内存之页表
内存管理中页表小结
1、 页表是什么
页表是一种特殊的数据结构,放在系统空间的页表区,用来存放逻辑页与物理页帧的对应关系。每一个进程都拥有一个自己的页表,PCB表中有指针指向页表。
个人理解一句话概括:
带有权限属性的放在物理内存中的,用来记录虚拟内存页与物理页映射关系的一张表。

2、 页面大小
在64位系统中,页面大小为4K Bytes,即2的12次方,所以页内位移需要12位表示。那么页号也就是64 – 12 = 52位,但实际上只有用到其中的一部分。比如在内核中配置虚拟地址长度为48bit,则页号用到了48 – 12 = 36位。

若逻辑地址长度为m bits,页面大小为:2nByte
页内位移为n bits;页号占m – n bits;
Notes:此为理论计算公式。
在aarch64中逻辑地址长度为64bits,常用页内偏移为12bits,理论上页号占据52bits;但实际使用中虚拟地址常用为48bits,因此实际页号占36bits。
获取Linux系统页大小的命令

3、 页表的notes
3.1、页表的作用
1) 地址转换
将虚拟地址转换为物理地址
2) 权限管理
管理CPU对物理页的访问,如:读、写、可执行等权限
3) 隔离地址空间
隔离各个进程的地址空间,使其互不影响,提供系统的安全性
Note:
可以在不额外增加物理内存的情况下,将页换出到块设备来增加有效的可用内存空间。
3.2、页表的存放
页表存放在物理内存中,打开MMU后,如果需要修改页表,需要将页表所在的物理地址映射到虚拟地址才能访问页表(如内核初始化后会将物理内存线性映射,这样通过物理地址和虚拟地址的偏移就可以获得页表物理地址对应的虚拟地址)。
3.3、页表项中存放的是虚是实
页表基地址寄存器和各级页表中存放的都是物理地址,而不是虚拟地址。
4、 页表的分级
4.1、单级与多级页表
在不同的架构体系中所使用的页表级数也不相同。页表为什么要分级?
Arm通常使用二级页表,arm64通常使用三级页表。
此处拿arm举例说明,
32位arm系统所支持的最大访问空间为4GB,页面大小为4KB。
<一级页表>

页内偏移为低12bit,页号占高20bit
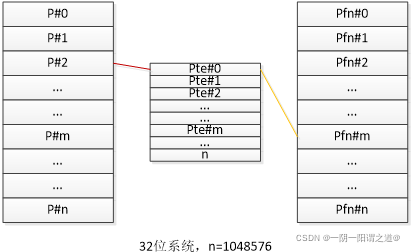
若将4GB空间映射需要4GB/4KB个页表条目,每个条目占据4Byte则单个进程的4GB空间所对应的页表需要消耗4MB的物理内存。在多进程中物理内存将极大的被消耗掉。另外页表是不能被拆分的,因此页表的存放必须是物理地址连续的4MB空间(1KB 连续页框)。随着业务程序的不断运行,系统内存页将逐渐碎片化,很难在需要时找到一块如此大的连续内存,这种严苛的条件往往很难达到。
<二级页表>
若是采用二级页表,则逻辑地址应该怎样分段呢?i、j、k、m以及n分别是什么?

