错误类型来查找此虚拟地址是否在某个VMA 的地址范围内以及是否满足正确的读写权限,如果在此范围内并且权限也正确即认为这是一次合法访问,但没有建立虚实对应关系。所以需要分配一个空闲的内存页,并修改页表完成虚地址到物理地址的映射,刷新 TLB,然后调用 iret 中断,返回到产生缺页异常的指令处重新执行此指令。如果该虚地址不再某 VMA 范围内,这认为是一次非法访问。
【注意】
地址空间的管理由虚存管理和页表管理两部分组成:虚拟内存管理和页表维护。
虚存管理限制了(程序)地址空间的范围以及权限,而页表维护的是实际使用的地址空 间以及权限,后者不能比前者有更大的范围或者权限,因为前者是实际管理页表的:
○ 比如权限,虚存管理可以规定地址空间的某个范围是可写的,但是页表中却可以标记是 read-only 的(比如 copy-on-write 的实现),这种冲突可以被内核(通过硬件异常)轻易的捕获到,并进行相应的处理;
○ 反过来,如果页表权限比虚存规定的权限更大,内核是没有办法发现这种冲突的。 由于虚存管理的存在,内核才能方便的实现更复杂和丰富的操作,比如 share memory、swap 等。
在后续的实验中还会遇到虚存管理只维护用户地址空间(也就是 [USERBASE, USERTOP)
区间)的情况,因为内核地址空间包括虚存和页表都是固定的。
4、页面置换算法
由于系统给用户态的应用程序提供了一个虚拟的“大容量”内存空间,而实际的物理内存空间又没有那么大,所以系统就“瞒着”应用程序,只把应用程序中“常用” 的数据和代码放在物理内存中,而不常用的数据和代码放在了硬盘这样的存储介质上。
一个好的页面置换算法会导致缺页异常次数少,也就意味着访问硬盘的次数也少,从而使得应用程序执行效率就高。
常用页面置换算法:
○ 最优 (Optimal) 页面置换算法:由 Belady 于 1966 年提出的一种理论上的算法。其所选择的被淘汰页面,将是以后永不使用的或许是在最长的未来时间内不再被访问的页面。采用最佳置换算法,通常可保证获得最低的缺页率。但由于操作系统其实无法预知一个应用程序在执行过程中访问到的若干页中哪一页是未来最长时间内不再被访问的,因而该算法是无法实际实现,但可以此算法作为上限来评价其它的页面置换算法。
○ 先进先出(First In First Out, FIFO)页面置换算法:该算法总是淘汰最先进入内存的页, 即选择在内存中驻留时间最久的页予以淘汰。只需把一个应用程序在执行过程中已调入内存的页按先后次序链接成一个队列,队列头指向内存中驻留时间最久的页, 队列尾指向最近被调入内存的页。这样需要淘汰页时,从队列头很容易查找到需要淘汰的页。FIFO 算法只是在应用程序按线性顺序访问地址空间时效果才好,否则效率不高。因为那些常被访问的页,往往在内存中也停留得最久,结果它们因变“老” 而不得不被置换出去。FIFO 算法的另一个缺点是,它有一种异常现象(Belady 现象),即在增加放置页的页帧的情况下,反而使缺页异常次数增多。
○ 二次机会(Second Chance)页面置换算法:为了克服 FIFO 算法的缺点,人们对它进行了改进。此算法在页表项(PTE)中设置了一位访问位来表示此页表项对应的页当前是否被访问过。当该页被访问时,CPU 中的 MMU 硬件将把访问位置“1”。当需要找到一个页淘汰时,对于最“老”的那个页面,操作系统去检查它的访问位。 如果访问位是 0,说明这个页面老且无用,应该立刻淘汰出局;如果访问位是 1, 这说明该页面曾经被访问过,因此就再给它一次机会。具体来说,先把访问位位清零,然后把这个页面放到队列的尾端,并修改它的装入时间,就好像它刚刚进入系统一样,然后继续往下搜索。二次机会算法的实质就是寻找一个比较古老的、而且从上一次缺页异常以来尚未被访问的页面。如果所有的页面都被访问过了,它就退化为纯粹的 FIFO 算法。
○ LRU(Least Recently Used,LRU)页面置换算法: FIFO 置换算法性能之所以较差,是因为它所依据的条件是各个页调入内存的时间,而页调入的先后顺序并不能反映页 是否“常用”的使用情况。最近最久未使用(LRU)置换算法,是根据页调入内存 后的使用情况进行决策页是否“常用”。由于无法预测各页面将来的使用情况,只 能利用“最近的过去”作为“最近的将来”的近似,因此,LRU 置换算法是选择最近最久未使用的页予以淘汰。该算法赋予每个页一个访问字段,用来记录一个页面 自上次被访问以来所经历的时间 t,,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最久未使用的页面予以淘汰。
○ 时钟(Clock)页面置换算法:也称最近未使用 (Not Used Recently, NUR) 页面置换算法。虽然二次机会算法是一个较合理的算法,但它经常需要在链表中移动页面, 这样做既降低了效率,又是不必要的。一个更好的办法是把各个页面组织成环形链表的形式,类似于一个钟的表面。然后把一个指针指向最古老的那个页面,或者说, 最先进来的那个页面。时钟算法和第二次机会算法的功能是完全一样的,只是在具体实现上有所不同。时钟算法需要在页表项(PTE)中设置了一位访问位来表示此页表项对应的页当前是否被访问过。当该页被访问时,CPU 中的 MMU 硬件将把访问位置“1”。然后将内存中所有的页都通过指针链接起来并形成一个循环队列。初始时,设置一个当前指针指向某页(比如最古老的那个页面)。操作系统需要淘汰页时,对当前指针指向的页所对应的页表项进行查询,如果访问位为“0”,则淘汰该页,把它换出到硬盘上;如果访问位为“1”,这将该页表项的此位置“0”,继续访问下一个页。该算法近似地体现了 LRU 的思想,且易于实现,开销少。但该算法需要硬件支持来设置访问位,且该算法在本质上与 FIFO 算法是类似的,惟一不同的是在 clock 算法中跳过了访问位为 1 的页。
○ 改进的时钟(Enhanced Clock)页面置换算法:在时钟置换算法中,淘汰一个页面时只考虑了页面是否被访问过,但在实际情况中,还应考虑被淘汰的页面是否被修 改过。因为淘汰修改过的页面还需要写回硬盘,使得其置换代价大于未修改过的页 面。改进的时钟置换算法除了考虑页面的访问情况,还需考虑页面的修改情况。即 该算法不但希望淘汰的页面是最近未使用的页,而且还希望被淘汰的页是在主存驻
留期间其页面内容未被修改过的。这需要为每一页的对应页表项内容中增加一位引用位和一位修改位。当该页被访问时,CPU 中的 MMU 硬件将把访问位置“1”。当该页被“写”时,CPU 中的 MMU 硬件将把修改位置“1”。这样这两位就存在四种可能的组合情况:(0,0)表示最近未被引用也未被修改,首先选择此页淘汰;
(0,1)最近未被使用,但被修改,其次选择;(1,0)最近使用而未修改,再次 选择;(1,1)最近使用且修改,最后选择。该算法与时钟算法相比,可进一步减少磁盘的 I/O 操作次数,但为了查找到一个尽可能适合淘汰的页面,可能需要经过多次扫描,增加了算法本身的执行开销。
5、页面置换机制实现
如果要实现页面置换机制,只考虑页面置换算法的设计与实现是远远不够的,还需考虑 其他问题:
○ 哪些页可以被换出?
