Ubuntu18.04中Hadoop3.1.3安装教程(单机/伪分布式配置)
Ubuntu18.04中Hadoop3.1.3安装教程(单机/伪分布式配置)
参考文章
厦门大学数据库实验室 / 林子雨出品http://dblab.xmu.edu.cn/blog/2441-2/
环境要求
Ubuntu 18.04 64位
hadoop-3.1.3.tar
jdk-8u162-linux-x64.tar
安装过程
首先我们需要一个已经安装成功的Ubuntu系统,安装过程可参考我之前的文章:
vmware15.5.0安装Ubuntu18.04.5详细配置
创建用户
改用户名的原因:最开始的用户是我们自己创建的,在后期的学习中用户名改为hadoop会更加方便。下图是创建用户前。

在Ubuntu系统中打开终端,输入指令创建hadoop新用户。
sudo useradd -m hadoop -s /bin/bash #创建用户
sudo passwd hadoop #设置密码
sudo adduser hadoop sudo #提权
注意:sudo是用高级权限执行指令,需要输入密码,在Linux中输入密码不会显示,自己只管输入,没用显示是正常现象。
在这里插入图片描述
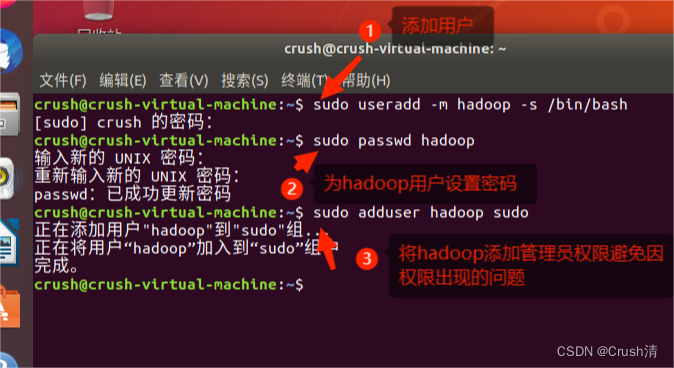
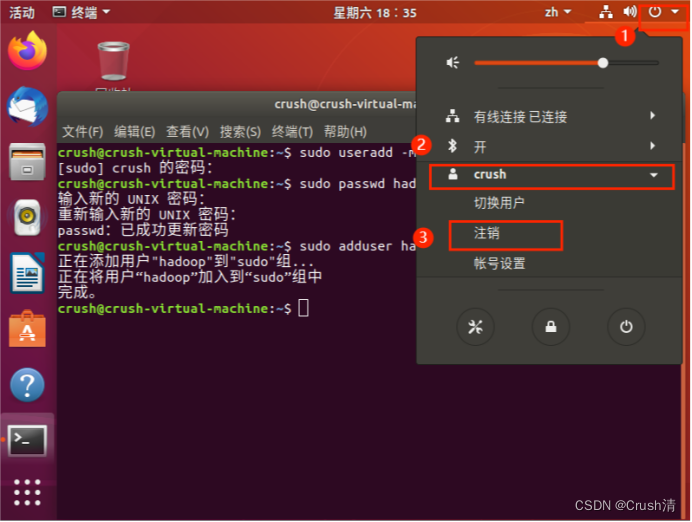
以上步骤完成后需要注销用户重新登录(也可选择重启虚拟机)。点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
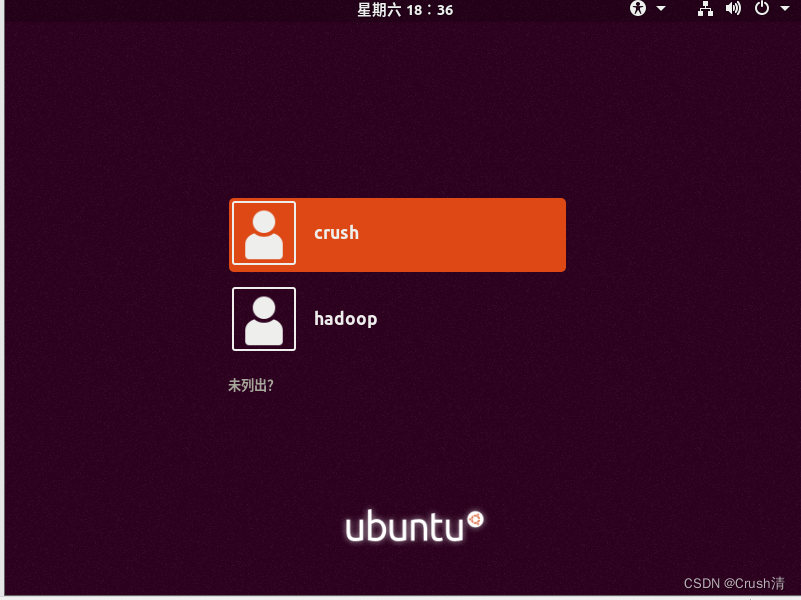
注销之后就可以在我们的登录界面看到我们新注册的hadoop用户。输入密码登录hadoop用户。
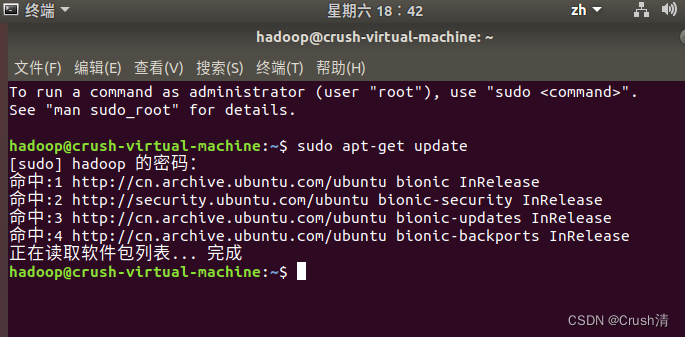
更新apt和安装编辑器
由于系统内置的软件版本可能会和我们用到的软件的版本不一致,所以需要升级apt。终端输入以下指令。
sudo apt-get update
安装vim编辑器和gedit编辑器,遇见Y输y就好。
sudo apt-get install vim
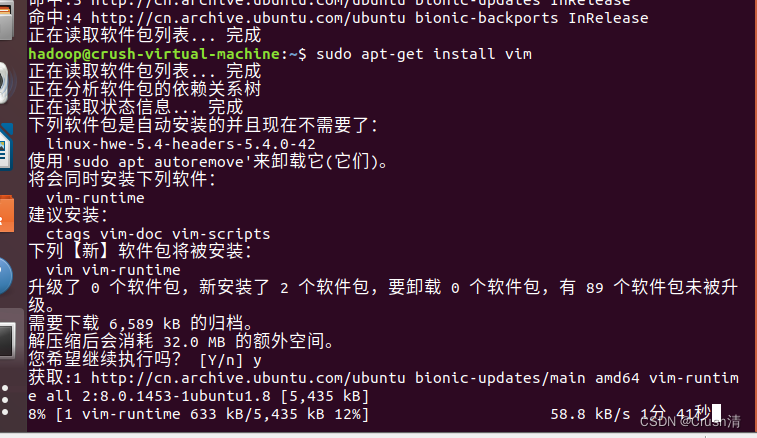
sudo apt-get install gedit
浅述vim与gedit不同:
vim:不能随意定位光标,编辑是需要按i键,退出编辑esc键,保存需要先按esc键,在打出:wq(w是保存,q是退出)。