页面大小仍然使用最常用的4KB,因此页内偏移是0~11;
32位系统中页表项(条目)大小为4Byte,因此一页最多可存放1024个页表项,因此以10bit来划分高位的20bit页号段;j ~ k = 12 ~ 21;m ~ n = 22 ~ 31。
采用二级页表时,对应规则就会改变,二级页表将对应到物理内存上的4KB大小的页,一级页表此时变为映射物理地址为4MB。在实际的内存访问中,先找到一级页表,一级页表再和二级页表进行结合,二级页表相当于一级页表4MB分成了1024个4KB,找完后二级页表充当了offset的角色,此时定位到具体的4KB的页面,再用逻辑地址中的页内偏移offset找到具体的物理地址。
这样一个进程浪费掉的空间是一级页表占用的(4GB/4MB)4byte=4KB,二级页表浪费掉的是1kB (一个一级页表拥有的二级页表数量) 1kB(一级页表的数目4GB/4MB) *4byte=4MB,加起来是4MB + 4KB,比光用一级页表要多4KB,但是二级页表是可以不存在的,比如此时程序只用了20%的页,那么4MB就需要乘以20%,这样一下内存消耗就比只用一级页表时少。
二级页表如何实现地址转换
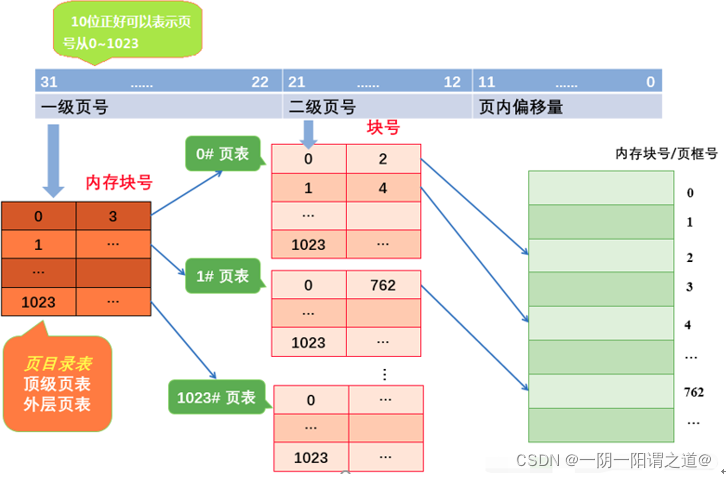
大致流程:
(1) 按照地址结构将逻辑地址拆成三个部分。
(2) 从PCB中读取页目录起始地址,再根据一级页号查页目录表,找到下一级页表在内存中存放位置。
(3) 根据二级页号查表,找到最终想要访问的内存块号。
(4) 结合页内偏移量得到物理地址。
4.2、优缺点
1、一级页表的优缺点
优点:只需要2次访问内存(一次访问页表,一次访问数据),效率高,实现简单
缺点:需要连续的大块内存存放每个进程的页表,浪费内存,虚拟内存越大页表越大,内存碎片化的时候很难分配到连续大块内存,大多数虚拟内存并没有使用。
2、多级页表的优缺点
优点:节省内存、可以按需分配各级页表、可以离散存储页表
缺点:需要遍历多级页表,需要多次访问内存,实现复杂度高。
4.3、快表
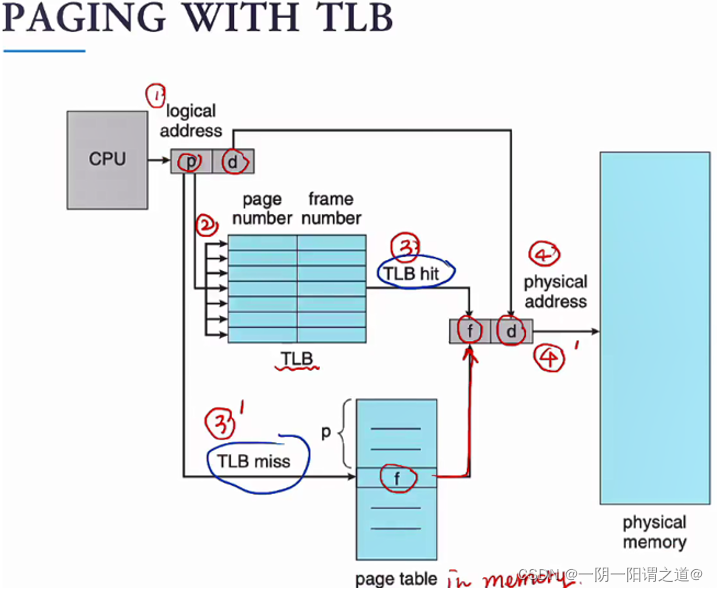
从上述内容可以看到在多级页表中,CPU预访问一个内存地址所需要的步骤比较多,如此带来的是性能的降低。为了提高访问内存的性能,硬件设计在MMU中增加了TLB。
TLB是一种很小但查找速度很快的缓存,TLB配合页表一起使用:
TLB存放了很多进程中的一部分页表条目(最近访问的),这些条目就称为快表
当CPU转换逻辑地址时,会去TLB中进行查找,如果找到了,那么立刻就能将地址转换完成;如果没有找到,那么需要对内存进行多次访问来将逻辑地址转换为物理地址。
4.4、arm64四级页表
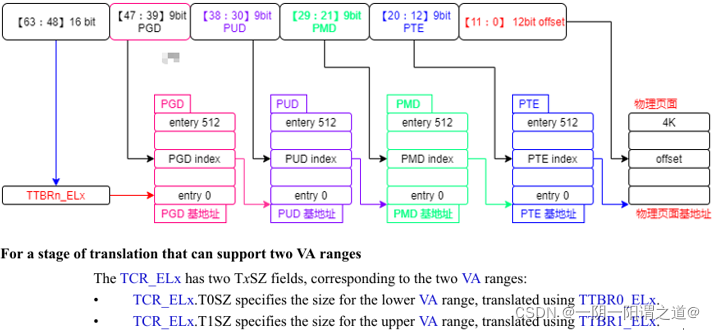
Arm64体系中虚拟地址为64bit,理论可访问的最大地址空间为2^64,这是一个超大的操作空间,现代的计算法并不会使用如此巨量的地址,在实际的应用中嵌入式平台上一般会配置为39bit,对应三级页表(pgd->pmd->pte),当虚拟地址长度配置为48bit时,则必须使用四级页表(pgd->pud->pmd->pte)。
下面以内核配置虚拟地址长度为48bit,PAGE_TABLE为4举例。
整个的逻辑地址按照页表层级划分如下:

