MySQL之Innodb引擎的4大特性
MySQL之Innodb引擎的4大特性原创 anselzhangDBA修炼之路5天前面试官:你了解MySQL的Inodb四大特性吗?1.插入缓冲 (Insert Buffer/Change Buffer)插入缓存之前版本叫insert buffer,现版本 change buffer,主要提升插入性能,change buffer是insert buffer的加强,insert buffer只针对i
面试官:你了解MySQL的Inodb四大特性吗?

1.插入缓冲 (Insert Buffer/Change Buffer)
插入缓存之前版本叫insert buffer,现版本 change buffer,主要提升插入性能,change buffer是insert buffer的加强,insert buffer只针对insert有效,change buffering对insert、delete、update(delete+insert)、purge都有效。有什么用呢?
对于非聚集索引来说,比如存在用户购买金额这样一个字段,索引是普通索引,每个用户的购买的金额不相同的概率比较大,这样导致可能出现购买记录在数据在数据里的排序可能是1000,3,499,35…,这种不连续的数据,一会插入这个数据页,一会插入那个数据页,这样造成的IO是很耗时的,所以出现了Insert Buffer。
Insert Buffer是怎么做的呢?mysql对于非聚集索引的插入,先去判断要插入的索引页是否已经在内存中了,如果不在,暂时不着急先把索引页加载到内存中,而是把它放到了一个Insert Buffer对象中,临时先放在这,然后等待情况,等待很多和现在情况一样的非聚集索引,再和要插入的非聚集索引页合并,比如说现在Insert Buffer中有1,99,2,100,合并之前可能要4次插入,合并之后1,2可能是一个页的,99,100可能是一个页的,这样就减少到了2次插入。这样就提升了效率和插入性能,减少了随机IO带来性能损耗。

综合上述,Insert Buffer 只对于非聚集索引(非唯一)的插入和更新有效,对于每一次的插入不是写到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,如果在则直接插入;若不在,则先放到Insert Buffer 中,再按照一定的频率进行合并操作,再写回disk。这样通常能将多个插入合并到一个操作中,目的还是减少了随机IO带来性能损耗。
使用插入缓冲的条件:
- 非聚集索引
- 非唯一索引
innodb_change_buffer设置的值有:
all: 默认值,缓存insert, delete, purges操作
none: 不缓存
inserts: 缓存insert操作
deletes: 缓存delete操作
changes: 缓存insert和delete操作
purges: 缓存后台执行的物理删除操作
可以通过参数控制其使用的大小:
mysql> show variables like 'innodb_change_buffer_max_size';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
+-------------------------------+-------+
1 row in set (0.05 sec)