○ 一个虚拟的页如何与硬盘上的扇区建立对应关系?
○ 何时进行换入和换出操作?
○ 如何设计数据结构已支持页面置换算法?
○ 如何完成页的换入换出操作?
可以被换出的页
在操作系统的设计中,一个基本的原则是:并非所有的物理页都可以交换出去的,只有 映射到用户空间且被用户程序直接访问的页面才能被交换,而被内核直接使用的内核空间的 页面不能被换出。这里面的原因是什么呢?操作系统是执行的关键代码,需要保证运行的高 效性和实时性,如果在操作系统执行过程中,发生了缺页现象,则操作系统不得不等很长时 间(硬盘的访问速度比内存的访问速度慢 2~3 个数量级),这将导致整个系统运行低效。而且,不难想象,处理缺页过程所用到的内核代码或者数据如果被换出,整个内核都面临崩溃 的危险。
但在 proj8 实现的 ucore 中,我们只是实现了换入换出机制,还没有设计用户态执行的程序,所以我们在 proj8 中仅仅通过执行 check_swap 函数在内核中分配一些页,模拟对这些页的访问,然后直接调用 page_launder 函数来查询这些页的访问情况并执行页面置换算法换出“不常用”的页到磁盘上。
虚存中的页与硬盘上的扇区之间的映射关系
如果一个页被置换到了硬盘上,那操作系统如何能简捷来表示这种情况呢?在 ucore 的设计上,充分利用了页表中的 PTE 来表示这种情况:当一个 PTE 用来描述一般意义上的物理页时,显然它应该维护各种权限和映射关系,以及应该有 PTE_P 标记;但当它用来描述一个被置换出去的物理页时,它被用来维护该物理页与 swap 磁盘上扇区的映射关系,并且该 PTE 不应该由 MMU 将它解释成物理页映射(即没有 PTE_P 标记),与此同时对应的权限则交由 mm_struct 来维护,当对位于该页的内存地址进行访问的时候,必然导致 #PF, 然后内核能够根据 PTE 描述的 swap 项将相应的物理页重新建立起来,并根据虚存所描述的权限重新设置好 PTE 使得内存访问能够继续正常进行。
如果一个页(4KB/页)被置换到了硬盘某 8 个扇区(0.5KB/扇区),该 PTE 的最低位—present 位应该为 0 (没有 PTE_P 标记),接下来的 7 位暂时保留,可以用作各种扩展;而原来用
来表示页帧号的高 24 位地址,恰好可以用来表示此页在硬盘上的起始扇区的位置(其从第几个扇区开始)。为了在页表项中区别 0 和 swap 分区的映射,将 swap 分区的一个 page 空出来不用,也就是说一个高 24 位不为 0,而最低位为 0 的 PTE 表示了一个放在硬盘上的页的起始扇区号(见 swap.h 中对 swap_entry_t 的描述):
swap_entry_t
| offset | reserved | 0 |
24 bits 7 bits 1 bit
考虑到硬盘的最小访问单位是一个扇区,而一个扇区的大小为 512(2^8)字节,所以需要 8
个连续扇区才能放置一个 4KB 的页。
在 ucore 中,用了第二个 IDE 硬盘来保存被换出的扇区,根据 proj8 的输出信息
“ide 1: 262144(sectors), ‘QEMU HARDDISK’.”