可以看到其是9:9:9:9:12的地址划分结构,上面也有提到地址如何划分,这里再赘述下:
m = 逻辑地址位数 – 页内偏移量
页大小为4KB,单个页表项占据8Byte,最大可容纳512个页表项。因此每级页表bit数不可超过9。
48bit ~ 63bit 在页表管理中是用不到的,但不是说没有意义。该段的数据代表着CPU访问的地址是用户空间还是内核空间,分别到TTBR0和TTBR1寄存器中获取Level0页表基地址。
1. 47~39:Level 0页表中的索引,根据描述符中的内容获取Level 1页表基地址;
2. 38~30:Level 1页表中的索引,根据描述符中的内容获取Level 2页表基地址;
3. 29~21:Level 2页表中的索引,根据描述符中的内容获取Level 3页表基地址;
4. 20~12:Level 3页表中的索引,根据描述符中的内容获取物理地址的高36位,以4K地址对齐;
5. 11~00:是物理地址的偏移,结合获取的物理地址高位,最终得到物理地址。
每一级页表中存储的下一级的物理地址和属性信息。
内存的映射过程如下:
4.5、四级页表的格式
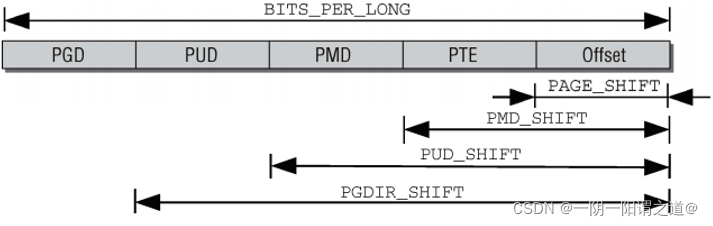
内核提供了4个数据结构(定义在page.h中)来表示页表项的结构
pgd_t用于全局页目录项。
pud_t用于上层页目录项。
pmd_t用于中间页目录项。
pte_t用于直接页表项。
PMD_SHIFT指定了页内偏移量和最后一级页表项所需比特位的总数。该值减去PAGE_SHIFT,可得最后一级页表项索引所需比特位的数目。更重要的是下述事实:该值表明了一个中间层页表项管理的部分地址空间的大小,即2PMD_SHIFT字节。
PUD_SHIFT由 PMD_SHIFT加 上 中 间 层 页 表 索 引 所 需 的 比 特 位 长 度 , 而 PGDIR_SHIFT则 由PUD_SHIFT加上上层页表索引所需的比特位长度。对全局页目录中的一项所能寻址的部分地址空间长度计算以2为底的对数,即为PGDIR_SHIFT。
在各级页目录/页表中所能存储的指针数目,也可以通过宏定义确定。 PTRS_PER_PGD指定了全局页目录中项的数目,PTRS_PER_PMD对应于中间页目录, PTRS_PER_PUD对应于上层页目录中项的数目,PTRS_PER_PTE则是页表中项的数目。
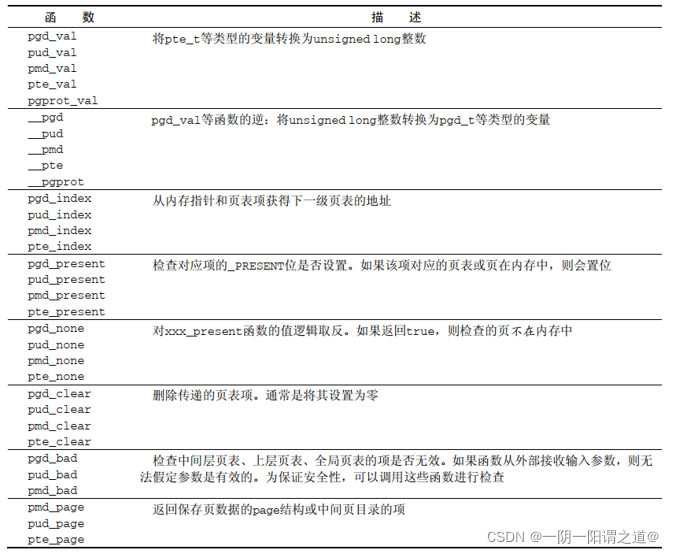
下表为分析页表项的函数
5、 页表的属性(特定于PTE的信息)
在内存的访问过程中往往带有一些特殊的属性信息,比如可执行文件代码段映射的内存区是只读的,不允许用户去修改;一段内存可以同时映射到不同的程序中去使用;同一段物理地址可以分别映射成DEVICE和NORMAL,用于不同的场景中。这些属性权限都是记录在页表中,由页表在管理维护。
在不同的架构体系中页表项所占用的长度是不相同的,arm中是4Byte,arm64中是8Byte。如此仅看arm64架构的相关内容,本质与arm是相同的,只是相比arm可能有更丰富的管理属性。

在armv-X相关手册中都有定义属性类型,Linux内核源码中同样存在。
最后一级页表中的项不仅包含了指向页的内存位置的指针,还在上述的多余比特位包含了与页有关的附加信息。尽管这些数据是特定于CPU的,它们至少提供了有关访问控制的一些信息。