innodb_change_buffer_max_size,默认是25%,即缓冲池的1/4。最大可设置为50%。当MySQL实例中有大量的修改操作时,要考虑增大innodb_change_buffer_max_size
上面提过在一定频率下进行合并,那所谓的频率是什么条件?
1)辅助索引页被读取到缓冲池中。正常的select先检查Insert Buffer是否有该非聚集索引页存在,若有则合并插入。
2)辅助索引页没有可用空间。空间小于1/32页的大小,则会强制合并操作。
3)Master Thread 每秒和每10秒的合并操作。
2.双写机制(Double Write)
在InnoDB将BP中的Dirty Page刷(flush)到磁盘上时,首先会将(memcpy函数)Page刷到InnoDB tablespace的一个区域中,我们称该区域为Double write Buffer(大小为2MB,每次写入1MB,128个页,每个页16k,其中120个页为后台线程的批量刷Dirty Page,还有8个也是为了前台起的sigle Page Flash线程,用户可以主动请求,并且能迅速的提供空余的空间)。在向Double write Buffer写入成功后,第二步、再将数据分别刷到一个共享空间和真正应该存在的位置。
MySQL可以根据redolog进行恢复,而mysq在恢复的过程中是检查page"的checksum, checksum就是pgae的最后事务号,发生partial page write问题时. DageR经损坏,找不到该page中的事务号就无法恢复。
具体的流程如下图所示:
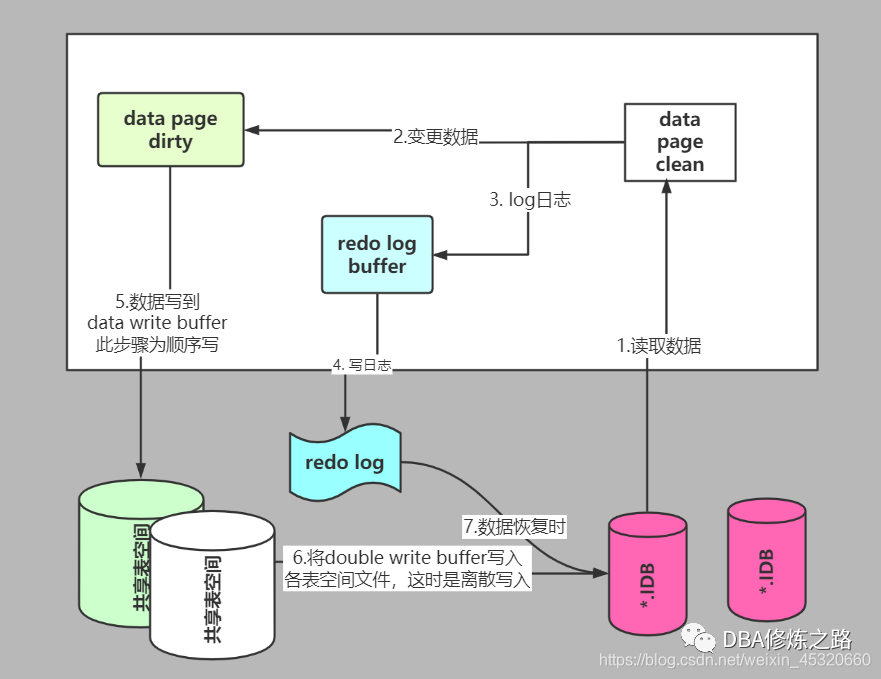
在不同的写入阶段,操作系统crash后,double write带来的保护机制:
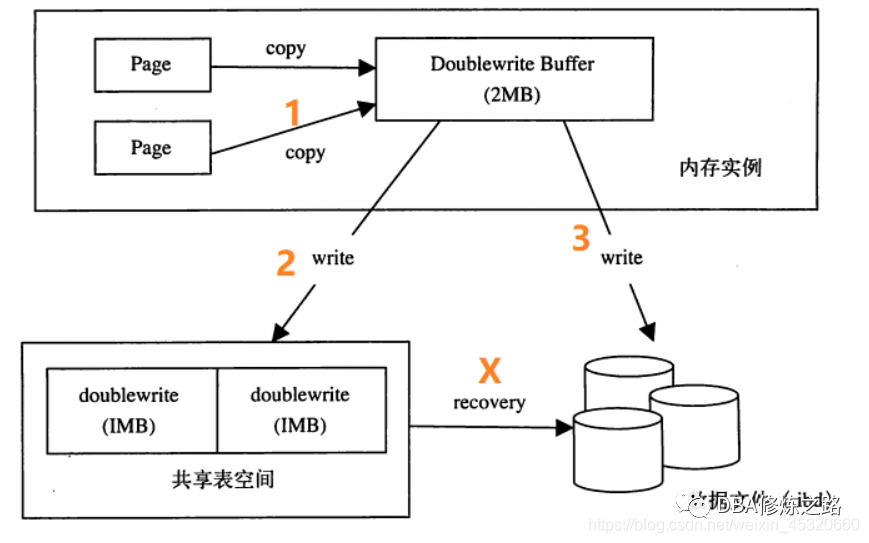
阶段一:copy过程中,操作系统crash,重启之后,脏页未刷到磁盘,但更早的数据并没有发生损坏,重新写入即可
阶段二:write到共享表空间过程中,操作系统crash,重启之后,脏页未刷到磁盘,但更早的数据并没有发生损坏,重新写入即可
阶段三:write到独立表空间过程中,操作系统crash,重启之后,发现:
(1)数据文件内的页损坏:头尾checksum值不匹配(即出现了partial page write的问题)。从共享表空间中的doublewrite segment内恢复该页的一个副本到数据文件,再应用redo log;
(2)若页自身的checksum匹配,但与doublewrite segment中对应页的checksum不匹配,则统一可以通过apply redo log来恢复。
阶段X:recover过程中,操作系统crash,重启之后,innodb面对的情况同阶段三一样(数据文件损坏,但共享表空间内有副本),再次应用redo log即可。
3.自适应哈希索引(Adaptive Hash Index,AHI)
哈希算法是一种非常快的查找方法,在一般情况(没有发生hash冲突)下这种查找的时间复杂度为O(1)。InnoDB存储引擎会监控对表上辅助索引页的查询。如果观察到建立hash索引可以提升性能,就会在缓冲池建立hash索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。
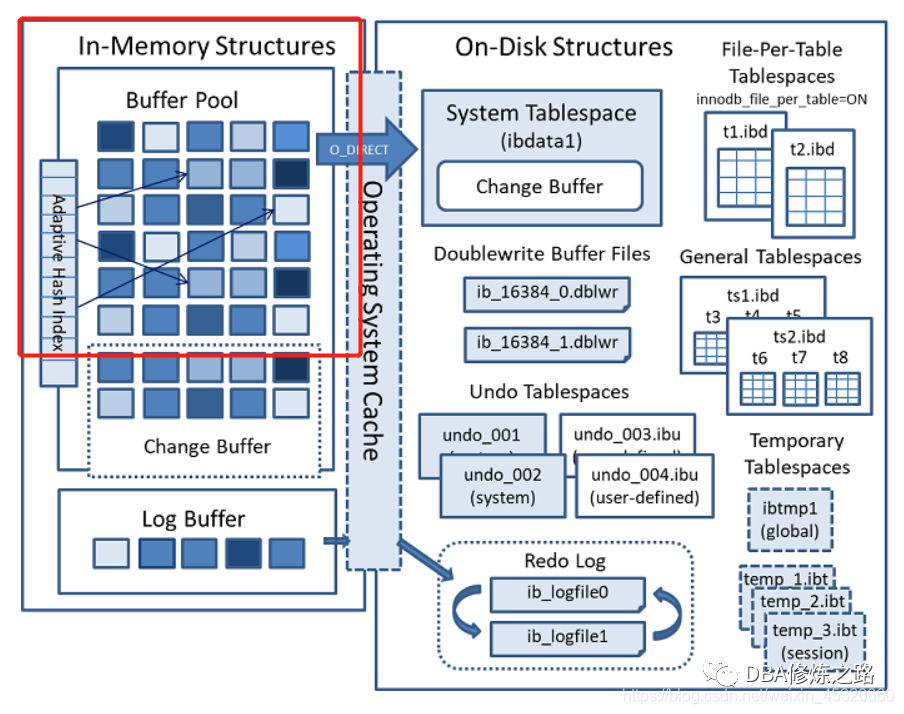