我们可以知道 proj8 可以保存 262144/8=32768 个页,即 128MB 的内存空间。swap 分区的大小是 swapfs_init 里面根据磁盘驱动的接口计算出来的,目前 ucore 里面要求 swap 磁盘至少包含 1000 个 page,并且至多能使用 1<<24 个 page。
swap.c 中维护了全局的 mem_map 表,用来记录 swap 分区的使用,它会在 swap_init 里面根据 swap 分区的大小进行适当的初始化。表中的每一项是一个 unsigned short 类型的整数,用来记录该 entry 的引用计数。ucore 使用一个非常大的整数 0xFFFF 表示一个 entry
(这里 entry 指 swap 分区上连续的 8 个扇区)是空闲的(没有被分配出去),并用 0xFFFE 表示一个 entry 的最大引用计数,通常一个页不会有这么大的引用计数,除非内核崩了。当一个 entry 的引用计数 是 0 的时候,表示该 entry 是可以被回收的,但是我们通常不是真的去回收他,只有当需要分配一个 entry,并且在 mem_map 里面实在找不到空闲的
entry 的时候才会去回收一个引用计数为 0 的 entry。因为一个引用计数为 0 的页很可能上面的数据和对应物理页上的数据一致,这样在换出该页的时候就可以避免写磁盘的代价, 而和写磁盘比起来,遍历 mem_map 数组的时间开销总是会小很多。
此外,为了简化实现,swap 只对页表中的数据页进行换出,即只对 PTE 进行操作,而第二级页表是保留不动的。
执行换入换出的时机
check_mm_struct 是在 lab2 里面用来做模块测试时使用的临时的 mm_struct。在 lab3 以后就没有用处了。在 proj8 中, check_mm_struct 变量这个数据结构表示了目前 ucore 认为合法的所有虚拟内存空间集合,而 mm 中的每个 vma 表示了一段地址连续的合法虚拟空间。当 ucore 或应用程序访问地址所在的页不在内存时,就会产生#PF 异常,引起调用
do_pgfault 函数,此函数会判断产生访问异常的地址属于 check_mm_struct 某个 vma 表示的合法虚拟地址空间,且保存在硬盘 swap 文件中(即对应的 PTE 的高 24 位不为 0,而最低位为 0),则是执行页换入的时机,将调用 swap_in_page 函数完成页面换入。
换出页面的时机相对复杂一些,针对不同的策略有不同的时机。
ucore 目前大致有两种策略,
○ 积极换出策略
○ 消极换出策略
积极换出策略是指操作系统周期性地(或在系统不忙的时候)主动把某些认为“不常用”
的页换出到硬盘上,从而确保系统中总有一定数量的空闲页存在,这样当需要空闲页时,基 本上能够及时满足需求;
消极换出策略是指,只是当试图得到空闲页时,发现当前没有空闲的物理页可供分配, 这时才开始查找“不常用”页面,并把一个或多个这样的页换出到硬盘上。
在 proj8 中,可支持上述两种情况,但都需要到 lab3/proj11 中才会完整实现。对于第一种积极换出策略,即创建了一个每隔 1 秒执行一次的内核线程 kswapd(在 lab3 的 proj11 中第一次出现),实现积极的换出策略。对于第二种消极的换出策略,则是在 ucore 调用
alloc_pages 函数获取空闲页时,此函数如果发现无法从页分配器(比如 buddy system)获得空闲页,就会进一步调用 try_free_pages 来唤醒线程 kswapd,并将 cpu 让给 kswapd 使得换出某些页,实现一种消极的换出策略。
页面置换算法的数据结构设计
到 proj7 为止,我们知道目前表示内存中物理页使用情况的变量是基于数据结构 Page 的全局变量 pages 数组,pages 的每一项表示了计算机系统中一个物理页的使用情况。为了表示物理页可被换出或已被换出的情况,可对 Page 数据结构进行扩展:
struct Page {
uint32_t flags; // array of flags that describe the status of the page frame swap_entry_t index; // stores a swapped-out page identifier
list_entry_t swap_link; // swap hash link
……
};
首先 flag 的含义做了扩展:
// the page is in the active or inactive page list (and swap hash table) #define PG_swap 4
// the page is in the active page list #define PG_active 5
前面提到 swap.c 里面声明了全局的 mem_map 数据结构,用来存储 swap 分区上的页的使用计数。除此之外,swap.c 里还声明了两个链表:
○ active_list;
○ inactive_list;
分别表示已经分配了 swap entry 的且处于“活跃”状态/“不活跃”状态的物理页链表。所有已经分配了 swap entry 的 page 必须处于两个链表中的一个。
当一个物理页 (struct Page) 需要被 swap 出去的时候,首先需要确保它已经分配了一个 swap entry。如果 page 数据结构的 flags 设置了 PG_swap 为 1,则表示该 page 中的
index 是有效的 swap entry 的索引值,从而该物理页上的数据可以被写出到 index 所表示的 swap page 上去。
如果一个物理页在硬盘上有一个页备份,则需要记录在硬盘中页备份的位置。Page 结构中的 index 就起到这个记录的作用,它保存了被换出的页的页表项 PTE 高 24 位的内容—
entry,即硬盘中对应页备份的起始扇区位置值(以字节为单位???)。
Page 结构中的 swap_link 保存了以 entry 为 hash 索引的链表项,这样根据 entry,就可以快速的对 page 数据结构进行查找。但 hash 数组在哪里呢?