下列位在Linux内核支持的大多数CPU中都可以找到。
_PAGE_PRESENT指定了虚拟内存页是否存在于内存中。页不见得总是在内存中,页可能换出到交换区。如果页不在内存中,那么页表项的结构通常会有所不同,因为不需要描述页在内存中的位置。相反,需要信息来标识并找到换出的页。
CPU每次访问页时,会自动设置_PAGE_ACCESSED。内核会定期检查该比特位,以确认页使用的活跃程度(不经常使用的页,比较适合于换出)。在读或写访问之后会设置该比特位。
_PAGE_DIRTY表示该页是否是“脏的”,即页的内容是否已经修改过。
_PAGE_FILE的数值与_PAGE_DIRTY相同,但用于不同的上下文,即页不在内存中的时候。显然,不存在的页不可能是脏的,因此可以重新解释该比特位。如果没有设置,则该项指向一个换出页的位置。如果该项属于非线性文件映射,则需要设置_PAGE_FILE。
如果设置了_PAGE_USER,则允许用户空间代码访问该页。否则只有内核才能访问(或CPU处于系统状态的时候)。
_PAGE_READ、 _PAGE_WRITE和_PAGE_EXECUTE指定了普通的用户进程是否允许读取、写入、执行该页中的机器代码。内核内存中的页必须防止用户进程写入。但即使属于用户进程的页,也无法保证可以写入,这可能是有意如此,也可能是无意偶合。例如,其中可能包含了不能修改的可执行代码。对于访问权限粒度不那么细的体系结构而言,如果没有进一步的准则可区分读写访问权限,则会定义_PAGE_RW常数,用于同时允许或禁止读写访问。
IA-32和AMD64提供了_PAGE_BIT_NX,用于将页标记为不可执行的(在IA-32系统上,只有启用了可寻址64 GiB内存的页面地址扩展( page address extension, PAE)功能时,才能使用该保护位。例如,它可以防止执行栈页上的代码。否则,恶意代码可能通过缓冲区溢出手段在栈上执行代码,导致程序的安全漏洞。 NX位无法防止缓冲器溢出,但可以抑制其效果,因为进程会拒绝执行恶意代码。当然,如果体系结构本身对内存页提供了良好的访问授权设置,也可以实现同样的效果,某些处理器就是这样(令人遗憾的是,这些处理器不怎么常见)。
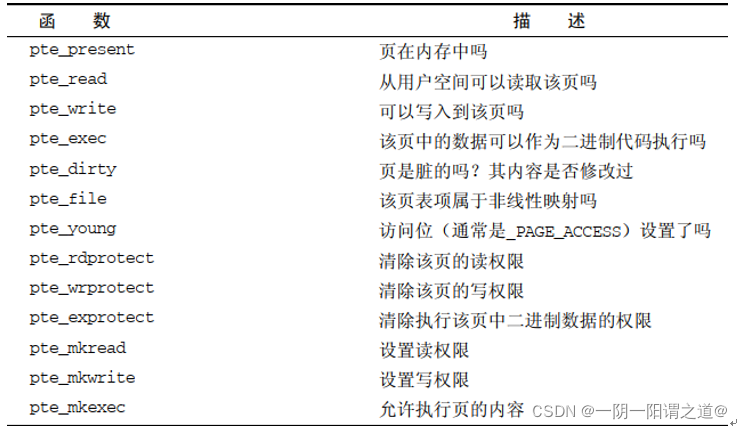
用于处理内存页的体系结构相关状态的函数

<相关数据结构>
在内核代码pgtable-hwdef.h(arch/arm64/include/asm)中可见PTE相关定义
#define PTE_VALID (_AT(pteval_t, 1) << 0)
#define PTE_WRITE (PTE_DBM) /* same as DBM (51) */
#define PTE_DIRTY (_AT(pteval_t, 1) << 55)
#define PTE_SPECIAL (_AT(pteval_t, 1) << 56)
#define PTE_PROT_NONE (_AT(pteval_t, 1) << 58) /* only when !PTE_VALID */
#define PTE_TYPE_MASK (_AT(pteval_t, 3) << 0)
#define PTE_TYPE_FAULT (_AT(pteval_t, 0) << 0)