复制:Ctrl+shift+C
粘贴是Ctrl+shift+V
gedit:可以用法与window文本编辑一样。
复制:Ctrl+C
粘贴:Ctrl+V
保存:Ctrl+S
安装SSH、配置SSH无密码登陆
为了实现免密和远程登录。
sudo apt-get install openssh-server
安装后用ssh localhost登录本机
ssh localhost
首次登陆会有提示,输入 yes 。然后按提示输入密码。

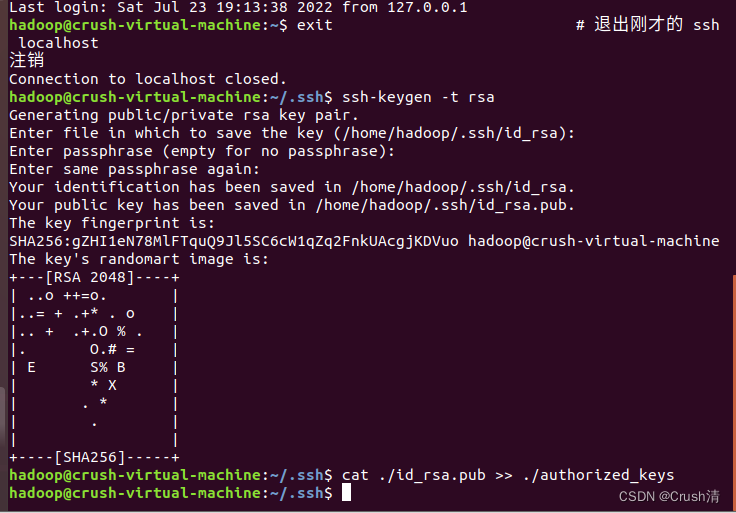
此时登录ssh还是需要输入密码为了方便我们将其配置成无密码登陆。首先退出登录的ssh,然后加入授权。
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
注意千万不要跳步骤,连贯性完成,不然容易出错。
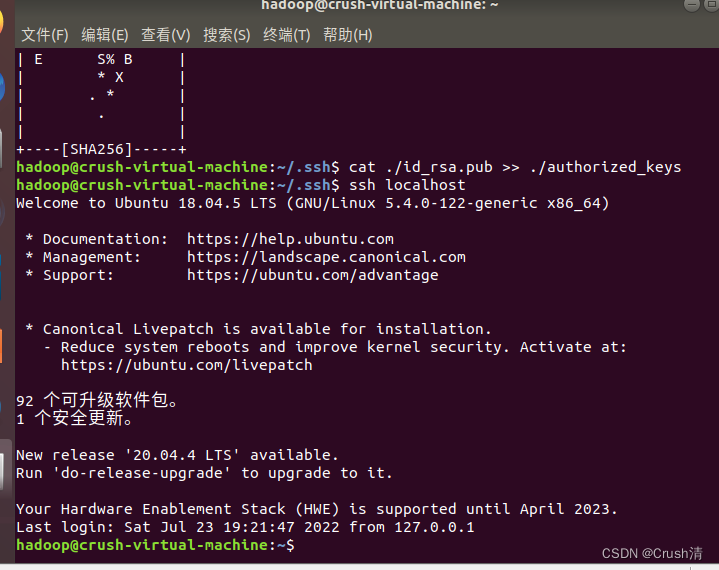
然后再次输入ssh localhost,就可以免密登录了。
ssh localhost
安装配置Java环境