对于在硬盘上有页备份的物理页(简称 swap_page),需要统一管理起来,为此在 proj8
中增加了全局变量:
static list_entry_t hash_list[HASH_LIST_SIZE];
hashlist 数组就是我们需要的 hash 数组,根据 index(swap entry) 索引全部的 swap page 的指针,这样通过 hash 函数
#define entry_hashfn(x) (hash32(x, HASH_SHIFT))
可以快速地根据 entry 找到对应的 page 数据结构。
正如页替换算法描述的那样,把“常用”的可被换出页和“不常用”的可被换出页分别 集中管理起来,形成 active_list 和 inactive_list 两个链表。 ucore 的页面置换算法会根据相应的准则把它认为“常用”的物理页放到 active_list 链表中,而把它认为“不常用”的物理页放到 inactive_list 链表中。一个标记了 PG_swap 的页总是需要在这两个链表之间移动。前面介绍过 mem_map 数组,他是用来记录 swap_page 的引用次数的。因为 swap 分区上的 page 实际上是某个物理页的数据备份。所以,一个物理页 page 的 page_ref 与 对应
swap_page 的 mem_map[offset] (offset = swap_offset(entry)) 值的和是这个数据页的真实引用计数。page_ref 表示 PTE 对该物理页的映射的个数;mem_map 表示 PTE 对该 swap 备份页的 映射个数。当 page_ref 为 0 的时候,表示物理页可以被回收;当 mem_map[offset] 为 0 的时候,表示 swap page 可以被回收(前面介绍过,可以回收,但是在万不得已的情况下才真的回收)。在后面的实验中还可能涉及到,这里只是简单了解一下。
【注意】
ucore 目前使用的 PIO 的方式读写 IDE 磁盘,这样的好处是,磁盘读入、写出操作可以认为是同步的,即当前 CPU 需要等待磁盘读写完毕后再进行进一步的工作。由于磁盘操作相对 CPU 的速度而言是很慢的,这使得会浪费大量的 CPU 时间在等 IO 操作上。于是我 们总是希望能够在 IO 性能上有更大的提升,比如引入 DMA 这种异步的 IO 机制,为了避免后续开发上的各种不便和冲突,我们假设所有的磁盘操作都是异步的(也包括后面的实验),即使目前是通过 PIO 完成的。
假定某 page 的 flags 中的 PG_swap 标志位为 1,并且 PG_active 标志位也为 1,则表示该 page 在 swap 的 active_list 中,否则在 inactive_list 中。 active_list 中的页表示活跃的物理页,即页表中可能存在多个 PTE 指向该物理页(这里可以是同一个页表中的多个
entry,在后面 lab3 的实验里面有了进程以后,也可以是多个进程的页表的多个 entry);反过来,inactive_list 链表所链接的 page 通常是指没有 PTE 再指向的页。
【注意】
需要强调两点设计因素:
○ 一个 page 是在 active_list 还是在 inactive_list 的条件不是绝对的;
○ 只有 inactive_list 上的页才会被尝试换出;
这两个设计因素的设计起因如下:
我们知道一个 page 换出的代价是很大的(磁盘操作),并且我们假设所有的磁盘操作都是异步的,那么换出一个 active 的页就变得非常不值得。因为在还有多个 PTE 指向他情况下进行换出操作(异步 IO 可能导致进程切换)的较长过程中,这个页可以随时被其它进程写脏。而硬件提供给内核的接口(即页表项 PTE 的 dirty 位)使得内核只能知道一个页是否是脏的(不能明确知道一个页的哪个部分是脏的),当这种情况发生时,就导致了一次无 效的写出。
active_list 和 inactive_list 的维护只能由 与 swap 有关的集中操作来完成。特别是在
lab3/proj11 引入 kswapd 内核线程之后,所有的内存页换出任务都交给 kswapd,这样减少了复杂的同步互斥实现(在 lab5 中会重点涉及)。
页面换入换出有关的操作需要做的就是尽可能的完成如下三件事情:
○ 将 PG_swap 为 0 的页转变成 PG_swap 为 1 的页。即尽可能的给每个物理页分配一个 swap entry(当然前提是有足够大的 swap 分区);
○ 将页从 active_list 上移动到 inactive_list 上。如果一个页还在 active_list 上,说明还有 PTE 指向此“活跃”的物理页。所以需要在完成内存页换出时断开对这些物理页的引用,把它变成不活跃的(inactive)。只有把所有的 PTE 对某 page 的引用都断开(即 page 的 page_ref 为 0)后,就可以将此 page 从 active_list 移动到inactive_list 上;
○ 将 inactive_list 上的页写出并释放掉。inactive_list 上的 page 表示已没有 PTE 指向此 page 了,那么该 page 可以被释放,如果该 page 被写过,那还需把此 page 换出到 swap 分区上。如果在整个换出过程(异步 IO)中没有其他进程再写这个物理页(即没有 PTE 在引用它或有 PTE 引用但页没有写脏),就认为这个物理页是可以安全释放的了。那么将它从 inactive_list 上取下,并调用 page_free 函数 实现
page 的回收;
值得注意的是,内存页换出操作只有特定时候才被调用,即通过 执行 try_free_pages 函数或者定时器机制(在 lab3/proj10.4 才引入)定期唤醒 kswapd 内核线程。这样会导致内存页换出操作对两个链表上的数据都不够敏感。比如处于 active_list 上的 page,可能在
kswapd 工作的时候,已经没有 PTE 再引用它了;再如相应的进程退出了,并且相应的地址空间已经被内核回收,从而变成了一个 inactive 的 page;还存在 inactive_list 上的 page 也可能在换出的时候,其它进程通过 page fault,又将 PTE 指向他,进而变成一个实际上 active的页。所以说,active 和 inactive 条件并不绝对。
页面置换算法的执行逻辑