#define PTE_TYPE_PAGE (_AT(pteval_t, 3) << 0)
#define PTE_TABLE_BIT (_AT(pteval_t, 1) << 1)
#define PTE_USER (_AT(pteval_t, 1) << 6) /* AP[1] */ 用户空间可访问
#define PTE_RDONLY (_AT(pteval_t, 1) << 7) /* AP[2] */ 只读
#define PTE_SHARED (_AT(pteval_t, 3) << 8) /* SH[1:0], inner shareable */
#define PTE_AF (_AT(pteval_t, 1) << 10) /* Access Flag */ 在内存中
#define PTE_NG (_AT(pteval_t, 1) << 11) /* nG */ 不可合并
#define PTE_DBM (_AT(pteval_t, 1) << 51) /* Dirty Bit Management */
#define PTE_CONT (_AT(pteval_t, 1) << 52) /* Contiguous range */
#define PTE_PXN (_AT(pteval_t, 1) << 53) /* Privileged XN */
#define PTE_UXN (_AT(pteval_t, 1) << 54) /* User XN */ 用户无执行权限
#define PTE_HYP_XN (_AT(pteval_t, 1) << 54) /* HYP XN */
/*
* AttrIndx[2:0] encoding (mapping attributes defined in the MAIR* registers).
*/
#define PTE_ATTRINDX(t) (_AT(pteval_t, (t)) << 2)
/*
* Memory types available.
*/
#define MT_DEVICE_nGnRnE 0
#define MT_DEVICE_nGnRE 1
#define MT_DEVICE_GRE 2
#define MT_NORMAL_NC 3
#define MT_NORMAL 4
#define MT_NORMAL_WT 5
<相关功能接口定义>
#define pte_pfn(pte) (__pte_to_phys(pte) >> PAGE_SHIFT)
#define pfn_pte(pfn,prot) \
__pte(__phys_to_pte_val((phys_addr_t)(pfn) << PAGE_SHIFT) | pgprot_val(prot))
#define pte_none(pte) (!pte_val(pte))
#define pte_clear(mm,addr,ptep) set_pte(ptep, __pte(0))
#define pte_page(pte) (pfn_to_page(pte_pfn(pte)))
/*
* The following only work if pte_present(). Undefined behaviour otherwise.