首先我们通过共享文件夹或Xftp传输jdk和hadoop的安装文件:jdk-8u162-linux-x64.tar和hadoop-3.1.3.tar。
共享文件夹配置方法:
实现共享粘贴板,共享文件夹
Xftp使用:
Xshell、Xftp连接虚拟机
我这里为了方便使用了Xftp传输文件,直接拖拽就好。这里将hadoop文件和jdk文件都传输了。
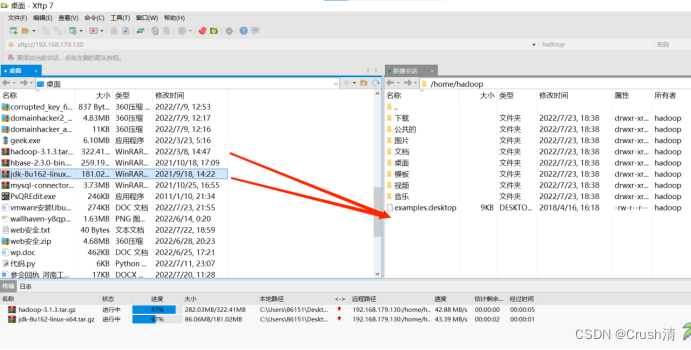
传输后可以直接在虚拟机中看到,将文件移动到到下载里面。(为了好利用指令处理)直接选中拖拽即可。
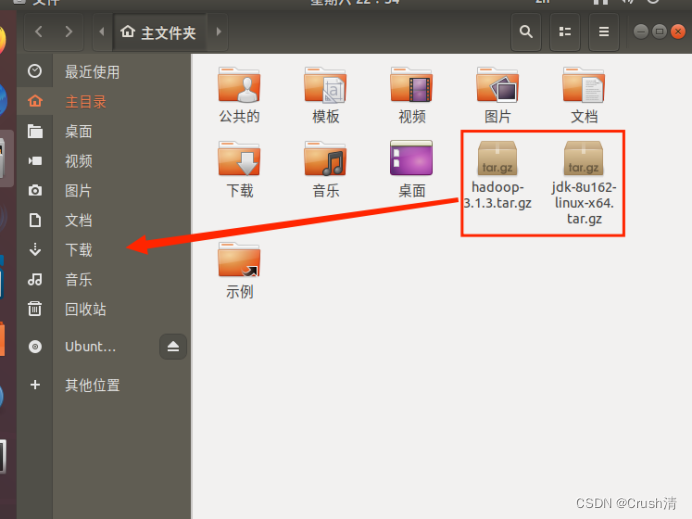
打开终端执行以下指令。
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~
cd 下载
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
创建文件夹/usr/lib保存jdk文件。
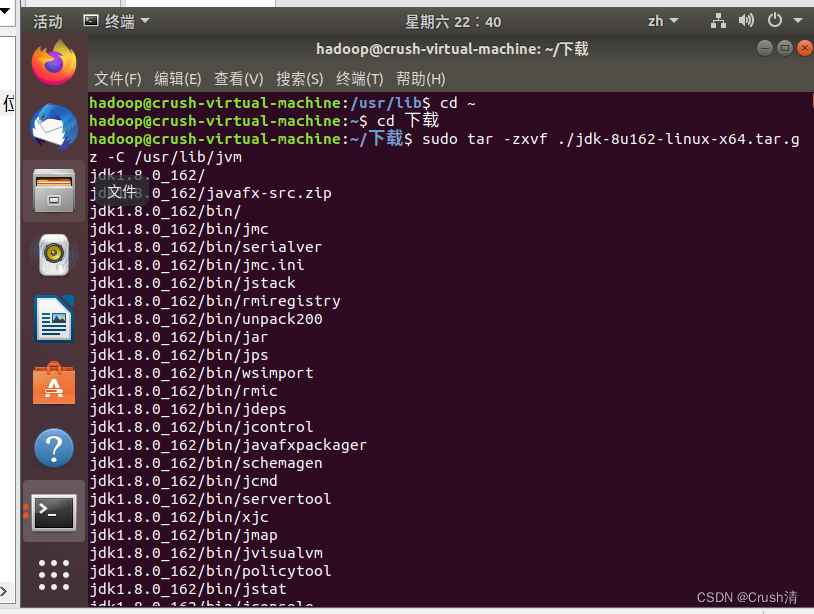
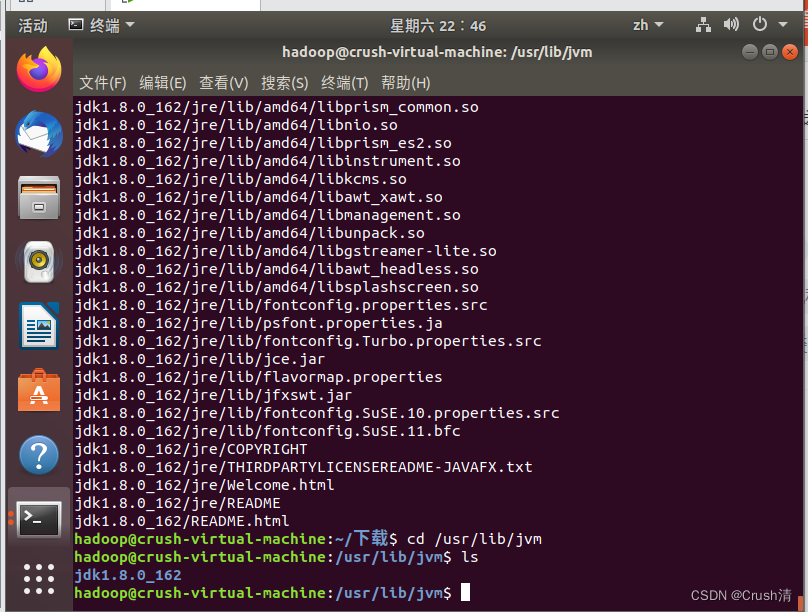
执行指令查看文件夹是否存在。
cd /usr/lib/jvm
ls
文件夹存在即为正确。