其实在 proj8 中并没有完全实现页面置换算法,只是实现了其中的部分关键函数,并通过 check_swap 来验证了这些函数的正确性。直到 lab3 的 proj11 才形成了完整的页面置换逻辑,而这个页面置换逻辑基本上是改进的时钟算法的一个实际扩展版本。
ucore 采用的页面置换算法是一个全局的页面置换算法:
○ 因为它收集了 ucore 中所有用户态进程(这里可理解为 ucore 中运行的每个用户态程序)的可换出页,并把这些可换出页中的一部分转换为空闲页;
○ 其次它考虑了页的访问情况(根据 PTE 中 PTE_A 位的值)和读写情况(根据 PTE
中 PTE_D 位的值):
■ 如果页被访问过,则把 PTE_A 位清零继续找下一页;
■ 如果页没有被访问过,这此页就成为了 active 状态的可换出页,并放入
active_list 链表中,这时需要把对应的 PTE 转换成为一个 swap entry(高 24 位保存为硬盘缓存页的起始扇区号,PTE_P 位清零);接着 refill_inactive_scan 函数会把处于 active 状态的部分可换出页转换成 inactive 状态,并放入 inactive_list 链表中;然后 page_launder 函数扫描 inactive_list 中的处于 inactive 状态的可换出页;
■ 如果此页不是 dirty 的,则把它直接转换成空闲页;
■ 如果此页是 dirty 的,则执行换出操作,把该页换出到硬盘上保存。这个页的状态变化图如下图所示:
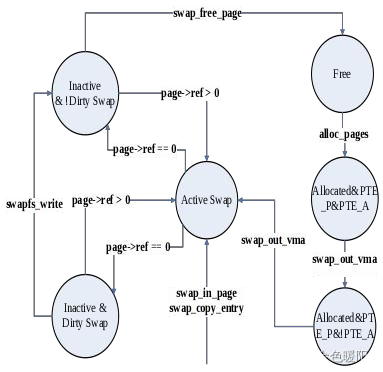
ucore 的物理页状态变化图
下面具体讲述一下proj11 中实现上述置换算法的页面置换逻辑
在 proj11 中同时实现了积极换出策略和消极换出策略,这都是通过在不同的时机执行
kwapd_main 函数来完成的。
● 当 ucore 调用 alloc_pages 函数以获取空闲页,但物理页内存分配器无法满足请求时, alloc_pages 函数将调用 tre_free_pages 来执行 kwapd_main 函数(通过直接唤醒线程的方式,在 lab3 中会进一步讲解),完成对页的换出操作和生成空闲页的操作。这是一种消极换出的策略。
● 另外,ucore 设立了每秒执行一次 kwapd_main 函数(通过设置 timer 来唤醒线程的方式,在 lab3 中会进一步讲解),完成对页的换出操作和生成空闲页的操作。这是一种积极换出的策略。
kswapd_main 是 ucore 整个页面置换算法的总控部分,其大致思路是根据当前的空闲页情况查找出足够多的可换出页(swap page),然后根据这些可换出页的访问情况确定哪些是“常用”页,哪些是“不常用”页,最后把“不常用”的页转换成空闲页。思路简单,但 具体实现相对复杂。
如前所述,swap 整个流程就是把尽可能多的 page 从变成 PG_active 的,并移动到active list 中;把 active list 中的页尽可能多的变成 inactive list 中页;最后把 inactive list 的页换出(洗净),根据情况处理洗净后的 page 结构(根据 page ref 以及相应的 dirty bit)。所以整个过程的核心是尽可能的断开页表中的 PTE 映射。
当 alloc_pages 执行分配 n 连续物理页失败的时候,则会通过调用 tree_free_page 来唤醒 kswapd 线程,此线程执行 kswapd_main 函数。kswapd 会发现它现在压力很大,需要尽可能的满足分配 n 个连续物理页的需求。既然需求是 n 个连续物理页,那么 kswapd 所需要释放的物理页就应该大于 n 个;每个页可能在某个或者许多个页表的不同的地方有PTE 映射(特别是 copy on write 之后,这种情况更为普遍),那么 kswapd 所需要断开的PTE 映射就远远不止 n 个。Linux 实现了能够根据 physical address 在页表中快速定位的数据结构,但是实现起来过于复杂,这里 ucore 采用了一个比较笨的方法,即遍历所有存在的页表结构,断开足够多的 PTE 映射。这里足够多是个经验公式,采用 n<<5 。当然这也可能失败,那么 kswapd 就会尝试一定次数。当他实在无能为力的时候,也就放弃了。而alloc_pages 也会不停的调用 try_free_pages 进行尝试,当尝试不停的遭遇失败的时候,程序中会有许多句 warn 来输出这些调试信息。而 Linux 的方案是选择一个占用内存最多的进程杀掉并释放出资源,来尽可能的满足当前程序的需求(注意,这里当前程序是指内核服 务或者调用),直到程序从内核态正常退出;ucore 的这种设计显然是过于简单了,不过此是后话。
扫描页表是一项艰巨的任务,因为除了内核空间,用户地址空间有将近 3G 的空间, 真正的程序很少能够用这么多。因此,充分利用虚存管理能够很大的提升扫描页表的速度。
现在我们来介绍以下 kswap_main 是如何一步一步完成 swap 的操作的。正如前面介绍过的,swap 需要完成 3 件事情,下面对应的是这三个操作的具体细节:
- kswapd_main 函数通过循环调用函数 swap_out_mm 并进一步调用 swap_out_vma,来查找 ucore 中所有存在的虚存空间,并总共断开 m 个 PTE 到物理页的映射(这里需要和进程的概念有所结合,可以理解为每个用户程序都拥有一个自己的虚存空间。但是需 要提一句的是,在后的实验中还会遇到虚存空间在多个进程之间的共享;遍历虚存空间 而不是遍历每个进程是为了避免某个虚存空间被很多进程共享进而被 kswapd 过度压榨所带来的不公平。可以想象,被过度压榨的虚存空间,同时又由于被很多进程共享从 而有很高的概率被使用到,最终必然会导致频繁的#PF,给系统不必要的负担。还有就是虽然 swap 的任务是断开 m 个 PTE 映射,但是实际上它对每个虚存空间都一次至多提出断开 32 个映射的需求,并循环遍历所有的虚存空间直到 m 得到满足。这样做的目的也是为了保证公平,使得每个虚存空间被交换出去的页的几率是近似相等的。
Linux 实际上应该有更好的实现,它根据虚存空间所实际使用的物理页的个数来决定断开的映射的个数。)。这些断开的 PTE 映射所指向的物理页如果没有 PG_active 标记, 则需要给他分配一个新的 swap entry,并做好标记,将 page 插入到 active_list 中去(同时也插入到 swap 的哈希表中),然后设置好相应的 page_ref 和 mem_map[offset] 的值,当然,如果找不到空闲的 swap entry 可以分配(比如 swap 分区已经用光了), 我们只能跳过这样的 PTE 映射,从下一个地址继续寻找出路;对于原来就已经标记了