*/
#define pte_present(pte) (!!(pte_val(pte) & (PTE_VALID | PTE_PROT_NONE)))
#define pte_young(pte) (!!(pte_val(pte) & PTE_AF))
#define pte_special(pte) (!!(pte_val(pte) & PTE_SPECIAL))
#define pte_write(pte) (!!(pte_val(pte) & PTE_WRITE))
#define pte_user_exec(pte) (!(pte_val(pte) & PTE_UXN))
#define pte_cont(pte) (!!(pte_val(pte) & PTE_CONT))
#define pte_hw_dirty(pte) (pte_write(pte) && !(pte_val(pte) & PTE_RDONLY))
#define pte_sw_dirty(pte) (!!(pte_val(pte) & PTE_DIRTY))
#define pte_dirty(pte) (pte_sw_dirty(pte) || pte_hw_dirty(pte))
#define pte_valid(pte) (!!(pte_val(pte) & PTE_VALID))
#define pte_valid_not_user(pte) \
((pte_val(pte) & (PTE_VALID | PTE_USER)) == PTE_VALID)
#define pte_valid_young(pte) \
((pte_val(pte) & (PTE_VALID | PTE_AF)) == (PTE_VALID | PTE_AF))
#define pte_valid_user(pte) \
((pte_val(pte) & (PTE_VALID | PTE_USER)) == (PTE_VALID | PTE_USER))
static inline pte_t pte_wrprotect(pte_t pte)
{
pte = clear_pte_bit(pte, __pgprot(PTE_WRITE));
pte = set_pte_bit(pte, __pgprot(PTE_RDONLY));
return pte;
}
static inline pte_t pte_mkwrite(pte_t pte)
{
pte = set_pte_bit(pte, __pgprot(PTE_WRITE));
pte = clear_pte_bit(pte, __pgprot(PTE_RDONLY));
return pte;
}
static inline pte_t pte_mkclean(pte_t pte)
{
pte = clear_pte_bit(pte, __pgprot(PTE_DIRTY));
pte = set_pte_bit(pte, __pgprot(PTE_RDONLY));
return pte;
}
static inline pte_t pte_mkdirty(pte_t pte)
{
pte = set_pte_bit(pte, __pgprot(PTE_DIRTY));
if (pte_write(pte))
pte = clear_pte_bit(pte, __pgprot(PTE_RDONLY));
return pte;
}
static inline pte_t pte_mkold(pte_t pte)
{
return clear_pte_bit(pte, __pgprot(PTE_AF));
}
static inline pte_t pte_mkyoung(pte_t pte)
{
return set_pte_bit(pte, __pgprot(PTE_AF));
}
static inline pte_t pte_mkspecial(pte_t pte)
{
return set_pte_bit(pte, __pgprot(PTE_SPECIAL));
}
static inline pte_t pte_mkcont(pte_t pte)
{
pte = set_pte_bit(pte, __pgprot(PTE_CONT));
return set_pte_bit(pte, __pgprot(PTE_TYPE_PAGE));
}
static inline pte_t pte_mknoncont(pte_t pte)
{
return clear_pte_bit(pte, __pgprot(PTE_CONT));
}
static inline pte_t pte_mkpresent(pte_t pte)
{
return set_pte_bit(pte, __pgprot(PTE_VALID));
}
static inline pmd_t pmd_mkcont(pmd_t pmd)
{
return __pmd(pmd_val(pmd) | PMD_SECT_CONT);
}
6、 页表对应的内存管理
上面有提到页表是存放在物理内存中的,因此页表的建立也是需要消耗内存的,其对应的内存分配有专门的接口函数。
用于创建新页表项的函数

<接口定义>
pgd_t *pgd_alloc(struct mm_struct *mm)
{
if (PGD_SIZE == PAGE_SIZE)
return (pgd_t *)__get_free_page(PGALLOC_GFP); //页申请
else
return kmem_cache_alloc(pgd_cache, PGALLOC_GFP);
}
void pgd_free(struct mm_struct *mm, pgd_t *pgd)
{
if (PGD_SIZE == PAGE_SIZE)
free_page((unsigned long)pgd);
else
kmem_cache_free(pgd_cache, pgd);
}
static inline pmd_t *pmd_alloc_one(struct mm_struct *mm, unsigned long addr)
{
return (pmd_t *)__get_free_page(PGALLOC_GFP);