接下来配置环境变量,打开环境文件。
cd ~
vim ~/.bashrc
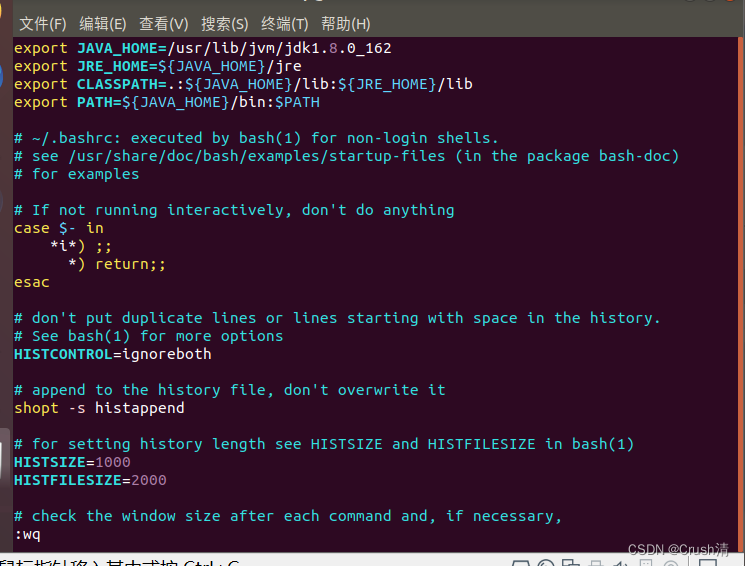
将下面代码输入
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
vim编辑用i键
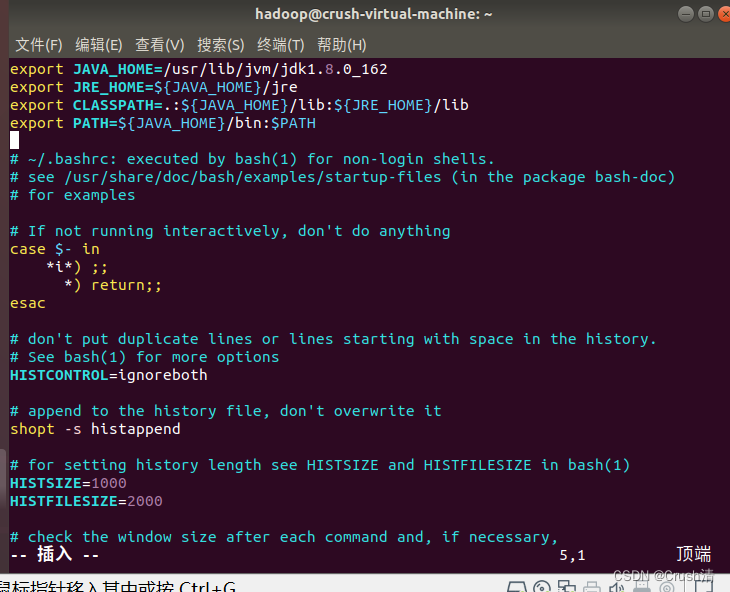
编辑完成后先按esc键,再输入:wq会在界面左下方显示。
如果实在不会用vim,可以用gedit编辑。但是要注意用gedit编辑千万不要动到源文件代码,哪怕多一个符号也可能会出问题。
添加成功后输入下面指令让修改生效。
source ~/.bashrc
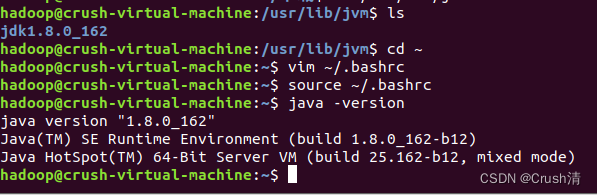
输入以下指令查看jdk是否安装成功也是查看jdk版本号的代码。
java -version
出现下面信息说明安装成功。
安装 Hadoop3.1.3
之前已经将安装包放在下载里了,所以直接解压就可以。
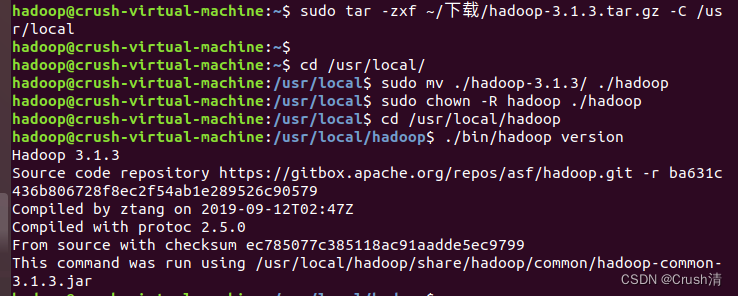
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