PG_swap 的物理页,则只需要完成后面的工作,即调整引用计数就足够了。断开的 PTE 被 swap_entry 取代,并取消 PTE_P 标记,,这样当出现#PF 的时候,我们能够直接根据 PTE 上的值得到该页的数据实际是在 swap 分区上的哪个位置上。
现在不必要计较一个 page 究竟是放在 active_list 还是放在 inactive_list 中,更不必要考虑换出这样的操作,这一阶段的工作只是断开 PTE 映射,余下的工作后面会一步步完成。
当 kswapd 断开足够数量的 PTE 映射以后,这一部分的工作也就完成了。虚存管理中维护了一个 swap_address 的地址,表示上一次 swap 操作结束时的地址,维护这个数据是避免每次 swap 操作都从虚存空间的起始地址开始,从而导致过多数量的重复的无效的遍历。
当 kswapd 发现自己竭尽所能的遍历都无法满足断开 m 个链接的需求时,该怎么办?我们需要明确的是 swap 操作的主要目的是释放物理页,而断开 PTE 映射是一个必要的步骤,作用是尽可能的扩大 inactive_list 中 page 的个数,为物理页的换出提供更大的基数(操作空间),但并不是主要过程。所以为了防止在这一步陷入死循环,
kswapd_main 最多会对全部虚存空间的链表尝试 rounds=16 次遍。
- 通过 page_launder 函数,遍历 inactive_list,实现页的换出。这部分和下面refill_inactive_list 操作的先后顺序并不那么严格。通俗的解释就是 page_launder 实现的是把 inactive_list 中的 page 洗净,并完成 page 的释放,当然也顺便实现了把实际上活跃的(active) 的 page 从 inactive_list 上取下,放回 active_list 的过程;而refill_inactive_list 从函数名上可以看出,实际上就是遍历 active_list,把实际上不活跃的(inactive) page 从 active_list 上取下,放到 inactive_list 上,方便下一轮 page_launder 的操作。后者没有什么需要特别强调的,但是 page_launder 是比较复杂的过程,我们需要仔细的分析一下。page_launder 先检查一个 page 的 page_ref 是否 != 0,如果满足,则表示该 page 实际上是 active 的,则把它移动到 active_list 上去;如果不是, 则需要对该页进行换出操作,过程如下:注意,下面讨论的是以 page_ref == 0 作为前提的。
(*) page_launder 的实现,涉及 ucore 内核代码设计的一个重要假设前提,这是第一次涉及,以后的各个模块也会逐步大量涉及。这部分和进程调度又有一定的关联,提 前了解一下,有助于理解这部分以后后续其它部分的代码。这个前提就是:ucore 的内核代码是不可抢占的,也就是,执行在内核部分的代码,只要不是以下几种情况,通常 可以认为是操作不会被抢占(preemption),即 CPU 控制权被剥夺:
○ 主动释放 cpu 执行权限,比如调用 schedule 让其它程序执行;
○ 进行同步互斥操作,比如争抢一个信号量、锁;
○ 进行磁盘等等异步操作,由于 kmalloc 有可能会调用 alloc_pages 来分配页,而
alloc_pages 可能失败进而将 cpu 让渡给 kswapd,所以,内核中的 kmalloc 操作可以认为不是一个同步的操作。所有这样的非同步的操作一个可能的问题,就是所 有执行比如 kmalloc 这样的函数之前所做出的各种条件判断,在 kmalloc 之后可能都不再成立了;
你可以理解下面两段程序在运行时的差异,其中 list 是一个全局变量,并且可能被任何程序在执行内核服务的时候修改掉:
partA:
if (!list_empty(list)) {
ptr = (uintptr_t)kmalloc(sizeof(uint32_t)); do_something(list_next(list), buffer); kfree(ptr);
}
partB:
ptr = (uintptr_t)kmalloc(sizeof(uint32_t)); if (!list_empty(list)) {
do_something(list_next(list), buffer);
}
kfree(ptr);
除此之外,中断处理的代码也需要进一步考虑进来。当内核尝试修改一部分数据的时候,如果该数据是中断处理流程可能访问的数据,那么内核需要对这次修改屏蔽中断; 同理,如果中断处理需可能修改一部分数据,并且内核打算尝试读取该数据,那么内核需要对读操作屏蔽中断,等等。
○ 如果一个页的 mem_map 项也为 0:前面已经讨论过 mem_map 和 page_ref 之间的关系。如果此时,这个页的 mem_map 项也为 0,说明这个时候已经没有 PTE 映射指向它们了,无论是物理页还是 swap 备份页。那么这个页也就没有必要洗净了。可以直接释放物理页以及相应的 swap entry 了(同时记得处理 swap 有关的链表,以下不再赘述)。
○ 如果一个页的 mem_map 项不为 0,但是没有 PG_dirty 标记:page 数据结构里面有 PG_dirty 标记,swap 部分的代码根据这个标记来判断一个页是否需要被洗净(写到 swap 分区上)。这个 PG_dirty 标记在什么情况下设置,我们稍后会讨论。这种情况可以等价为物理页上的数据和 swap 分区上的数据是一致的,所以不需要洗净该页,因为该物理页本身就已经足够干净了。所以可以安全的和(1) 中的操作一样对该物理页进行释放。
○ 如果一个页的确有 PG_dirty 标记:表示该页需要被洗净。ucore 这里的实现存在一个 bug,最新的代码已经修复了这个bug,不过bug 对于理解这段代码没有影响 。
先清楚,洗净一个页,需要调用 swapfs_write 函数,完成将物理页写到磁盘上的操作。前面已经强调过,我们假设所有磁盘操作是异步 IO。 先明确一下,当前的状态, page_ref=0 &&mem_map!=0 && PG_dirty,那么写出的过程中就可能发生下面许多种可能的场景:
○ swapfs_write 操作失败了。磁盘操作不像内存操作,它应该允许发生更多的错误。