}
static inline pgtable_t pte_alloc_one(struct mm_struct *mm, unsigned long addr)
{
struct page *pte;
pte = alloc_pages(PGALLOC_GFP, 0);
if (!pte)
return NULL;
if (!pgtable_page_ctor(pte)) {
__free_page(pte);
return NULL;
}
return pte;
}
7、 虚拟地址的内存属性的获取
7.1、内核态虚拟地址内存属性的获取
在内核中可通过如下的方式获取一段内核态地址属性信息:
//读取descriptor地址中数据并右移2
#define get_mem_attr(descriptor) ((*(unsigned long*)descriptor >> 2) & 0x7)
void print_vm_prot(unsigned long virt)
{
pgd_t *pgd = NULL;
pud_t *pud = NULL;
pmd_t *pmd = NULL;
pte_t *pte = NULL;
int mem_attr;
printk("virt addr 0x%08lx", virt);
pgd = pgd_offset_k(virt);
if (pgd_none(*pgd) || pgd_bad(*pgd))
{
printk(KERN_ERR"not mapped in pgd!\n");
return;
}
pud = pud_offset(pgd, virt);
if (pud_none(*pud) || pud_bad(*pud))
{
printk(KERN_ERR"not mapped in pud!pgd:%llx\n", pgd_val(*pgd));
return;
}
pmd = pmd_offset(pud, virt);
if (pmd_none(*pmd) || pmd_bad(*pmd))
{
printk(KERN_ERR"not mapped in pmd!\n");
return;
}
pte = pte_offset_map(pmd, virt);
printk(", *pte=%016llx", pte_val(*pte));
printk("pgd:%#llx, pud:%#llx, pmd:%#llx\n", pgd_val(*pgd), pud_val(*pud), pmd_val(*pmd));
mem_attr = get_mem_attr(pte);
if (mem_attr == MT_DEVICE_nGnRnE)
printk("Memory Attribute: DEVICE_nGnRnE\n");
else if (mem_attr == MT_DEVICE_nGnRE)
printk("Memory Attribute: DEVICE_nGnRE\n");
else if (mem_attr == MT_DEVICE_GRE)
printk("Memory Attribute: DEVICE_GRE\n");
else if (mem_attr == MT_NORMAL_NC)
printk("Memory Attribute: NORMAL_NC\n");
else if (mem_attr == MT_NORMAL)
printk("Memory Attribute: NORMAL\n");
else if (mem_attr == MT_NORMAL_WT)
printk("Memory Attribute: NORMAL_WT\n");
}
7.3、How to mmap physical address to user space?
#define DEVICE_TEST "/dev/mem"
uintptr_t va_1 = 0, phy_1 = 0;
static int fd;
alloc_type_t alloc_type;
int ret = 0;
void *map_base = NULL;
unsigned int page_size = 0;
fd = open(DEVICE_TEST, O_RDWR);
// if you use bufferable method.
alloc_type = ALLOC_BUFFERABLE | ALLOC_MAP_ONLY;
// if you use non-cacheable method
//alloc_type = ALLOC_NONCACHABLE | ALLOC_MAP_ONLY;
// if you use cacheable method
// alloc_type = ALLOC_CACHEABLE | ALLOC_MAP_ONLY;
ret = ioctl(fd, NVTMEM_ALLOC_TYPE, &alloc_type);
page_size = getpagesize();
va_1 = (uintptr_t)mmap(NULL, mapped_size, PROT_READ |
PROT_WRITE, MAP_SHARED, fd, phy_addr);
Limitation: In ARM64, because it will be set to device memory when you choose
non-cacheable method to do mmap, you will get some errors when you do some
operations, such as memset 0. Therefore, we suggest you to use bufferable method to do mmap
参考文献:
1、 https://blog.csdn.net/qq2208889900;
2、 《Arm® Architecture Reference Manual Armv8, for Armv8-A architecture profile》
3、 《深入Linux内核架构》

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)