hadoop解压后直接就可以使用。
检查是否成功解压也是查看hadoop版本号的指令。
cd /usr/local/hadoop
./bin/hadoop version
出现以下信息即为成功。
配置过程
Hadoop单机配置(非分布式)
利用hadoop自带的例子测试。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
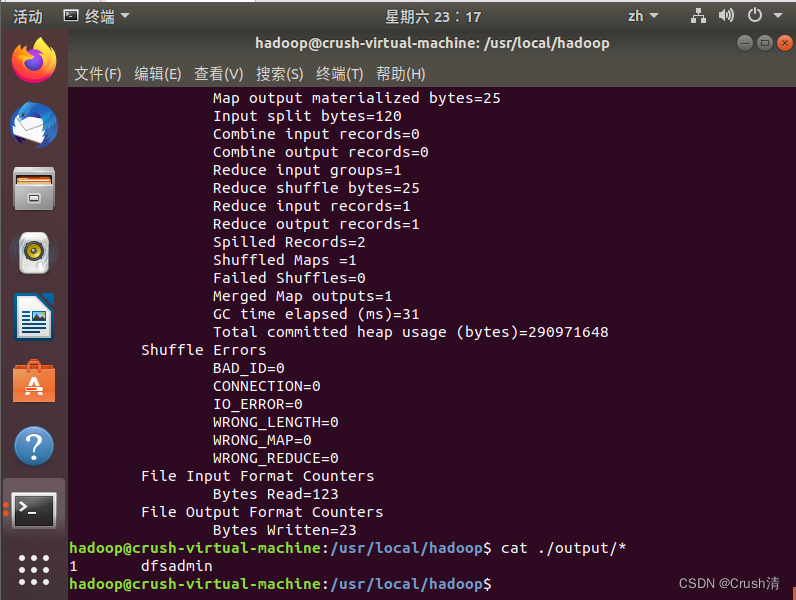
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
这中间会出现很多信息,但是不用管,最后结果如下就好。
出现:
1 dfsadmin
注意:Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output(即输出文件) 删除
rm -r ./output
Hadoop伪分布式配置
修改core-site.xml文件
gedit ./etc/hadoop/core-site.xml
在<configuration> </configuration>中间添加代码