○ 其它进程又访问到相应的数据页,前面提到过,因为 PTE 已经被修了,所以会产生#PF,内核会根据 PTE 的内容在 swap hash 里面查找到相应的物理页,并将它重新插入到相应的页表中,并更新该 page 的 page_ref 和 mem_map 的值。整个过程发生时,swapfs_write 还没有结束。那么当完成洗净一个页的操作时(写到
swap 分区),swap 部分的代码应该有能力检测出这种变化。也就是在
swapfs_write 之后,需要再判断 page_ref 是否依然满足 inactive 的。
○ 和 b 类似,不过不同的是,这次对物理页进行的是一个写操作。操作完成之后,进程又将该 PTE 指向的页释放掉了。那么当 swapfs_write 返回的时候,它面对的条件,可能就变成了 page_ref=0 &&mem_map=0 &&PG_dirty。它应该能够处理这个变化。
○ 和 c 类似,不同的是,该 page 有两个不同的 PTE 映射。那么在 swapfs_write 操作之前,状态可能是 page_ref =0&&mem_map=2&!PG_dirty,那么当 c 中的情况发生以后,该物理页的状态就可能变成了 page_ref=0&mem_map=1&PG_dirty 了。swap 应该能够处理这种变化。
综上所述,page_launder 部分的代码变得相对复杂很多。大家可以参照程序了解 ucore是怎么解决这种冲突的。
最后,提及一下那个 bug。因为 swapfs_write 是异步操作,并且是对该 page 的操作,
ucore 为了保证在操作的过程中,该页不被释放(比如一个进程通过#PF,增加 page_ref 到
1,然后又通过释放该 page 减少 page_ref 到 0,进而触发内核执行 page_free 的操作),分别在 swapfs_write 前后获得和释放该 page 的引用(page_ref_inc/page_ref_dec)。但事实证明,这种担心是多余的。理由很简单,当 page_launder 操作一个页的时候,该页是被标记 PG_swap 的,这个标记一方面表示 page 结构中的 index 有意义,另一方面也代表了, 这样的 page 的释放,只能够由 swap 部分的代码来完成(参见 pmm.c 以及后面 shmem.c 的处理)。所以,swap 在操作该 page 的时候,不可能有程序能够调用 free_page 释放该 page。
而相反的,mem_map 是一个需要保护的数据。这个是产生 bug 的地方,有兴趣的同学可以去自己理解一下。
此外,可以翻阅一下涉及到 page_ref 修改的 pmm 部分的代码,不难发现,当一个
page 从 PTE 断开的时候,也就是 page_ref 下降的时候,内核会根据 PTE 上的硬件设置的
PTE_D 来设置 PG_dirty。其实这就足够了。因为 PG_dirty 并不需要时时刻刻都十分的准确, 只要在 swap 尝试判断该 page 是否需要洗净的时候,PG_dirty 是正确的,就足够了。所以只需要保证每次 page_ref 下降的时候,PG_dirty 是正确的即可。除此之外,在对每个页分配 swap_entry 的时候,需要保证标记 PG_dirty,因为毕竟是刚刚分配的,物理页的数据还从来没有写出去过。
总结一下,页换入换出的实现很复杂,但是相对独立。并且正是由于 ucore 的内核代码不可抢占使得实现变得相对容易一些。只要是不涉及 IO 操作,大部分过程都可以认为处于不可抢占的内核执行过程。
6、共享内存实现
实现共享内存功能的目的是为在不同进程(process)之间能够通过共享内存实现数据共享。共享内存机制其实是一种进程间通信的手段。
相关数据结构
由于 vma 中并没有描述此虚拟地址对应的物理地址空间,所以无法确保不同页表中描述同一虚拟地址空间的 vma 指向同一个物理地址空间,所以不同页表间的内存无法实现共享。所以 vma_struct 增加下面两个域(field):
struct shmem_struct *shmem; size_t shmem_off;
shmem 的作用是统一维护不同 mm_struct 结构(即不同页表)中描述具有共享属性的同一虚拟地址空间的唯一物理地址空间。如果 vma->flags 里面有 VM_SHARE , 就表示vma->shmem 有意义,他指向一个 shmem_struct 结构的指针。shmem_struct 结构定义如下:
struct shmem_struct { list_entry_t shmn_list; shmn_t *shmn_cache; size_t len;
atomic_t shmem_ref; lock_t shmem_lock;
};
shmem_struct 包含了 list_entry_t 结构的 shmn_list,此链表的元素是 shmn_t 结构的共享页描述(包含某共享虚拟页的信息(page 或者 swap entry),为了维护起来简便,里面借用了页表的 PTE 描述方式,除了 PTE_P 用来区分是否是一个物理页以外,没有任何其它权限标记,所以后面提到的 PTE 应该是带引号的),所以此链表就是用来存储虚拟地址空间的 PTE 集合,即此共享的虚拟地址空间对应的唯一的物理地址空间的映射关系。shmem_ref 指出了当前有多少进程共享此共享虚拟空间。shmn_t 是用来描述一段共享虚拟空间的信息,可理解为一个 shmem node 结构,其定义如下:
typedef struct shmn_s { uintptr_t start; uintptr_t end; pte_t *entry;
list_entry_t list_link;
} shmn_t;
在这个结构中,entry 保存了一块(4KB)连续的虚拟空间的 PTE 数组,可以理解为一个二级页表,这个页表最大可以描述 4MB 的连续虚拟空间对应的物理空间地址信息。entry 中的每一项用于保存 physical address | PTE_P 或者 swap_entry。这样能最大限度节约内存,并且能很快通过 entry 项计算出对应的 struct page。
而 list_link 是用来把自身连接属于同一 shmem_struct 结构的域-shmn_list 链表,便于shmem_struct 结构的变量对共享空间进行管理。这样就可以形成如下图所示的共享内存布局:
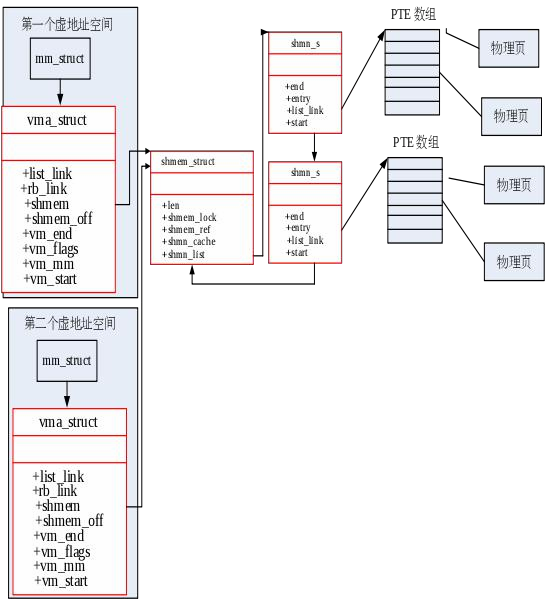
创建和访问共享内存的实现逻辑