自适应哈希索引由innodb_adaptive_hash_index 变量启用,AHI是通过缓冲池的B+ Tree构造而来,使用索引键的前缀来构建哈希索引,前缀可以是任意长度。InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立hash索引。加快索引读取的效果,相当于索引的索引,帮助InnoDB快速读取索引页。
根据InnoDB官方文档说明,启用了AHI后,读写的速度会提升2倍,辅助索引的连接操作性能可以提高5倍。
查看AHI的工作状态:
show engine innodb status;
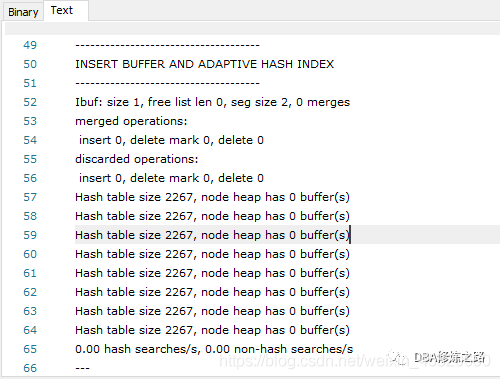
Hash table size:代表AHI的大小;
hash searches/s:代表命中hash查询的频率;
non-hash searches/s:代表没有命中hash查询的频率;
注意:hash查询是等值查询,例如模糊查询、范围查找,是不能使用hash索引的。用户可以根据实际场景去权衡是否要开启AHI。
4.预读 (Read Ahead)
预读(read-ahead)操作是一种IO操作,用于异步将磁盘的页读取到buffer pool中,预料这些页会马上被读取到。预读请求的所有页集中在一个范围内。InnoDB使用两种预读算法:
- Linear read-ahead:线性预读技术预测在buffer pool中被访问到的数据它临近的页也会很快被访问到。能够通过调整被连续访问的页的数量来控制InnoDB的预读操作,使用参数 innodb_read_ahead_threshold配置,添加这个参数前,InnoDB会在读取到当前区段最后一页时才会发起异步预读请求
innodb_read_ahead_threshold 这个参数控制InnoDB在检测顺序页面访问模式时的灵敏度。如果在一个区块顺序读取的页数大于或者等于 innodb_read_ahead_threshold 这个参数,InnoDB启动预读操作来读取下一个区块。innodb_read_ahead_threshold参数值的范围是 0-64,默认值为56. 这个值越高则访问默认越严格。比如,如果设置为48,在当前区块中当有48个页被顺序访问时,InnoDB就会启动异步的预读操作,如果设置为8,则仅仅有8个页被顺序访问就会启动异步预读操作。你可以在MySQL配置文件中设置这个值,或者通过SET GLOBAL 语句动态修改(需要有set global 权限)。
- Random read-ahead: 随机预读通过buffer pool中存中的来预测哪些页可能很快会被访问,而不考虑这些页的读取顺序。如果发现buffer pool中存中一个区段的13个连续的页,InnoDB会异步发起预读请求这个区段剩余的页。通过设置 innodb_random_read_ahead 为 ON开启随机预读特性。
通过 SHOW INNODB ENGINE STATUS 命令输出的统计信息可以帮助你评估预读算法的效果,统计信息包含了下面几个值:
innodb_buffer_pool_read_ahead 通过预读异步读取到buffer pool的页数
innodb_buffer_pool_read_ahead_evicted 预读的页没被使用就被驱逐出buffer pool的页数,这个值与上面预读的页数的比值可以反应出预读算法的优劣。
innodb_buffer_pool_read_ahead_rnd 由InnoDB触发的随机预读次数。
更多精彩内容,欢迎关注微信公众号


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)