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
添加前:
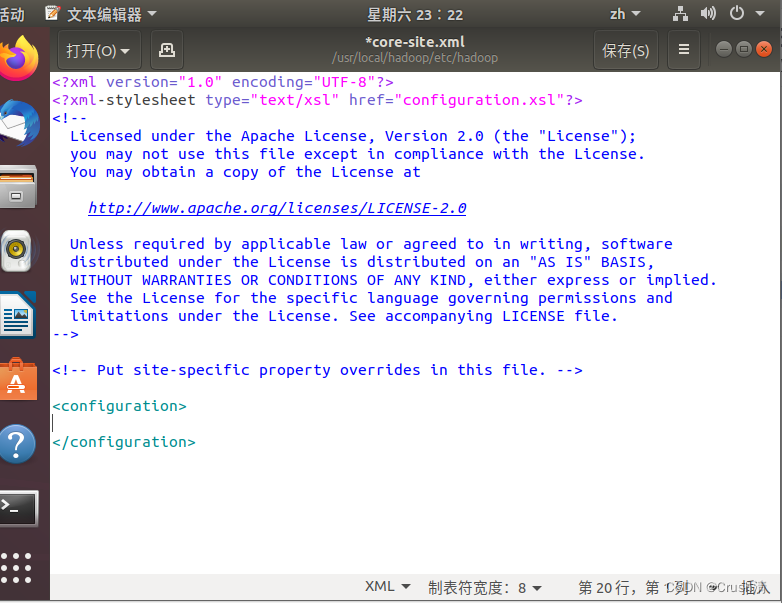
添加后:
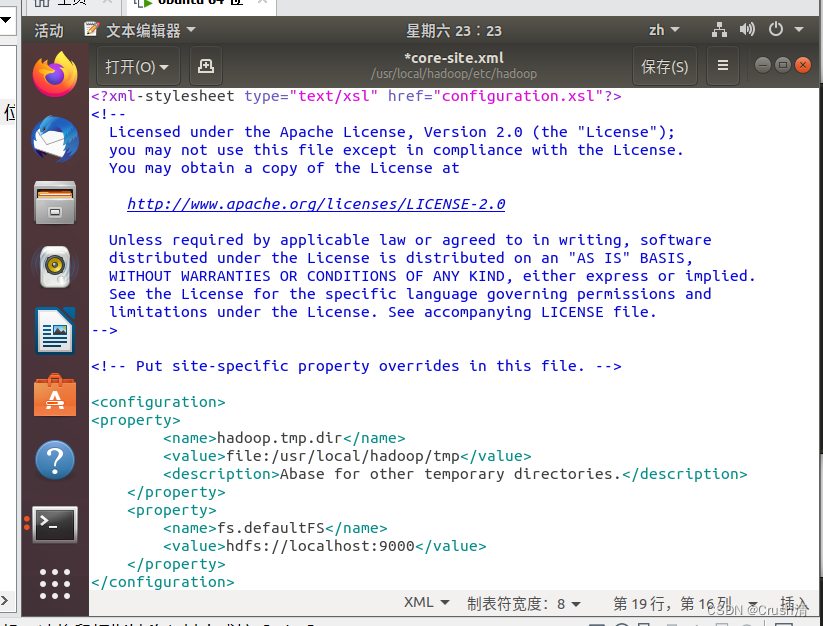
直接Ctrl+S保存就好。关闭后修改文件文件 hdfs-site.xml
gedit ./etc/hadoop/hdfs-site.xml
同理,在<configuration> </configuration>中间添加代码
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
添加后:
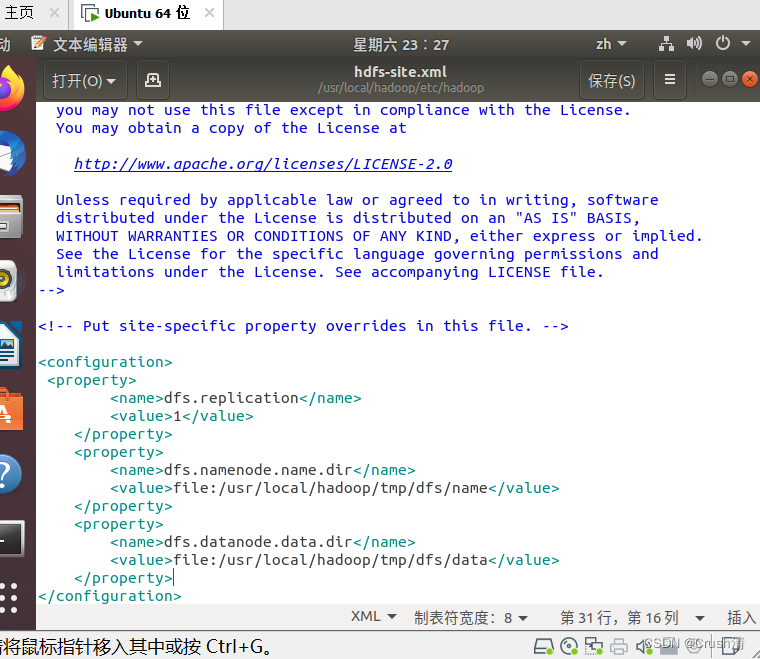
注意代码不能多也不能少。配置完成后,执行 NameNode 的格式化
cd /usr/local/hadoop
./bin/hdfs namenode -format
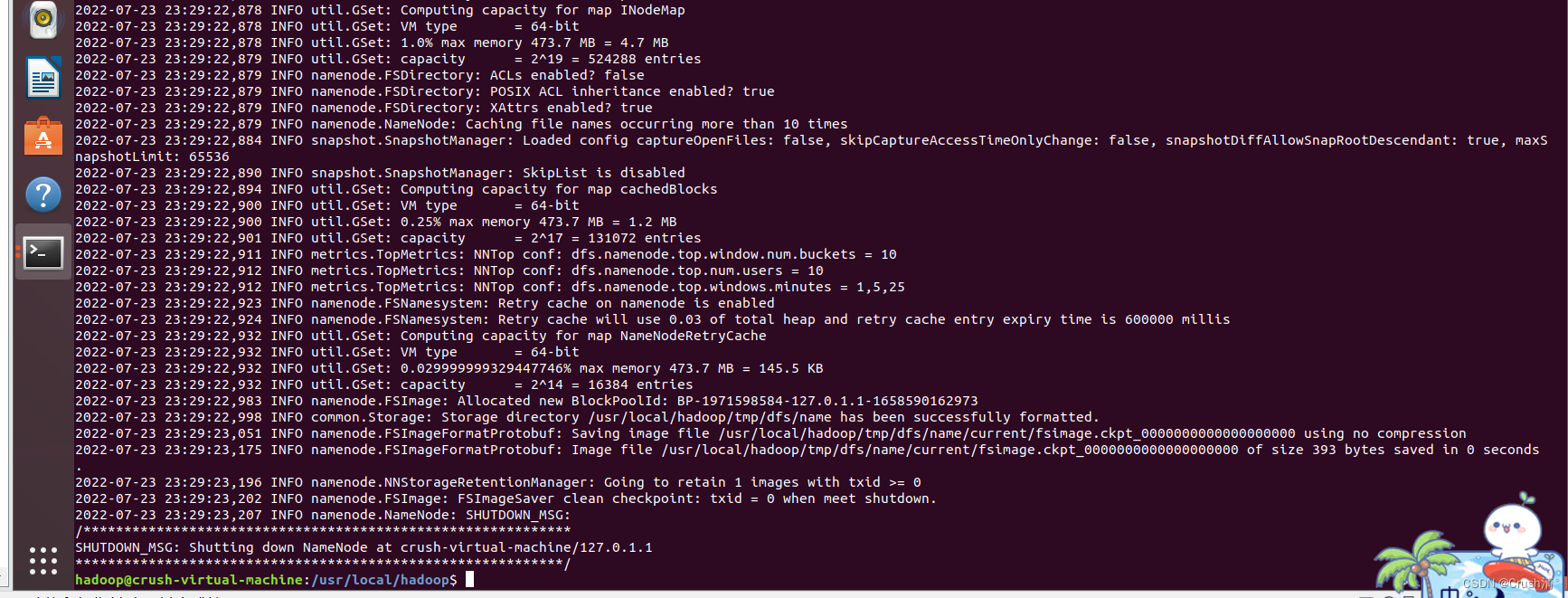
下面是反馈信息的前部分和后部分
WARNING: /usr/local/hadoop/logs does not exist. Creating.