为了创建一块共享内存,首先需要在内核中调用 do_shmem 函数,do_shmem 函数并进一步调用 shmem_create 函数创建一个 shmem_struct 结构的变量,然后再调用
mm_map_shmem 函数来创建一个 vma 结构的变量,并设置 vma 的属性为 VM_SHARE,并把vma->shmem 指向 shmem 结构变量。这样就初步建立好了一个共享内存虚拟空间。
由于并没有给这块共享内存虚拟空间实际分配物理空间,所以在第一次访问此 vma 中某地址时,会产生缺页异(page fault),并触发 do_pgfault 函数被调用。此函数如果发现是
“合法”的共享内存虚拟空间出现的地址访问错时,将调用 shmem 的处理函数shmem_get_entry,来查找此共享内存虚拟子空间所在的其他虚拟地址空间中(具有不同的页表)是否此虚地址对应的 PTE 项存在,如果不存在,则表明这是第一次访问这个共享内存区域,就可以创建一个物理页,并在 shmn_s 的 entry 中记录虚拟页与物理页的映射关系; 如果存在,则在本虚拟地址空间中建立此虚地址对应的 PTE 项,这样就可以确保不同页表中的共享虚拟地址空间共享一个唯一的物理地址空间。
shmem 结构中增加一个计数器,在执行复制某虚拟地址空间的 copy_mm 函数的时,如果 vm_flags 有 VM_SHARE,则仅增加 shmem 计数器 shmem_ref,而不用再创建一个shmem 变量;同理,释放具有共享内存属性的 vma 时,应该减少 shmem 计数器 shmem_ref, 当 shmem 计数器 shmem_ref 减少到 0 的时候,应该释放 shmem 所占有的资源。
另外,在 shmem 里面不能记录地址,因为不同 vma 可能 map 到不同的地址上去,因此它只维护一个 page 的大小。上面提到的 shmem_off 的作用是定位页面。具有共享属性的 vma 创建的时候,shmem_off = 0。当 vma->vm_start 增加的时候(只可能变大,因为内
核不支持它减小,unmap 的时候可能导致 vma 前面部分的 unmap,这就可能会让 vm_start变大),应该将 vm_start 的增量赋给 shmem_off,以保证剩下的 shmem 能够访问正确的位置。这样在访问共享内存地址addr 发生缺页异常的时候,此地址对应的页在 shmem_struct 里面的 PTE 数组项的索引 index 应该等于 (addr - vma->vm_start + vma->shmem_off) /
PGSIZE。
【注意】
在页换出操作中,尝试换出一页的条件是页的 page_ref 到 0。为了防止 share memory
的 page 被意外的释放掉,shmem 结构也会增加相应数据页的引用计数。那么对于一个 share
memory 的数据页,是不是就不能换出了?前面提到,页换出操作的第一步是扫描所有的虚拟地址空间,那么页换出操作就完全有能力知道当前扫描的 vma 是普通的 vma 还是对应的 share memory 的 vma。正如 swap.c 里面看到的那样,swap 断开一个 page 以后,如果发现当前 vma 是 share memory 的,并且 page_ref 是 1,那么可以确定的是这个最后一个 page_ref 是在 shmem 结构中。那么 swap 也同时将该 share memory 上的 PTE 断开, 就满足了 page_launder 的换出条件。
share memory 上的 entry 换成了 swap entry 带来的坏处也很明显,因为标记 share 的
vma 如果一开始没有页表内容,需要通过 #PF 从 shmem 里面得到相应的 PTE。但是不幸的是,得到的是 swap entry,那么只能再通过第二次 #PF,才能将 swap entry 替换成数据页。
7、实现写时复制
写时复制(Copy On Write,简称 COW)的主要功能,为高效地创建子进程打下了基础。其设计思想相对简单:父进程和子进程之间共享(share)页面而不是复制(copy)页面。但只要页面被共享,它们就不能被修改,即是只读的。注意此共享是指父子进程共享一个表示内存空间的 mm_struct 结构的变量。当父进程或子进程试图写一个共享的页面,就产生一个页访问异常,这时内核就把这个页复制到一个新的页面中并标记为可写。注意,原来的页面仍然是写保护的。当其它进程试图写入时,ucore 检查写进程是否是这个页面的唯一属主(通过判断 page_ref 和 swap_page_count 即 mem_map 中相关 entry 保存的值的和是否为 1。注意区分与 share memory 的差别,share memory 通过 vma 中的 shmem 实现,这样的 page 是直接标记为共享的,而不是 copy on write,所以也没有任何冲突);如果是, 它把这个页面标记为对这个进程是可写的。
在具体实现上,ucore 调用 dup_mmap 函数,并进一步调用 copy_range 函数来具体完成对页表内容的复制,这样两个页表表示同一个虚拟地址空间(包括对应的物理地址空间), 且还需修改两个页表中每一个页对应的页表项属性为只读,但在这种情况下,两个进程有两个页表,但这两个页表只映射了一块只读的物理内存。同理,对于换出的页,也采用同样的办法来共享一个换出页。综上所述,我们可以总结出:如果一个页的 PTE 属性是只读的,但此页所属的 VMA 描述指出其虚地址空间是可写的,则这样的页是 COW 页。
当对这样的地址空间进行写操作的时候,会触发 do_pgfault 函数被调用。此函数如果发现是 COW 页,就会调用 alloc_page 函数新分配一个物理页,并调用 memcpy 函数把旧页的内容复制到新页中,并最后调用 page_insert 函数给当前产生缺页错的进程建立虚拟页地址到新物理页地址的映射关系(即改写 PTE,并设置此页为可读写)。这里还有一个特殊情况,如果产生访问异常的页已经被换出到硬盘上了,则需要把此页 通过 swap_in_page 函数换入到内存中来,如果进一步发现换入的页是一个 COW 页,则把其属性设置为只读,然后异常处理结束返回。但这样重新执行产生异常的写操作,又会触发一 次内存访问异常,则又要执行上一段描述的过程了。Page 结构的 ref 域用于跟踪共享相应页面的进程数目。只要进程释放一个页面或者在它上面执行写时复制,它的 ref 域就递减;只有当 ref 变为 0 时,这个页面才被释放。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)