2022-07-23 23:29:21,335 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = crush-virtual-machine/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.3
STARTUP_MSG: classpath = /usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/accessors-smart-1.2.jar:
..........(省略的部分)
2022-07-23 23:29:22,983 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1971598584-127.0.1.1-1658590162973
2022-07-23 23:29:22,998 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted.
2022-07-23 23:29:23,051 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2022-07-23 23:29:23,175 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .
2022-07-23 23:29:23,196 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2022-07-23 23:29:23,202 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2022-07-23 23:29:23,207 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at crush-virtual-machine/127.0.1.1
************************************************************/
一般报错为java的错,若出错请仔细检查jdk安装与配置和 core-site.xml与hdfs-site.xml文件的配置是否出现多个字符少个字符的情况。
尝试启动hadoop,开启 NameNode 和 DataNode 进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh
输入jps查看进程。
jps
如下图出现4个进程说明配置成功
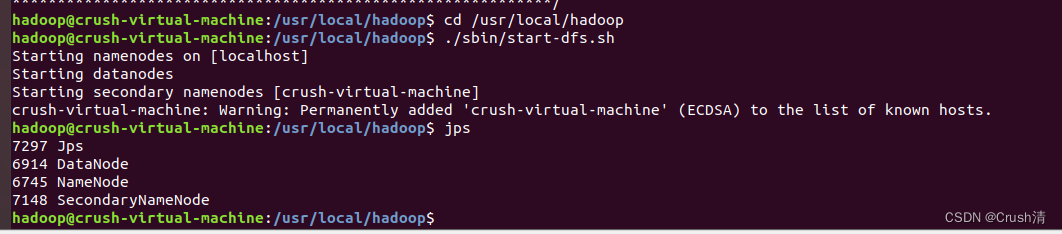
即伪分布式配置成功。尝试运行实例。
首先在 HDFS 中创建用户目录。
./bin/hdfs dfs -mkdir -p /user/hadoop
将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统。
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input
伪分布式运行 MapReduce 作业的方式跟单机模式相同:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
查看运行结果。
./bin/hdfs dfs -cat output/*
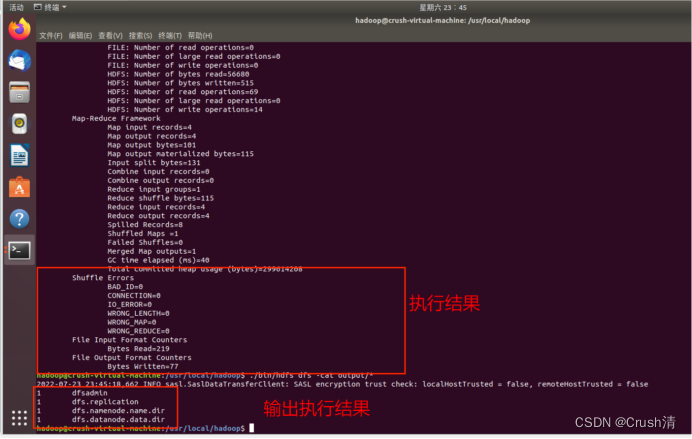
将运行结果取回到本地,在本地查看。
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*

为了避免重复最后删除 output 文件夹
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
最后关闭 Hadoop.
./sbin/stop-dfs.sh
**注意:**伪分布式的使用必须开启./sbin/start-dfs.sh和关闭./sbin/stop-dfs.sh,异常关闭可能会使下次使用出现错误。
至此,完成了Hadoop3.1.3的安装与单机/伪分布式配置并测试。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)